







cycleGAN理论讲解:
论文地址:https://arxiv.org/pdf/1703.10593.pdf
cycleGAN适用于非配对的图像到图像转换,cycleGAN解决了需要对数据进行训练的困难。
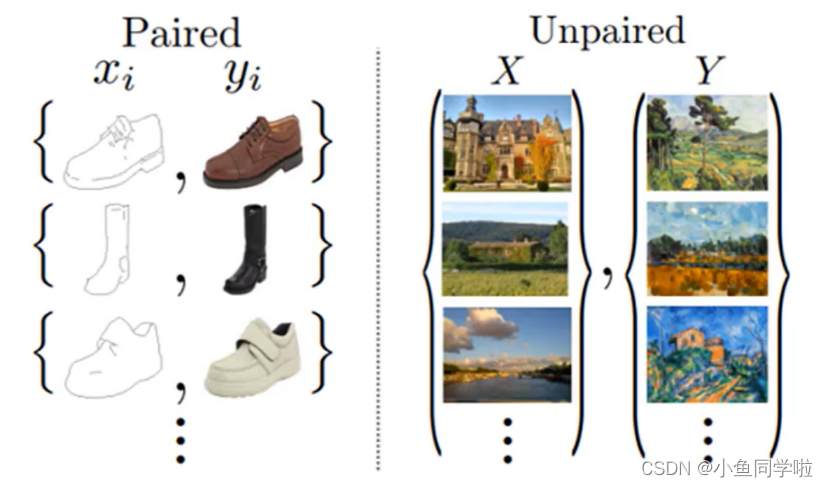
可以看到上图中左边是配对图片,鞋子的素描和鞋子的真实图片为一对。右边为非配对图片,X是真实图片,Y是油画风格图片。
CycleGAN的原理可以概述为:将一类图片转换成另一类图片。也就是说,现在有两个样本空间,X 和 Y, 我们希望把 X 空间中的样本转换成 Y 空间中的样本。可以理解为一种风格上的转换。
这样来看:实际的目标就是学习从 X 到 Y 的映射。我们假设这个映射为F。他就对应着GAN中的生成器,F可以将X中的图片x转换为Y中的图片F(x)。对于生成的图片,我们还需要GAN中的判别器来判别它是否为真实图片,由此构成对抗生成网络。
CycleGAN的整体架构:
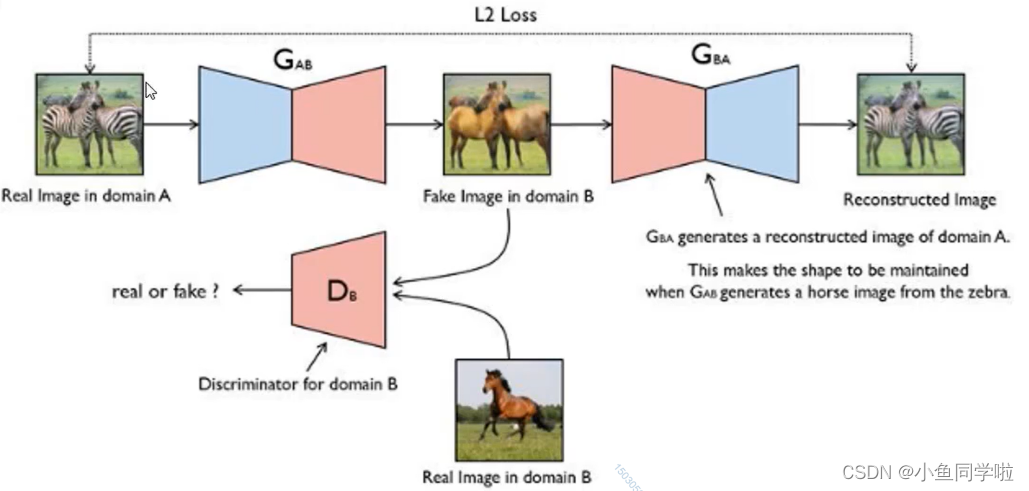
关于损失函数:
这里有一个问题是在足够大的样本容量下,网络可以将相同的输入图像集合映射到目标域中图像的任何随机排列,其中任何学习的映射可以归纳出与目标分布匹配的输出分布。换句话说,映射F完全可以将所有 X 都映射为 Y 空间中的同一张图片,是的损失无效化。因此单独的对抗损失Loss不能保证学习函数可以将单个输入 Xi 映射到期望的输出 Yi。对此,论文作者提出了所谓的”循环一致性损失“(cycle consistency loss)
循环一致损失:
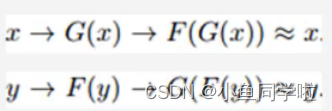
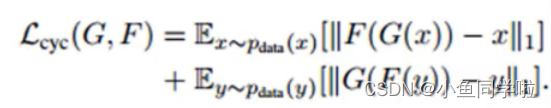
还有一个identity loss:
可以理解为,生成器是负责域 X 到 域 Y 的图像生成,如果输入域Y的图片还是应该生成域Y的图片y‘’,计算 y‘’ 和 输入y 的loss。
总损失:
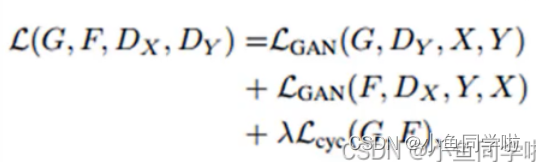
训练结果:


epoch = 1


epoch = 15


epoch = 30


epoch = 45
导入的库:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
from torch.utils import data
import matplotlib.pyplot as plt
import glob
from PIL import Image
import itertools
import numpy as np训练代码:
# 准备训练数据集
mans_path = glob.glob("data/man_woman/trianA/*.jpg")
print(len(mans_path))
plt.figure(figsize=(12, 8))
for i, man_path in enumerate(mans_path[:4]):
man_img = Image.open(man_path)
man_np_img = np.array(man_img)
plt.subplot(2, 2, i + 1)
plt.imshow(man_np_img)
plt.title(str(man_np_img.shape))
plt.show()
womans_path = glob.glob("data/man_woman/trainB/*.jpg")
print(len(womans_path))
plt.figure(figsize=(12, 8))
for i, woman_path in enumerate(womans_path[:4]):
woman_img = Image.open(woman_path)
woman_np_img = np.array(woman_img)
plt.subplot(2, 2, i + 1)
plt.imshow(woman_np_img)
plt.title(str(woman_np_img.shape))
plt.show()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((256, 256)),
transforms.Normalize(0.5, 0.5)
])
class MW_dataset(data.Dataset):
def __init__(self, img_path):
self.img_path = img_path
def __getitem__(self, index):
imgpath = self.img_path[index]
pil_img = Image.open(imgpath)
pil_img = transform(pil_img)
return pil_img
def __len__(self):
return len(self.img_path)
man_dataset = MW_dataset(mans_path)
woman_dataset = MW_dataset(womans_path)
BATCHSIZE = 4
man_dl = data.DataLoader(man_dataset, batch_size=BATCHSIZE, shuffle=True)
woman_dl = data.DataLoader(woman_dataset, batch_size=BATCHSIZE, shuffle=True)
