






最近,公司业务上对长文本的需求显著增加,因为在 prompt 中需要塞入大量的 RAG 内容,供决策使用。这些召回的内容都有可能在决策过程中被用到,因此对大模型处理长文本的能力提出了更高的要求。在技术选型时,特别需要重点考察模型在处理长文本方面的表现。
在总结收集各家大模型的“长文本”能力时,测试了市面上几款主流大模型,我发现它们普遍存在两个主要不足:
首先,有些模型能够处理的文本长度仍然有限。尽管某些大模型已将文本处理能力提升至 20 万字,但面对像《红楼梦》这样接近百万字的名著,仍然需要多次处理才能完整“阅读”完毕。
其次,这些模型的语言理解和生成能力尚显不足,常常会出现“幻觉”现象。“长文本”的挑战不仅在于字数的庞大,还涉及复杂的逻辑关系和文本语义的连贯性,因而需要更为流畅、紧密相关的响应能力。
就在前几天,一位从事 AIGC 领域的老同学向我透露:“智谱 AI 开放平台低调上线了一款专为处理超长文本和记忆型任务设计的 GLM-4-Long 模型,支持高达 100 万字的上下文处理。”
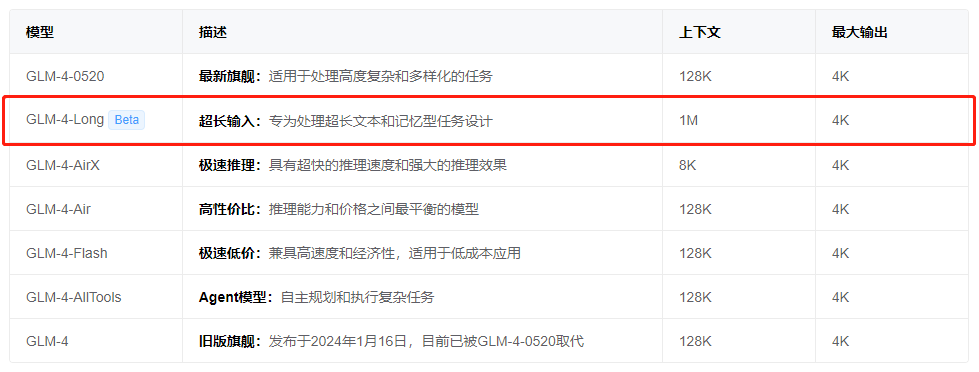
我的天!100万字的上下文长度究竟意味着什么呢?举个简单的例子,《红楼梦》大约是 73 万字,月之暗面 128K 的大模型,每次可以处理 6.4 万个汉字,需要 12 次才能读完;Claude 200K 的大模型,每次可以处理 10 万个汉字,需要 8 次才能读完;而 GLM-4-Long 实测可以处理 150-200 万字,一次就能读完一本《红楼梦》。
话不多说,我们直接来开箱体验一下 GLM-4-Long 到底有没有那么强!
体验地址:https://bigmodel.cn/
搭建本地 GLM-4-Long 大模型对话控制台
作为开发者,在线的调试和体验总是感觉少了点意思,我们完全可以自己在本地搭建自己的应用,直接调用 GLM-4-Long 大模型 API。
1. 获取 API
注册、登录之后,进入控制台,点击右上角菜单栏的”API 密钥“,就可以看见自己的 API 密钥了。
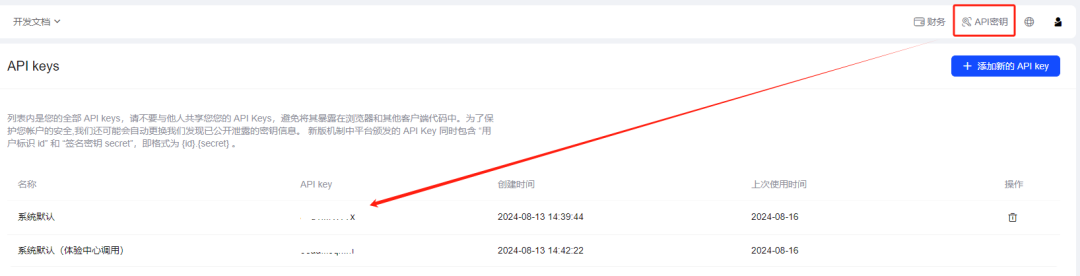
这里不得不提一下,智谱还是大气,现在注册即可获得 2500 万 Tokens 免费使用。差不多能帮你读 30 本《红楼梦》啦~

