







简单介绍:
Kmeans聚类算法是通过计算各个数据点离簇中心的距离来进行分类的,即除了簇中心外每一个数据点都要计算离每一个簇中心(或者叫质心也行)的距离,然后将这个数据点分配到数据点离簇中心距离最小的那个簇的族群中,但由于簇中心的选择无法一次找到完美的中心(运气除外),就必须进行迭代,让簇中心不断的进行偏移矫正,然后产生新的族群,使得最终可以产生一个不错的分配结果。
算法特点:
Kmeans算法用于聚类,寻找族群,此种算法不依赖训练数据,按照机器学习的经验之谈,可称之为无监督学习方法,目前这种算法在业界广泛应用,可谓是各行开花。
Kmeans算法计算距离目前使用以下这三种:1)欧氏距离;2)闵式距离;3)曼哈顿距离也称为城市街区距离。
Kmeans算法的簇需要手动输入,也就是说,你想分成几类,必须指定出来。
迭代次数多少蛮看重运气的,毕竟随机选择质心。
新质心的选择可以使用加权平均的方法,且不需要一定是数据集合中存在的点。
基本是必定会收敛,如果没收敛,检查一下是不是程序写错了。
我这里使用欧式距离来进行计算推导,欧氏距离公式:
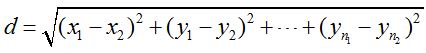
核心思想:
计算欧式距离进行归类
计算发生偏移寻找新的质心
计算误差是否可以结束
迭代以上内容
接下来我们用代码实现,代码实现思想如下:
1)数据源的产生(我这里使用随机数据)
2)簇的数量(分类数量是手动制定)
3)簇中心的选取(我这里使用随机选择)
4)计算各点与各簇中心的距离,进行初步的族群分配
5)通过加权平均进行新质心的找寻
6)判断迭代是否可以结束(结束条件为 :1、迭代次数用尽了,2、质心不再偏移或者偏移量小到可以接受)
7)画个图看看迭代效果
8)迭代次数(最大迭代次数自己制定即可)
使用到的库和全局变量定义如下:
from matplotlib import pyplot as plt
import numpy as np
#数据点的数量
PonitNum = 100
LowVal = 0
HighVal = 2000
#簇的数量
KVal = 1
#簇的坐标序列
KPoint = []
#数据集合
data_x = []
data_y = []
#簇的分类集合
KClassify = []
#簇的坐标
K_x = []
K_y = []
#旧的簇的坐标
K_ox = []
K_oy = []
def generate_data():
global data_x,data_y
data_x = np.random.randint(LowVal,HighVal,PonitNum)
data_y = np.random.randint(LowVal,HighVal,PonitNum)第二步,手动定义簇的数量:
#计算,k为簇的数量
def run(k=1):
global KVal
KVal = k
#随机生成簇的中心
