







SVM SVM 学习笔记第四篇
Soft-Margin Support Vector Machine
这篇介绍的是 Soft-Margin SVM Soft-Margin SVM ,也就是再将 SVM S V M 做一些变化,或者是针对 Hard-Margin SVM Hard-Margin SVM 做一些改进, 放宽 SVM SVM 的限制,可以允许存在一些误分类的点。
0 - 回顾
在上一篇中介绍了对偶形式的 Kernel SVM Kernel SVM ,在对偶 SVM SVM (从某个角度来说,对偶形式的 SVM S V M 得到了 primal SVM p r i m a l S V M 的內积形式)中利用核函数可以很方便的解决很复杂的非线性问题,例如使用高斯核函数可以在无限维度的空间中寻找超平面。但是正如我们之前说到过的,高斯 SVM S V M 在参数选择的不恰当的时候,也会出现 overfit o v e r f i t 的情况。为什么 SVM S V M 也会出现过拟合的情况呢(虽然有最大间隔的保证)?一个原因可能是因为我们选择的特征转化太过于 powerful p o w e r f u l ,就算存在最大间隔的限制,最终也还是会出现过拟合。另外一个原因是因为我们坚持要把正例和负例完美的分开,导致会被一些噪声点影响。
1 - 容忍一些噪声
现在我们知道了 hard SVM h a r d S V M 可能由于要求完全正确的划分正例和负例而被一些噪声点影响导致过拟合,那么回想一下,以前我们是怎么处理这些噪声数据的呢?
1.1 - pocket算法
在
pocket
p
o
c
k
e
t
算法中,由于数据不是线性可分的,所以我们真的没有办法找到一条线将数据完美的分开,所以我们退而求其次:找一条线,这条线在数据上犯的错误最少。即我们想要最小化如下的式子:
这里: 1=|[◯]| 1 = | [ ◯ ] | ,如果 ◯ ◯ 成立; 0=|[◯]| 0 = | [ ◯ ] | ,如果 ◯ ◯ 不成立。
1.2 - 硬间隔支撑向量机
而我们之前提到的 hard margin SVM h a r d m a r g i n S V M 如下:
即要求所有的样本点都要正确划分,并且在这个基础上找到间隔最大的。
1.3 - pocket + hard margin SVM
结合 pocket p o c k e t 算法对错误的容忍和 SVM S V M 算法对于间隔最大化的要求得到如下的模型( soft margin SVM s o f t m a r g i n S V M ):约束中的第二个条件表明允许存在一些点不满足原来的 SVM S V M 的要求,即 yn(wTxn+b) y n ( w T x n + b ) 可以小于 1 1 ;但是要尽量减少这样的点,这一目标体现在我们的中: minw⋯+C∑Nn=1|[yn≠sign(wTzn+b)]| m i n w ⋯ + C ∑ n = 1 N | [ y n ≠ s i g n ( w T z n + b ) ] | , 即要最小化犯错误的数据的个数。那么现在我们不仅仅想要 w w 的长度最小,这是为了保证最大,而且想要犯错误的点的数量最少,所以引入了参数 C C 来权衡两者之间的关系,表示两者之间的相对重要性。比较大的时候表示我们想要犯更少的错误, C C 比较的小的时候表示我们想要更大的间隔。
1.4 - 软间隔支撑向量机
软间隔支撑向量机可以理解为我们牺牲了在某些点上必须正确划分的限制,来换取更大的分隔间隔。
上述软间隔
SVM
S
V
M
的表达可以合并为下式:
上述模型存在缺点:
- 因为 |[◯]| | [ ◯ ] | 不是一个线性运算,所以上述问题不再是一个二次规划问题,这样的话就不可以使用之前所介绍的 dual,Kernel d u a l , K e r n e l 的机制。
- 对所有的错误一视同仁,不区分犯错的数据点离分隔超平面的远近。
为了解决这些问题,尤其是第二个问题,我们提出了下面的新的和上面想法类似的软间隔 SVM S V M 表达方式,在这种新的表达方式中,首先可以区分小错和大错,其次可以保证还是一个 QP Q P 问题,软间隔支持向量机的原始形式:
在这里,我们把错误记录在一个 ξn(ξn≥0) ξ n ( ξ n ≥ 0 ) 当中。这个变量记录了 (xn,yn) ( x n , y n ) 犯了多大的错。然后在目标函数中最小化 ∑Nn=1 ξn ∑ n = 1 N ξ n 。事实上,当 yn(WTxn+b)≥1 y n ( W T x n + b ) ≥ 1 , 说明该样本点划分正确,因为要最小化所有的 ξn ξ n 的和,所以可得 ξn=0⟶ ξ n = 0 ⟶ 该样本没有犯错;如果 yn(WTxn+b)<1 y n ( W T x n + b ) < 1 , 说明该样本点没有划分正确, ξn=1−yn(WTxn+b)⟶ ξ n = 1 − y n ( W T x n + b ) ⟶ 该样本犯了 1−yn(WTxn+b) 1 − y n ( W T x n + b ) 的错。
- 假如 y1(wTz1+b)=−10 y 1 ( w T z 1 + b ) = − 10 , 那么相应的 ξ1= ? ξ 1 = ? ⟶ ⟶ ξ1=10+1=11 ξ 1 = 10 + 1 = 11
经过这样的变化,新的问题就变成了一个 QP(linear constraints and quadratic objective) Q P ( l i n e a r c o n s t r a i n t s a n d q u a d r a t i c o b j e c t i v e ) 问题。这样一来,我们将 pocket p o c k e t 和 SVM S V M 融合在一起的这个不好解决的问题通过变形变成了比较熟悉的形式。
我们将 ξ ξ 称为 margin violation m a r g i n v i o l a t i o n 。参数 C C 用来权衡间隔和 ∑Nn=1ξn ∑ n = 1 N ξ n
- C C 大表明我们更 care c a r e 的是划分的正确性, margin m a r g i n 可以“瘦”一点,但是划分错误的点要少一点。
- C C 小表明我们想要的是更“胖”一点的边界,划分错误的点多一点没有关系。
现在这个问题变成了一个标准的 QP Q P 问题,变量有 d~+1+N d ~ + 1 + N 个,限制条件有 2N 2 N 个。
2 - 对偶问题
通过上面的分析得到了 soft s o f t - margin SVM m a r g i n S V M ,即我们允许有一些误分类的点存在以使得 margin m a r g i n 足够的大,或者说避免拟合 noise n o i s e 。现在推导该问题的对偶问题。得出了对偶问题就可以很方便的使用特征转化。
2.1 - 软间隔支持向量机的原始形式
2.2 - 拉格朗日函数
引入拉格朗日乘子得到如下的拉格朗日函数:需要注意的是,先把条件转换为 ≤ ≤ 的形式。
接下来就可以使用 max min m a x m i n 来得到对偶问题,然后使用 KKT condition KKT condition 来做简化。
2.3 - 拉格朗日对偶
首先对
ξn
ξ
n
求偏导使其为
0
0
,这是根据得到的,最优解要满足对原始问题中的每一个变量的微分为
0
0
。
也就是说在最佳解上,
αn+βn
α
n
+
β
n
要等于
C
C
, 即:
那么就可以把式子中的所有的 β β 替换掉,只剩下 αn α n (这样是为了长的和原来的 hard h a r d - margin m a r g i n 的对偶问题的形式比较像): βn=C−αn β n = C − α n 。因为 αn≥0, βn≥0 α n ≥ 0 , β n ≥ 0 ,所以可以得到 C≥αn≥0 C ≥ α n ≥ 0 。
那么可以整理为:
这样我们就去掉了式子中的
ξn
ξ
n
和
βn
β
n
。得到了简单的形式:
这个时候我们发现里面的最小化问题是和硬间隔 SVM S V M 中的对偶问题中的形式一毛一样的。那么同样的我们可以对 b b 偏导,得到。然后对 w w 求导可以得到。
最后我们可以得到一个标准的软间隔的 SVM S V M 的对偶问题如下。
2.4 - 软间隔支持向量机的对偶形式
Standard Soft-Margin SVM DUAL
Standard Soft-Margin SVM DUAL
唯一和硬间隔 SVM S V M 不同的是 αn α n 有一个上界 C C 。
3 - 软间隔SVM中隐藏的信息
3.1 - 软间隔SVM+Kernel
在得到了软间隔的对偶形式之后,我们就可以使用之前讨论的 kernel k e r n e l 函数来做更多的事情。 Kernel Soft-Margin SVM Kernel Soft-Margin SVM 算法如下:
- qn,m=ynymK(xn,xm);p=−1N;(A,c) q n , m = y n y m K ( x n , x m ) ; p = − 1 N ; ( A , c )
- α⟵QP(QD,p,A,c) α ⟵ Q P ( Q D , p , A , c )
- b=? b = ?
