







现实生活中,除了人本身有两只眼睛可以通过双目视觉信息获取深度信息,我们很难方便的有如此稳定和精确的双目系统来测深度。最近接触到了AR.Drone的无人机,开放接口这种事情最喜欢了,似乎可以用深度信息来控制无人机的运动,不过介于无人机只有单目摄像头的限制,不得不转换思维,开始搜集论文研究如何用单目视觉信息来获取深度。
提取单目视觉信息的方式可以包括两种,基于静止的单张图像和基于运动的多张图像。
这篇是之前看了Andrew N.g.的05年ICML论文(High Speed Obstacle Avoidance using Monocular Vision and
Reinforcement Learning (ICML,2005)),做了一次组会分享的内容,希望基于此启发感兴趣的童鞋,之后会做更多方法和实验的跟进。

论文里解决的是玩具车的无人导航系统问题,实验提出的假设如上图所示:
1、玩具车行驶速度一般在5m/s,所以1s内发给玩具车的命令必须保证选择5m内没有障碍的方向行驶,当然可能1s内已经有多次计算,很多指令发出,这基于算法和图像传输效率。
2、外界环境是不规则的,论文在训练参数的时候所在的环境是一个灌木丛生,叶子随处可见,偶尔还有石凳的小花园,视觉系统的参数被训练好(论文里还使用了合成图像加入到训练数据里)之后,测试也同样是在这个花园,鄙人以为似乎有对环境建模的嫌疑。
3、实验采用了当下比较常见的硬件,包括摄像头和小型动力机。4、整个自动化控制系统是基于视觉处理和行车控制系统来完成的。
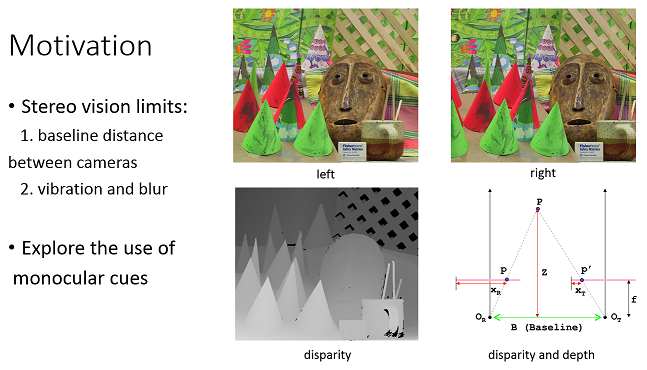
我们知道双目视觉系统,是通过左右两个对齐的摄像机的成像结果,基于极限约束计算视差图,再由几何关系得到深度数据的,但是这样做的局限是:1、两个摄像机的位置距离限制了深度数据的获取。2、由于抖动等不稳定因素使得两个摄像机的对齐困难。所以论文开始探索从单目视觉获取相关信息。
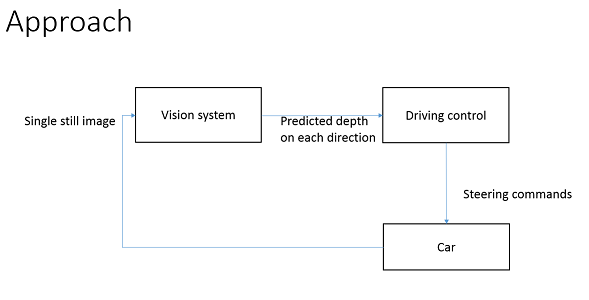
上图是这个方法的系统结构。参数训练好后,玩具车上的照片获取到图片,依次传到电脑上的视觉系统处理,输出在视野中每个方向的预测深度,到行车控制系统,输出导航命令(之间可能会通过一些控制动力机的底层操作系统接口来发出指令),从而玩具车按照指定的方向行动。

鄙人自认为才疏学浅,对于Driving Control的部分没有深入研究,如果有对此部分感兴趣的童鞋,可以
了解一些 model based reinforcement learning 的相关算法。本篇主要是对单目视觉系统的研究,今后也会陆续有其他相关算法和实验,无人机!俺来也!
上图简单描述了论文里采集训练数据的方法:
1、采集数据时使用了摄像头拍摄彩色图像和激光扫描仪测实际距离同时进行。
2、所有彩色图像被分割成16段竖条,每段都代表了可能的导航方向。
3、激光扫描仪对视野中的物体横向扫描,获取一维数据(这个数据应该调整到与相应图像中的16段数据对应,并且选取最近的深度距离作为图像每段数据的标签)。

