







 本文详细解读了微信AI在OCR领域的技术报告,重点探讨了ACE Loss,一种优于CTC和Attention的损失函数。ACE Loss通过聚合交叉熵解决了2-D序列识别问题,具有较低的时间复杂度,适用于长文本识别。尽管可能存在收敛困难,但在与CTC结合训练时能取得更好的效果。
本文详细解读了微信AI在OCR领域的技术报告,重点探讨了ACE Loss,一种优于CTC和Attention的损失函数。ACE Loss通过聚合交叉熵解决了2-D序列识别问题,具有较低的时间复杂度,适用于长文本识别。尽管可能存在收敛困难,但在与CTC结合训练时能取得更好的效果。
前段时间拜读了微信AI在OCR领域的一篇技术报告,其中有一个文本识别方向挺有意思的实践是在训练识别网络的时候,利用CNN+BLSTM提取文本行的序列特征,同时采用muti-head的结构,在训练时,以CTC为主,Attention Decoder和ACE辅助训练。在预测时,考虑到速度和性能,只采用CTC进行解码预测,具体的网络结构如下。
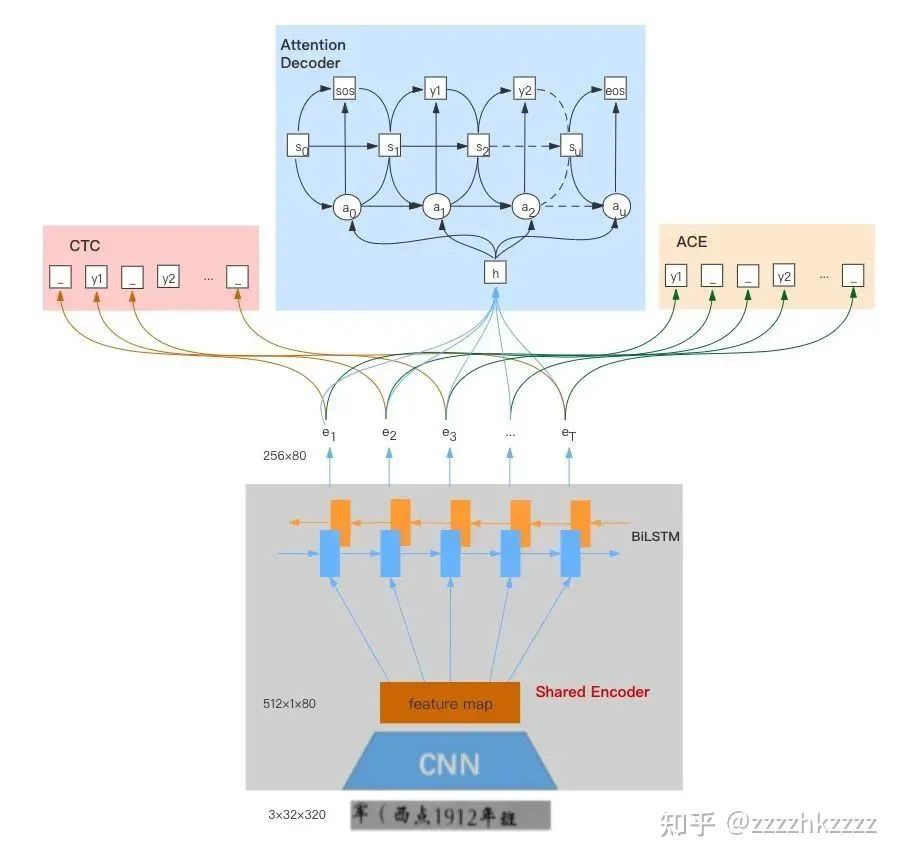
图1 muti-head ctc+attetion+ace识别网络
笔者最近正在进行复现该技术报告的相关工作,在此之前,因为对ACE loss的了解并不深入,特地通读了一下ACE loss的原论文。所以该篇博文,主要针对ACE loss的具体原理做一个解读。由于笔者的能力有限,如果有解读不到位或者是错误的地方,还望各位多多指正。
论文的原文链接如下:
https://arxiv.org/abs/1904.08364
GIT链接如下:
https://github.com/summerlvsong/Aggregation-Cross-Entropy
ACE loss 简介
目前主流的OCR pipeline基本上都是采用检测+识别两步走的方式完成的,导致现有文本识别任务中必须解决针对不定长文本行的识别问题。不定长文本行的文本识别,本质上是一个序列识别的问题。