- 返回支撑向量
SVs
S
V
s
和与之相对应的
αn
α
n
,还有参数
b
b
,那么就得到了带有核函数的软间隔分类器:
这样看来,软间隔和硬间隔的 SVM S V M 几乎是一样的,相对于硬间隔来说,软间隔更加灵活一点,因为我们可以通过调节 C C 的值来控制我们更加关心的是分隔超平面的间隔大一点,还是分类错误的点少一点。并且不再要求我们的数据是线性可分的。所以软间隔通常要比硬间隔更加的有实际的应用价值。现在唯一的问题是偏置 的求法。
3.2 - b的求法
对于 hard margin SVM hard margin SVM ,根据 KKT K K T 条件,有 αn(1−yn(wTzn+b))=0 α n ( 1 − y n ( w T z n + b ) ) = 0 (我们把这样的条件称为 complementary slackness c o m p l e m e n t a r y s l a c k n e s s ),这样的话,我们只需要找到一个 αs≥0 α s ≥ 0 , 那么就可以得到 ys(wTzs+b)=1 y s ( w T z s + b ) = 1 ,从而得到 b=ys−wTzs b = y s − w T z s 。
同样的对于软间隔 SVM S V M 来说,我们也可以找到相应的 somplementary slackness s o m p l e m e n t a r y s l a c k n e s s 如下:
所以如果我们找到了一个支撑向量,也就是一个
αs≥0
α
s
≥
0
,那么根据第一个式子可以得到
1−ξn−yn(wTzn+b)=0
1
−
ξ
n
−
y
n
(
w
T
z
n
+
b
)
=
0
,进一步可以得到
b=ys−ysξs−wTzs
b
=
y
s
−
y
s
ξ
s
−
w
T
z
s
。
这个式子告诉我们如果想要求得
b
b
,就需要先知道,但是我们没有办法得到
ξs
ξ
s
。但是如果
ξs
ξ
s
是0的话,那么我们就可以得到
b=ys−wTzs
b
=
y
s
−
w
T
z
s
。要想让
ξs=0
ξ
s
=
0
, 那我们就要确保
C−αs≠0
C
−
α
s
≠
0
,即
C≠αs
C
≠
α
s
, 那就只能是
αs<C
α
s
<
C
。 我们把
αs<C
α
s
<
C
对应的支撑向量成为
free vector
f
r
e
e
v
e
c
t
o
r
。可知
free vector
f
r
e
e
v
e
c
t
o
r
对应的
ξs=0
ξ
s
=
0
。所以就成功的算出了
b=ys−wTzs
b
=
y
s
−
w
T
z
s
。
这样我们就终于得到了
b
b
的求法:
我们需要找一个,并且不是一般的
Support Vector
S
u
p
p
o
r
t
V
e
c
t
o
r
,而是
free support vector (xs,ys)
f
