







hi,大家好~我是shadow,一枚设计师/全栈工程师/算法研究员,目前主要研究方向是人工智能写作和人工智能设计,当然偶尔也会跨界到人工智能艺术及其他各种AI产品。这是我发在《人工智能Mix》的一篇论文阅读笔记。

文末了解《人工智能Mix》
视觉常识R-CNN
Visual Commonsense R-CNN
给定图像中检测到的一组对象区域(例如,使用Faster R-CNN),就像其他任何无监督的特征学习方法(例如word2vec,可以捕捉到语言的上下文关系)一样,VC R-CNN的代理训练目标是预测对象的上下文对象。
VC R-CNN的预测是使用因果干预:P (Y | do(X )),而其他方法是使用常规可能性:P (Y | X )。

如上图所示,由于缺乏常识,不难发现机器所犯的“认知错误”。仅使用视觉功能,即基于流行的Faster R-CNN ,机器通常无法描述确切的视觉关系(图像生成字幕示例),或者即使如果预测正确,则潜在的视觉注意力不合理。
- VC R-CNN的架构
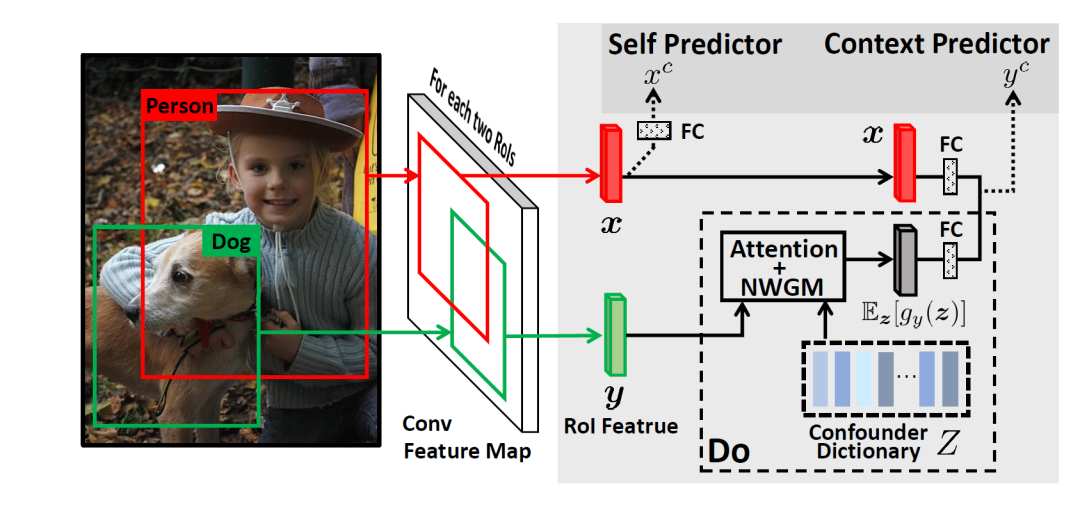 最核心的是Do-expression(因果模块),其中Confounder Dictionary 干扰因子字典存储了常识。如下图所示:
最核心的是Do-expression(因果模块),其中Confounder Dictionary 干扰因子字典存储了常识。如下图所示:
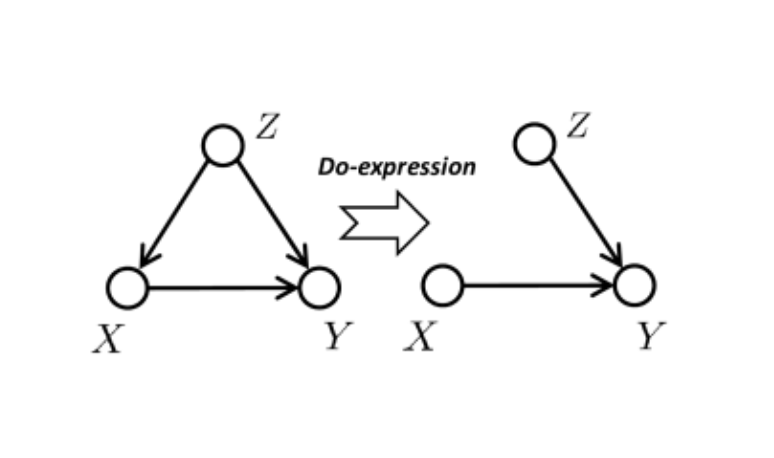
如何理解上图呢?我们的视觉世界存在许多干扰因素,从可能性只能学习到伪相关的P,如上左图。作者举了个例子,如下图
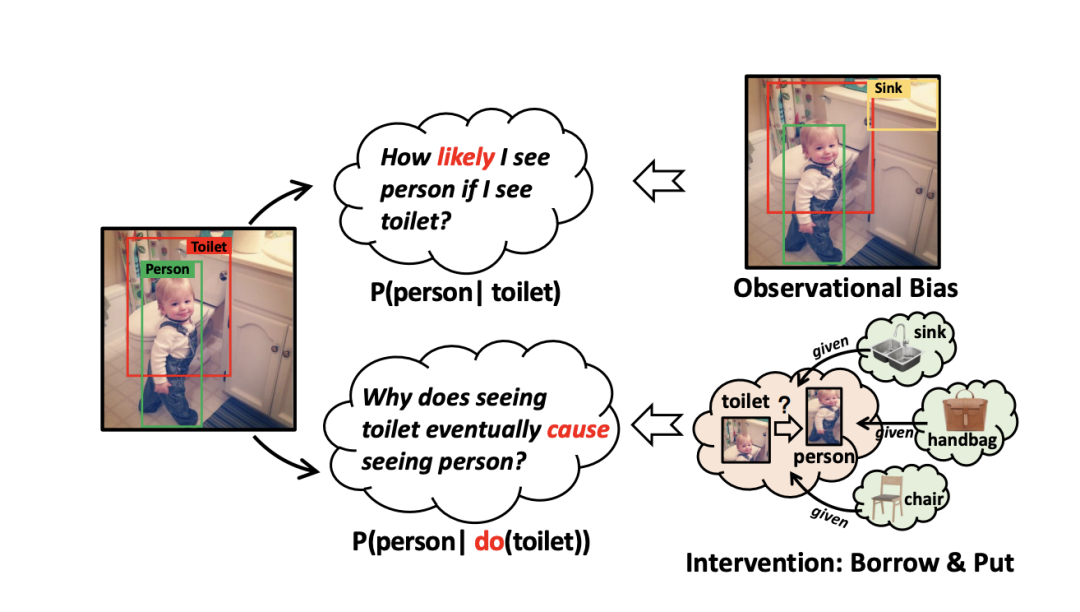
机器识别到了Person、Toilet,那到底是什么会紧跟着person跟Toilet这个场景的出现?是sink,还是hanbag?还是chair?有这么一个Confounder Dictionary,见下图:
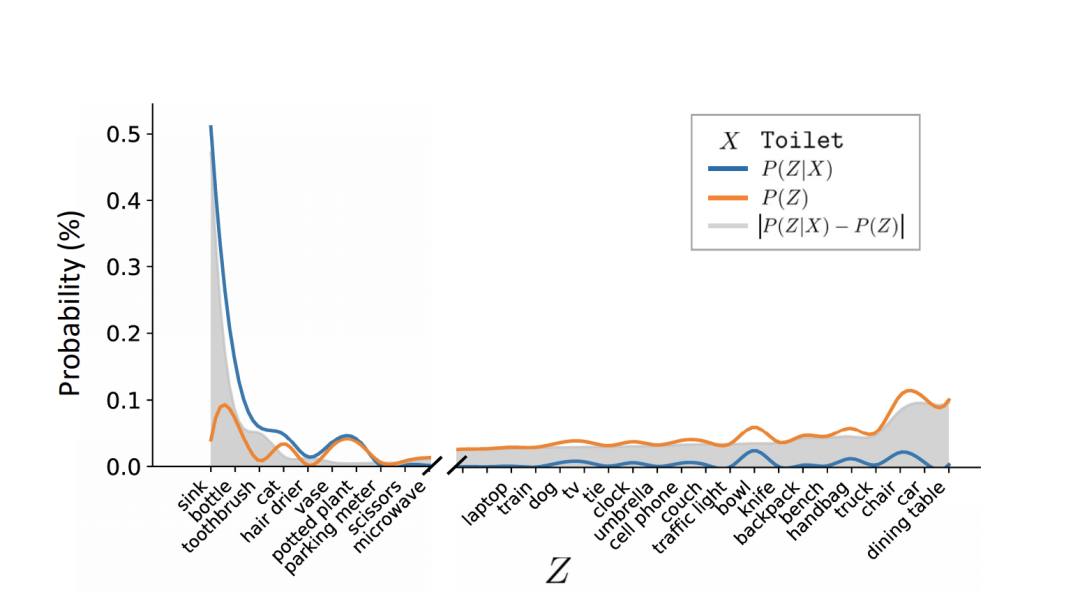
可见,
P(z=sink|X=toilet) > P(z=chair|X=toilet),
于是
P(Y =person|X=toilet,z=sink) >P(Y =person|X=toilet,z=chair)
这样机器就可以预测小孩在马桶边的下一个对象可能是什么。
原文地址:
https://arxiv.org/pdf/2002.12204.pdf
代码:
https://github.com/Wangt-CN/VC-R-CNN
作者解读:
https://zhuanlan.zhihu.com/p/111306353
更多内容,欢迎在专栏《人工智能MIX》中讨论。

即将恢复原价

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









