






PaliGemma 是 Google 开发和发布的具有多模态功能的视觉语言模型 (VLM)。
与其他 VLM(例如 OpenAI 的 GPT-4o、Google Gemini 和 Anthropic 的 Claude 3)不同,PaliGemma 具有广泛的功能,并能够微调以在特定任务上获得更好的性能。
Google 决定发布一个具有对自定义数据进行微调能力的开放多模态模型,这是 AI 的重大突破。PaliGemma 让你有机会创建自定义多模态模型,可以在云端自行托管这些模型,并可能在 NVIDIA Jetsons 等更大的边缘设备上托管这些模型。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、什么是 PaliGemma?
PaliGemma 与其他产品一起在 2024 年 Google I/O 活动上发布,它是一种基于 Google 研究的另外两个模型的组合多模态模型:视觉模型 SigLIP 和大型语言模型 Gemma,这意味着该模型是 Transformer 解码器和 Vision Transformer 图像编码器的组合。它将图像和文本作为输入,并生成文本作为输出,支持多种语言。
PaliGemma 的重要方面:
- 相对较小的 30 亿组合参数模型
- 允许的商业使用条款
- 能够针对图像和短视频字幕、视觉问答、文本阅读、对象检测和对象分割进行微调
虽然 PaliGemma 无需微调即可使用,但 Google 表示它“并非设计为直接使用,而是使用类似的提示结构(通过微调)转移到特定任务”,这意味着我们可以通过模型权重观察到的任何基线都只是该模型在给定上下文中可能有多有用的冰山一角。 PaliGemma 已在 WebLI、CC3M-35L、VQ²A-CC3M-35L/VQG-CC3M-35L、OpenImages 和 WIT 上进行过预训练。
2、PaliGemma 资源链接
Google 提供了充足的资源来开始使用 PaliGemma 进行原型设计,我们为那些想要立即开始使用 PaliGemma 的人精心挑选了最高质量的信息。我们建议从以下资源开始:
- PaliGemma Github README
- PaliGemma 文档
- PaliGemma 微调文档
- 在 Google Colab 中微调 PaliGemma
- 在 Google Vertex 中访问 PaliGemma
在这篇文章中,我们将探索 PaliGemma 可以做什么,将 PaliGemma 基准与其他 LMM 进行比较,了解 PaliGemma 的局限性,并了解它在实际用例中的表现。我们汇集了可以在测试 PaliGemma 时节省时间的学习内容。
让我们开始吧!
3、PaliGemma 能做什么?
PaliGemma 是一种单轮视觉语言模型,在针对特定用例进行微调时效果最佳。这意味着您可以输入图像和文本字符串,例如提示为图像添加标题或问题,PaliGemma 将输出响应输入的文本,例如图像的标题、问题的答案或对象边界框坐标列表。
PaliGemma 适合执行的任务与 Google 针对以下任务发布的基准测试结果有关:
- 单个任务的微调
- 图像问答和字幕
- 视频问答和字幕
- 分割
这意味着 PaliGemma 适用于与视觉数据相关的直接和具体问题。
我们根据常见基准测试报告的结果创建了一个表格,以显示 PaliGemma 相对于其他模型的结果。

虽然基准测试是有用的数据点,但它们并不能说明全部情况。PaliGemma 是为微调而构建的,而其他模型都是闭源的。为了展示哪些选项可用,我们与其他通常要大得多的无法微调的模型进行了比较。
值得尝试一下,看看使用自定义数据进行微调是否会为你的特定用例带来比其他模型的开箱即用性能更好的性能。
在这篇文章的后面,我们将使用一组标准测试将 PaliGemma 与其他开源 VLM 和 LMM 进行比较。继续阅读以了解它的表现。
4、如何微调 PaliGemma
PaliGemma 令人兴奋的方面之一是它能够根据自定义用例数据进行微调。Google 的 PaliGemma 团队发布的笔记本展示了如何在小型数据集上进行微调。
重要的是要注意,在这个例子中,只有注意层经过了微调,因此性能改进可能有限。
5、如何部署和使用 PaliGemma
你可以使用开源的推理包部署 PaliGemma。首先,我们需要安装推理包,以及运行 PaliGemma 所需的一些其他包。
!git clone https://github.com/roboflow/inference.git
%cd inference
!pip install -e .!pip install git+https://github.com/huggingface/transformers.git accelerate -q接下来,我们将通过从 Inference 导入模块并输入我们的 Roboflow API 密钥来设置 PaliGemma。
import inference
from inference.models.paligemma.paligemma import PaliGemma
pg = PaliGemma(api_key="YOUR ROBOFLOW API KEY")最后,我们可以输入一个测试图像作为 Pillow 图像,将其与提示配对,然后等待结果。
from PIL import Image
image = Image.open("/content/dog.webp") # Change to your image
prompt = "How many dogs are in this image?"
