









使用Caffe复现DeepID实验
本实验使用Casia-Webface part2的切图来复现DeepID实验结果。
- DeepID网络配置文件
- 训练验证数据组织
- 实验结果
- 结果分析
DeepID网络配置文件
-下面给出deepId_train_test.prototxt的内容
name: "deepID_network"
layer {
name: "input_data"
top: "data"
top: "label"
type: "Data"
data_param {
source: "dataset/deepId_train_lmdb"
backend: LMDB
batch_size: 128
}
transform_param {
mean_file: "dataset/deepId_mean.proto"
}
include {
phase: TRAIN
}
}
layer {
name: "input_data"
top: "data"
top: "label"
type: "Data"
data_param {
source: "dataset/deepId_test_lmdb"
backend: LMDB
batch_size: 128
}
transform_param {
mean_file: "dataset/deepId_mean.proto"
}
include {
phase: TEST
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
name: "conv1_w"
lr_mult: 1
decay_mult: 0
}
param {
name: "conv1_b"
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 20
kernel_size: 4
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
name: "conv2_w"
lr_mult: 1
decay_mult: 0
}
param {
name: "conv2_b"
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 40
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 1
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
name: "conv3_w"
lr_mult: 1
decay_mult: 0
}
param {
name: "conv3_b"
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 60
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4"
type: "Convolution"
bottom: "pool3"
top: "conv4"
param {
name: "conv4_w"
lr_mult: 1
decay_mult: 0
}
param {
name: "conv4_b"
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 80
kernel_size: 2
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "fc160_1"
type: "InnerProduct"
bottom: "pool3"
top: "fc160_1"
param {
name: "fc160_1_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "fc160_1_b"
lr_mult: 2
decay_mult: 1
}
inner_product_param {
num_output: 160
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "fc160_2"
type: "InnerProduct"
bottom: "conv4"
top: "fc160_2"
param {
name: "fc160_2_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "fc160_2_b"
lr_mult: 2
decay_mult: 1
}
inner_product_param {
num_output: 160
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "fc160"
type: "Eltwise"
bottom: "fc160_1"
bottom: "fc160_2"
top: "fc160"
eltwise_param {
operation: SUM
}
}
layer {
name: "dropout"
type: "Dropout"
bottom: "fc160"