def random_k_val():
global KPoint,K_x,K_y
KPoint = np.random.randint(LowVal,PonitNum,KVal)
for i in range( len( KPoint) ):
KClassify.append([KPoint[i]])
K_x.append(data_x[KPoint[i]])
K_y.append(data_y[KPoint[i]])
print(KPoint)
print(KClassify,K_x,K_y)第四步,计算个点与各个簇中心的距离(利用欧式距离):
#计算欧式距离
def calc_euclidean_distance(x1,y1,x2,y2):
return np.sqrt(np.square((x2 - x1)) + np.square((y2 - y1)))
#开始分类,将数据集合按照簇的数量分割
def classify_structure():
global KClassify
KClassify = []
print("初始化" + str( KClassify) )
for i in range(len(KPoint)):
KClassify.append([])
print(KClassify)
for i in range(PonitNum):
dis = []#储存各个簇和点的距离集合
isNext = False #判断是否跳过的标志
#判断当前坐标是否为簇的坐标,如果是的话,则跳过
for t in range(len(KPoint)):
if data_x[i] == K_x[t] and data_y[i] == K_y[t]:
isNext = True
print('簇中心,跳过,分配到对应族类中')
KClassify[t].append(i)
if isNext:
continue
#使用簇的数量进行计算
for m in range(len(KPoint)):
dis.append( calc_euclidean_distance(data_x[i],data_y[i],K_x[m],K_y[m]) )
index = dis.index(min(dis))#找到簇与点的的坐标距离最近,
# print(index) #分类结果
KClassify[index].append(i) #将对应坐标归到对应的簇的集合中
print('共有' + str(len(KPoint)) + "个簇")
print('分别是:')
for i in range(len(KPoint)):
print(KClassify[i])
print("----")
#求解每一组分类中新的质心
def find_new_centroid():
global K_x,K_y,K_ox,K_oy
K_ox = K_x
K_oy = K_y
