






MMSegmentation 环境配置 + 制作自己的数据集 + 训练 + 预测
一、创建Window平台环境
1. 创建python 环境
conda create --name openmmlab2 python=3.8 -y
conda activate openmmlab2 // 激活环境
2. 安装pytorch
torch官方网站
访问torch网站,选择适合自己的pytorch版本,由于我这里使用的cuda是11.6,所以我安装以下版本,版本不对应,后面会有各种报错。
torch旧版本地址
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
感觉慢的可以通过清华镜像离线下载进行安装,
下载的时候下载对应的torch,torchvision,torchaudio
download.pytorch.org/whl/torch_stable.html
3. 安装MMCV
pip install -U openmim -i https://pypi.tuna.tsinghua.edu.cn/simple
mim install mmengine -i https://pypi.tuna.tsinghua.edu.cn/simple
mim install "mmcv>=2.0.0"
4. 安装 MMSegmentation.
D:
mkdir mmseg
cd mmseg
conda install git
git clone -b main https://github.com/open-mmlab/mmsegmentation.git
cd mmsegmentation
pip install -v -e .
# '-v' means verbose, or more output
# '-e' means installing a project in editable mode,
# thus any local modifications made to the code will take effect without reinstallati
如果不从源码编译可以直接安装:
pip install "mmsegmentation>=1.0.0"
5. 测试是否安装成功
mim download mmsegmentation --config pspnet_r50-d8_4xb2-40k_cityscapes-512x1024 --dest .
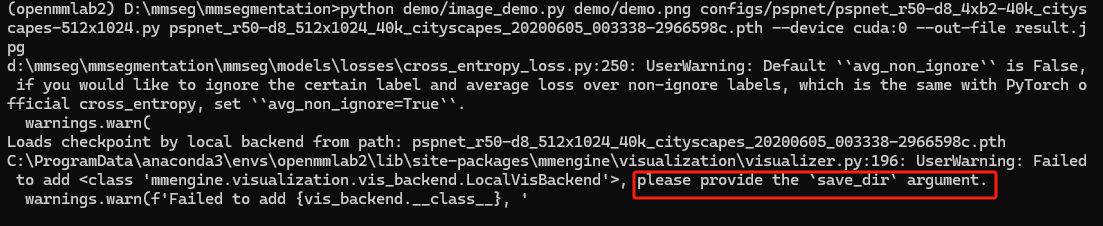
python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg
如果报numpy版本高,需要对numpy降版本
pip install numpy==1.26.4
出现AssertionError: MMCV==2.2.0 is used but incompatible. Please install mmcv>=2.0.0rc4.
安装对应的提示版本即可:
mim install "mmcv==2.0.0rc4"
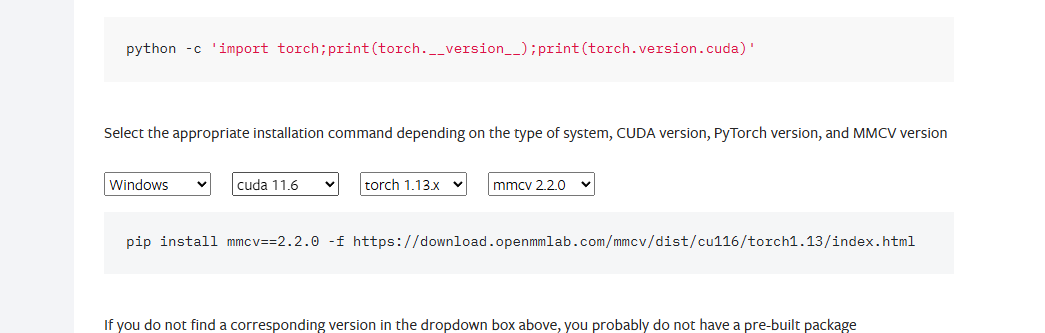
可以去下面这个网站,查找mmcv相应的版本:
mmcv官网
安装其他依赖
pip install ftfy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install regex -i https://pypi.tuna.tsinghua.edu.cn/simple
然后再运行这一句,就成功了:
python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg
运行的时候可能会出现如下错误:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll
already initialized.