一张静止的图像,有什么信息可以推测物体深度呢?上图说明了论文中提出的一些信息:纹理灰度变化和雾度,纹理梯度变化,物体的大小和遮挡,图片的整体信息。如上图所示,图片被分割成16段竖条,每段又用11个以50%重叠的窗口覆盖,每个窗口提取上述特征信息(论文里用到的是Laws灰度变化检测,Harris角点检测,Radon边缘检测的方法,在之后会详细说明,这篇我们先做基本的描述)。
假设每个窗口的特征维度是n,那么一段竖条(stripe)的特征维度是11xn,为了让特征能描述到整体的结构,论文中加入左右两边stripe的特征,所以最终一个stripe的特征维度是3x11xn。
下面说说为什么采用这些特征。

图片纹理的灰度变化表达了图片的能量:变化越频繁,能量越大,比如上图两个黄色矩形框的内容,左边的就右边的能量低,用斑点滤波和边缘滤波器可以得到这些特征。雾度顾名思义,就是起雾的程度,我们在现实生活中应该有所体会,放眼望去,越被雾气笼罩的部分往往越远离我们,用灰度均值滤波器可以检测到这种特征。

纹理的梯度变化包含了灰度变化的方向和这些方向的密度,比如上图离我们近的瓷砖,变化比较稀疏,离我们远的变化就比较密集,右边的群山图也是同样的道理,艺术家们常用这种方法让人有种处在三维空间的错觉。
论文对Harris角点检测方法进行改进,不是以前的比较灰度梯度变化方差矩阵的特征值相对大小,而是直接统计不同角度的特征向量对应的特征值,从而得到多个方向上灰度变化情况的分布。对与Radon变化也做了改进,找到最显著的直线的方向,加入纹理梯度变化的特征集合。

物体的空间分布也告诉我们很多信息。如图中桌球相互遮挡,前面的球能依次遮住后面的球。如果我们知道桌球的大小,那么在这个图中不同位置的桌球的不同大小也说明了其离我们的远近。这两种特征在论文中都用上文提到的整体结构信息描述方法来概括了,在Andrew N.g.的其他论文里还建立了同一图片,不同分辨率的之间的关系,能更好的表达整体信息。
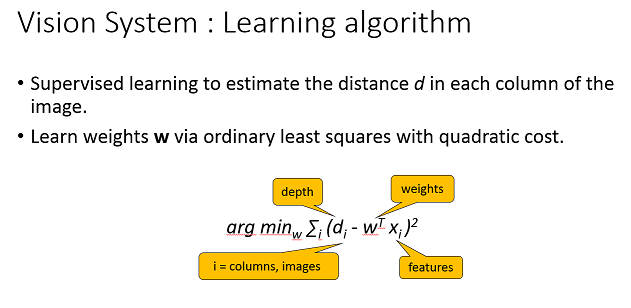
现在我们将一张静止图片中,每段竖条(代表可能的导航方向)的特征信息和实际深度(在这个导航方向上与小车最近的障碍物的距离)建立线性回归方程,特征的每一维都有相应的参数,优化参数使得通过方程预测得到的深度,和实际深度的均方误差和最小。这个过程的求解是可以通过伪逆矩阵直接计算,不用像线代课程里所讲的梯度下降法反复迭代来求最优解。

论文的这部分实验,把不同特征分成不同的特征集合,得到的预测深度和实际深度的误差期望(用对数是为了突出乘积误差,弱化加法误差),目前鄙人的实验还在进行中,和论文的数据跑出的结果基本接近,所以接下来可能尝试,用其他环境的数据来检验这个算法。
做完小组分享后,发现论文里的特征对环境依赖性很强,似乎还可以用现在很流行的深度学习算法来预测深度,不过事情要一步一步的做,重在学习过程是吧。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









