







我用的是ubuntu18.04服务器,因为要跑代码所以需要装gpu版的tensorflow1.5.0。
先放一张linux-GPU版本对应表: 官网,接下来根据上面的要求一个个去装gcc、CUDA和cuDNN,以及建python环境:
| 版本 | Python 版本 | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| tensorflow-2.6.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.5.0 | 3.6-3.9 | GCC 7.3.1 | Bazel 3.7.2 | 8.1 | 11.2 |
| tensorflow-2.4.0 | 3.6-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 8.0 | 11.0 |
| tensorflow-2.3.0 | 3.5-3.8 | GCC 7.3.1 | Bazel 3.1.0 | 7.6 | 10.1 |
| tensorflow-2.2.0 | 3.5-3.8 | GCC 7.3.1 | Bazel 2.0.0 | 7.6 | 10.1 |
| tensorflow-2.1.0 | 2.7、3.5-3.7 | GCC 7.3.1 | Bazel 0.27.1 | 7.6 | 10.1 |
| tensorflow-2.0.0 | 2.7、3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10.0 |
| tensorflow_gpu-1.15.0 | 2.7、3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10.0 |
| tensorflow_gpu-1.14.0 | 2.7、3.3-3.7 | GCC 4.8 | Bazel 0.24.1 | 7.4 | 10.0 |
| tensorflow_gpu-1.13.1 | 2.7、3.3-3.7 | GCC 4.8 | Bazel 0.19.2 | 7.4 | 10.0 |
| tensorflow_gpu-1.12.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.11.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.10.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.15.0 | 7 | 9 |
| tensorflow_gpu-1.9.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.11.0 | 7 | 9 |
| tensorflow_gpu-1.8.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.10.0 | 7 | 9 |
| tensorflow_gpu-1.7.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
| tensorflow_gpu-1.6.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
