







文章目录

上一篇博客 【AI 大模型】RAG 检索增强生成 ⑥ ( 使用 向量数据库 作为 RAG 知识库 完整实现 ) 中 , 完整的 实现了一个 RAG 知识库 ,
- 知识库准备 , 使用 OpenAI 的 text-embedding-ada-002 文本向量模型 将文本转为向量 , 然后 存储到 chromadb 向量数据库 中 ;
- 检索 Retrieval - 向量相似度匹配 , 从 向量数据库 中 查询 与提问相似的 文本知识 ;
- 增强 Augmented - 知识库信息注入 , 将 相似 文本内容 嵌入到 Prompt 提示词 中 ;
- 生成 Generation - 大模型整合输出 , 将 提示词 输入到大模型中 , 得到输出内容 ;
上述知识库 准备过程中 , 使用 OpenAI 的 text-embedding-ada-002 文本向量模型 需要 购买 OpenAI 的 token 用量 , 如果知识库很大 , 如 : 十亿级 , 会 产生大量的费用 ,
一、Sentence Transformers 工具库
1、Sentence Transformers 概念
Sentence Transformers , 简称 SBERT , 是一个用于 组织自然语言的神经网络模型和工具库 , 基于 Transformer 架构的深度学习模型 , 专门为 文本转换为 高质量 文本向量 而设计 , 这些向量能够 捕捉文本的语义信息 , 从而实现 文本相似度计算、文本分类、文本聚类等自然语言处理任务 ;
Sentence Transformers 官网 : https://sbert.net/index.html
2、Sentence Transformer 特点
参考 https://sbert.net/docs/quickstart.html 文档 , Sentence Transformer 具有如下特点 :
-
高效向量计算与检索 :
- 将 文本 / 图像 快速转化为 固定大小的语义向量 , 转化效率高。
- 向量相似度 计算速度 极快,支持大规模数据的高效检索。
-
广泛的任务适用性 : 适用于语义文 本相似性、语义搜索、聚类、分类、释义挖掘 等多种自然语言处理任务。
-
用于两步检索流程 : 首步通过 双编码器模型筛选候选结果 , 如前 k 个 , 再通过 交叉编码器对结果重排序以提升准确度 , 如 : 模型A粗筛 + 模型B精排 ;
-
预训练模型与灵活定制 :
- 提供丰富的 预训练模型库,覆盖多语言与垂直领域,用户可直接选择适配模型。
- 支持 对 预训练模型 微调 , 优化其在特定任务或数据集上的性能。
-
多语言与跨领域支持 : 支持 多语言文本处理 , 适应全球化应用场景。
-
高质量的语义表征能力 : 生成的 向量 能 精准捕捉文本深层语义信息 , 平衡高效性与准确性,为下游任务提供可靠基础。
二、本地部署向量模型
1、安装 Sentence Transformers
参考 https://sbert.net/docs/installation.html 文档 安装 Sentence Transformers ;