man_batch = next(iter(man_dl))
woman_batch = next(iter(woman_dl))
# 打印处理好的图片数据
fig = plt.figure(figsize=(8, 15))
for i, (m, w) in enumerate(zip(man_batch[:3], woman_batch[:3])):
m = (m.permute(1, 2, 0).numpy() + 1) / 2
w = (w.permute(1, 2, 0).numpy() + 1) / 2
plt.subplot(3, 2, 2 * i + 1)
plt.title("man")
plt.imshow(m)
plt.subplot(3, 2, 2 * i + 2)
plt.title("woman")
plt.imshow(w)
plt.show()
# 准备测试数据集
mans_path_test = glob.glob("data/man_woman/testA/*.jpg")
womans_path_test = glob.glob("data/man_woman/testB/*.jpg")
man_dataset_test = MW_dataset(mans_path_test)
woman_dataset_test = MW_dataset(womans_path_test)
man_dl_test = data.DataLoader(man_dataset_test, batch_size=BATCHSIZE, shuffle=True)
woman_dl_test = data.DataLoader(woman_dataset_test, batch_size=BATCHSIZE, shuffle=True)
# 定义下采样模块
class Downsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample, self).__init__()
self.conv_relu = nn.Sequential(
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1),
nn.LeakyReLU(inplace=True) # inplce=True:就地修改输入张量
)
self.bn = nn.InstanceNorm2d(out_channels) # 因为这里我们需要优化每一张图片,所以要用instancenorm2d
def forward(self, x, is_bn=True):
x = self.conv_relu(x)
if is_bn:
x = self.bn(x)
return x
# 定义上采样模块
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upconv1 = nn.Sequential(
nn.ConvTranspose2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.LeakyReLU(inplace=True) # inplce=True:就地修改输入张量
)
self.bn = nn.InstanceNorm2d(out_channels) # 因为这里我们需要优化每一张图片,所以要用instancenorm2d
def forward(self, x, is_drop=False):
x = self.upconv1(x)
x = self.bn(x)
if is_drop:
x = F.dropout2d(x)
return x
# 初始化生成器:6个下采样,5个上采样+1个输出层
# PS:实战中建议画出模型图,方便了解输入层和输出层的关系(U-net)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.down1 = Downsample(3, 64) # (64, 128, 128)
self.down2 = Downsample(64, 128) # (128, 64, 64)
self.down3 = Downsample(128, 256) # (256, 32, 32)
self.down4 = Downsample(256, 512) # (512, 16, 16)
self.down5 = Downsample(512, 512) # (512, 8, 8)
self.down6 = Downsample(512, 512) # (512, 4, 4)
self.up1 = Upsample(512, 512) # (512, 8, 8)
self.up2 = Upsample(1024, 512) # (512, 16, 16)
self.up3 = Upsample(1024, 256) # (256, 32, 32)
self.up4 = Upsample(512, 128) # (128, 64, 64)
self.up5 = Upsample(256, 64) # (64, 128, 128)
self.last = nn.ConvTranspose2d(128, 3,
kernel_size=3,
stride=2,
padding=1,
output_padding=1)
def forward(self, x):
x1 = self.down1(x)