搜索自己的安装位置,会有很多的 libiomp5md.dll, 删除一些就可以。
然后出现一下结果就可以了,这个报错是一个输入的问题,先不用管。
测试代码
from mmseg.apis import inference_model, init_model, show_result_pyplot
import mmcv
config_file = 'pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
checkpoint_file = 'pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
# build the model from a config file and a checkpoint file
model = init_model(config_file, checkpoint_file, device='cuda:0')
# test a single image and show the results
img = 'demo/demo.png' # or img = mmcv.imread(img), which will only load it once
result = inference_model(model, img)
# visualize the results in a new window
show_result_pyplot(model, img, result, show=True)
# or save the visualization results to image files
# you can change the opacity of the painted segmentation map in (0, 1].
show_result_pyplot(model, img, result, show=True, out_file='result.jpg', opacity=0.5)
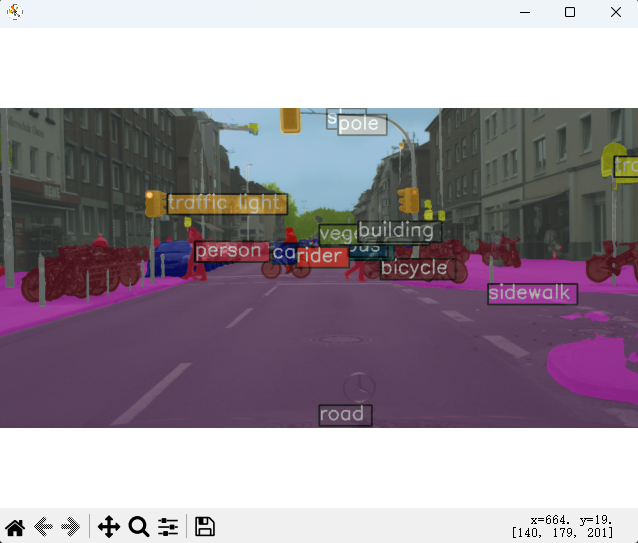
!!!至此,环境就配置完成了。
二、制作自己的数据
这里需要制作的数据格式为VOC的格式。
代码链接
1. 标注
我这里使用的是x-anylabeling软件,因为里面可以使用最新的SAM2.1,标注比较方便。
安装:
conda create --name x-anylabeling python=3.9 -y
conda activate x-anylabeling
pip install onnxruntime-gpu==1.14 -i https://pypi.tuna.tsinghua.edu.cn/simple
D:
mkdir LabelTool
cd LabelTool
conda install git