2. 本地搭建 zhipuai 开发环境
幸运的是,官方提供了 Python SDK, 我们可以直接一行命令安装 SDK:
pip install zhipuai
pip install --upgrade zhipuai3. 开箱实测 GLM-4-Long 长文本能力
在选择长文本内容时,我挑选了近期 Lex Fridman 对马斯克的采访播客文本。这段播客时长达 8 个半小时,目前在油管上的播放量已经超过 300 万次。内容极其丰富,但由于篇幅过长,很难一口气看完啊~

这不,正巧 Lex Fridman 提供了采访的文本记录(Transcript),大约 15 万 tokens,正好是 txt 格式的,我们就可以用它来试试 GLM-Long 处理长文本的能力!
4. Python SDK 创建 Client
API 有了,长文本也有了。下一步就是在本地编写自己的应用啦!我选择使用 GLM-Long 模型,设置多轮对话模式,我也不藏着掖着了,完整代码直接给到大家:
import os
from zhipuai import ZhipuAI
def load_document(file_path):
"""加载文档内容"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件 {file_path} 不存在")
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def query_model(document_content, question, api_client):
"""向大模型发送问题,并根据文档内容进行回答"""
prompt = (
f"基于以下文档内容回答问题,如果文档中没有相关描述,请告知。\n\n"
f"文档内容:\n{document_content}\n\n"
f"问题: {question}\n"
)
response = api_client.chat.completions.create(
model="glm-4-long", # 使用的模型名称
messages=[{"role": "user", "content": prompt}],
)
return response.choices[0].message.content.strip()
def main():
file_path = "Lex_Fridman.txt" # 替换为您的文档路径
document_content = load_document(file_path)
api_client = ZhipuAI(api_key="xxxx") # 替换为您的API Key
print("欢迎进入多轮对话模式。您可以根据文档内容提问,输入 '退出' 来结束对话。")
while True:
user_question = input("请输入您的问题: ")
if user_question.lower() in ['退出', 'exit', 'quit']:
print("对话已结束。")
break
answer = query_model(document_content, user_question, api_client)
print(f"回答: {answer}\n")
if __name__ == "__main__":
main()注意,将 api_key 替换成你自己的。
代码写完了,本地直接运行 python 脚本,进行测试:

我们输入第一个问题:帮我总结这篇文档的主要内容。
GLM-Long 的反映时间还是很快的,差不多 10s 的时间,就给我输出答案了:

再来看看 GPT-4o 的回答:

有一说一,GLM-Long 侧重回答了 Neuralink,而 GPT-4o 的回答没有突出侧重点。所以我更喜欢 GLM-4-Long 这样的回答。
再来问第二个细节问题:根据文档内容概括一下 Neuralink 的潜在应用有哪些。

再来看看 GPT-4o 的回答:

两者各有千秋吧,但是 GLM-Long 提到的娱乐和意识研究,GPT-4o并没有回答出来。
GLM-4-Long 的大海捞针能力
1. 制定大海捞针方案
1大模型的“大海捞针”能力就是它能在大量数据中快速找到你需要的关键信息。就像在一堆内容里迅速找到一根针一样,它可以从海量信息中准确提取出最有用的部分。
GLM-Long 的“大海捞针”指标达到了 128K,可以同时“看到”这么多内容,在大量信息中找到你需要的关键点。128K 以内全绿,做到 100% 精准召回:
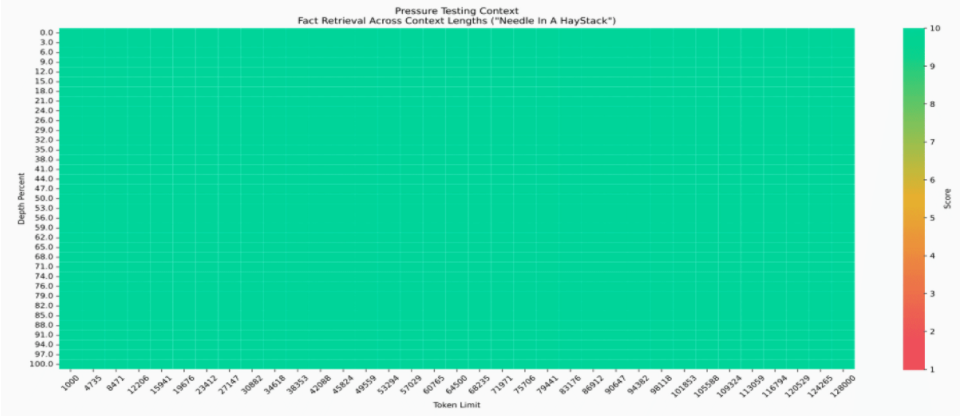
值得一提的是:目前,“大海捞针”存在两个主要问题:首先,许多测试题目只需关注一句话就能得出答案,而不需要考虑所有插入的文本内容,这使得测试的全面性受到影响。其次,许多题目在训练阶段已经多次出现,无论文本长度或内容为何,模型都能够轻松回答,这削弱了测试的实际挑战性和有效性。
下面我们来实测一下 GLM-Long 的大海捞针能力到底如何。为了更精确地进行测试,我们需要进行以下调整:首先,在推理过程中必须全面考虑所有可能的插入点,确保没有任何遗漏。其次,确保测试的内容是大模型尚未学习过的全新信息。
我最终选择的方案是这样:将近四届奥运会中国队获得的金牌、银牌、铜牌、奖牌总数信息,分为 16 段,分别插入到《红楼梦》全文中的各个位置,让 GLM-Long 把这些信息找出来,并整理给我。
2. Python SDK 创建 Client
编写测试脚本:
import os
from zhipuai import ZhipuAI
def load_text(file_path):
"""加载文本文件内容"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件 {file_path} 不存在")
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def distribute_insert_positions(text_length, items_count):
"""计算插入位置,使得插入内容在文本中均匀分布"""
if items_count == 0:
return []
interval = max(1, text_length // (items_count + 1))
return [interval * (i + 1) for i in range(items_count)]
def build_medal_statements(gold, silver, bronze, total):
"""构建奖牌统计语句"""
statements = []
for i in range(max(len(gold), len(silver), len(bronze), len(total))):
if i < len(gold):
statements.append(f"中国队获得了 金牌 {gold[i]} 枚。")
if i < len(silver):
statements.append(f"中国队获得了 银牌 {silver[i]} 枚。")
if i < len(bronze):
statements.append(f"中国队获得了 铜牌 {bronze[i]} 枚。")
if i < len(total):
statements.append(f"中国队获得了 奖牌总数 {total[i]} 枚。")
return statements
def insert_statements_into_text(text, statements, positions):
"""将生成的句子插入到文本的指定位置"""
text_parts = []
last_position = 0
for position, statement in zip(positions, statements):
text_parts.append(text[last_position:position])
text_parts.append(f"\n{statement}\n")
last_position = position
text_parts.append(text[last_position:])
return ''.join(text_parts)
def process_medal_data(file_path, gold_data, silver_data, bronze_data, total_data):
"""主处理函数,读取文件并插入奖牌信息"""
original_text = load_text(file_path)[:1024 * (1024 - 2)]
medal_statements = build_medal_statements(gold_data, silver_data, bronze_data, total_data)
insert_positions = distribute_insert_positions(len(original_text), len(medal_statements))
updated_text = insert_statements_into_text(original_text, medal_statements, insert_positions)
return updated_text
if __name__ == "__main__":
file_name = "HongLouMeng.txt"
gold_medals = [39,26,38,40]
silver_medals = [31,18,32,27]
bronze_medals = [22,26,19,24]
total_medals = [92,70,89,91]
# 构建提示信息
instruction = (
"请你根据如下文本,整理中国队获得的金银铜牌数。输出格式:"
"{\"金牌数\":[x,x,x,...],\"银牌数\":[x,x,x,...],\"铜牌数\":[x,x,x,...],\"奖牌总数\":[x,x,x,...]}"
"[x,x,x,...]中对应的奖牌数,仅以JSON格式输出结果,不需要输出任何解释。下面是文本:\n"
)
modified_content = process_medal_data(file_name, gold_medals, silver_medals, bronze_medals, total_medals)
print(f"处理后的文本长度: {len(modified_content)}")
# 调用API
api_client = ZhipuAI(api_key="xxxx") # 替换为您的API Key
response = api_client.chat.completions.create(
model="glm-4-long",
messages=[{"role": "user", "content": instruction + modified_content}],
)
print(response.choices[0].message.content)以上代码中,我们将奥运奖牌数总信息切分成 16 段,均匀插入到《红楼梦》全文中,以考验 GLM-Long 真正的大海捞针能力!
用这个脚本测试进行测试:
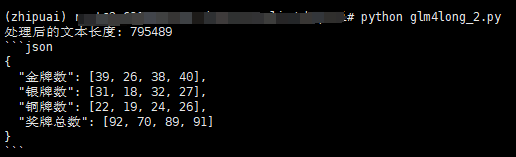
完全答对了!要知道,《红楼梦》整本书的字符数达到了 80 万,对应的 tokens 数量还不足 100 万。然而,GLM-4-long 的处理能力却达到了 100 万 tokens,这确实令人惊叹。换句话说,它相当于可以同时处理两本《红楼梦》的内容,简直可以说是达到了“一目万行”的程度。
GLM-4-Long 百万上下文的能力从何而来?
我很好奇,GLM-4-long 百万上下文的能力到底从何而来?直到看到了他们技术团队介绍了如何逐步实现百万级上下文,归纳起来就是四个字:拾级而上!