x2 = self.down2(x1)
x3 = self.down3(x2)
x4 = self.down4(x3)
x5 = self.down5(x4)
x6 = self.down6(x5)
x6 = self.up1(x6, is_drop=True)
x6 = torch.cat([x6, x5], dim=1)
x6 = self.up2(x6, is_drop=True)
x6 = torch.cat([x6, x4], dim=1)
x6 = self.up3(x6, is_drop=True)
x6 = torch.cat([x6, x3], dim=1)
x6 = self.up4(x6)
x6 = torch.cat([x6, x2], dim=1)
x6 = self.up5(x6)
x6 = torch.cat([x6, x1], dim=1)
x6 = torch.tanh(self.last(x6))
return x6
# 初始化判别器(patchGAN) 输入anno+img(生成的或者真实的) concat
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.down1 = Downsample(3, 64) # (64, 128, 128) PS:这里输入的6:anno+img
self.down2 = Downsample(64, 128) # (128, 64, 64)
self.last = nn.Conv2d(128, 1, 3) # (1, 62, 62)
def forward(self, img):
x = self.down1(img)
x = self.down2(x)
x = torch.sigmoid(self.last(x)) # (batch, 1, 60, 60)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
# 创建两个生成器,两个判别器
gen_AB = Generator().to(device)
gen_BA = Generator().to(device)
dis_A = Discriminator().to(device)
dis_B = Discriminator().to(device)
# 定义损失函数 1.gan loss 2.cycle consistance 3.identity loss
bceloss = torch.nn.BCELoss()
l1_loss = torch.nn.L1Loss()
# 初始化优化器
gen_optimizer = torch.optim.Adam(
itertools.chain(gen_AB.parameters(), gen_BA.parameters()),
lr=2e-4,
betas=(0.5, 0.999)
)
dis_optimizer_A = torch.optim.Adam(
itertools.chain(dis_A.parameters(), gen_BA.parameters()),
lr=2e-4,
betas=(0.5, 0.999)
)
dis_optimizer_B = torch.optim.Adam(
itertools.chain(dis_B.parameters(), gen_BA.parameters()),
lr=2e-4,
betas=(0.5, 0.999)
)
# 画图函数
def generate_image(model, test_input):
predictions = model(test_input).permute(0, 2, 3, 1).detach().cpu().numpy()
test_input = test_input.permute(0, 2, 3, 1).cpu().numpy()
title_list = ["input", "output"]
display_list = [test_input[0], predictions[0]]
fig = plt.figure(figsize=(10, 6))
for i in range(2):
plt.subplot(1, 2, i + 1)
plt.title(title_list[i])
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis("off")
plt.show()
test_batch = next(iter(man_dl_test))
# 因为我们只用一张图片作为test_input,所以没有bartchsize,因此用unsquezze设置batchsize为0
test_input = torch.unsqueeze(test_batch[0], 0).to(device)
# 训练模型
D_loss = []
G_loss = []
best_gen_loss = float("inf")
EPOCH = 5
for epoch in range(EPOCH):
D_epoch_loss = 0
G_epoch_loss = 0
count = min(len(man_dl), len(woman_dl))
for step, (real_A, real_B) in enumerate(zip(man_dl, woman_dl)):
real_A = real_A.to(device)
real_B = real_B.to(device)