git clone https://github.com/CVHub520/X-AnyLabeling.git
cd X-AnyLabeling
pip install -r requirements-gpu-dev.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pyrcc5 -o anylabeling/resources/resources.py anylabeling/resources/resources.qrc
pip uninstall anylabeling -y
set PYTHONPATH=D:\LabelTool\X-AnyLabeling
python anylabeling/app.py
## 模型可以去网站上下载
把AI模型放到相应目录中 C:\Users\Administrator\xanylabeling_data\models\hyper_yolos-r20241216
使用
conda activate x-anylabeling
D:
cd D:\LabelTool\X-AnyLabeling
python anylabeling/app.py
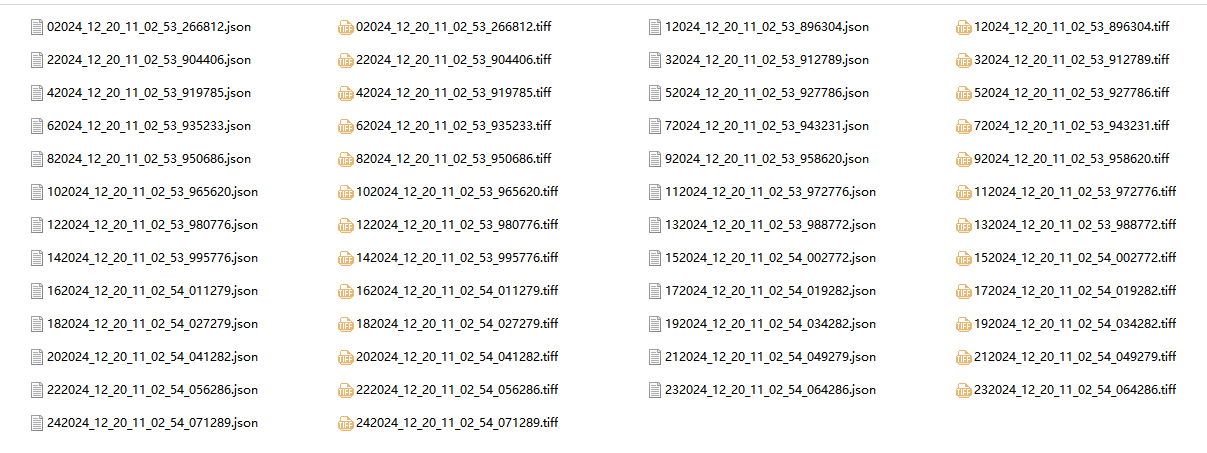
标注完之后的文件的文件格式如下:
2. 数据格式转换 Json 转换成 PNG
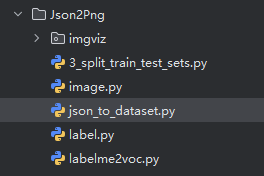
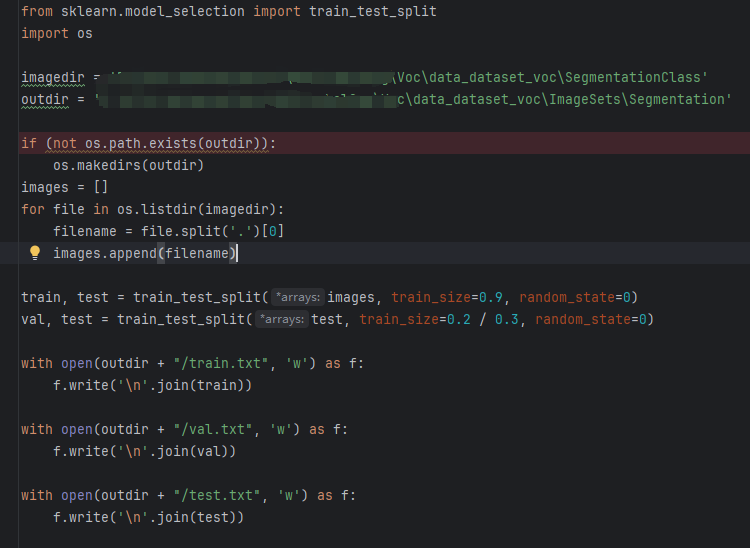
运行代码:labelme2voc.py
然后进行数据集划分:split_train_test_sets.py
需要修改的地方:
- json_to_dataset.py 添加自己的类别
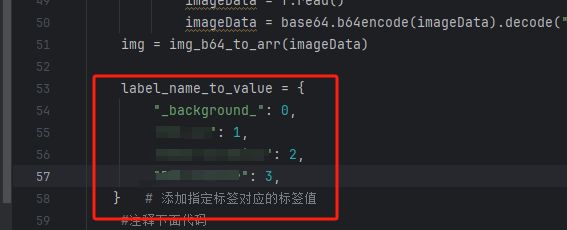
- label.py 中对应的RGB颜色,与标签对应
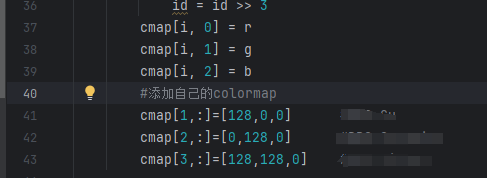
- labelme2voc.py 中的路径

- 还需要创建一个labels.txt,存放类别,_background_是背景,如果没有可以不加

- 运行后生成 labelme2voc.py格式如下:
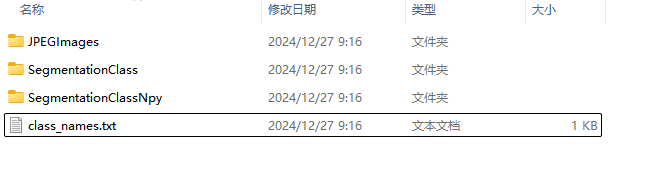
- 数据划分

三、MMSegmentation 模型设置
以voc为例,其需要修改的配置文件如下:
mmsegmentation\mmseg\datasets\myvoc.py
mmsegmentation\mmseg\datasets\\__init__.py
mmsegmentation\configs\_base_\datasets\myvoc12.py # 自己创建!!!
