







机器学习中的多模态领域近年来取得了显著进展。能够处理图像、音频或视频以及文本(语言)的模型显著增多,特别是在Transformer模型的帮助下。
我们对现在的多模态按照架构模式分为四类:A、B、C、D。A和B类型在模型内部层中深度融合多模态输入,可以实现细粒度控制模态信息流动,但需要大量训练数据和计算资源;C和D类型在输入层融合多模态输入,C类型具有模块化设计,可以容易地添加更多模态。D类型使用标记化,可以方便地训练不同模态,但需要训练通用标记器。
按照不同架构模式跟踪多模态发展,里程碑如下:
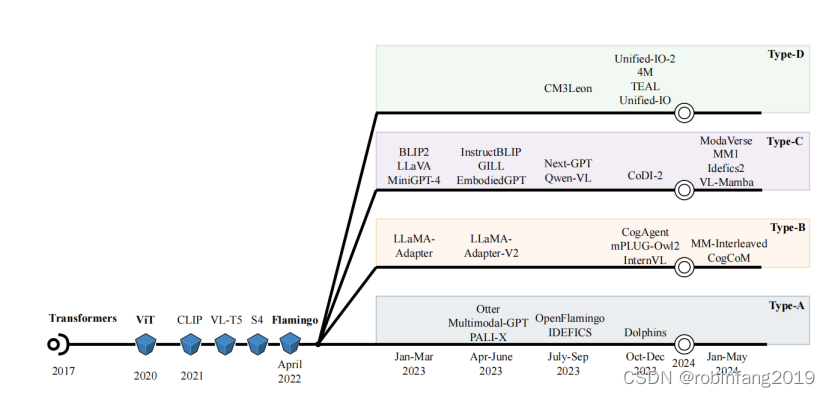
多模态发展里程碑
1、A型多模态模型
A类模型,即基于标准交叉注意力的深度融合(Standard Cross-Attention based Deep Fusion, SCDF)。
1.1 特点
- 内部层深度融合:该架构使用标准的Transformer模型,并在模型的内部层添加了标准的交叉注意力层,以实现输入多模态信息的深度融合。
- 不同模态输入编码:每个输入模态(图像、视频、音频等)都通过对应的编码器进行编码,然后将编码后的多模态特征输入到模型内部层。
- 跨模态特征融合:模型内部层通过标准的交叉注意力层对不同模态的特征进行融合,使模型能够同时处理多个模态的信息。
- 多模态解码器:通常采用只包含解码器的Transformer模型作为多模态解码器,用于生成多模态输出。
- 自回归生成:多模态解码器可以实现多模态输入的自回归生成,即生成多模态输出。
- 训练数据需求:需要大量多模态训练数据,计算资源需求较高。
- 添加模态困难:在模型内部层添加更多模态比较困难。
1.2 优势与不足
- A类型多模态模型具有多模态信息精细控制的优势。
- 计算资源需求较高,模型复杂,添加模态困难。
1.3 典型A类模型开源代码
- Flamingo
官方代码: https://github.com/flamingo-vl/flamingo
基于Transformer的多模态模型,可以处理图像和文本数据。
- OpenFlamingo
官方代码: https://github.com/openai/flamingo
开源的Flamingo模型的实现,提供了模型的复现。
- Otter
官方代码: https://github.com/microsoft/otter-generative
基于OpenFlamingo的多模态模型,可以处理图像和文本数据。
- MultiModal-GPT
官方代码: https://github.com/tuanvu2203/multimodal-gpt
基于OpenFlamingo的多模态模型,可以处理图像和文本数据。
- PaLI-X
官方代码: https://github.com/microsoft/PALI-X
多模态模型,可以处理图像、文本和视频数据。
- IDEFICS
官方代码: https://github.com/google/IDEFICS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