安装前 , 需要安装 前置依赖 包 Python、PyTorch、transformers ,官方要求版本需要满足如下要求 :
- Python 3.9 及以上版本
- PyTorch 1.11.0 及以上版本 , 执行下面的代码安装 PyTorch 软件包 ;
pip install torch
- transformers v4.41.0 及以上版本
执行
pip install sentence-transformers
命令 , 安装 Sentence Transformers ;
输出如下内容 , 说明安装成功 ;
2、本地运行向量模型 - Sentence Transformer 示例
这是 文档给出的官方示例 :
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
上述代码无法执行 , 因为 国内无法从 Hugging Face 模型库 中 , 下载 all-MiniLM-L6-v2 模型 , 这里需要在代码中动态设置 国内的 镜像源 ;
参考 :
- 【错误记录】本地部署大模型 从 Hugging Face 的模型库下载模型报错 ( OSError: We couldn‘t connect to ‘https://huggingface.co‘ )
- 【错误记录】Hugging Face 模型库下载模型报错 ( huggingface_hub 函数库使用 configure_hf 函数 报错 | 更新到最新版本 | 使用旧版本兼容方法设置镜像源 )
博客 , 解决了上述问题 , 可配置如下镜像源 :
- 官方镜像 : https://hf-mirror.com
- 深度求索 : https://hf-mirror.aliendao.cn
- 阿里云镜像 : https://modelscope.cn
- 清华大学镜像 : https://mirrors.tuna.tsinghua.edu.cn/hugging-face
动态配置镜像源后的代码为 :
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 核心配置
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2") # 注意完整路径
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
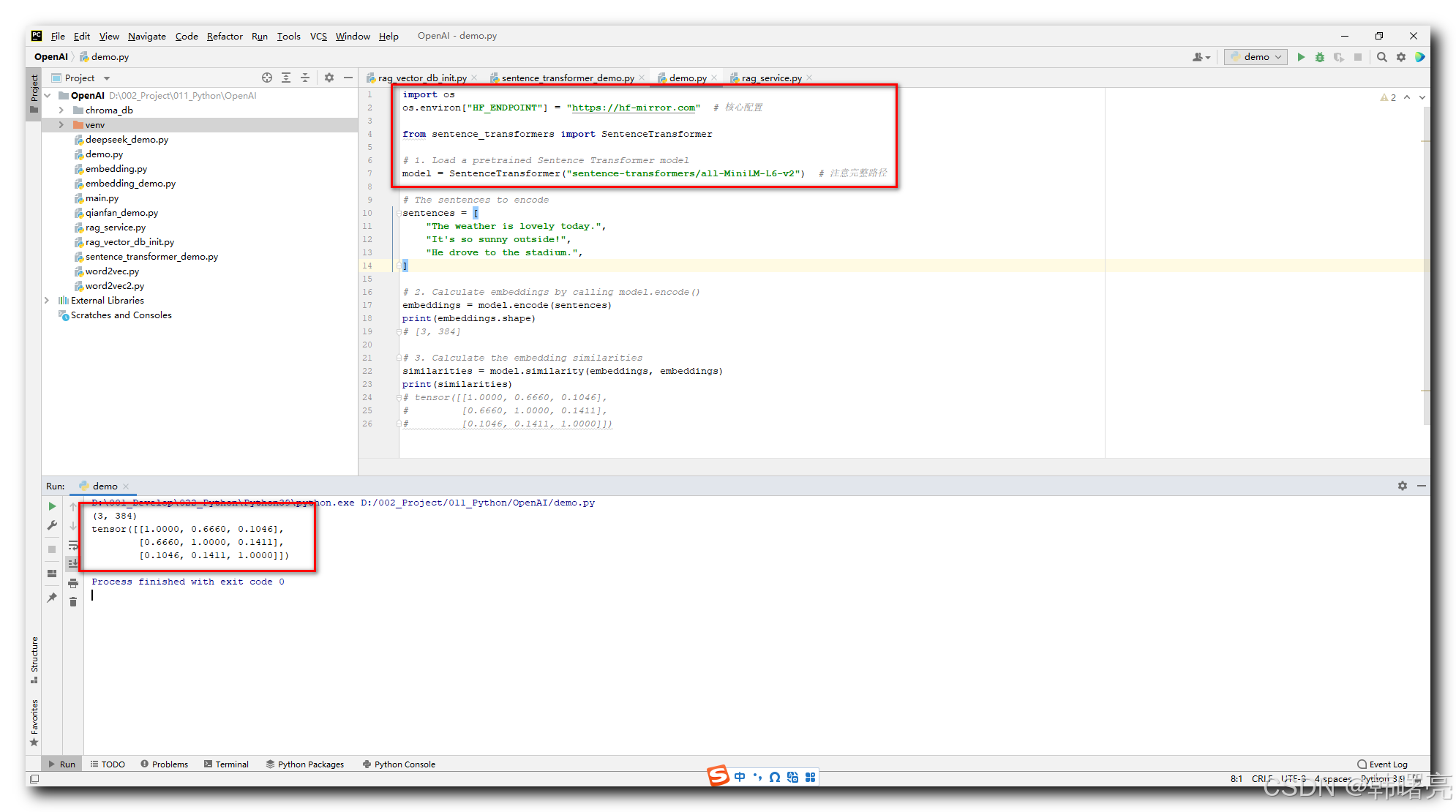
执行结果如下 :
(3, 384)
tensor([[1.0000, 0.6660, 0.1046],
[0.6660, 1.0000, 0.1411],
[0.1046, 0.1411, 1.0000]])
3、查看本地部署的向量模型
模型下载到了 " C:\Users\octop.cache\huggingface " 目录中 ,
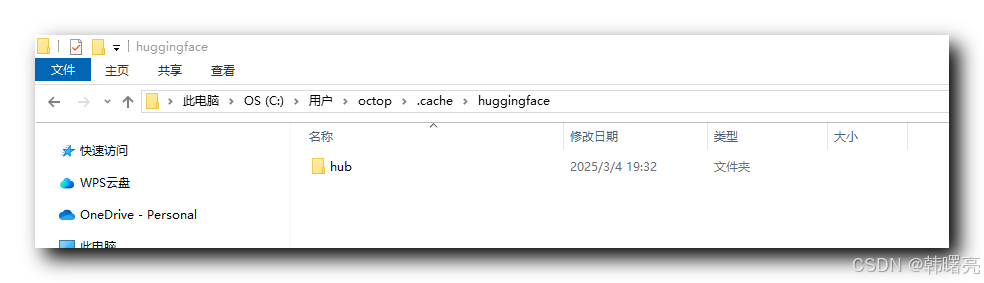