top: "fc160"
dropout_param {
dropout_ratio: 0.4
}
}
layer {
name: "fc_class"
type: "InnerProduct"
bottom: "fc160"
top: "fc_class"
param {
name: "fc_class_w"
lr_mult: 1
decay_mult: 1
}
param {
name: "fc_class_b"
lr_mult: 2
decay_mult: 1
}
inner_product_param {
num_output: 10499
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc_class"
bottom: "label"
top: "loss"
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc_class"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
#这里注意fc160维之后不接ReLU,个人在这里吃了亏,因为拿fc160做特征时,用了ReLU就将负数信息删除了,而存在于这一层的负数特征可能对分类有帮助。- 下面是deepId_solver.prototxt
net: "deepId_train_test.prototxt"
# conver the whole test set. 484 * 128 = 62006 images.
test_iter: 484
# Each 6805 is one epoch, test after each epoch
test_interval: 6805
base_lr: 0.01
momentum: 0.9
weight_decay: 0.005
lr_policy: "step"
# every 30 epochs, decrease the learning rate by factor 10.
stepsize: 204164
gamma: 0.1
# power: 0.75
display: 200
max_iter: 816659 # 120 epochs.
snapshot: 10000
snapshot_prefix: “trained_model/deepId"
solver_mode: GPU训练数据组织
数据来自CASIA-Webface的切图(人脸对齐,缩放到一个固定的比例,比如55*55),CASIA-Webface共10575个人,每个人的图片数量从几十到几百不等。类别数量之间严重不平衡,这里,我试验了两个方式(没有用全部的10575类,如deepId_train_test.prototxt定义的那样,只使用了10499类,如果某类别的图片数目过少,就不使用它):
1. 让训练集的每一类数目完全一样,比如我的实验中为训练集每个人50张图片。
2. 图片数目最多的那一类于最少的哪一类的数目比例不超过3:1(个人愚见,不知是否有道理,请高手指点一二)。
验证集是从每一类别的都随机挑选一部分不在训练集中的图片来做验证。
-下面的prepare_deepId_data.py是我组织训练测试数据的Python代码,仅供参考(高手请拍砖)。
import os
from random import shuffle
import cPickle
def check_parameter(param, param_type, create_new_if_missing=False):
assert param_type == 'file' or param_type == 'directory'
if param_type == 'file':
assert os.path.exists(param)
assert os.path.isfile(param)
else:
if create_new_if_missing is True:
if not os.path.exists(param):
os.makedirs(param)
else:
assert os.path.isdir(param)
else:
assert os.path.exists(param)
assert os.path.isdir(param)
def listdir(top_dir, type='image'):
# type_len = len(type)
tmp_file_lists = os.listdir(top_dir)
file_lists = []
if type == 'image':
for e in tmp_file_lists:
if e.endswith('.jpg') or e.endswith('.png') or e.endswith('.bmp'):
file_lists.append(e)
elif type == 'dir':
for e in tmp_file_lists:
if os.path.isdir(top_dir + e):
file_lists.append(e)
else:
raise Exception('Unknown type in listdir')
return file_lists
def prepare_deepId_data_eq(src_dir, tgt_dir, num_threshold=50):
check_parameter(src_dir, 'directory')
check_parameter(tgt_dir, 'directory', True)
if src_dir[-1] != '/':
src_dir += '/'
if tgt_dir[-1] != '/':
tgt_dir += '/'
class_lists = listdir(src_dir, 'dir')
print '# class is : %d' % len(class_lists)
class_table = {}
num = 0
for e in class_lists:
assert e not in class_table
class_table[e] = listdir(''.join([src_dir, e]), 'image')
if len(class_table[e]) > num_threshold:
num += 1
print 'There are %d people whose number of images is greater than %d.' % (num, num_threshold)
print 'Use %d num people to train the deepId net..' % num
train_set = []
test_set = []
label = 0
dirname2label = {}
for k, v in class_table.iteritems():
if len(v) >= num_threshold:
shuffle(v)
assert k not in dirname2label
dirname2label[k] = label
i = 0
for i in xrange(num_threshold):
train_set.append((k + '/' + v[i], label))
i += 1
num_test_images = min(num_threshold / 3, len(v) - num_threshold)
for j in xrange(num_test_images):
test_set.append((k + '/' + v[i + j], label))
label += 1
f = open(tgt_dir + 'dirname2label.pkl', 'wb')
cPickle.dump(dirname2label, f, 0)
f.close()
f = open(tgt_dir + 'deepId_train_lists.txt', 'w')
for e in train_set:
print >> f, e[0], ' ', e[1]
f.close()
f = open(tgt_dir + 'deepId_test_lists.txt', 'w')
for e in test_set:
print >> f, e[0], ' ', e[1]
f.close()
def prepare_deepId_data_dif(src_dir, tgt_dir, num_threshold=20, add_all=False):
check_parameter(src_dir, 'directory')
check_parameter(tgt_dir, 'directory', True)
if src_dir[-1] != '/':
src_dir += '/'
if tgt_dir[-1] != '/':
tgt_dir += '/'
class_lists = listdir(src_dir, 'dir')
print '# class is : %d' % len(class_lists)
class_table = {}
num = 0
for e in class_lists:
assert e not in class_table
class_table[e] = listdir(''.join([src_dir, e]), 'image')
if len(class_table[e]) > num_threshold:
num += 1
print 'There are %d people whose number of images is greater than %d.' % (num, num_threshold)
print 'Use %d num people to train the deepId net, we do not care the validation set result...' % num
train_set = []
test_set = []
label = 0
dirname2label = {}
for k, v in class_table.iteritems():
if len(v) >= num_threshold:
shuffle(v)