result = pg.predict(image,prompt)当用这张图片提示时,我们得到的准确答案是“1”。

6、PaliGemma 计算机视觉评估
接下来,我们将评估 PaliGemma 在使用 GPT-4o、Claude 3、Gemini 和其他模型测试的各种计算机视觉任务中的表现。
在这里,我们将测试几个不同的用例,包括光学字符识别 (OCR)、文档 OCR、文档理解、视觉问答 (VQA) 和对象检测。

以下评估测试是使用官方的 Google Hugging Face Space 运行的,您也可以使用它来运行自己的测试。
6.1 用于光学字符识别 (OCR) 的 PaliGemma
光学字符识别是一项计算机视觉任务,用于以机器可读的文本格式从图像中返回可见文本。虽然从概念上讲这是一项简单的任务,但在生产应用中完成起来却很困难。
下面我们尝试使用我们已经看到过与其他 LMM 一起使用的两个提示进行 OCR,要求它“读取序列号。返回不带其他文本的号码。”对于这个提示,它失败了,声称它没有接受过训练或没有能力回答这个问题。
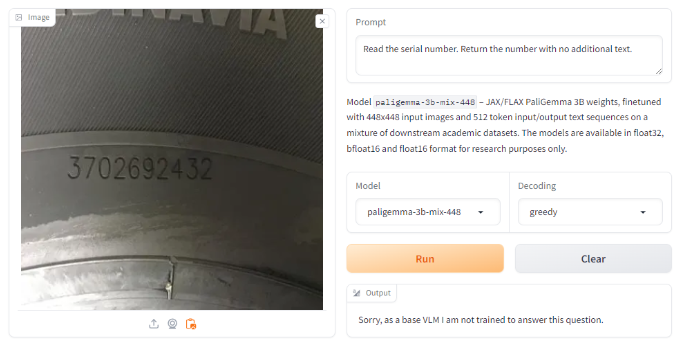
但是,我们从模型文档中知道它应该能够进行 OCR。我们尝试使用文档中提供的示例提示“ocr”,得到了成功且正确的结果。

尝试使用第一个提示使用不同的图像也得到了正确的结果,但这也带来了提示灵敏度的潜在限制。
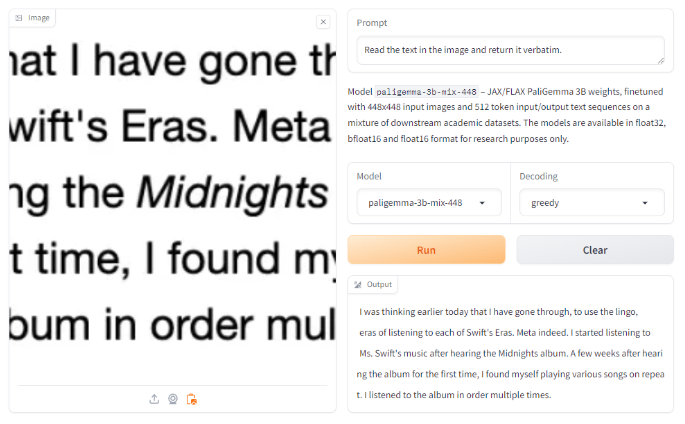
接下来,在我们之前用于测试其他 OCR 模型(如 Tesseract、Gemini、Claude、GPT-4o 等)的 OCR 基准上进行测试,我们看到了非常令人印象深刻的结果。
平均准确率达到 85.84%,击败了除 Anthropic 的 Claude 3 Opus 之外的所有其他 OCR 模型。
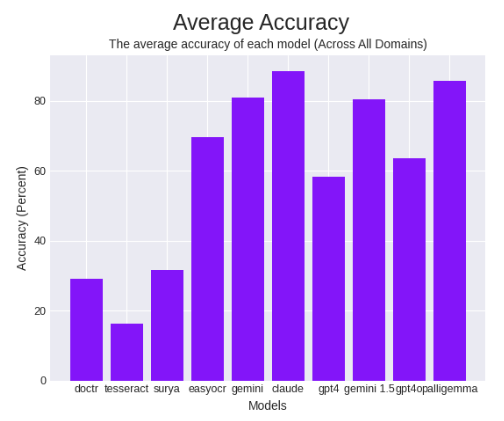
上图是所有测试模型的平均准确率,其中除 PaliGemma 外均为缓存结果。右侧的图表标签重叠。它们依次为 Gemini 1.5、GPT-4o 和 PaliGemma。