all-MiniLM-L6-v2 模型的目录是 " C:\Users\octop.cache\huggingface\hub\models–sentence-transformers–all-MiniLM-L6-v2 "
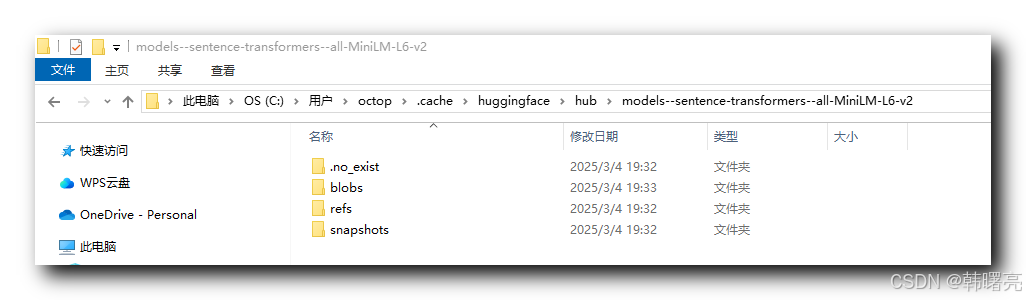
all-MiniLM-L6-v2 模型 目录结构为 :
├── blobs
│ ├── 8a49...(模型二进制文件)
│ └── 6b32...
├── refs
│ └── main
└── snapshots
└── 9e5f...(实际使用的版本)
├── config.json
├── pytorch_model.bin
└── tokenizer.json
三、从 Hugging Face 模型库 中查找模型
1、查询模型
在 Hugging Face 模型库 网站 https://huggingface.co/ 中 大部分模型都是 开源模型 , 采用MIT、Apache 2.0等开源许可证 , 如 BERT、GPT-2、RoBERTa等经典模型 , 这些模型 允许 商用、修改、二次分发 ;
在 商用前 检查许可证类型 + 确认是否允许商业用途 , 使用 huggingface_hub 库的 scan_license() 函数 可快速检测模型授权信息 ;
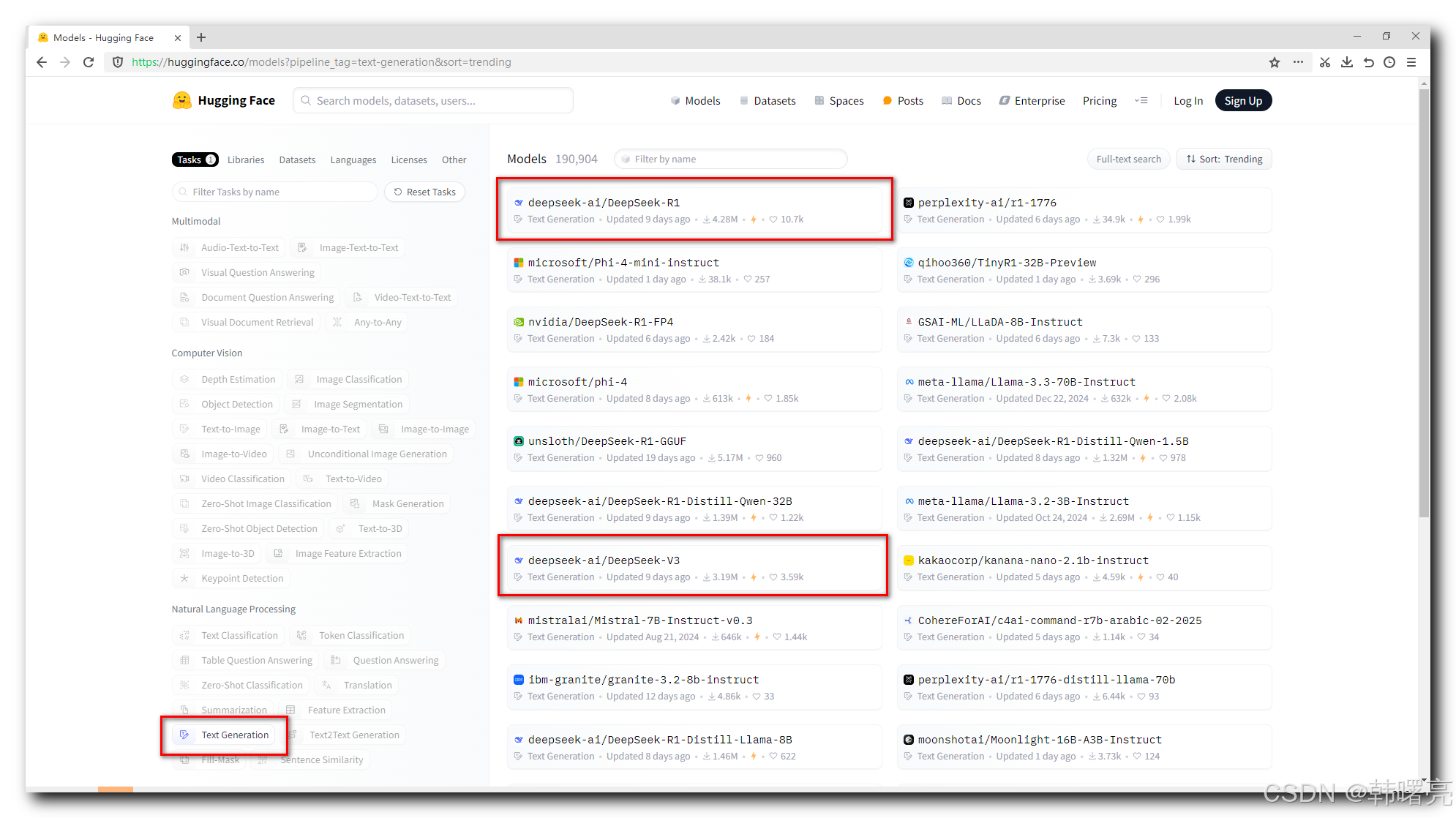
具体的 模型广场 页面是 https://huggingface.co/models , 该页面的左侧 选中 Tasks 标签 , 可以根据任务类型 筛选 需要的模型 ;

选中 " Text Generation " 类型的任务 , 就可以看到 文本生成 类的 开源模型 ,
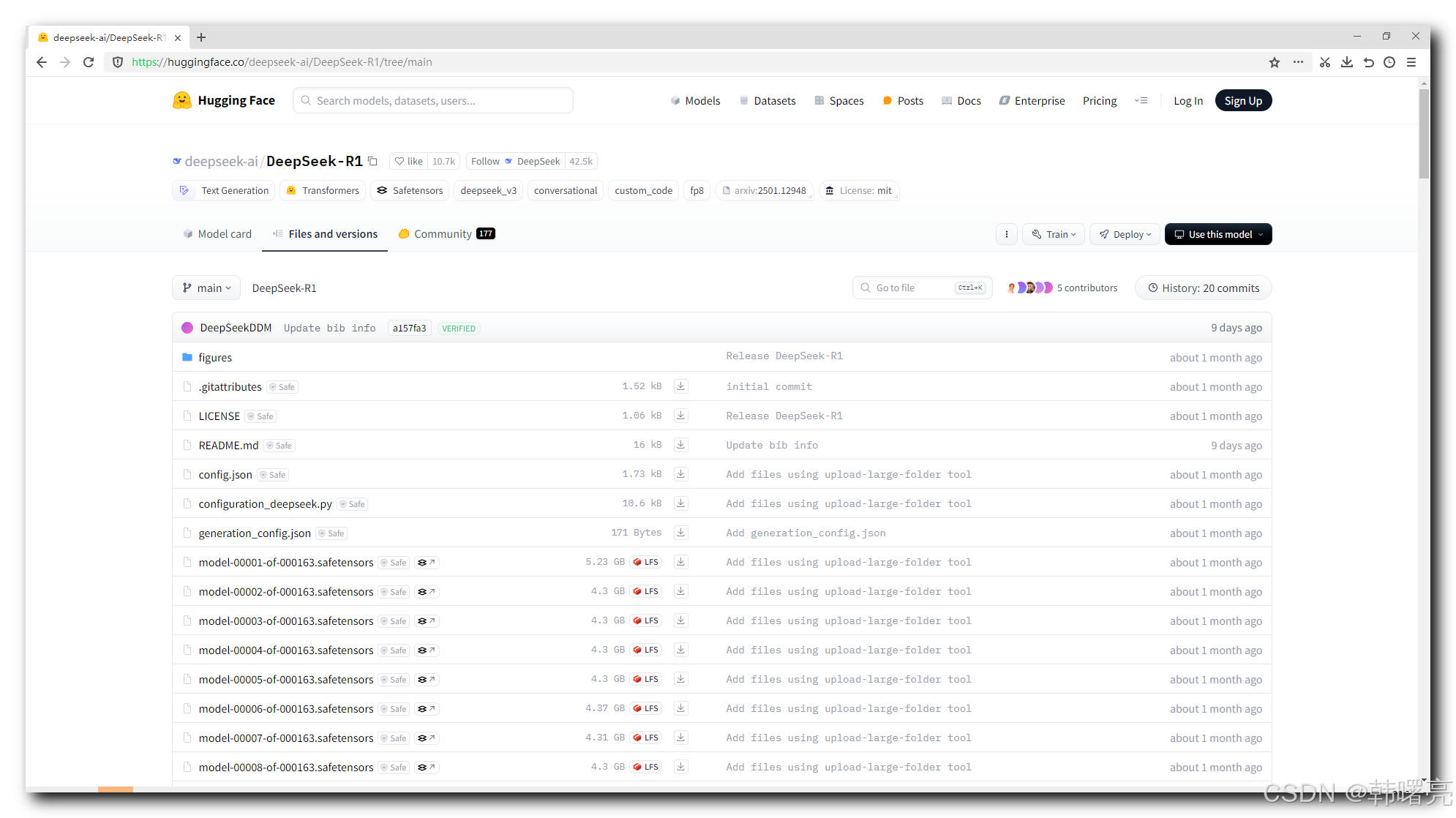
点进去以后 , 可以看到 671B 满血版的 DeepSeek-R1 模型的文件 , 满血版模型有几百个 4.3GB 的文件组成 , 运行需要 20 张左右的 A100 显卡 ;
2、查询文本向量模型
这里 我们要本地部署 RAG 相关的 向量模型 , 之前使用的是 OpenAI 的 text-embedding-ada-002 文本向量模型 , 这个模型必须在线使用 , 并且使用时 消耗 Token , 需要付费使用 ;
这里我们到 Hugging Face 模型库 中 , 选择一款 开源免费的 文本向量模型 , 实现 文本 转 向量 的工作 ;
在 https://huggingface.co/models 页面中 , 选择
-
Sentence Similarity 任务类型 :
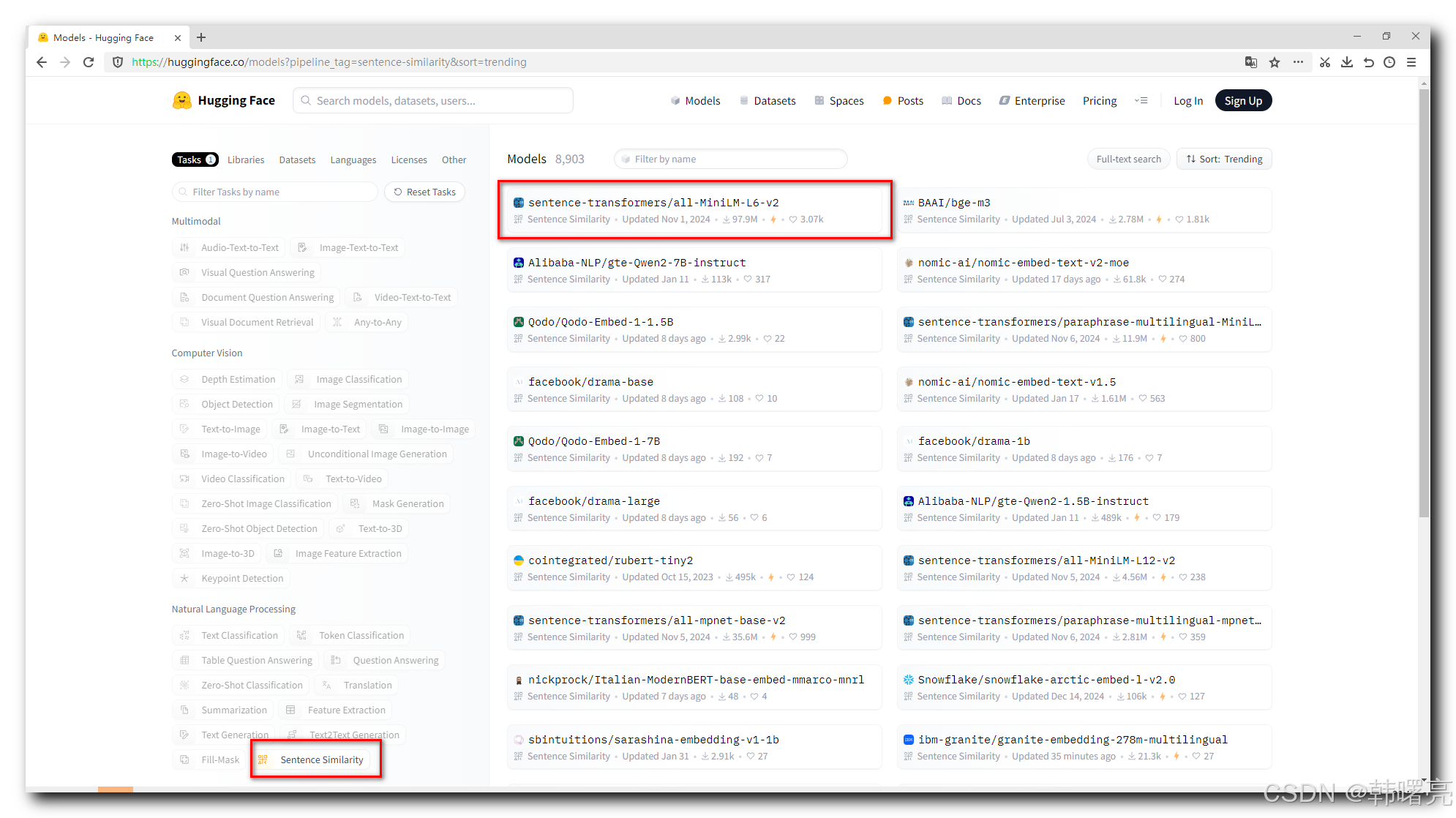
-
Feature Extraction 任务类型 :
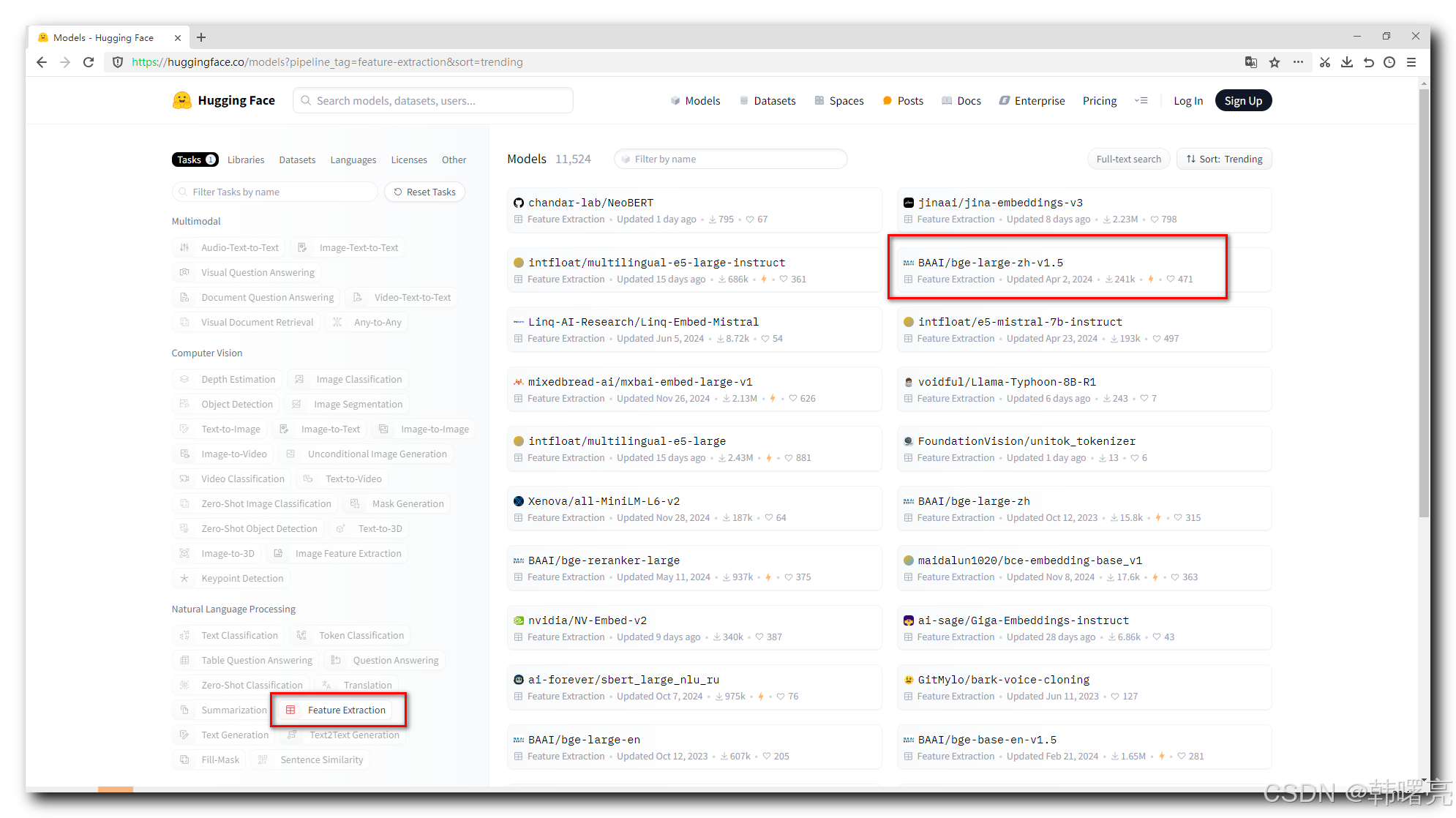
就可以找到 文本向量 相关的模型 ;
3、筛选适合中文的 文本向量模型