| tensorflow_gpu-1.5.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.8.0 | 7 | 9 |
| tensorflow_gpu-1.4.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.5.4 | 6 | 8 |
| tensorflow_gpu-1.3.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.4.5 | 6 | 8 |
| tensorflow_gpu-1.2.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.4.5 | 5.1 | 8 |
| tensorflow_gpu-1.1.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.4.2 | 5.1 | 8 |
| tensorflow_gpu-1.0.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.4.2 | 5.1 | 8 |
可以看到,tensorflow_gpu-1.5.0需要GCC 4.8、cuDNN7、CUDA9(这里的Bazel 0.8.0可以不用管它),然后在python2.7、3.3-3.6环境下装。
推荐严格按照对应关系进行环境的安装:CUDA版本较低必定安装不了,而CUDA版本较高也会报错。
下面分步骤具体介绍。
1. 更新电脑显卡驱动
不同版本的CUDA对驱动的要求不同,如下:
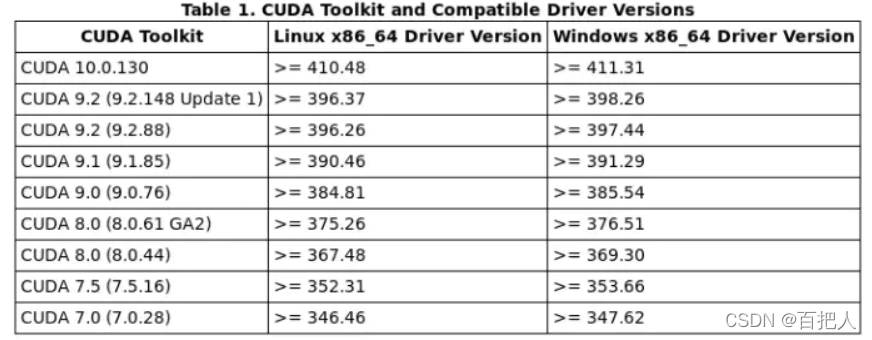
可以通过nvidia-smi查看服务器驱动:
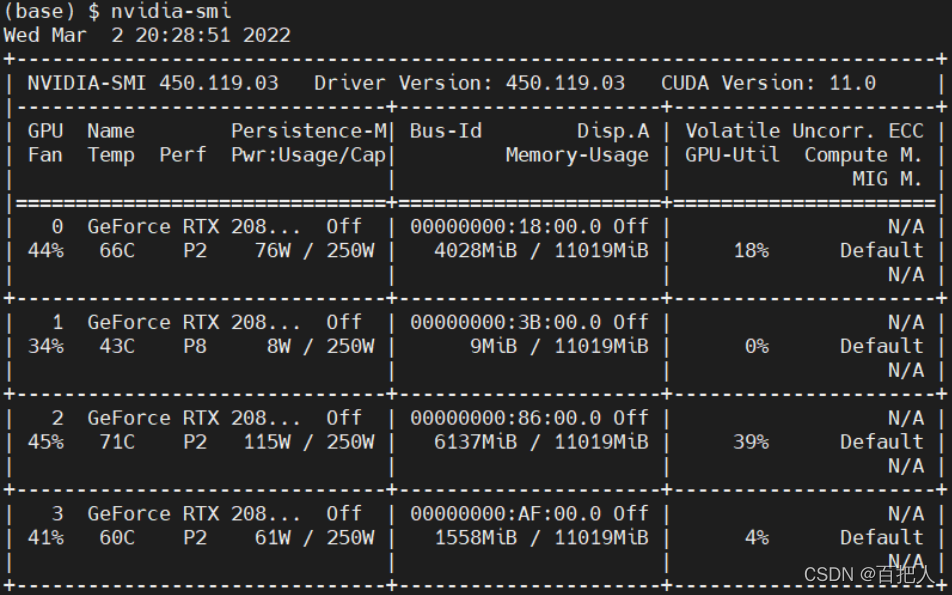
驱动版本是450.119.03,而我们计划装的CUDA9.0需要384.81以上,满足要求。
如果不满足,可以参考这里的方法,或者从网上下载NVIDIA-Linux-x86_64-450.119.03.run文件自己安装。但NVIDIA官网似乎只提供最新版的驱动,老版本推荐去bing搜索文件名,百度不太好使。
2. 更改gcc和g++版本
gcc和g++的作用如同windows里的vc和vs一样,为c和c++编译器,而gcc和g++就是Ubuntu里的c和c++编译器。Ubuntu 18.04预装GCC版本为7.3,需要手动降级到4.8版本。
自动安装:sudo apt-get install gcc-4.8,在用apt-get install的时候很可能报错:
错误:1 https://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic/universe amd64 gcc-4.8-base amd64 4.8.5-4ubuntu8
Certificate verification failed: The certificate is NOT trusted. The certificate chain uses expired certificate. Could not handshake: Error in the certificate verification. [IP: 101.6.15.130 443]
错误:2...