PaliGemma 的速度也相对较快。结合模型更便宜的本地特性,PaliGemma 似乎是速度效率和成本效率方面最好的 OCR 模型。
在平均速度效率方面,它以较大优势超越了前一天发布时创下的领先者 GPT-4o。在成本效率方面,PaliGemma 的表现比前任领先者 EasyOCR 高出近三倍,运行更准确,成本更低。
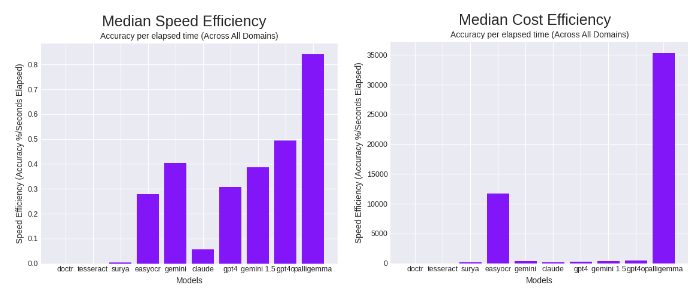
上图是所有测试模型的平均速度和成本效率,其中除 PaliGemma 之外的所有模型都是缓存结果。右侧的图表标签是重叠的。它们依次为 Gemini 1.5、GPT-4o 和 PaliGemma。
我们认为这些结果使 PaliGemma 成为顶级 OCR 模型,因为与它击败的模型(包括最近发布的 GPT-4o、Gemini 和其他 OCR 软件包)相比,PaliGemma 具有本地化和更轻量级的特性。
6.2 文档理解
文档理解是指从图像中提取相关关键信息的能力,通常与其他不相关的文本一起提取。
在一张带有收据的图像上,我们要求它根据收据提取所缴纳的税款。在这里,PaliGemma 在几次尝试中始终给出接近但错误的结果。
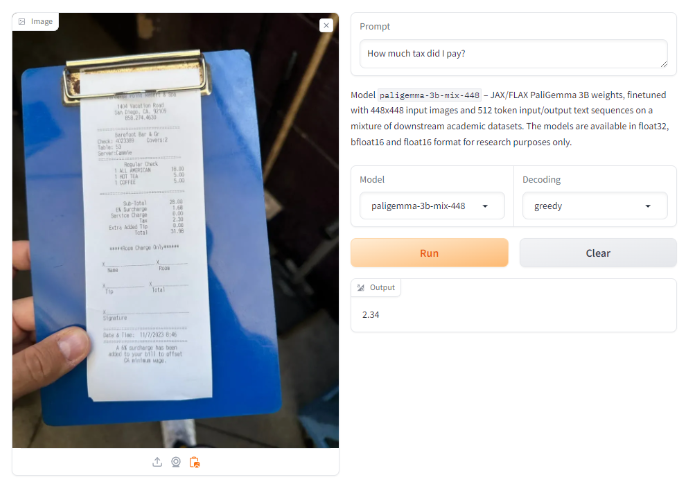
然而,在一张带有披萨菜单的图像上,当被要求提供特定披萨的价格时,它返回了正确的值。
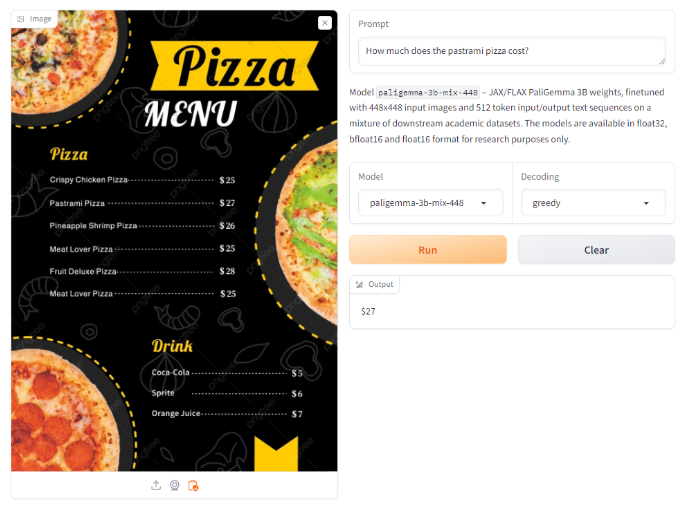
这与我们使用 Vision 的 GPT-4 的体验类似或相同,它未能提取税款,但正确回答了披萨菜单问题。Gemini、Claude 3 和新的 GPT-4o 以及开源 VLM Qwen-VL-Plus 都正确回答了这两个问题。
6.3 视觉问答 (VQA)
视觉问答涉及向模型提出一个图像和一个需要某种形式的识别、鉴别或推理的问题。
当被问到一张有 4 枚硬币的图片中有多少钱时,它回答了 4 枚硬币。从技术上讲,这是一个正确的答案,但问题是询问图片中的金额。
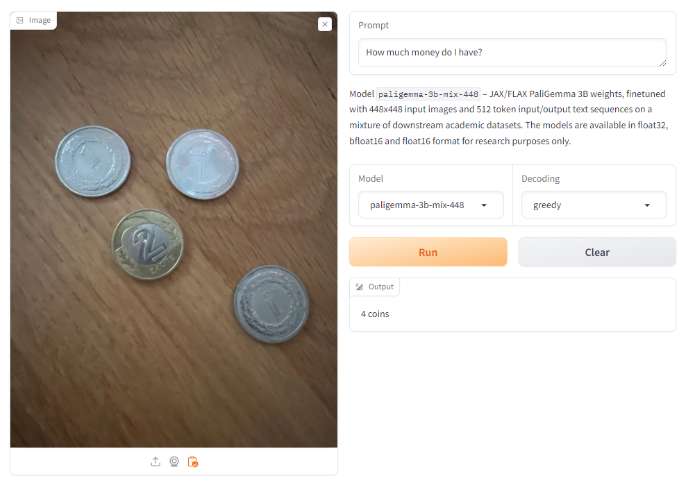