在 Sentence Transformer 文档 https://sbert.net/docs/quickstart.html 中 ,
默认使用的 " sentence-transformers/all-MiniLM-L6-v2 " 模型 , https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 , 设计为多语言模型,支持包括中文在内的多种语言 , 但中文优化程度较低 , 语义捕捉能力弱于专用中文模型 , 适合
- 多语言混合场景下的基础语义检索 ;
- 资源受限环境 , 如 : 移动端 / 边缘设备 ;
- 对中文质量要求不高的快速原型开发 ;
" BAAI/bge-large-zh-v1.5 " 模型 , https://huggingface.co/BAAI/bge-large-zh-v1.5 , 专为中文优化的文本向量模型 , 中文语义理解能力强,支持成语、古汉语等复杂表达 , 适用于
- 中文语义搜索/问答系统 ;
- 高精度文本相似度计算 ;
- 需要捕捉深层语义关系的场景 , 如 : 法律/医疗文本 ;
4、BAAI 与 BGE 模型
BAAI 全称 Beijing Academy of Artificial Intelligence 是 " 北京智源人工智能研究院 " , 成立于2018年 , 是由北京市政府支持成立的非营利性研究机构 , 开发了很多开源模型 ;
BAAI 官网 https://www.baai.ac.cn/
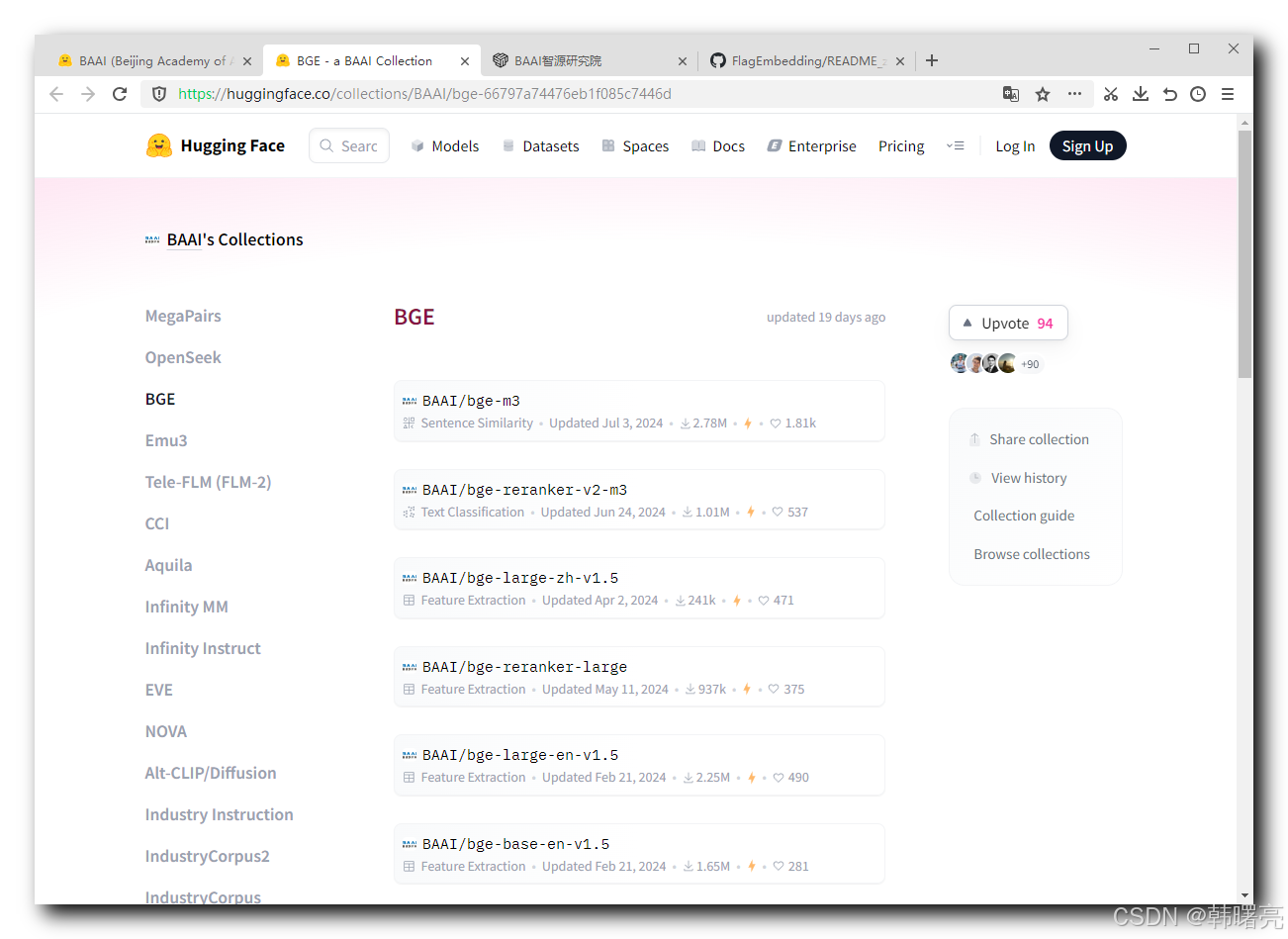
BGE ( BAAI General Embedding ) 专注于检索增强 llm 领域 , https://huggingface.co/collections/BAAI/bge-66797a74476eb1f085c7446d 页面 中 列举出了 所有的 BAAI 的 BGE 模型 ;
https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
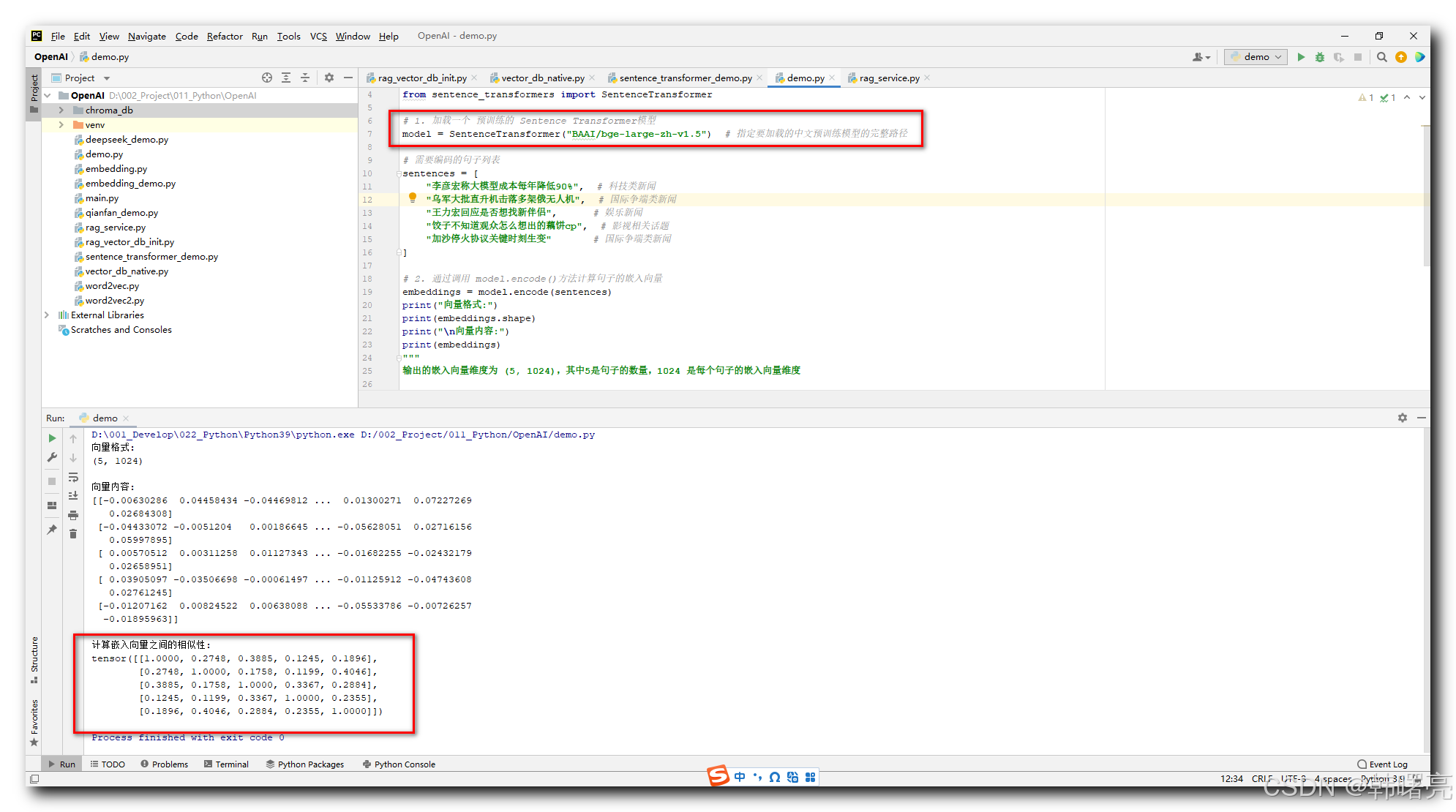
四、使用 BAAI/bge-large-zh-v1.5 模型进行向量转化
1、向量转化示例
将 https://sbert.net/docs/quickstart.html 文档 提供的 Sentence Transformer 示例 中 默认使用的 " sentence-transformers/all-MiniLM-L6-v2 " 模型 , 修改为 对中文支持更好的 " BAAI/bge-large-zh-v1.5 " 模型 ,
完整代码如下 :
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
from sentence_transformers import SentenceTransformer