mmsegmentation\configs\_base_\models\deeplabv3plus_r50-d8.py
mmsegmentation\configs\deeplabv3plus\my_deeplabv3plus_r50-d8_4xb4-20k_voc12-512x512.py
1. mmsegmentation\mmseg\datasets\myvoc.py
# Copyright (c) OpenMMLab. All rights reserved.
import os.path as osp
import mmengine.fileio as fileio
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset
@DATASETS.register_module()
class MyVOCDataset(BaseSegDataset): # 改一下名称
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
METAINFO = dict(
classes=('_background_', "A", "B", "C"), # 改成自己的类别
palette=[[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0]]) # 与制作voc中的对应
def __init__(self,
ann_file,
img_suffix='.jpg',
seg_map_suffix='.png',
**kwargs) -> None:
super().__init__(
img_suffix=img_suffix,
seg_map_suffix=seg_map_suffix,
ann_file=ann_file,
**kwargs)
assert fileio.exists(self.data_prefix['img_path'],
self.backend_args) and osp.isfile(self.ann_file)
2. mmsegmentation\mmseg\datasets\init.py
# Copyright (c) OpenMMLab. All rights reserved.
# yapf: disable
from .ade import ADE20KDataset
from .basesegdataset import BaseCDDataset, BaseSegDataset
from .bdd100k import BDD100KDataset
from .chase_db1 import ChaseDB1Dataset
from .cityscapes import CityscapesDataset
from .coco_stuff import COCOStuffDataset
from .dark_zurich import DarkZurichDataset
from .dataset_wrappers import MultiImageMixDataset
from .decathlon import DecathlonDataset
from .drive import DRIVEDataset
from .dsdl import DSDLSegDataset
from .hrf import HRFDataset
from .hsi_drive import HSIDrive20Dataset
from .isaid import iSAIDDataset
from .isprs import ISPRSDataset
from .levir import LEVIRCDDataset
from .lip import LIPDataset
from .loveda import LoveDADataset
from .mapillary import MapillaryDataset_v1, MapillaryDataset_v2
from .night_driving import NightDrivingDataset
from .nyu import NYUDataset
from .pascal_context import PascalContextDataset, PascalContextDataset59
from .potsdam import PotsdamDataset
from .refuge import REFUGEDataset
from .stare import STAREDataset
from .synapse import SynapseDataset
from .myvoc import MyVOCDataset # 添加!!!