当它被要求识别电影《小鬼当家》中凯文·麦卡利斯特的场景时,它回答的是“圣诞节”。我们认为这是一个错误的答案。
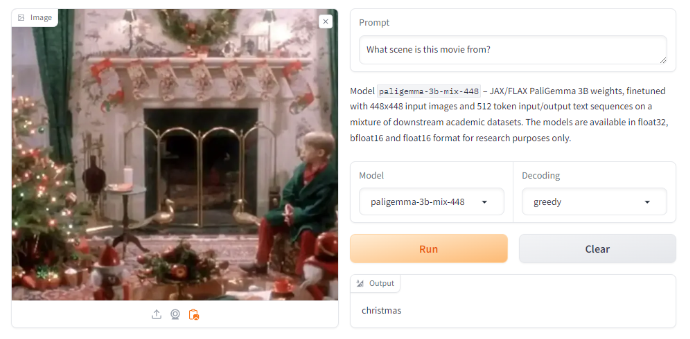
6.3 物体检测
正如我们前面提到的,VLM 传统上在物体检测方面表现不佳,更不用说实例分割了。然而,据报道,PaliGemma 具有物体检测和实例分割能力。
首先,我们使用过去给其他模型的相同提示进行测试。在这里,它返回了一个不正确的、可能是幻觉的结果。
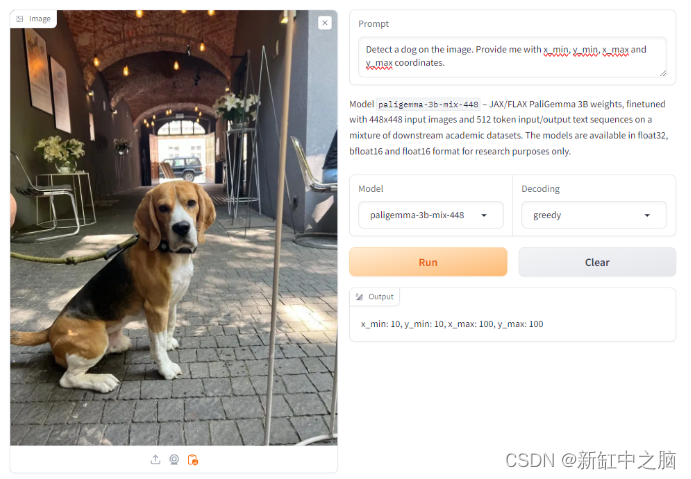
但是,当使用关键字“detect”提示,然后输入对象“dog”(因此为“detect dog”)时(如模型文档中所述),它可以正确且准确地识别图像中的狗。使用关键字“segment dog”也可以实现正确的分割。

尽管 VLM 能够提供物体检测和识别功能,这非常令人印象深刻,但值得注意的是,只有基本示例(例如使用传统物体检测模型可能实现的示例)才能成功。当提示寻找汽车时(从后面的建筑物门可以看到一辆汽车),它没有返回任何结果。
7、PaliGemma 的用例
无论是使用 PaliGemma zero-shot 还是对自定义数据进行微调,都有针对 PaliGemma 优势量身定制的特定用例,这些用例将为新的 AI 用例打开大门。让我们来看看其中的两个。
7.1 定制应用
Claude 3、Gemini 1.5 Pro 和 GPT-4o 等模型可开箱即用,并应用于它们适合解决的问题。PaliGemmi 为闭源模型尚未解决的用例带来了多模态能力,因为你可以使用与您的问题相关的专有数据对 PaliGemma 进行微调。这在制造业、CPG、医疗保健和安全等行业非常有用。如果你有一个独特的问题,而闭源模型没有见过,而且由于其专有性质,永远不会见到,那么 PaliGemma 是构建自定义 AI 解决方案的绝佳切入点。
7.2 OCR