# 1. 加载一个 预训练的 Sentence Transformer模型
model = SentenceTransformer("BAAI/bge-large-zh-v1.5") # 指定要加载的中文预训练模型的完整路径
# 需要编码的句子列表
sentences = [
"李彦宏称大模型成本每年降低90%", # 科技类新闻
"乌军大批直升机击落多架俄无人机", # 国际争端类新闻
"王力宏回应是否想找新伴侣", # 娱乐新闻
"饺子不知道观众怎么想出的藕饼cp", # 影视相关话题
"加沙停火协议关键时刻生变" # 国际争端类新闻
]
# 2. 通过调用 model.encode()方法计算句子的嵌入向量
embeddings = model.encode(sentences)
print("向量格式:")
print(embeddings.shape)
print("\n向量内容:")
print(embeddings)
"""
输出的嵌入向量维度为 (5, 1024),其中5是句子的数量,1024 是每个句子的嵌入向量维度
(5, 1024)
"""
# 3. 计算嵌入向量之间的相似性
similarities = model.similarity(embeddings, embeddings)
print("\n计算嵌入向量之间的相似性:")
print(similarities)
"""
最终打印出的 similarities 是一个 5x5 的矩阵 , 表示每两个句子之间的相似性得分
tensor([[1.0000, 0.2748, 0.3885, 0.1245, 0.1896],
[0.2748, 1.0000, 0.1758, 0.1199, 0.4046],
[0.3885, 0.1758, 1.0000, 0.3367, 0.2884],
[0.1245, 0.1199, 0.3367, 1.0000, 0.2355],
[0.1896, 0.4046, 0.2884, 0.2355, 1.0000]])
"""
执行结果 :
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/OpenAI/demo.py
向量格式:
(5, 1024)
向量内容:
[[-0.00630286 0.04458434 -0.04469812 ... 0.01300271 0.07227269
0.02684308]
[-0.04433072 -0.0051204 0.00186645 ... -0.05628051 0.02716156
0.05997895]
[ 0.00570512 0.00311258 0.01127343 ... -0.01682255 -0.02432179
0.02658951]
[ 0.03905097 -0.03506698 -0.00061497 ... -0.01125912 -0.04743608
0.02761245]
[-0.01207162 0.00824522 0.00638088 ... -0.05533786 -0.00726257
-0.01895963]]
计算嵌入向量之间的相似性:
tensor([[1.0000, 0.2748, 0.3885, 0.1245, 0.1896],
[0.2748, 1.0000, 0.1758, 0.1199, 0.4046],
[0.3885, 0.1758, 1.0000, 0.3367, 0.2884],
[0.1245, 0.1199, 0.3367, 1.0000, 0.2355],
[0.1896, 0.4046, 0.2884, 0.2355, 1.0000]])
Process finished with exit code 0
2、查看下载到本地的模型
上述代码中 , 初次执行时 , 会下载 " BAAI/bge-large-zh-v1.5 " 模型到本地 ,
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
from sentence_transformers import SentenceTransformer
# 1. 加载一个 预训练的 Sentence Transformer模型
model = SentenceTransformer("BAAI/bge-large-zh-v1.5") # 指定要加载的中文预训练模型的完整路径
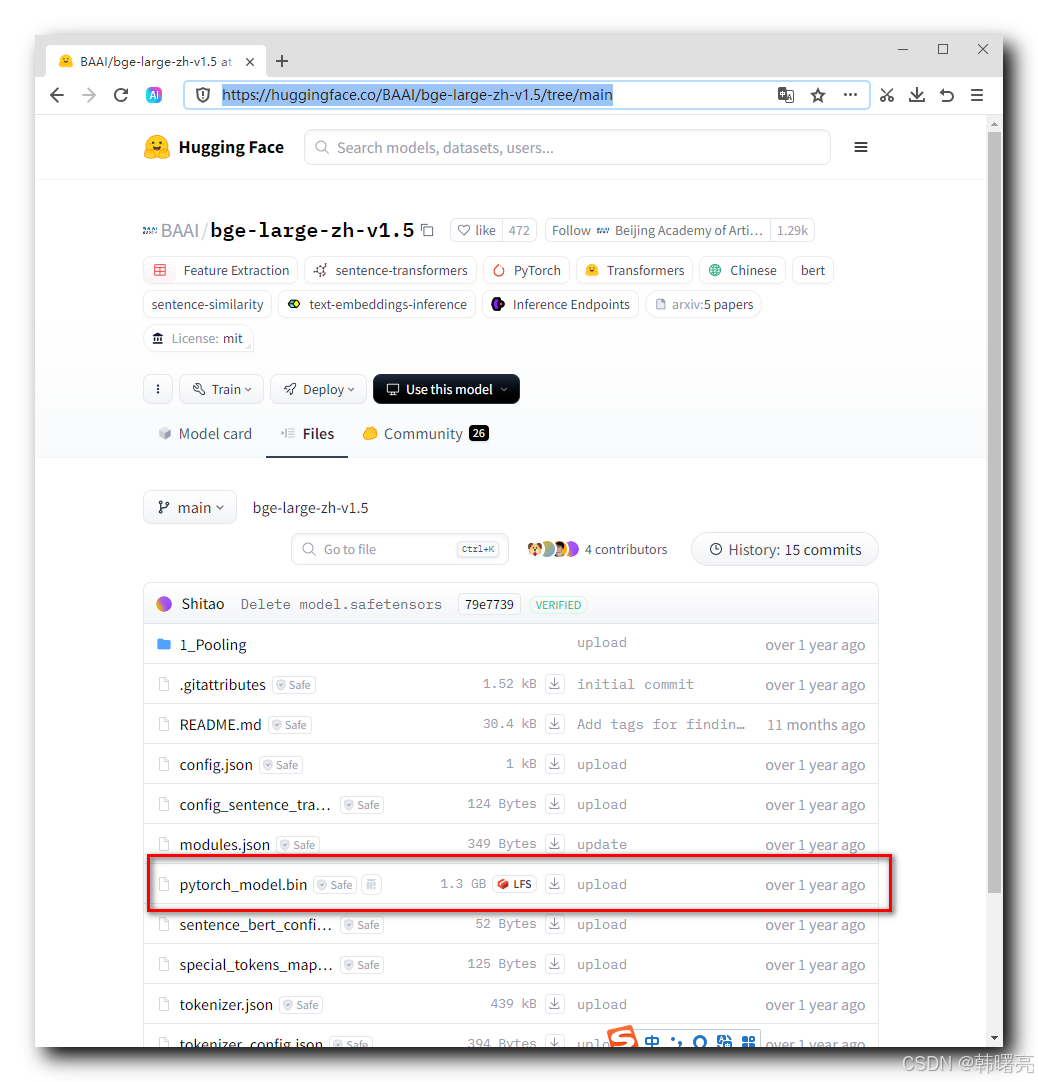
" BAAI/bge-large-zh-v1.5 " 模型地址如下 ,
https://huggingface.co/BAAI/bge-large-zh-v1.5/tree/main
查看 文件 , 该模型的二进制文件 pytorch_model.bin 有 1.3G 大小 ;
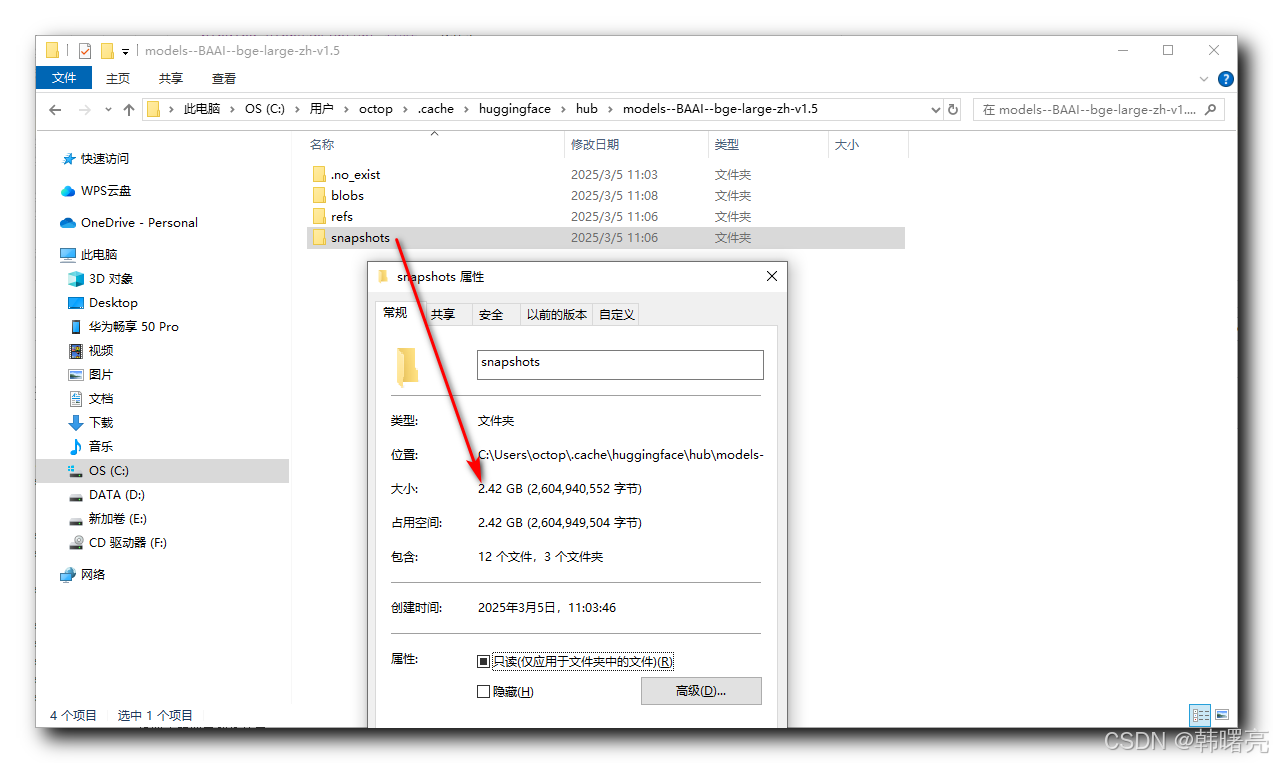
在 WIndows 平台 , 模型会自动下载到 " C:\Users\octop.cache\huggingface\hub\models–BAAI–bge-large-zh-v1.5 " 目录中 , 会下载 2.5G 左右的文件 ;
3、使用本地部署的 " BAAI/bge-large-zh-v1.5 " 模型计算文本向量实例
在 【AI 大模型】RAG 检索增强生成 ⑤ ( 向量数据库 | 向量数据库 索引结构和搜索算法 | 常见 向量数据库 对比 | 安装并使用 向量数据库 chromadb 案例 ) 博客中 , 使用的是 OpenAI 的 text-embedding-ada-002 文本向量模型 将 文本转为 向量 , 然后插入数据库 中 , 然后再 根据 向量 从数据库中查询 相似的文档 ;
这里我们使用 本地部署的 " BAAI/bge-large-zh-v1.5 " 模型 替换上面的 OpenAI 的 text-embedding-ada-002 文本向量模型 进行向量计算 ;
核心实现是将 get_embeddings 函数中 的 OpenAI 相关函数
from openai import OpenAI # OpenAI 客户端
# 初始化 OpenAI 客户端 (替换成自己的 API 信息)
client = OpenAI(