解决:执行sudo vim /etc/apt/sources.list修改里面清华源的url,把https改成http。注意这里要用sudo vim,如果只用vim的话没有权限。然后再执行刚才的命令,安装成功。
此时用gcc --version查看版本,发现仍然显示原来的gcc,原因是新装的gcc优先级不够,需要重新设置gcc的优先级:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8 10
最后的数字10为优先级(越大越高),因为只有一个4.8版本作为alternatives,可以不要纠结数字,这样设就行了。
然后把原来gcc的优先级降低:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 1
然后可以输入以下命令查看设置结果(非必须) :
sudo update-alternatives --config gcc
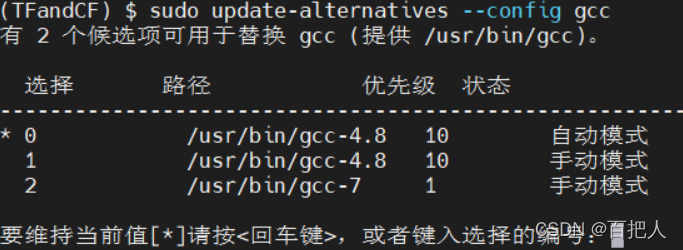
最后再次输入命令gcc -version查看gcc的版本:

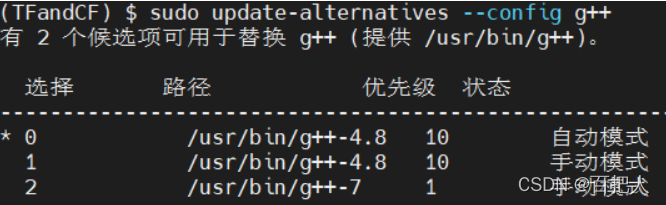
同理,修改默认的g++也是如此:
sudo apt-get install g++-4.8
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/g++-4.8 10
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/g++-7 1
sudo update-alternatives --config g++

测试gcc能不能用:gcc4.8可以支持c++11,因此为了验证是否能够正常工作,以新加入到C++11中的std::array为例。
#include <iostream>
#include <string>
#include <iterator>
#include <algorithm>
#include <array>
int main()
{
// construction uses aggregate initialization
std::array<int, 3> a1{ {1,2,3} }; // double-braces required
std::array<int, 3> a2 = {1, 2, 3}; // except after =
std::array<std::string, 2> a3 = { {std::string("a"), "b"} };
// container operations are supported
std::sort(a1.begin(), a1.end());
std::reverse_copy(a2.begin(), a2.end(),
std::ostream_iterator<int>(std::cout, " "));
std::cout << '\n';
// ranged for loop is supported
for(auto& s: a3)
std::cout << s << ' ';
std::cout << '\n';
}
编译:g++ -std=c++11 -o stdarray stdarray.cpp. 一定要加上c++11,否则可能无法编译或者无法运行。
运行:./stdarray
结果输出:
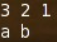
则表示gcc确实能够支持C++11开发。
3. 安装CUDA
CUDA是英伟达专门为GPU计算推出的计算平台,从CUDA3.0开始已经支持C++和FORTRAN,所以上面我们需要将gcc和g++调整到CUDA支持的版本。
查看cuda版本:cat /usr/local/cuda/version.txt或者 nvcc -V。结果:CUDA Version 10.2.89
插播:CUDA driver version 和 runtime version的区别:
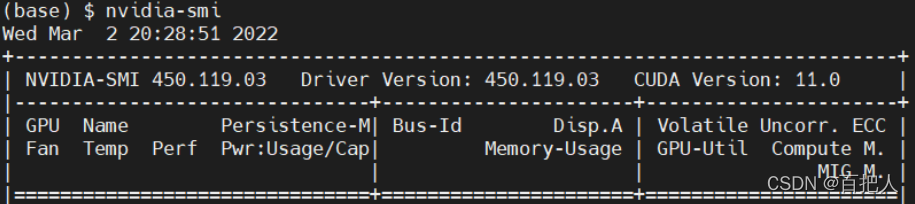
CUDA Driver Version是跟nvidia的GPU驱动(nvidia-driver)绑定在一起的, 执行nvidia-smi得到右上角显示的cuda版本:
上图说明驱动版本是450.119.03,可支持的CUDA版本是≤11.0
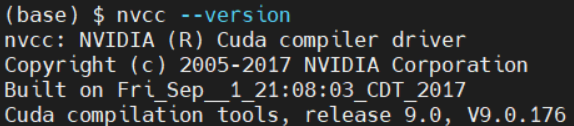
CUDA Runtime Version是你自己在系统上安装的cuda版本,是你跑深度学习模型或其它程序调用的cuda版本,执行nvcc -V或者nvcc --version可以查看(前提是你正确安装了cuda并将cuda加入了环境变量),例如:
综上所述:CUDA Driver Version和CUDA Runtime Version的版本不必非要一致,但CUDA Runtime Version要<=CUDA Driver Version。
插播:确定CUDA是否可用于当前的pytorch或者tf:
pytorch:https://bbs.huaweicloud.com/blogs/140384
