







我们生活在大模型 (LLM) 时代,几乎每周你都会听到一种新的语言模型问世。从谷歌的 Gemini 和 Gemma 模型到 Meta 最新的 Llama 3 和微软的微型 Phi-3 模型,这些行业巨头之间正在进行激烈的在线竞争,以争夺头把交椅。
在这一连串的活动中,最引人注目的是这些科技巨头愿意向开发者社区开放其中一些语言模型。
开放模型有什么好处?
向开发者社区开放模型带来了几个好处,包括开发人员可以针对特定用例微调这些模型来解决有趣的问题。
如果你现在是一个大模型 (LLM)粉丝,我相信你已经尝试微调至少一个开放模型来探索它们的能力。在讨论所有这些流行的模型时,很少能找到同时开放和多模式的模型。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
我最近探索到的其中一个隐藏宝藏是 Hugging Face 🤗 构建的 Idefics2-8B 视觉语言模型。它是开放的,支持多模态,接受图像和文本输入序列。Idefics2 模型可以回答有关图像的问题、描述视觉内容、从多幅图像创建故事等等。
我一直在寻找详细介绍在自定义数据集上微调视觉语言模型的步骤的文章和教程。虽然大多数文章都涵盖了微调过程(在已有的数据集上),但它们往往忽略了数据准备的关键步骤。
本博客将为你带来这一点:微调 Idefics2 模型的综合指南,你不仅可以学习如何微调视觉语言模型,还可以从头开始准备自己的自定义数据集。你可以在此 GitHub 存储库中找到完整的 Colab 笔记本和原始数据集。
但在开始之前,让我们快速了解视觉语言模型的高级架构,以及它们与标准 LLM 有何不同。
视觉语言模型是从图像和文本中学习的多模态模型,从图像和文本输入生成文本输出。它们在零样本能力、泛化以及图像识别、问答和文档理解等各种任务方面表现出色。
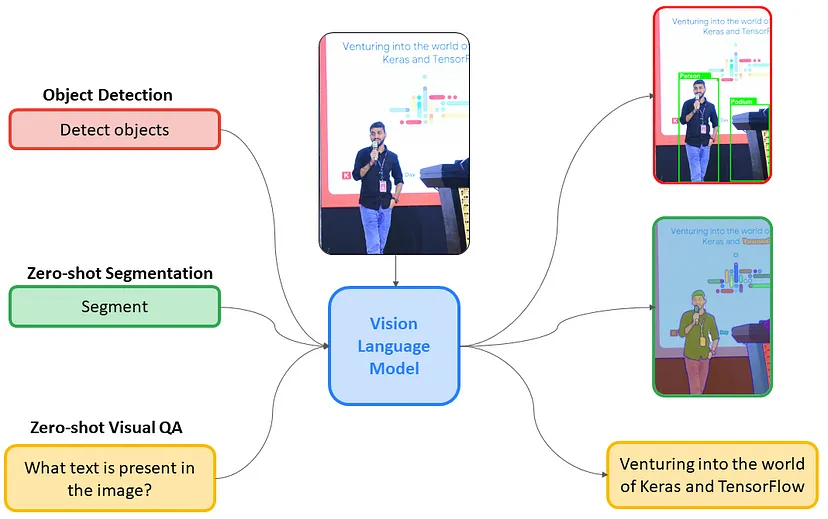
视觉语言模型
这些模型还可以捕获空间属性并输出特定主题的边界框或分割蒙版。在此处详细了解 VLM 及其架构。
现在你已经对 VLM 有了基本的了解,是时候展示一下了。让我们深入了解代码。
1、数据准备
与 LLM 不同,VLM 的数据集格式略有不同,因为除了标准文本数据外还引入了图像和视频。
今天,我们将在文档图像上微调 Idefics2 模型,以进行视觉问答。我们的训练数据来自 DocVQA 数据集的子采样版本,并进行了轻微修改以从头开始重新创建整个数据集。
克隆以下存储库:
!git clone https://github.com/NSTiwari/Fine-tune-IDEFICS-Vision-Language-Model
在存储库中,你将找到一个数据集文件夹,其中包含一个图像子文件夹。此子文件夹包含训练和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