r
e
e
s
u
p
p
o
r
t
v
e
c
t
o
r
(
x
s
,
y
s
)
,这样的支撑向量对应的
C>αs>0
C
>
α
s
>
0
,这样就可以求解得到
b
b
:
3.3 - 使用高斯核的软间隔SVM的表现
Soft-Margin Gaussian SVM in Action Soft-Margin Gaussian SVM in Action
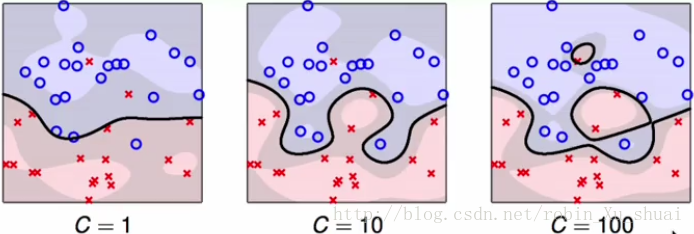
C C 越大,对噪声的容忍度就越小,就越容易。所以就算我们使用的是带有高斯核函数的软间隔 SVM S V M ,也是由可能会出现过拟合的情况,所以这就需要我们认真的挑选参数 (γ,C) ( γ , C ) , γ γ 是高斯核函数的参数, C C 是软间隔分类的的参数。
3.4 - 软间隔SVM背后的信息
我们之前使用了 complementary slackness c o m p l e m e n t a r y s l a c k n e s s (如下)成功的求解了参数 b b 。现在再来看看通过这两个条件我们可以得到什么关于soft-margin SVM的信息。
根据这两个条件,我们可以所有的数据点划分为三种:(根据 α α 的取值)
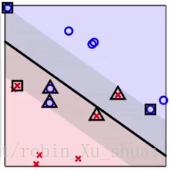
- non SV(0=αn) n o n S V ( 0 = α n ) : 因为 αn=0 α n = 0 ,所以 ξn=0 ξ n = 0 ,也就是对应着那些没有违反边界的点。所以这些点会离分割面很远,也有极少数的点可能在分隔边界上。
- free support vector(0<αn<C) f r e e s u p p o r t v e c t o r ( 0 < α n < C ) :因为 0<αn<C 0 < α n < C 所以 ξn=0 ξ n = 0 ,并且 1=yn(wTzn+b) 1 = y n ( w T z n + b ) , 即这些点正好是位于分隔边界上的点,如图中使用方框框起来的点。并且我们正是利用了这些点来求出了 b b 。
- :那么根据第一个条件, ξn=1−yn(wTzn+b) ξ n = 1 − y n ( w T z n + b ) ,这个时候 ξn ξ n 记录了该点“犯了多大的错”。如图中三角形的点。我们称这样的点为 bounded SV b o u n d e d S V ,这些点在边界上,或者是违反了边界。
思考题:
假设数据集的大小为10000,使用
soft margin SVM
s
o
f
t
m
a
r
g
i
n
S
V
M
之后,得到了1126个
SV
S
V
,其中有1000个
bounded SV
b
o
u
n
d
e
d
S
V
,那么
Ein(gSVM)
E
i
n
(
g
S
V
M
)
的取值范围是多少呢?