# 训练生成器(Generator)
gen_optimizer.zero_grad()
# identity loss
same_A = gen_BA(real_A)
same_A_loss = l1_loss(same_A, real_A)
same_B = gen_AB(real_B)
same_B_loss = l1_loss(same_B, real_B)
# gan loss 对抗损失
fake_A = gen_BA(real_B)
fake_A_output = dis_A(fake_A)
fake_A_output_loss = bceloss(fake_A_output, torch.ones_like(fake_A_output, device=device))
fake_B = gen_AB(real_A)
fake_B_output = dis_B(fake_B)
fake_B_output_loss = bceloss(fake_B_output, torch.ones_like(fake_B_output, device=device))
# cycle loss 循环一致损失
recovered_A = gen_BA(fake_B)
cycle_ABA_loss = l1_loss(recovered_A, real_A)
recovered_B = gen_AB(fake_A)
cycle_BAB_loss = l1_loss(recovered_B, real_B)
g_loss = (same_A_loss + same_B_loss + fake_A_output_loss + fake_B_output_loss + cycle_ABA_loss + cycle_BAB_loss)
g_loss.backward()
gen_optimizer.step()
# 训练判别器(Discriminator)
# 训练dis_A
dis_optimizer_A.zero_grad()
real_A_output = dis_A(real_A)
real_A_loss = bceloss(real_A_output, torch.ones_like(real_A_output))
fake_A_output = dis_A(fake_A.detach())
fake_A_loss = bceloss(fake_A_output, torch.zeros_like(fake_A_output))
dis_A_loss = real_A_loss + fake_A_loss
dis_A_loss.backward()
dis_optimizer_A.step()
# 训练dis_B
dis_optimizer_B.zero_grad()
real_B_output = dis_B(real_B)
real_B_loss = bceloss(real_B_output, torch.ones_like(real_B_output))
fake_B_output = dis_B(fake_B.detach())
fake_B_loss = bceloss(fake_B_output, torch.zeros_like(fake_B_output))
dis_B_loss = real_B_loss + fake_B_loss
dis_B_loss.backward()
dis_optimizer_B.step()
with torch.no_grad():
G_epoch_loss += g_loss.item()
D_epoch_loss += (dis_A_loss + dis_B_loss).item()
# 保存最好的模型
if G_epoch_loss < best_gen_loss:
best_gen_loss = G_epoch_loss
# 保存生成器的状态字典
torch.save(gen_AB.state_dict(), 'best_cycleGAN_model.pth')
with torch.no_grad():
D_epoch_loss /= count
G_epoch_loss /= count
D_loss.append(D_epoch_loss)
G_loss.append(G_epoch_loss)
print("Epoch:{}".format(epoch),
"g_epoch_loss:{}".format(G_epoch_loss),
"d_epoch_loss:{}".format(D_epoch_loss))
# if epoch % 5 == 0:
# generate_image(gen_AB, test_input)使用训练好的模型:
import os
import torch
import torchvision.utils
from torchvision import transforms
from PIL import Image
import torch.nn as nn
import torch.nn.functional as F
# 定义下采样模块
class Downsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample, self).__init__()
self.conv_relu = nn.Sequential(
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1),