api_key="sk-i3dHaF6", # 替换为你的 OpenAI API Key , 这里我把自己的 API-KEY 隐藏了
base_url="https://api.xiaoai.plus/v1" # 替换为你的 API 服务端点
)
def get_embeddings(texts, model="text-embedding-ada-002"):
"""将文本转换为向量表示
Args:
texts: 需要编码的文本列表
model: 使用的嵌入模型(默认OpenAI官方推荐模型)
Returns:
包含向量数据的列表,每个元素对应输入文本的768维向量
"""
response = client.embeddings.create(
input=texts,
model=model
)
# 从响应中提取向量数据
return [item.embedding for item in response.data]
替换为 SentenceTransformer 的 使用 “BAAI/bge-large-zh-v1.5” 模型转换向量的函数
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
from sentence_transformers import SentenceTransformer
def get_embeddings(texts):
"""将文本转换为向量表示
:param texts: 需要编码的文本列表
:return:
包含向量数据的列表,每个元素对应输入文本的768维向量
"""
# 1. 加载一个 预训练的 Sentence Transformer模型
model = SentenceTransformer("BAAI/bge-large-zh-v1.5") # 指定要加载的中文预训练模型的完整路径
# 2. 通过调用 model.encode()方法计算句子的嵌入向量
embeddings = model.encode(texts)
# 从响应中提取向量数据
return embeddings
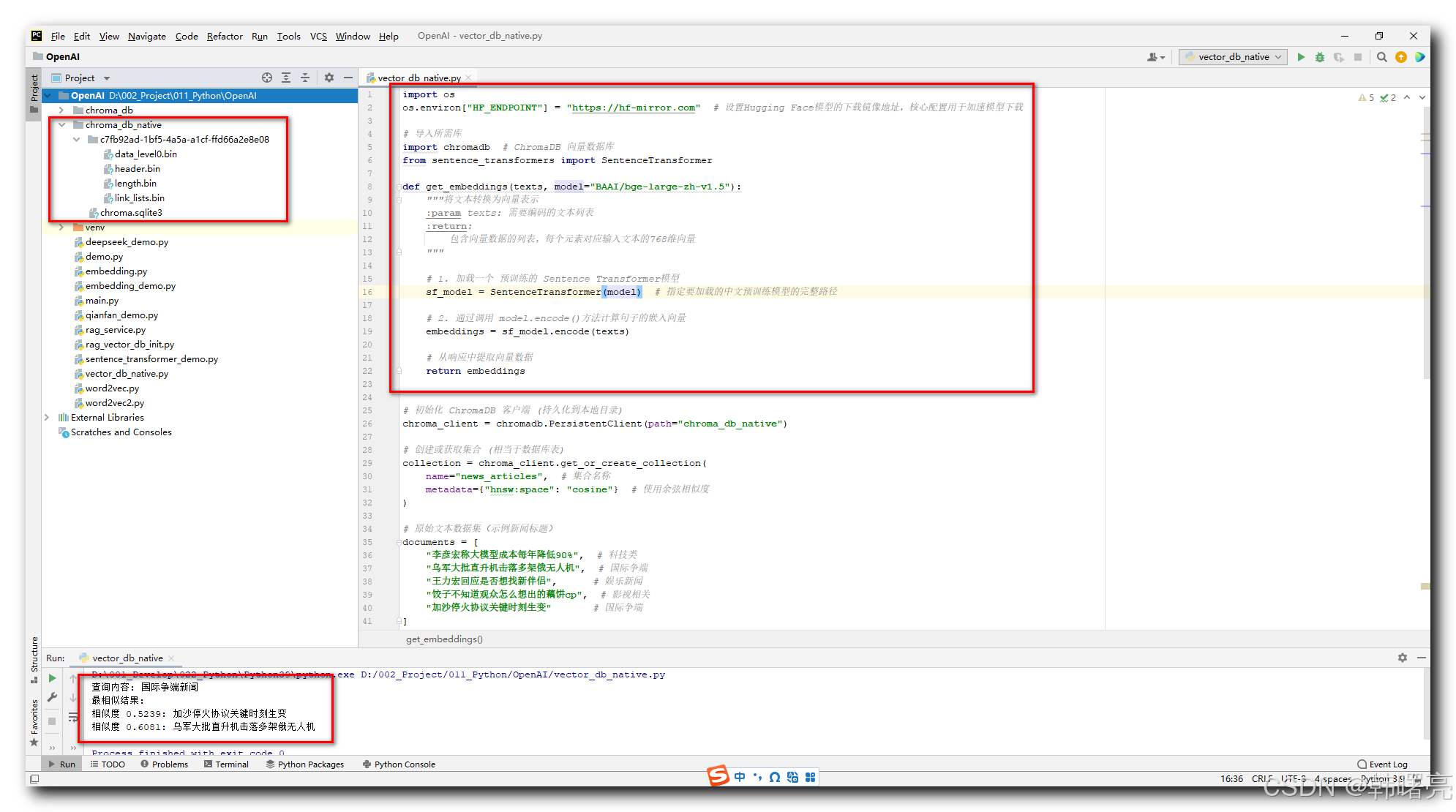
完整代码如下 :
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
# 导入所需库
import chromadb # ChromaDB 向量数据库
from sentence_transformers import SentenceTransformer
def get_embeddings(texts, model="BAAI/bge-large-zh-v1.5"):
"""将文本转换为向量表示
:param texts: 需要编码的文本列表
:return:
包含向量数据的列表,每个元素对应输入文本的768维向量
"""
# 1. 加载一个 预训练的 Sentence Transformer模型
sf_model = SentenceTransformer(model) # 指定要加载的中文预训练模型的完整路径