答案: 0.0000≤Ein(gSVM)≤0.1000 0.0000 ≤ E i n ( g S V M ) ≤ 0.1000 , 因为 bounded SV b o u n d e d S V 是可能会越界(也就是划分错误)或者正好在边界上的点,所以当这些 bounded SV b o u n d e d S V 都在边界上的时候, Ein(gSVM)=0 E i n ( g S V M ) = 0 ;当这些 bounded SV b o u n d e d S V 都越界了的时候, Ein(gSVM)=0 E i n ( g S V M ) = 0
4 - 模型的选择
4.1 - 各种参数下的表现
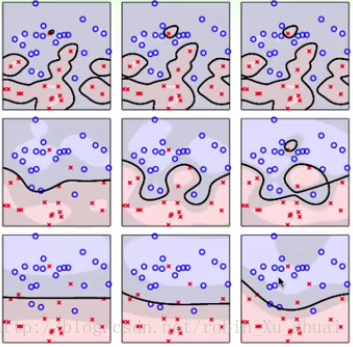
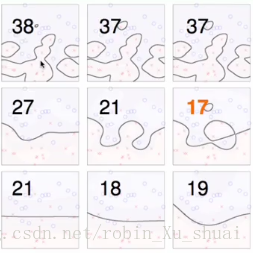
上图表示的是,在不同的参数 γ γ 和 C C 的选择下,使用在数据上的表现,从左到右为逐渐增大的 C C (要更少误分的点),从下到上为逐渐增大的(要更加复杂的特征)。
4.2 - 如何做出选择
通过计算比较交叉检验 cross validation c r o s s v a l i d a t i o n 的结果。
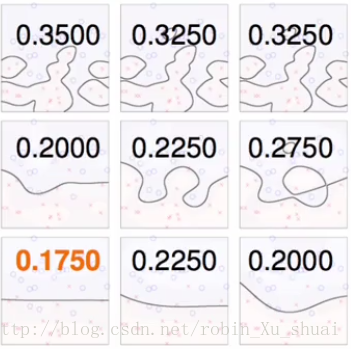
我们之前曾经讲过,如果将
cross validation
cross validation
应用到极致,那么就会得到另一种验证的方法:
leave
l
e
a
v
e
-
one
o
n
e
-
out Cross Validation
o
u
t
C
r
o
s
s
V
a
l
i
d
a
t
i
o
n
,也就是只留一笔资料做验证,其他的都做训练。
leave
l
e
a
v
e
-
one
o
n
e
-
out Cross Validation
o
u
t
C
r
o
s
s
V
a
l
i
d
a
t
i
o
n
在
SVM
S
V
M
上有一个很有趣的结果。
也就是说,如果有数据的资料量是1000,其中有100个SV,那么 Eloocv E l o o c v 会小于0.1。事实上,如果现在有 N=1000 N = 1000 笔资料,使用 SVM S V M 求解之后得到 (α1,α2,α3,⋯,αN) ( α 1 , α 2 , α 3 , ⋯ , α N ) 是最优解并且 αN=0 α N = 0 ,也就是说最后一笔资料不是支撑向量。那么如果将前999笔资料喂给 SVM S V M 算法还是会得到 (α1,α2,α3,⋯,αN−1) ( α 1 , α 2 , α 3 , ⋯ , α N − 1 ) 是新问题的最优解。也就是说, g−=g g − = g 当 leave out non l e a v e o u t n o n - SV S V 。所以 enon−SV=err(g−,non SV)=err(g,non SV)=0 e n o n − S V = e r r ( g − , n o n S V ) = e r r ( g , n o n S V ) = 0 , 而 eSV≤1 e S V ≤ 1
所以也可以使用
SV
S
V
的数量来进行模型的选择:
但是需要注意的是, SV S V 的数量首先不是连续的,其次这只是一个上限,通常可以使用这个方法来排除那些比较差的情形,即排除有太多的 SV S V 的模型。然后再剩下的比较好的模型中使用交叉验证来进行模型的选择。
5 - 总结
本篇记录了
SVM
S
V
M
的一个最常用的形式的
soft
s
o
f
t
-
margin SVM
m
a
r
g
i
n
S
V
M
的提出和求解,这个模型的出发点是,我们可以容忍一些错误的发生,即,可以容忍分隔超平面对某些点划分错误,所以我们在模型中引入了对错误的衡量,将其作为惩罚性加在目标方程中。新的模型同样是一个二次规划问题,所以我们推导了该问题的对偶问题,发现对偶问题和硬间隔的
SVM
S
V
M
几乎完全相同,不同的地方仅仅是
αn
α
n
有一个上界
C
C
。并且对偶问题的解使得我们可以将数据分为三类。这对于做资料的分析非常的有用。
这四篇是
soft
s
o
f
t
-
margin
m
a
r
g
i
n
的
SVM
S
V
M
的完整的讲解,从
hard
h
a
r
d
-
margin
m
a
r
g
i
n
的
SVM
S
V
M
,到对偶问题的导出,到引入核函数,最后到
soft
s
o
f
t
-
margin
m
a
r
g
i
n
。















 5562
5562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