针对序列识别的问题,两种业界比较主流的做法是从ASR任务中借鉴来的 CRNN+CTC方式,或者是从机器翻译任务中借鉴来的seq2seq+attention方式。
CRNN+CTC只能解决1-D的序列识别问题,在长文本识别,中文识别任务中表现出来了不错的效果。同时,得益于CTC计算中的前向后向递推迭代计算方式,使得其在运行效率上也有不俗的表现。但当文本行的形变较大时,CTC的效果就会受到比较大的影响。
Seq2Seq+attention的识别方式,原则上能够解决2-D的序列识别问题,但受限于RNN网络在长序列识别中的局限性,以及seq2seq的串行机制,导致这种方式,在长序列文本识别和运行效率上的表现并不十分尽如人意。
ACE loss就是为了弥补这两种方式的设计缺陷提出的,全称是Aggregation Cross-Entropy聚合交叉熵。文章中描述ACE不仅能够解决2-D文本的识别问题,还在时间复杂度和空间复杂度上优于CTC loss。
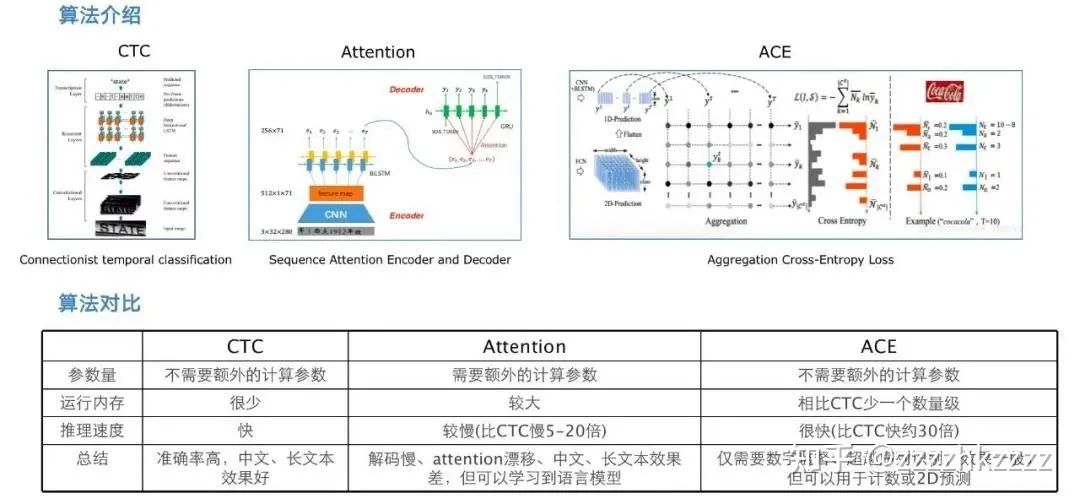
图2 三种算法的对比
具体实现细节
那么这个ACE loss 究竟有什么优势,又是怎么实现的呢?
我们不难知道,网络经过CNN+BLSTM提取特征+softmax之后,会得到一个
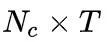
的后验概率矩阵,其中 是需要识别的字符集合长度,T是序列的长度,如下图所示。
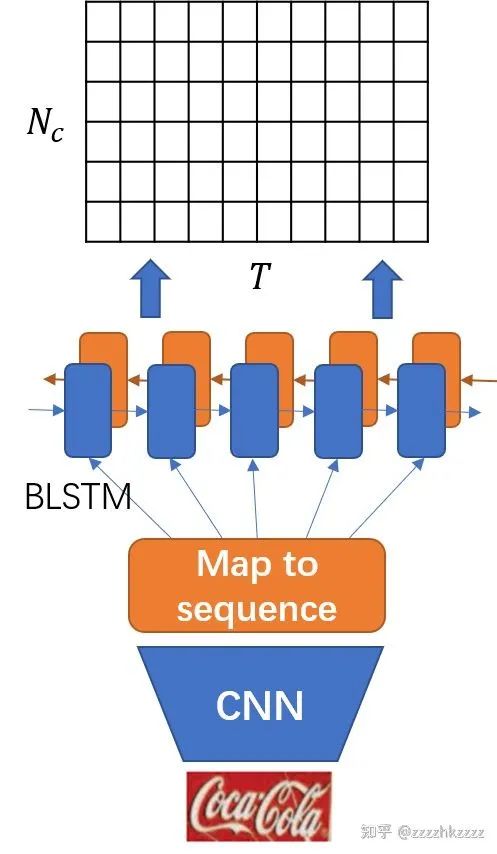
图3 网络输出的后验概率矩阵
定义文本行的annotation为
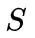
, 为 的长度, 第 个位置的字符记为,文本行图片记为 ,训练集记为 。那么某一个满足输入图片为,网络权重为 ,解码序列为 的序列概率可以表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