K_x = []
K_y = []
for i in range(len(KPoint)):
new_x, new_y = calc_avg(KClassify[i])
K_x.append(new_x)
K_y.append(new_y)
print('新的质心为:' + str(K_x) + str(K_y) )
#计算平均值,求解新的质心坐标
def calc_avg(point):
sum_x = 0
sum_y = 0
len_p = len(point)
for m in point:
sum_x = sum_x + data_x[m]
sum_y = sum_y + data_y[m]
new_x = sum_x / len_p
new_y = sum_y / len_p
print('len' + str(len_p) )
return new_x,new_y
第七步,判断族群的分配是否结束(这里以新旧质心的坐标差值是否相近为判断机制):
#判断是否可以结束,判断旧的质心坐标和新的质心坐标差值是否相近,如果相近则迭代可以结束
def loop_over(loss_c = 0.5):
result = []
for i in range(len(KPoint)):
if abs(K_ox[i] - K_x[i]) <= loss_c and abs(K_oy[i] - K_y[i]) <= loss_c:
result.append(True)
else:
result.append(False)
if False in result: #无法结束
return False
else:#可以结束
return True第八步,绘图:
def show_pic():
color_range = ('red','cornflowerblue','lime','plum','yellow')
color_range_p = ('darkred','midnightblue','darkgreen','purple','olive')
for i in range(len(KPoint)):
dx = []
dy = []
for m in KClassify[i]:
dx.append(data_x[m])
dy.append(data_y[m])
# c = color_range[i]
plt.plot(K_x[i],K_y[i],color=str(color_range_p[i]),marker='*')
plt.scatter(dx,dy,c=str(color_range[i]),marker="D")
plt.show()最后一步,把这些组合成一个完整的序列:
if __name__ == "__main__":
generate_data()
run(k=4)
random_k_val()
for i in range(100):