# yapf: disable
from .transforms import (CLAHE, AdjustGamma, Albu, BioMedical3DPad,
BioMedical3DRandomCrop, BioMedical3DRandomFlip,
BioMedicalGaussianBlur, BioMedicalGaussianNoise,
BioMedicalRandomGamma, ConcatCDInput, GenerateEdge,
LoadAnnotations, LoadBiomedicalAnnotation,
LoadBiomedicalData, LoadBiomedicalImageFromFile,
LoadImageFromNDArray, LoadMultipleRSImageFromFile,
LoadSingleRSImageFromFile, PackSegInputs,
PhotoMetricDistortion, RandomCrop, RandomCutOut,
RandomMosaic, RandomRotate, RandomRotFlip, Rerange,
ResizeShortestEdge, ResizeToMultiple, RGB2Gray,
SegRescale)
# yapf: enable
__all__ = [
'BaseSegDataset', 'BioMedical3DRandomCrop', 'BioMedical3DRandomFlip',
'CityscapesDataset', 'MyVOCDataset'-添加, 'ADE20KDataset',
'PascalContextDataset', 'PascalContextDataset59', 'ChaseDB1Dataset',
'DRIVEDataset', 'HRFDataset', 'STAREDataset', 'DarkZurichDataset',
'NightDrivingDataset', 'COCOStuffDataset', 'LoveDADataset',
'MultiImageMixDataset', 'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset',
'LoadAnnotations', 'RandomCrop', 'SegRescale', 'PhotoMetricDistortion',
'RandomRotate', 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray',
'RandomCutOut', 'RandomMosaic', 'PackSegInputs', 'ResizeToMultiple',
'LoadImageFromNDArray', 'LoadBiomedicalImageFromFile',
'LoadBiomedicalAnnotation', 'LoadBiomedicalData', 'GenerateEdge',
'DecathlonDataset', 'LIPDataset', 'ResizeShortestEdge',
'BioMedicalGaussianNoise', 'BioMedicalGaussianBlur',
'BioMedicalRandomGamma', 'BioMedical3DPad', 'RandomRotFlip',
'SynapseDataset', 'REFUGEDataset', 'MapillaryDataset_v1',
'MapillaryDataset_v2', 'Albu', 'LEVIRCDDataset',
'LoadMultipleRSImageFromFile', 'LoadSingleRSImageFromFile',
'ConcatCDInput', 'BaseCDDataset', 'DSDLSegDataset', 'BDD100KDataset',
'NYUDataset', 'HSIDrive20Dataset'
]
3. mmsegmentation\configs_base_\datasets\myvoc12.py
# dataset settings
dataset_type = 'MyVOCDataset' # 改成第一步中自己修改的类别
data_root = r'path\..\to\Voc\data_dataset_voc' # 自己数据集的路径
crop_size = (512, 512) # 裁剪尺寸,这里需要注意保持一致,可以修改成其他尺寸,但要和其他尺寸保持一致
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(
type='RandomResize',
scale=(1024, 256), # 2 * 512, 0.5 * 512
ratio_range=(0.5, 2.0),
keep_ratio=True),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='PackSegInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=(1024, 256), keep_ratio=True), # 保持一致
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations'),
dict(type='PackSegInputs')
]
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
tta_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(
type='TestTimeAug',
transforms=[
[
dict(type='Resize', scale_factor=r, keep_ratio=True)
for r in img_ratios
],
[
dict(type='RandomFlip', prob=0., direction='horizontal'),
dict(type='RandomFlip', prob=1., direction='horizontal')
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
])
]
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='InfiniteSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages', seg_map_path='SegmentationClass'),
ann_file='ImageSets/Segmentation/train.txt',
pipeline=train_pipeline))
val_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages', seg_map_path='SegmentationClass'),
ann_file='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
test_dataloader = val_dataloader
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
test_evaluator = val_evaluator
4. mmsegmentation\configs_base_\models\deeplabv3plus_r50-d8.py
这里主要是模型的一些参数,根据实际需要修改!