assert k not in dirname2label
dirname2label[k] = label
i = 0
for i in xrange(num_threshold):
train_set.append((k + '/' + v[i], label))
i += 1
j = 0
num_test_images = min(int(num_threshold / 3), len(v) - num_threshold)
for j in xrange(num_test_images):
test_set.append((k + '/' + v[i + j], label))
if len(v) > num_threshold + num_test_images:
offset = j + 1 + i
if add_all is False:
# add the rest of all images or 3 times the num_threshold images to the training set....
num_left = len(v) - num_threshold - num_test_images
num_left = min(num_left, num_threshold)
for ii in xrange(num_left):
train_set.append((k + '/' + v[ii + offset], label))
else:
# print 'Adding the rest of all data into training set.'
while offset < len(v):
train_set.append((k + '/' + v[offset], label))
offset += 1
label += 1
f = open(tgt_dir + 'dirname2label.pkl', 'wb')
cPickle.dump(dirname2label, f, 0)
f.close()
f = open(tgt_dir + 'deepId_train_lists.txt', 'w')
for e in train_set:
print >> f, e[0], ' ', e[1]
f.close()
f = open(tgt_dir + 'deepId_test_lists.txt', 'w')
for e in test_set:
print >> f, e[0], ' ', e[1]
f.close()
if __name__ == '__main__':
prepare_deepId_data_eq('CASIA-Webface/','dataset', 50)
prepare_deepId_data_dif('CASIA-Webface/','dataset', 20, True)
#后缀eq表示每一类数目一样,50表示希望每一类都有50幅图片,dif每一类数目不一样。实验结果
实验过程是抽取已经训练好了的模型,将lfw的测试数据抽取特征fc160维的特征,然后对特征用cos距离或者joint bayesian距离来做人脸验证。
-训练过程loss曲线如下:
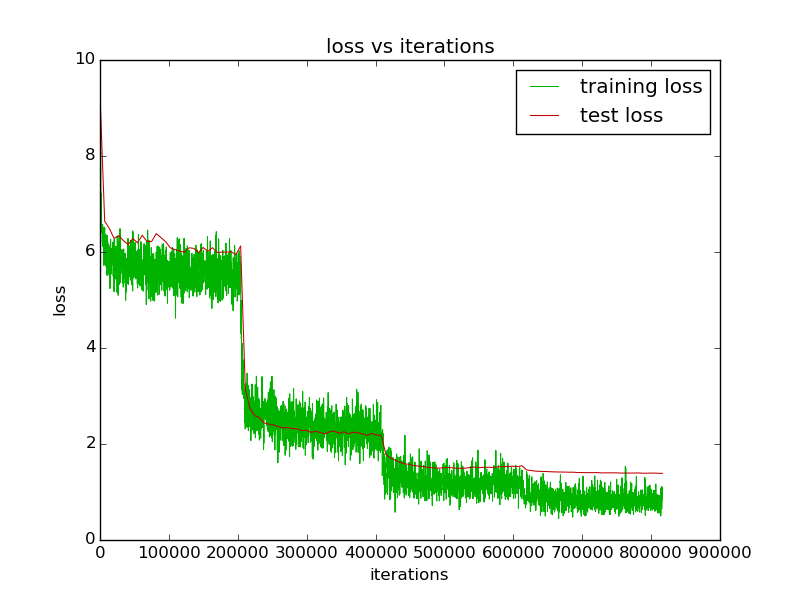
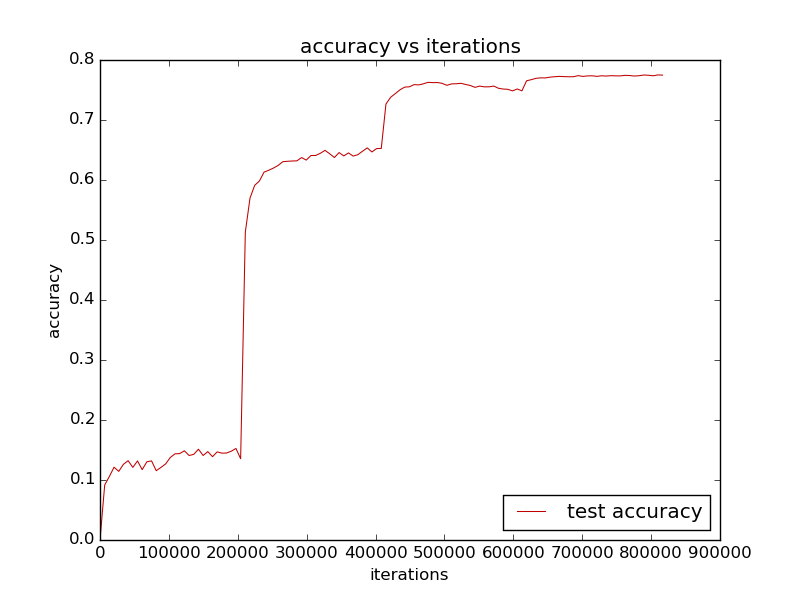
-训练过程的accuracy曲线如下:
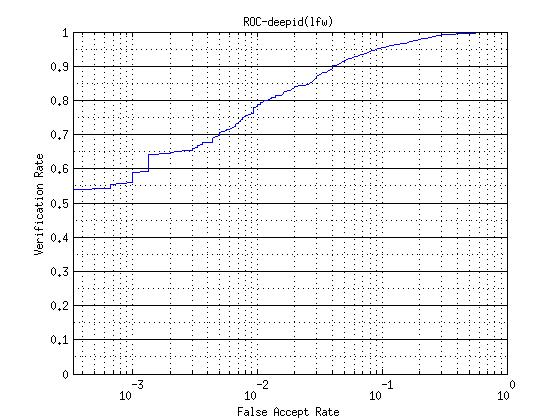
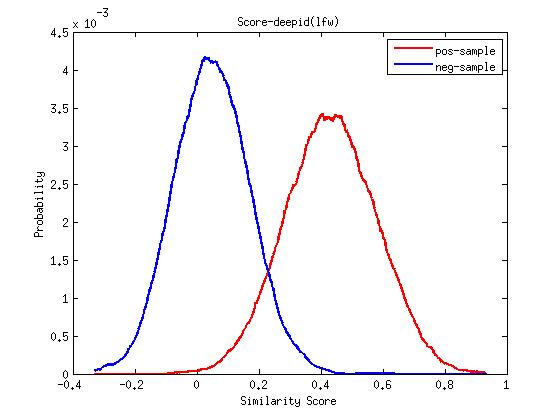
-使用cos距离度量在LFW上的roc曲线以及正负样本分布图
-使用joint bayesian在LFW上的roc曲线以及正负样本分布图
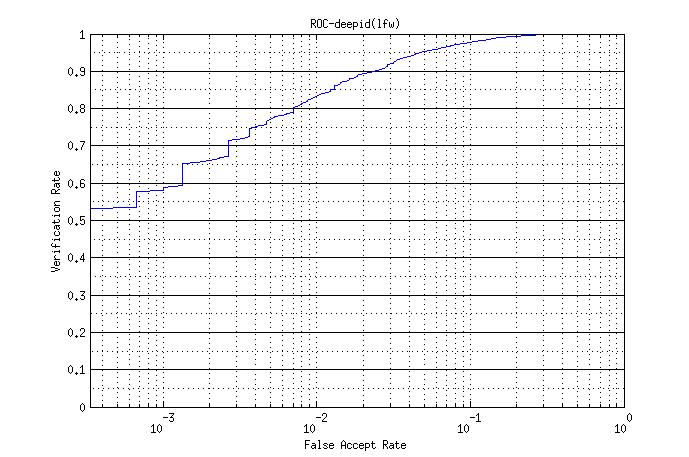
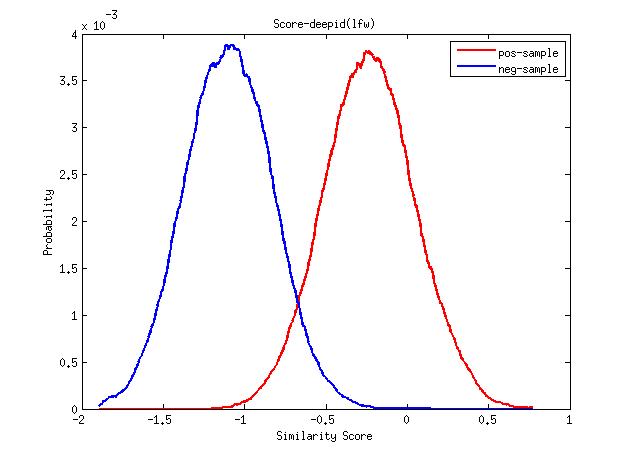
-在LFW上的单part模型结果如下:
| metric | mean accuracy | std |
|---|---|---|
| cos | 0.9395 | 0.0035 |
| joint bayesian | 0.9545 | 0.0045 |
实验结果分析说明
本实验单模型只有95.45%的准确率,没有到97%左右(实验室师兄用convnet复现得到的单part的准确率),存在如此大的差距。一方面还是参数没调好,训练的不够好,数据组织欠妥,另一方面也许是deepID的第3个conv层和第4个conv层用的local卷积,人脸不同区域用不同filter来提取特征能得到更加丰富的特征?
ps: caffe的local卷积太慢了,有点不能忍。 话说happynear大神deepID的LFW上了97.17,不得不佩服大神调参能力,还是自己太菜了。
*******************************************************************************************************************************************
-

