






很神奇,本来以为经理让我们连接微信公众号和niagara,本来以为微信公众号的url是阿里云,疯狂配置好久之后,看了网课才想到阿里云部署有点麻烦,我实属草鸡。像我可以做好久的测试,然后这一下部署一次,我觉得真的会炸,好吧,其实我也不知道这返回的值在哪。
用了内网穿透的方法。跟着网课也连上了token。说明java 用tomcat部署的方法有效
开始niagara,在n4中创建一个module,这个真的让我炸了,路径小王子疯狂找不到路径。但是发现artifacts没有servlet,就知道问题出在哪里,疯狂配置artifacts。
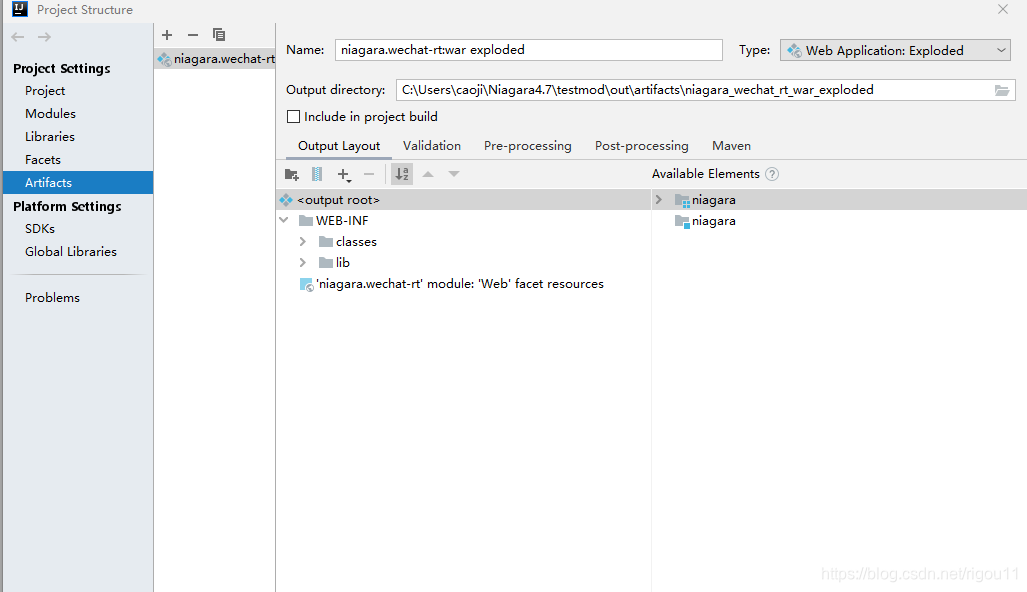
要创建一个classes ,一个lib,WEB-INF
module创造的啥也没有,所以这些都是要自己配啊!
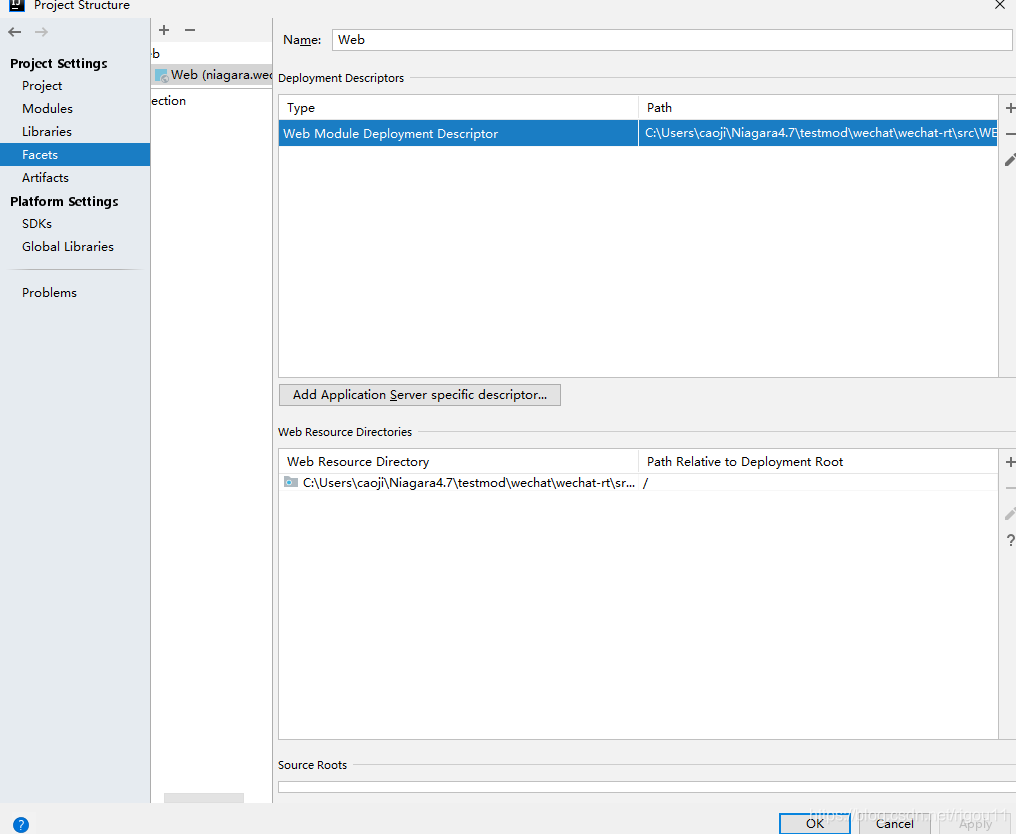
这是一个定位到web.xml 下面是定位到web-inf
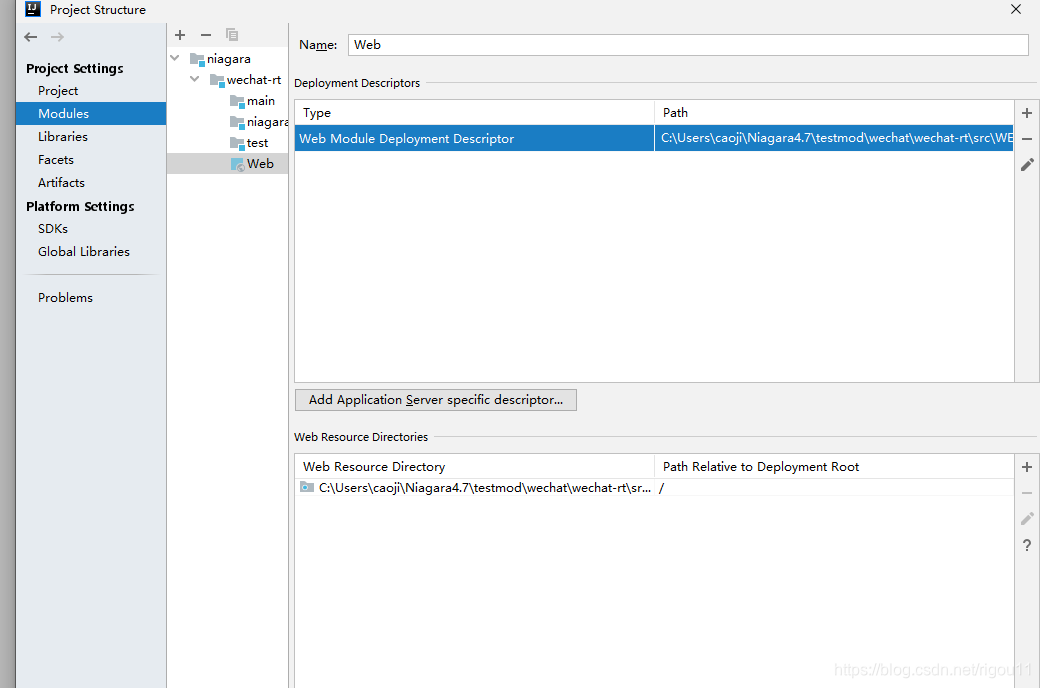
记得要在module中加入一个web
真的在module中啥也没有
那个web.xml 要是不知道怎么写,就去tomcat那边conf中找web.xml
重点看了社区此才知道,要是要入jar包等第三方中加一句话
compileOnly group: 'javax.servlet', name: 'javax.servlet-api', version:'4.0.1'
可见多看文档的重要性
我突然想到niagara要用80端口
也不知道为啥,他写的竟然500了 太难了!
后记
感觉这几天终于有了成果,草鸡真的是喜悦万分,哈哈哈哈哈,冲冲冲。要多看文档,不然真的啥也不知道,要静下心来,就可以知道问题来自哪里。就算遇到问题也不要害怕,解决了这个问题,大不了还有一个更大的问题,但是解决完之后,就是成功了呀!哈哈哈哈,草鸡又要开始冲冲冲!
好了,要多多看那个代码了,毕竟人家给了那么多的举例代码,加油草鸡。你是最棒的。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