nn.LeakyReLU(inplace=True) # inplce=True:就地修改输入张量
)
self.bn = nn.InstanceNorm2d(out_channels) # 因为这里我们需要优化每一张图片,所以要用instancenorm2d
def forward(self, x, is_bn=True):
x = self.conv_relu(x)
if is_bn:
x = self.bn(x)
return x
# 定义上采样模块
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upconv1 = nn.Sequential(
nn.ConvTranspose2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.LeakyReLU(inplace=True) # inplce=True:就地修改输入张量
)
self.bn = nn.InstanceNorm2d(out_channels) # 因为这里我们需要优化每一张图片,所以要用instancenorm2d
def forward(self, x, is_drop=False):
x = self.upconv1(x)
x = self.bn(x)
if is_drop:
x = F.dropout2d(x)
return x
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.down1 = Downsample(3, 64) # (64, 128, 128)
self.down2 = Downsample(64, 128) # (128, 64, 64)
self.down3 = Downsample(128, 256) # (256, 32, 32)
self.down4 = Downsample(256, 512) # (512, 16, 16)
self.down5 = Downsample(512, 512) # (512, 8, 8)
self.down6 = Downsample(512, 512) # (512, 4, 4)
self.up1 = Upsample(512, 512) # (512, 8, 8)
self.up2 = Upsample(1024, 512) # (512, 16, 16)
self.up3 = Upsample(1024, 256) # (256, 32, 32)
self.up4 = Upsample(512, 128) # (128, 64, 64)
self.up5 = Upsample(256, 64) # (64, 128, 128)
self.last = nn.ConvTranspose2d(128, 3,
kernel_size=3,
stride=2,
padding=1,
output_padding=1)
def forward(self, x):
x1 = self.down1(x)
x2 = self.down2(x1)
x3 = self.down3(x2)
x4 = self.down4(x3)
x5 = self.down5(x4)
x6 = self.down6(x5)
x6 = self.up1(x6, is_drop=True)
x6 = torch.cat([x6, x5], dim=1)
x6 = self.up2(x6, is_drop=True)
x6 = torch.cat([x6, x4], dim=1)
x6 = self.up3(x6, is_drop=True)
x6 = torch.cat([x6, x3], dim=1)
x6 = self.up4(x6)
x6 = torch.cat([x6, x2], dim=1)
x6 = self.up5(x6)
x6 = torch.cat([x6, x1], dim=1)
x6 = torch.tanh(self.last(x6))
return x6
print("00000000")
# 确保文件夹存在
output_folder = "output"
os.makedirs(output_folder, exist_ok=True)
# 初始化生成器模型
gen_AB = Generator()
# 加载保存的模型状态字典
gen_AB.load_state_dict(torch.load("best_cycleGAN_model.pth"))
# 初始化数据集
img_path = "input.jpg"
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((256, 256)),
transforms.Normalize(0.5, 0.5)
])
img = Image.open(img_path)
img = transform(img)
img = img.unsqueeze(0)
img = img
output = gen_AB(img).detach().cpu()
torchvision.utils.save_image((img + 1) / 2, os.path.join(output_folder, "output.jpg"))















 2841
2841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