- 你好,我的数据是CASIA-WEBface人脸对齐过后的,输入的图像crop成80*80灰度图进行训练,每一类使用两个样本进行测试,其余全部用来训练,网络结构和训练参数和提供的网络的一样,但是我的测试集合上的准确率只到68% ,loss也一直都是在2.0上下,到达65%以上保存了model,在调低了学习率之后,fixed学习20W次以上也只提高到68%,我想请问准确率的提升是调整学习率一个参数,还是其他参数都要调整吗?谢谢!
34楼 小娃娃妮 2016-09-09 15:20发表
-
33楼
lyf5oo 2016-09-03 20:53发表
-

- 我看图片集中的人脸都是对齐的啊(鼻子都在中间),还需要用什么工具来对齐吗?对齐指的是把人脸扣出来吗?谢谢。
-
32楼
姜鱼 2016-08-26 10:26发表
-

-
楼主CASIA-Webface样本库方便共享一下吗?Google下着下着就断了,毕设需要用这个,可以的话加我qq呗,qq号:348132030。
-
Re:
天妒WS 2016-09-01 18:15发表
-

- 回复jianliuyu:这个数据库需要申请。不能私自传哦。你可以让你让老师申请吧。
-
-
31楼
yueyuecsdn 2016-08-22 14:32发表
-

-
楼主你好,我用的是caffe在训练数据,然后需要train文件夹和test文件夹及其levdel文件,那么由原始的数据集怎样生成这两个文件夹呢,求楼主
-
Re:
天妒WS 2016-08-22 20:03发表
-
-
回复yueyuecsdn:说实话,不是特别能够理解你的问题。你是说如何划分训练测试还是指怎么用程序生成呢?
-
Re:
yueyuecsdn 2016-08-23 14:53发表
-
- 回复a_1937:问题已经解决,么么哒
-
-
-
30楼
wjxzju 2016-07-24 21:35发表
-

-
您好,很感谢这篇文章的指导,我在复现时,采用的是CASIA_WEBFACE的数据库,我对CASIA_WEBFACE进行过crop处理,将图像归一化为55x47大小,利用您的网络训练时,test_accuracy一直不高,目前在60%-70%左右,跟您的结果相比差了10%,利用lfw数据库进行测试,效果也不是很好,我对您文中提到的让训练集每一类数目完全一样有点疑问,因为数据库中有相当一部分人的图片数目少于50张,我统计过大约有快一半的人数,那么怎么对这些人进行扩充满足条件呢,我在训练的时候并没有进行这种保证每人图片数均衡的操作,只是简单的划分训练集和验证集时采用了9:1的比例(另外我还去除了图片数目太少,<10张的人数),是不是每人图片均衡一点,效果会更好呢? 还望您能解答一下,谢谢!
-
Re:
天妒WS 2016-07-27 23:33发表
-
- 回复wjxzju:1、确保你的训练数据的人脸是对齐的;2、组织数据时,不必按照这篇博客的来,这个实验是我做了比较久了,后来又实验时,直接每一类取1~2张人脸作为验证集,其余的全部作为训练集。3、对齐后的人脸一般不要按照分类任务那样crop做数据增强,仅仅做个水平 镜像即可。
-
-
29楼
lyf5oo 2016-07-21 22:39发表
-
-
感谢!这片文章对我帮助很大! 但当我用这个网络实际训练时却是如下的输出:
Solving deepID_network
Learning Rate Policy: step
Iteration 0, Testing net (#0)
Test net output #0: accuracy = 0
Test net output #1: loss = 9.26645 (* 1 = 9.26645 loss)
Iteration 0, loss = 9.26654
Train net output #0: loss = 9.26654 (* 1 = 9.26654 loss)
Iteration 0, lr = 0.001
Iteration 50, loss = -8.41308e-08
Train net output #0: loss = 0 (* 1 = 0 loss)
Iteration 50, lr = 0.001
Iteration 100, loss = -8.41308e-08
。。。
Iteration 2000, loss = -8.41308e-08
然后一只是这样,loss = -8.41308e-08
不知为啥这样,请指教,谢谢!-
Re:
天妒WS 2016-07-27 23:29发表
-
- 回复lyf5oo:CNN一般是需要大量数据才能训练好的,如果针对一个特定任务可用数据量太小的话,可以考虑在另一个较为相似的较大规模的数据库上预训练,然后Finetune这个小数据库。
-
Re:
天妒WS 2016-07-22 13:30发表
-
-
回复lyf5oo:lfw人脸太少了吧,CNN需要大数据量的,建议使用CASIA-Webface
-
Re:
lyf5oo 2016-07-23 07:17发表
-
- 回复a_1937:就是CASIA-Webface下不到,看页面上说需要大学申请,不对个人:(
-
-
Re:
lyf5oo 2016-07-21 22:40发表
-
- 回复lyf5oo:我用的是lfw的人脸库训练的。
-
-
28楼
qq_34896051 2016-07-16 14:42发表
-

-
请问博主使用的是什么型号的GPU 迭代训练一共花了多长时间 我用Titian X迭代30万次 预估时间要200多天。。。。。。请问调整哪些系数能加快训练 谢谢
-
Re:
天妒WS 2016-07-17 11:08发表
-
- 回复qq_34896051:你一定是哪里搞错了吧,我用的也是titanx,训练3个多小时就完成了。
-
-
27楼
纪阴阳 2016-07-14 13:49发表
-