# 2. 通过调用 model.encode()方法计算句子的嵌入向量
embeddings = sf_model.encode(texts)
# 从响应中提取向量数据
return embeddings
# 初始化 ChromaDB 客户端 (持久化到本地目录)
chroma_client = chromadb.PersistentClient(path="chroma_db_native")
# 创建或获取集合 (相当于数据库表)
collection = chroma_client.get_or_create_collection(
name="news_articles", # 集合名称
metadata={"hnsw:space": "cosine"} # 使用余弦相似度
)
# 原始文本数据集(示例新闻标题)
documents = [
"李彦宏称大模型成本每年降低90%", # 科技类
"乌军大批直升机击落多架俄无人机", # 国际争端
"王力宏回应是否想找新伴侣", # 娱乐新闻
"饺子不知道观众怎么想出的藕饼cp", # 影视相关
"加沙停火协议关键时刻生变" # 国际争端
]
# 批量生成文档向量
document_embeddings = get_embeddings(documents)
# 生成唯一文档 ID (需要唯一标识符)
document_ids = [str(i) for i in range(len(documents))] # 生成 ["0", "1", ..., "4"]
# 将文档插入数据库
collection.add(
ids=document_ids, # 唯一ID列表
embeddings=document_embeddings, # 文本向量列表
documents=documents # 原始文本列表
)
# 查询文本
query_text = "国际争端新闻"
# 生成查询向量
query_embedding = get_embeddings([query_text])[0]
# 执行相似性查询
results = collection.query(
query_embeddings=[query_embedding], # 查询向量
n_results=2 # 返回前2个最相似结果
)
# 打印查询结果
print("查询内容:", query_text)
print("最相似结果:")
for doc, score in zip(results['documents'][0], results['distances'][0]):
print(f"相似度 {score:.4f}: {doc}")
执行结果 :
查询内容: 国际争端新闻
最相似结果:
相似度 0.5239: 加沙停火协议关键时刻生变
相似度 0.6081: 乌军大批直升机击落多架俄无人机

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