# model settings
norm_cfg = dict(type='SyncBN', requires_grad=True)
data_preprocessor = dict(
type='SegDataPreProcessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_val=0,
seg_pad_val=255)
model = dict(
type='EncoderDecoder',
data_preprocessor=data_preprocessor,
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='DepthwiseSeparableASPPHead',
in_channels=2048,
in_index=3,
channels=512,
dilations=(1, 12, 24, 36),
c1_in_channels=256,
c1_channels=48,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
5. mmsegmentation\configs\deeplabv3plus\my_deeplabv3plus_r50-d8_4xb4-20k_voc12-512x512.py
# 修改自己的对应文件
_base_ = [
'../_base_/models/deeplabv3plus_r50-d8.py',
'../_base_/datasets/my_voc12.py', '../_base_/default_runtime.py',
'../_base_/schedules/schedule_20k.py' # 训练时的参数设定
]
crop_size = (512, 512) # 保持一致
data_preprocessor = dict(size=crop_size)
model = dict(
data_preprocessor=data_preprocessor,
decode_head=dict(num_classes=4),
auxiliary_head=dict(num_classes=4)) # 改成自己的类别个数
四、MMSegmentation 训练
tools\train.y
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import logging
import os
import os.path as osp
from mmengine.config import Config, DictAction
from mmengine.logging import print_log
from mmengine.runner import Runner
from mmseg.registry import RUNNERS
def parse_args():
parser = argparse.ArgumentParser(description='Train a segmentor')
# 修改
parser.add_argument('--config',
default='../configs/deeplabv3plus//my_deeplabv3plus_r50-d8_4xb4-20k_voc12-512x512.py',
help='train config file path')
# 修改
parser.add_argument('--work-dir', default='../WorkDirs',help='the dir to save logs and models')
parser.add_argument(
'--resume',
action='store_true',
default=False,
help='resume from the latest checkpoint in the work_dir automatically')
parser.add_argument(
'--amp',
action='store_true',
default=False,
help='enable automatic-mixed-precision training')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
# When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
# will pass the `--local-rank` parameter to `tools/train.py` instead
# of `--local_rank`.
parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
return args
def main():
args = parse_args()
# load config
cfg = Config.fromfile(args.config)
cfg.launcher = args.launcher
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
# work_dir is determined in this priority: CLI > segment in file > filename
if args.work_dir is not None:
# update configs according to CLI args if args.work_dir is not None
cfg.work_dir = args.work_dir
elif cfg.get('work_dir', None) is None:
# use config filename as default work_dir if cfg.work_dir is None
cfg.work_dir = osp.join('./work_dirs',
osp.splitext(osp.basename(args.config))[0])
# enable automatic-mixed-precision training
if args.amp is True:
optim_wrapper = cfg.optim_wrapper.type
if optim_wrapper == 'AmpOptimWrapper':
print_log(
'AMP training is already enabled in your config.',
logger='current',
level=logging.WARNING)
else:
assert optim_wrapper == 'OptimWrapper', (
'`--amp` is only supported when the optimizer wrapper type is '
f'`OptimWrapper` but got {optim_wrapper}.')
cfg.optim_wrapper.type = 'AmpOptimWrapper'
cfg.optim_wrapper.loss_scale = 'dynamic'
# resume training
cfg.resume = args.resume
# build the runner from config
if 'runner_type' not in cfg:
# build the default runner
runner = Runner.from_cfg(cfg)
else:
# build customized runner from the registry
# if 'runner_type' is set in the cfg
runner = RUNNERS.build(cfg)
# start training
runner.train()
if __name__ == '__main__':
main()

运行成功
五、MMSegmentation 测试
测试代码如下
from mmseg.apis import init_model, inference_model, show_result_pyplot
config_path = 'configs/deeplabv3plus/my_deeplabv3plus_r50-d8_4xb4-20k_voc12-512x512.py'
checkpoint_path = 'WorkDirs/iter_2000.pth'
img_path = 'demo/5.tiff'
model = init_model(config_path, checkpoint_path)
result = inference_model(model, img_path)
# 展示分割结果
vis_image = show_result_pyplot(model, img_path, result)
# 保存可视化结果,输出图像将在 `workdirs/result.png` 路径下找到
vis_iamge = show_result_pyplot(model, img_path, result, out_file='work_dirs/result.png')
# # 修改展示图像的时间,注意 0 是表示“无限”的特殊值
# vis_image = show_result_pyplot(model, img_path, result, wait_time=5)


















 2349
2349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