-
楼主你好,我又继续来烦你了,不好意思。。
关于LFW的测试过程,博文里提的不多,楼主简要说一下可以么?主要是测试数据怎么组织的?谢谢!-
Re:
天妒WS 2016-07-15 15:52发表
-
-
回复u012490753:测试数据就是LFW的View2协议吧,10折交叉验证,评估算法效果。
-
Re:
yueyuecsdn 2016-08-23 21:35发表
-
- 回复a_1937:楼主,有关这个view2协议,有什么相关文档和实现代码可以参考吗?
-
Re:
纪阴阳 2016-07-18 12:38发表
-
-
回复a_1937:多谢楼主哈,我还想再请教一下,lfw的pair comparison测试,楼主是用pycaffe或者matcaffe自己写的么?如果是的话,图片的读取和预处理应该也是自己做的吧?请问除了减去mean face还需要什么预处理操作呢。。
如果不是用pycaffe自己写的,那是怎么做的呢?我之前train是用的digits,不过看来它应该没法搞pair comparison。楼主是又自己写了一个test的prototxt吗?
多谢了!
-
-
-
26楼
bomberggggg 2016-07-11 10:05发表
-

-
楼主你好,你说的55*47不太明确,是高55,宽47吗?另外,我用webface对齐加裁剪后的图片训练,lfw测试精度只有82%,训练的精度只有50%多,和你的结果差别很大,我估计是样本有问题,我想楼主能不能把你用于训练的样本(对齐裁剪后的)打包成百度云发给大家,多谢了!
-
Re:
纪阴阳 2016-07-14 10:17发表
-
-
回复bomberggggg:层主你好,我情况跟你差不多啊,我是912个类,每个类60-100张不等,尺寸250*250(filter size跟着相应调整),但是调了很久参数准确率也只有62%……
而且我非常不能理解博主的loss/accuracy曲线为什么会有那种突降,是个step down的学习率相关吗还是为什么
-
-
25楼
bomberggggg 2016-07-11 10:05发表
-
- 楼主你好,你说的55*47不太明确,是高55,宽47吗?另外,我用webface对齐加裁剪后的图片训练,lfw测试精度只有82%,训练的精度只有50%多,和你的结果差别很大,我估计是样本有问题,我想楼主能不能把你用于训练的样本(对齐裁剪后的)打包成百度云发给大家,多谢了!
-
24楼
qq_34896051 2016-07-07 15:27发表
-
-
你好,请问训练好model后如何计算余弦距离或者贝叶斯距离来测试?
-
Re:
天妒WS 2016-07-09 23:09发表
-
- 回复qq_34896051:你训练好了模型,然后将两幅待比对的人脸图片进行特征提取,比如deepID的160维特征向量,你就得到了两个160维特征向量,这两个特征向量就可以计算cos距离了。
-
-
23楼
纪阴阳 2016-07-01 11:28发表
-
-
楼主你好,我对你的文章的理解是这样的,不知道对不对
你的95%的正确率是verification的正确率,也就是说任务是给两张一个人或者不同人的照片然后判断是否是一个人。
但是之前训练模型时是按照分类任务进行训练的,这个训练的准确率应该没有95%这么高吧?请问大概是多少?-
Re:
天妒WS 2016-07-04 13:10发表
-
- 回复u012490753:训练的准确率也只有70~80%
-
-
22楼
qq_32196403 2016-06-27 10:43发表
-

-
请问博主,你的卷积核大小和stride以及pooling的size和stride是怎么选择的?
-
Re:
天妒WS 2016-06-28 10:30发表
-
- 回复qq_32196403:pooling的size和大小一般都是按照将feature map的大小减半来设计的吧,参考了vgg的,这个实验除了pooling2以外,基本与deepID1的论文结构保持一致。
-
-
21楼
小古东阿杜 2016-06-23 09:45发表
-

-
你好,请问最后用于分类的160特征保存在哪边,如何提取出来进行分类呢,非常感谢!
-
Re:
天妒WS 2016-06-28 10:32发表
-
- 回复u014661462:那个你看看tools/extract_features.cpp的源代码就清楚了吧。
-
-
20楼
qq_32196403 2016-05-27 15:56发表
-
-
就是楼主有像DeepID论文里将脸按照不同特征点对齐裁剪出来再训练吗?
-
Re:
天妒WS 2016-05-30 13:48发表
-
- 回复qq_32196403:这个数据库得向CASIA申请,对齐是用SDM检测关键点然后根据相似变换做的。具体的SDM算法可以参见网址http://www.cnblogs.com/cv-pr/p/4797823.html
-
-
19楼
qq_32196403 2016-05-27 15:55发表
-
- 或者楼主能给个数据链接吗?这个数据还得交申请,网上下载的就是一堆z01,z02什么的
-
18楼
qq_32196403 2016-05-27 15:51发表
-
- 请问楼主,那个casia_webface数据库里面webface.z01,z02是啥意思?跟那个casia_webface.zip有啥关系?还有楼主你是怎么对齐的人脸,预处理有同时对lfw和casia_webface裁剪并对齐脸吗?
-
17楼
刘春水 2016-05-14 18:16发表
-