如本文前面所示,PaliGemma 是一个强大的 OCR 模型,无需任何额外的微调。在构建可扩展至数十亿个预测的 OCR 应用程序时,延迟、成本和准确性可能难以平衡。在 PaliGemma 之前,闭源模型是性能最佳的选择,但它们的成本和缺乏模型所有权使得它们难以在生产中得到证明。此模型可以提供即时性能,并通过对你的特定数据进行微调来随着时间的推移而改进。
8、PaliGemma 的局限性
PaliGemma 和所有 VLM 最适合具有明确说明的任务,并不是解决开放式、复杂、细微或基于原因的问题的最佳工具。这就是 VLM 与 LMM 的不同之处,如果在最有可能表现良好的地方使用模型,你将获得最佳结果。
就上下文而言,PaliGemma 拥有基于预训练数据集和微调期间提供的任何数据的信息。PaliGemma 不会知道除此之外的信息,除非使用来自 Google 或开源社区的新数据更新权重,否则你不应依赖 PaliGemma 作为知识库。
为了充分利用 PaliGemma,并有理由使用该模型而不是其他开源模型,你需要在自定义数据上训练该模型。其零样本性能在大多数基准测试中都不是最先进的。设置自定义训练管道对于保证在大多数情况下使用 PaliGemma 是必要的。
最后,在各种测试中,我们发现提示稍有变化,结果就会有很大差异。这与其他 LMM(如 YOLO-World)的行为类似,需要花时间才能了解如何最好地提示模型。提示的变化(例如删除“s”以使单词变为单数而不是复数)可能是完美检测和不可用输出之间的区别。
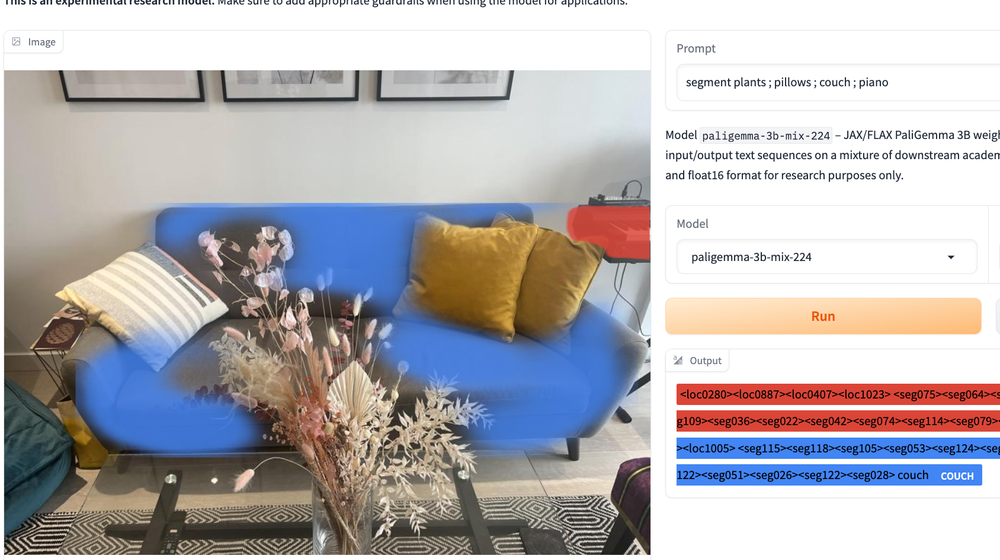
注意基于复数名词和单数名词的不同结果
9、结束语
Google 发布的 PaliGemma 对多模态 AI 的发展非常有用。专为微调而构建的轻量级开放模型意味着任何人都可以自定义训练自己的大型视觉语言模型,并将其部署在自己的硬件或云端用于任何商业用途。
以前的 LMM 微调成本极高,并且通常需要大量计算才能运行,因此无法广泛采用。PaliGemma 打破了这种模式,为构建自定义 AI 应用程序的人们提供了一个突破性的模型来创建复杂的应用程序。

















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