1M 的上下文处理能力并非一朝一夕就能实现,而是经过了多个阶段的逐步优化和激活,才能最终具备并维持模型在长文本处理上的卓越性能。
在基础模型通过预训练阶段完成后,技术团队进行了两次关键的上下文长度扩展。首先,将上下文长度从 8k 扩展至 128k,随后再次扩展至 1M。在 SFT 阶段,技术团队特别收集了针对长文本的 SFT 数据,并与通用 SFT 数据进行混合训练。从报告中可以看出,技术团队在长文本处理方面确实投入了大量精力,不仅在技术上取得了显著进展,还积累了丰富的实践经验。
总结
以上就是本次对 GLM-4-long 模型的开箱体验,整体感觉该模型的上下文处理能力表现得非常稳定可靠,生成效果也达到了预期水准。
GLM-4-Long 不仅功能没得说!最为关键的是,现在价格非常实惠,100 万 tokens 仅需1元。
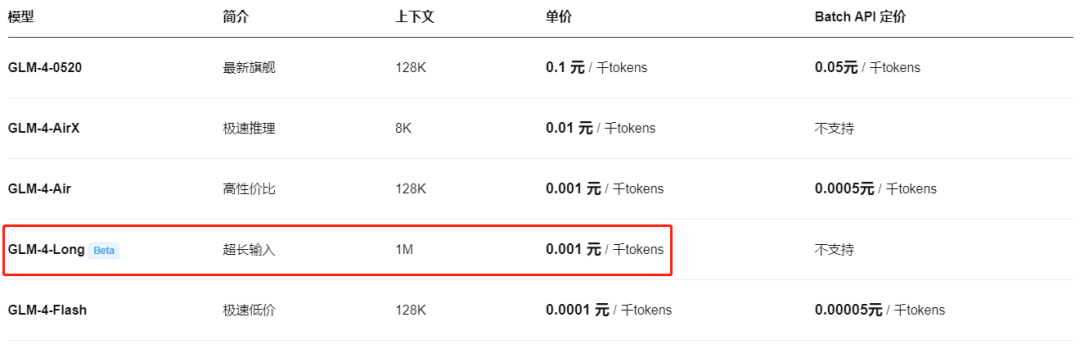
作为一款百万级上下文处理模型,GLM-4-long 在性价比方面尤为突出,值得大家亲自体验一番~
体验地址:https://bigmodel.cn/
点击阅读原文,立即获取 API 额度👇


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