- 博主您好,我最近也在复现deepid,目前还没训练完,但是发现准确率在相当长的时间停在0.5左右,我发现你给出的准确率曲线图有一个骤升的过程,这是为什么呢?
-
16楼
gongxuchao001 2016-05-07 10:42发表
-

-
感谢您的回复,是这样的,我直接作cos距离的时候统计了一下,相同人脸的相似度有很多比不同人脸的还低,整体准确率也就在50%左右,我也试过别人训练的模型也都差不多是这个准确率,这是啥原因呢?是不是简单的特征比对有问题?多谢了!
-
Re:
K3832127 2016-05-12 14:47发表
-

- 回复gongxuchao001:胸弟,你叼。你要知道随便设阈值做分割时,都至少有50%
-
Re:
天妒WS 2016-05-09 18:31发表
-
- 回复gongxuchao001:我猜可能的原因:1、模型没训练好,以LFW为测试基准,看看你的模型在LFW上的准确率; 2、测试的时候,训练数据是怎么预处理的,测试数据也怎么预处理;3、画出ROC曲线,选取一个最好的阈值。
-
-
15楼
gongxuchao001 2016-05-06 17:33发表
-
-
您好 我最近在复现deepid,已经训练完成,比对的时候我按照您博客里的方式提取了160维特征,直接用cos距离做的匹配,不是同一张人脸的相似度也都很高,请问是我度量的方式有问题么?
-
Re:
天妒WS 2016-05-06 20:01发表
-
- 回复gongxuchao001:不是同一个人的分数也很高这很正常,本身这个deepID网络训练好后在LFW上的识别率也才96左右,也就是说还是有那么一些不是同一个人的人脸图片被当成同一个人脸的图片,度量方式并没有任何问题。而且你还得选择一个阈值,使得在LFW上的识别率最高,也就是那个ROC曲线中你选取的阈值。当两张人脸分数大于这个阈值为同一个人,小于时为不同的人。这个结果告诉你你大概有96%的信心相信预测结果是正确的。
-
-
14楼
zeromike 2016-05-03 19:28发表
-

- 楼主你好,我最近第一次接触caffe,图片的预处理,lmdb转换,caffe的一些细节都不太熟练,不知如何下手,楼主可不可以发我一份完整code让我参考一下
-
13楼
Sunshine_in_Moon 2016-05-03 10:33发表
-

-
楼主你好,我看到你的test精度没有达到80%,为什么在lFW上测试能达到90%以上呢?差别为什么这么大?
-
Re:
天妒WS 2016-05-03 10:40发表
-
-
回复Sunshine_in_Moon:那个test是在CASIA上的准确率,其实就是用来指示什么时候训练可以结束的标识而已。跟LFW上的准确率并无任何关系。
-
Re:
Sunshine_in_Moon 2016-05-04 10:20发表
-
- 回复a_1937:谢谢!
-
-
-
12楼
xubokun1992 2016-04-11 09:48发表
-

-
-
Re:
天妒WS 2016-04-11 10:25发表
-
- 回复xubokun1992:第3,4个卷积层我用的就是普通的卷积,没有用局部权值不共享的那种卷积层,caffe里面有那种局部权重不共享的那种卷积,叫做local卷积,但是local卷积实现得不好,速度非常慢,而且大大增加了参数量,所以我没有用,我发现用普通的卷积效果就不错额
-
-
11楼
xubokun1992 2016-04-11 09:46发表
-
-
楼主你好,我最近也在学习研究deepid。我目前也在caffe的平台上做这个,关于deepid1的版本论文:Deep learning face representation from predicting 10000 class,这个应该是你复现的版本。我想请教一下,论文中提到的在第三层卷积层的的权值局部共享(locally shared in every 2*2 regions),然后在第四层全部不共享(totally unshared),您是怎么实现的?我看您在con3、con4的定义中没有什么特别的地方,还是说您在pathon代码中实习的?
还是说您没有加这两个特性,发现跑出来的结果也还不错?
-
10楼
csuwujiyang 2016-04-05 15:25发表
-