tf: 只能在 import tensorflow as tf 的时候才能发现CUDA是否可用,如果不可用,会有如下类似的报错:ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory。 这就表示当前tf需要CUDA 9.0,但是没有找到,而决定tf应该使用哪个版本的CUDA,是tf安装目录下的一个_pywrap_tensorflow_internal.lib库文件定义的 。
下面来装我们的CUDA9.0。到NVIDIA官网CUDA9.0 下载页面下载runfile,选择ubuntu16.04,因为18.04版本的系统能够安装16.04版本对应的CUDA 。

文件下载后用以下指令安装:
sudo chmod a+x cuda_9.0.176_384.81_linux.run
sudo ./cuda_9.0.176_384.81_linux.run --no-opengl-libs
然后会打印出一堆内容,中间包含了默认路径(后面测试 cuda 的 Samples会用到,建议记一下)和条款:
Default Install Location of CUDA Toolkit
Linux platform:
/usr/local/cuda-#.#
Default Install Location of CUDA Samples
Linux platform:
/usr/local/cuda-#.#/samples
然后是一些问答。 大多数是yes,除了是否安装显卡驱动时,一定选择 no(之前安装过显卡驱动)
Do you accept the previously read EULA?
accept/decline/quit: accept
You are attempting to install on an unsupported configuration. Do you wish to continue?
(y)es/(n)o [ default is no ]: y
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n
Install the CUDA 9.0 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[ default is /usr/local/cuda-9.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 9.0 Samples?
(y)es/(n)o/(q)uit: y
Enter CUDA Samples Location
[ default is /home/gsy ]:
Installing the CUDA Toolkit in /usr/local/cuda-9.0 ...
Missing recommended library: libGLU.so
Missing recommended library: libX11.so
Missing recommended library: libXi.so
Missing recommended library: libXmu.so
Missing recommended library: libGL.so
Installing the CUDA Samples in /home/gsy ...
Copying samples to /home/gsy/NVIDIA_CUDA-9.0_Samples now...
Finished copying samples.
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-9.0
Samples: Installed in /home/gsy, but missing recommended libraries
Please make sure that
- PATH includes /usr/local/cuda-9.0/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-9.0/lib64, or, add /usr/local/cuda-9.0/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-9.0/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-9.0/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 384.00 is required for CUDA 9.0 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run -silent -driver
Logfile is /tmp/cuda_install_1090.log
之后声明一下环境变量,并将其写入到 ~/.bashrc 文件(在用户目录下)的尾部,输入内容如下:
export PATH=/usr/local/cuda-9.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:$LD_LIBRARY_PATH
保存退出,并输入下面指令使环境变量立刻生效: source ~/.bashrc
设置环境变量和动态链接库
在命令行输入sudo vim /etc/profile
在打开的文件末尾加入: export PATH=/usr/local/cuda/bin:$PATH