print('第' + str(i) +'次计算:')
classify_structure()
show_pic()
find_new_centroid()
if loop_over(loss_c=0.5):
print("结束")
break
show_pic()我们运行一下,看一看完整的效果:
这张图表示为随机数据后,第一次随机选择簇中心的分配结果,其中五角星代表簇中心,颜色代表不同族群,对应k=4,这里表示为四个族群:
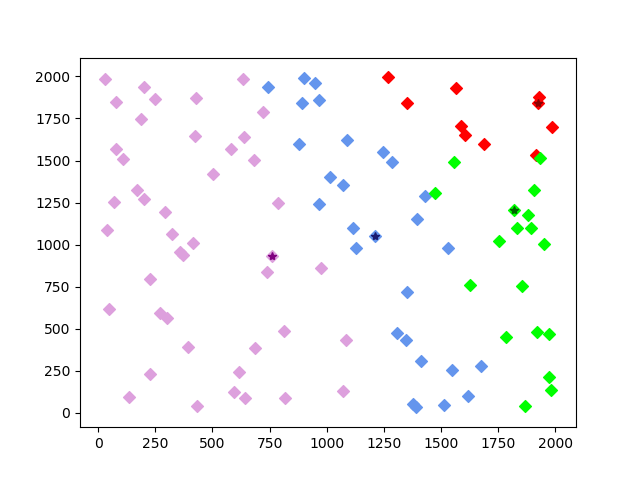
第二次迭代,簇中心产生偏移,族群归属发生改变:
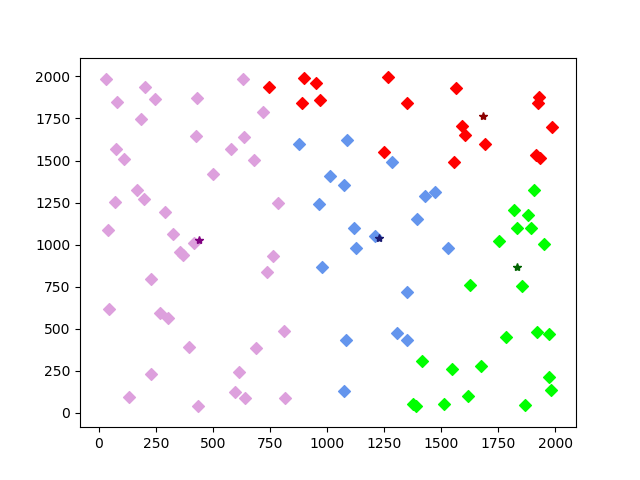
第五次迭代效果:
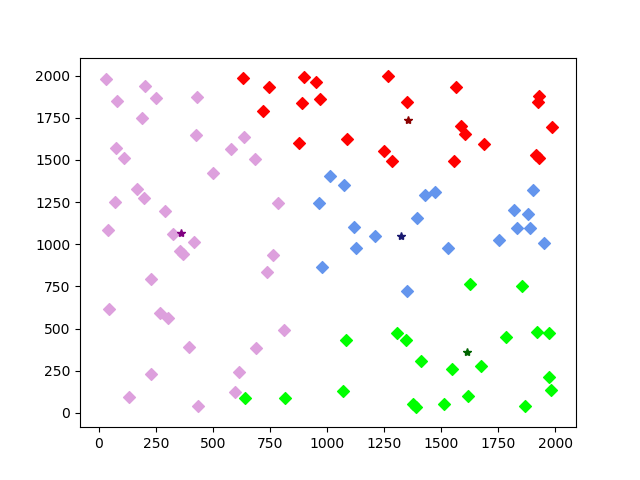
第十次迭代效果:
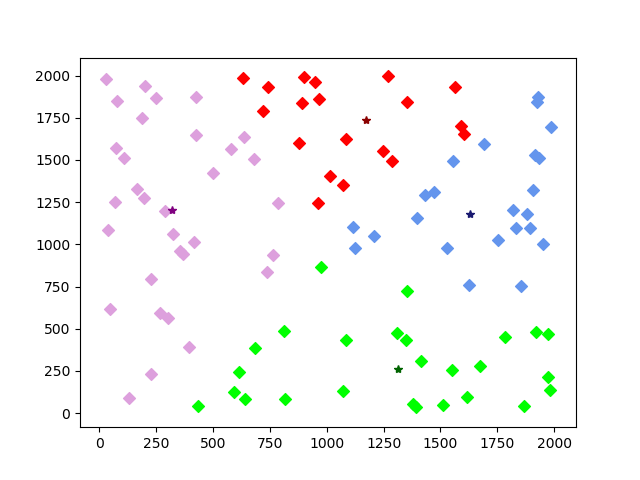
第十五次,效果已经很明显了是不是:
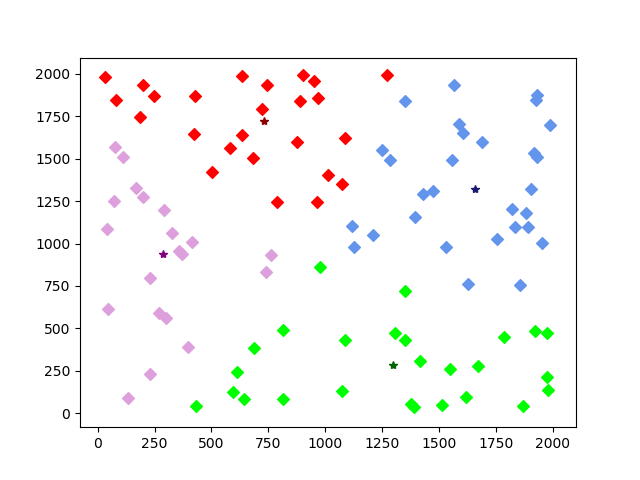
第二十次迭代:
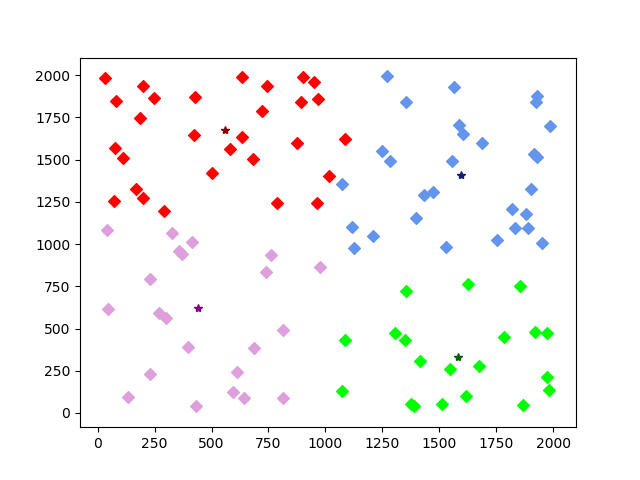
最后一次(即第二十三次迭代后族群分配结束,迭代条件终止):
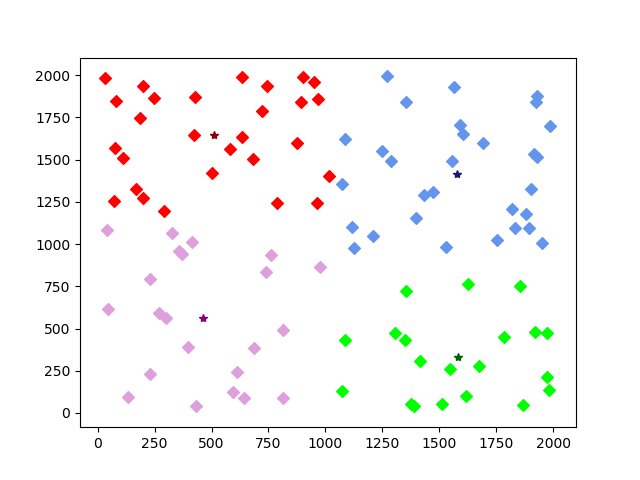
同样的,我们手动指定族群为5个,即k=5,产生效果如下:
初始:
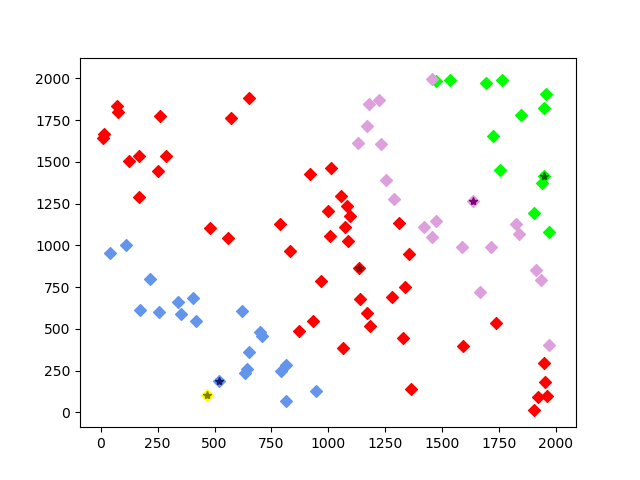
经过五次迭代,产生了最终结果:
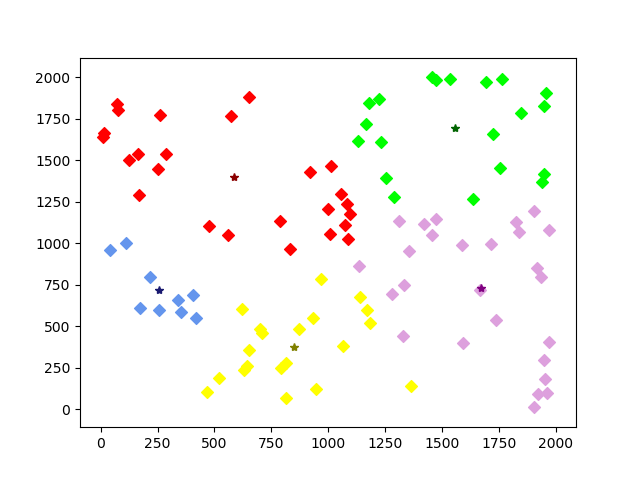
很简单,也很有意思是不是~
写在最后:
程序代码全部都贴在这里了,希望可以帮到需要和学习的人,也欢迎讨论,另外也说一下,超讨厌那些写博客云里雾里的,猜来猜去累死了,贴个公式,说个复杂度,然后拿人家的库套一套样例数据就说解决了机器学习,累不累啊,不愿意写没关系啊,没时间造轮子无所谓啊,起码推导一下啊,知不知道搜索引擎把你们的文章放在前面很浪费时间。
另外,如果要计算高维数据,其实就是对应改动里面的部分计算和输入方式就可以了,公式和原理是一样的,另外我给出的代码,由于颜色代码我只给了五个,所以如果指定的k大于5,就会产生报错,如何解决这种问题呢?当然是在颜色指定的那一部分中,把你想要的对应颜色加进去就可以了。
补充一下,如果发生了某种异常行为,例如数据源相似度太高,产生了某一个族群变成了0成员,那么对于这种解决方法,提供两种方案:1、分裂最大的那个族群,产生两个族群重新分配; 2、在所有的点中,找到一个点,这个点距离目前所有的簇中心,相较于其它成员的距离时最远的,然后重新分配族群。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