-
博主您好,看评论中您说输入的图像是55x47,那这个尺寸是如何计算得到的呢?谢谢!
-
Re:
天妒WS 2016-04-06 09:58发表
-
-
回复u013078356:CASIA-Webface的人脸尺寸大约在55像素左右,考虑到人脸是类似矩形的,而且DeepID论文中也是55*47的,所以这里就用的55*47,这种尺寸的人脸包含的背景较少哦。
-
Re:
csuwujiyang 2016-04-06 14:30发表
-
-
回复a_1937:还有一个问题就是,我看了一下您的网络结构定义,应该就是deepid2论文中的定义结构吧,那么第二个池化层pool2的stride不应该也是2吗,为什么你的是1呢?
-
Re:
天妒WS 2016-04-06 14:36发表
-
- 回复u013078356:原始论文中,pooling层的stride的确全部是2,这里是因为当时一时疏忽,而且,我自己做实验发现,pool2得stride设为1要比stride2的识别率高,这应该是因为增加了网络参数所致的吧。你也可以直接设为2呢。
-
-
-
-
9楼
qq_31557779 2016-03-29 14:44发表
-

-
您好我做完了对齐,在将图像数据转换为lmdb的时候我有10575类人的图像,难道要针对每一个人都写一条语句吗?有没有批量转换的方法?
-
Re:
天妒WS 2016-03-30 21:09发表
-
-
回复qq_31557779:转化lmdb有现成的转化程序啊/
-
Re:
qq_31557779 2016-04-06 09:10发表
-
- 回复a_1937:您好,能加一下您的QQ吗?有些问题还想向您请教,麻烦您了。
-
-
-
8楼
班长管班干部 2016-03-25 20:51发表
-

-
请问博主的prepare_deepId_data_dif('CASIA-Webface/','dataset', 20, True)中的20指什么
-
Re:
天妒WS 2016-03-28 13:23发表
-
- 回复xuhang0910:20指的是确保每类图片不得少于20张
-
-
7楼
qq_31557779 2016-03-24 10:30发表
-
-
您好,我是一名本科生,本科毕业设计要做这个东西,我现在caffe配置好了,也申请到了李子青团队的人脸数据,但是现在很迷茫,不知道接下来该怎么做,能给些意见吗?
-
Re:
天妒WS 2016-03-24 11:24发表
-
- 回复qq_31557779:先按照deepID论文用sdm进行人脸对齐,然后可以参考本文给出的网络结构进行训练。然后就可以得出一个还算过得去的识别率。
-
-
6楼
qq_31557779 2016-03-24 10:29发表
-
- 您好,我是一名本科生,本科毕业设计要做这个东西,我现在caffe配置好了,也申请到了李子青团队的人脸数据,但是现在很迷茫,不知道接下来该怎么做,能给些意见吗?
-
5楼
qq_31557779 2016-03-24 10:28发表
-
- 您好,我是一名本科生,本科毕业设计要做这个东西,我现在caffe配置好了,也申请到了李子青团队的人脸数据,但是现在很迷茫,不知道接下来该怎么做,能给些意见吗?
-
4楼
班长管班干部 2016-03-21 00:17发表
-
-
请问博主的prepare_deepId_data.py是干什么的?就是生成train.txt和val.txt的吗?
第2个问题是,我一直不明白DeepID产生的特征后训练分类器的是哪部分代码?
-
3楼
Nan_cy 2016-03-07 16:53发表
-

-
你好,我用的是CASIA-Webface,这个数据库共10575类,人脸数据是自己对齐成55x47大小的RGB图像,按照楼主的网络结构训练,但不收敛,不知道为什么,望赐教,在此谢谢了!
-
Re:
qq_31557779 2016-03-29 14:52发表
-
- 回复shixiaoli1094:您好我也在做这方面的东西,有些不懂的可以向您请教一下吗?我做完图像对齐后,要将图像数据转换为lmdb的时候我有10575类人的图像,难道要针对每一个人都写一条语句吗?有没有批量转换的方法?
-
-
2楼
xgbhk2 2016-02-26 09:10发表
-

-
你好,文中说到:
让训练集的每一类数目完全一样,比如我的实验中为训练集每个人50张图片。
怎么我拿到的数据集里只有2500个人左右有超过50张图片?你用的是webface里面的normalize face中扩展加入mirror的那一部分吗?即便用那个翻倍了之后我用你的程序跑也没有10499类,是我哪里搞错了吗?-
Re:
天妒WS 2016-03-01 18:24发表
-
- 回复xgbhk2:我用的是CASIA-Webface,这个数据库共10575类,每一类很不均衡,当时我训练的时候,没有多少经验,所以训练的时候训练集的类别不至于数量太不均衡。其实你可以忽略这篇博客的数据组织方式。我后来的数据组织方式是,将10575类中每一类随机拿出2张图片作为验证集,然后其余的全部作为训练集,然后训练,然后在lfw上的结果是(joint bayesian)96.22%。
-
-
1楼
nuohanfengyun 2016-01-21 09:29发表
-

- 你好,我使用你搭建的网络进行训练,为什么训练不收敛呢?麻烦大神不吝赐教,谢谢!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