创建链接文件
sudo vim /etc/ld.so.conf.d/cuda.conf
在打开的文件中添加如下语句: /usr/local/cuda/lib64。
保存退出,然后执行 sudo ldconfig使链接立即生效。
测试 cuda 的 Samples
切换到 CUDA Samples 的默认安装路径(根据安装后打印出来的提示是/usr/local/cuda-9.0/samples), 终端下输入:sudo make all -j4,等几分钟,出现“Finished building CUDA samples”,然后输入
cd bin/x86_64/linux/release
./deviceQuery
然后打印出一堆东西,能输出GPU的信息,就说明ok。最后可以看到CUDA的runtime version已经变成了9.0:

查看cuda版本: nvcc --version

如果不对,可以在~/.bashrc里添加路径:
export PATH="$PATH:/usr/local/cuda-9.0/bin"
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-9.0/lib64/"
export LIBRARY_PATH="$LIBRARY_PATH:/usr/local/cuda-9.0/lib64"
4. 安装cuDNN
cuDNN是英伟达为CUDA加速运算推出的加速库,用于在GPU上实现高性能现代并行计算。
看cuDNN版本:cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
 即:cuDNN7.6.5,已经满足,不需要再装了。但还没完:要把cudnn的一些文件复制到cuda文件夹下(我这里没找到cudnn之前安装的文件夹,所以把原来有的cuda10.2里的文件复制到了新装的cuda9.0里面,毕竟它也是来源于cudnn文件夹):
即:cuDNN7.6.5,已经满足,不需要再装了。但还没完:要把cudnn的一些文件复制到cuda文件夹下(我这里没找到cudnn之前安装的文件夹,所以把原来有的cuda10.2里的文件复制到了新装的cuda9.0里面,毕竟它也是来源于cudnn文件夹):
sudo cp /usr/local/cuda-10.2/targets/x86_64-linux/include/cudnn.h /usr/local/cuda-9.0/include/cudnn.h
sudo cp /usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn* /usr/local/cuda-9.0/lib64
然后安装 libcupti-dev 包:sudo apt-get install libcupti-dev
并给上述文件添加读取权限:
sudo chmod 755 /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
5. 最后安装Tensorflow-gpu
先在环境变量里增加一句(这是使用tf的要求):export CUDA_HOME=/usr/local/cuda-9.0
然后安装依赖(for Python 3.n ): sudo apt-get install python3-pip python3-dev
然后安装tf-gpu版: pip3 install tensorflow-gpu==1.5.0
如果报错的话可以试试 pip install tensorflow-gpu==1.5.0,或者自己下载 清华镜像源的文件 ,然后pip或pip3 install tensorflow_gpu-1.5.0-cp36-cp36m-manylinux1_x86_64.whl
然后用anaconda创建一个python3.6的环境,进入后import测试:
import tensorflow as tf
hello = tf.constant('hello,tf')
sess = tf.Session()
print(sess.run(hello)) # b'hello,tf'
a = tf.constant(10)
b = tf.constant(22)
print(sess.run(a + b)) # 32
tf.__version__ # 1.5.0
能够输出就说明装好了。这里可能会打印一些关于GPU的信息,别慌,不是报错。最后一行代码是查看tf版本。
因为装的是gpu版本,可以使用下面的代码来测试是否能够成功启动gpu:
from tensorflow.python.client import device_lib
print('GPU:',tf.test.is_gpu_available())
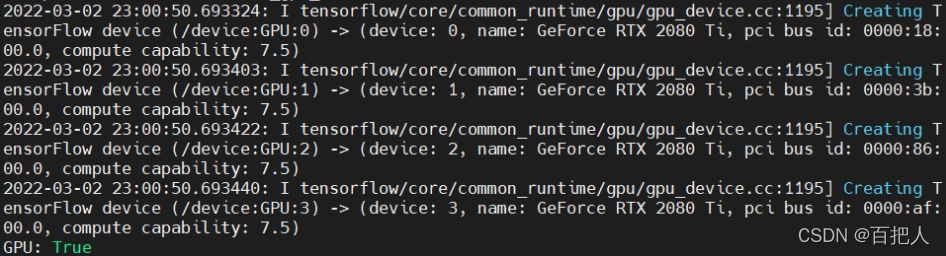
输出true就行了,大功告成~
参考资料
Ubantu 18.04 安装 TensorFlow 详细教程
Ubuntu17.04安装TensorFlow1.2的GPU版本
tensorflow对应cuda的兼容版本问题
Ubuntu18.04下安装CUDA和cudnn
除此以外也参考了其他资料,但难以追溯了,一并感谢。















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











