







上一节自动驾驶3D视觉入门之路(二)——坐标系转换(1)-CSDN博客主要介绍了3D空间坐标系的转换,本节我们重点关注3D空间与2D空间的坐标系转换。
1. 3D -> 2D的坐标系转换
经典的3D -> 2D的坐标系转换就是相机坐标系 -> 像素坐标系的转换,而相机与画布之间的标定关系常用相机内参表示,那什么是相机内参呢?或者相机内参的数据格式是什么样的?
1.1 相机内参矩阵
定义内参矩阵如下:
其中,与
分别表示x轴与y周的焦距,焦距就是真空与图像平面(投影屏幕)的距离,类似于人眼和视网膜,焦距的度量是针对像素的。如下图红线部分即指代焦距。
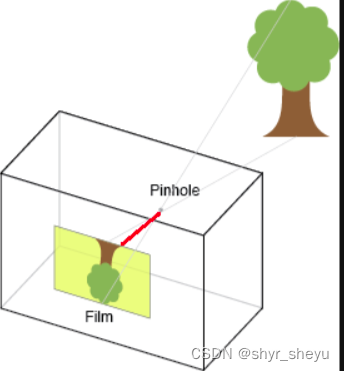
而、
表示相机坐标系原点与像素坐标系原点在x轴和y轴的偏移量。
1.2 图像坐标系变换
先上公式:
套用上述公式即可完成图像坐标系到像素坐标的转换, 其中即为相机内参矩阵,
、
即像素坐标;
、
和
分别表示相机坐标系下的点云坐标。那为什么要在z轴方向上做归一化操作呢?这是因为像素坐标系不存在Z轴,所以需要用一个单位向量补齐,因此相机坐标系下也需要对Z轴做单位化操作后才可以进行转换。
至此,相机到图像的坐标系转换就完成了,是不是非常简单,对应代码:
def cam2img(points_cam, K):
points_cam[:0] = points_cam[:0] / points_cam[:,2]
points_cam[:1] = points_cam[:1] / points_cam[:,2]
points_cam_new = np.concatenate([points_cam[:0],points_cam[:1],np.ones])
uv_coor = K * points_cam_new
return uv_coor1.3 深度图建立
通过相机内参可以实现图像坐标系到像素坐标系的转换,那在实际项目中可以用来做什么呢?第一个比较重要的应用就是创建深度标签,纯视觉pipeline中比较重要组成部分就是深度监督网络,那么做深度训练就需要深度标签,如何获取质量好的深度标签呢?现在主流的方式都是通过lidar点采样,并投影至像素坐标系上实现深度标签构建。那么我们简单学习这个pipeline是如何完成的,仍然以nuscenens一个case场景为例,先上代码:
import numpy as np
from nuscenes.nuscenes import NuScenes
from pyquaternion import Quaternion
import numpy as np
from pyquaternion import Quaternion
import cv2
def get_R_T(quat, trans):
"""
Args:
quat: 四元素,eg.[w,x,y,z]
trans: 偏移量,eg.[x',y',z']
Return:
RT: 转移矩阵
"""
RT = np.eye(4)
RT[:3,:3] = Quaternion(quat).rotation_matrix
RT[:3,3] = np.array(trans)
return RT
nusc = NuScenes(version='v1.0-trainval', dataroot='./data/nuscenes', verbose=True)
scene = nusc.scene[0]
def trans_coor(nusc, scene):
cur_sample = nusc.get('sample', scene['first_sample_token'])
lidar_path, gt_boxes, _ = nusc.get_sample_data(cur_sample['data']['LIDAR_TOP']) # 获取lidar路径
pts_lidar = np.fromfile(lidar_path, dtype=np.float32).reshape(-1,5) #读取lidar数据,前三维为x,y,z,此时点云处于lidar坐标系
#读取lidar传感器外参
sd_rec = nusc.get('sample_data', cur_sample['data']['LIDAR_TOP'])
cs_record = nusc.get('calibrated_sensor', sd_rec['calibrated_sensor_token'])
lidar2ego_translation = cs_record['translation']
lidar2ego_quat = cs_record['rotation']
#读取ego位姿信息
pose_record = nusc.get('ego_pose', sd_rec['ego_pose_token'])
ego2global_translation = pose_record['translation']
ego2global_rotation = pose_record['rotation']
#读取相机info
camera_types = 'CAM_FRONT'
cam_token = cur_sample['data'][camera_types]
cam_path, _, K = nusc.get_sample_data(cam_token)
cam_rec = nusc.get('sample_data', cam_token)
cam_record = nusc.get('calibrated_sensor',
cam_rec['calibrated_sensor_token'])
cam2ego_translation = cam_record['translation']
cam2ego_rotation = cam_record['rotation']
cam_pose_record = nusc.get('ego_pose', cam_rec['ego_pose_token'])
camego2global_translation = cam_pose_record['translation']
camego2global_rotation = cam_pose_record['rotation']
img = cv2.imread(cam_path)
height, width,c = img.shape
#计算旋转矩阵
lidar2ego_RT = get_R_T(lidar2ego_quat, lidar2ego_translation) # lidar -> ego
ego2global_RT = get_R_T(ego2global_rotation, ego2global_translation) # lidarego -> global
cam2ego_RT = get_R_T(cam2ego_rotation, cam2ego_translation) # cam -> ego
camego2global_RT = get_R_T(camego2global_rotation, camego2global_translation) # camego -> global
lidar2global = ego2global_RT @ lidar2ego_RT # lidar -> global
cam2global = camego2global_RT @ cam2ego_RT # cam -> global
lidar2cam = np.linalg.inv(cam2global) @ lidar2global # lidar -> cam
cam2img = np.eye(4)
cam2img[:3,:3] = K
lidar2img = cam2img @ lidar2cam # lidar -> img
# 坐标系转换,构建深度图
point_img = (lidar2img[:3,:3] @ pts_lidar[:,:3].T).T + lidar2img[:3,3]
points = np.concatenate(
[point_img[:, :2] / point_img[:, 2:3],
point_img[:, 2:3]], 1).astype(np.float32)
depth_map = np.zeros((height, width), dtype=np.float32)
coor = np.round(points[:, :2])
depth = points[:, 2]
kept1 = (coor[:, 0] >= 0) & (coor[:, 0] < width) & \
(coor[:, 1] >= 0) & (coor[:, 1] < height) & \
(depth < 80) & (depth > 0)
coor, depth = coor[kept1], depth[kept1]
coor = coor.astype(np.int32)
depth_map[coor[:, 1], coor[:, 0]] = depth
#可视化深度图
for u in range(width):
for v in range(height):
if depth_map[v,u] > 0:
cv2.circle(img, (int(u), int(v)), 1, (0, 255, 0), 1)
cv2.imwrite('test_depth.jpg',img)
trans_coor(nusc, scene)可视化结果如下:

由于lidar点是比较稀疏的,所以构建的深度图也是很稀疏的。 整体的转换逻辑就是按照lidar -> ego -> global -> camego -> cam ->img 这一条pipeline进行实现的,主要包含上篇中的3D坐标系转换与本篇中的3D -> 2D坐标系转换原理,理解具体含义后就没那么难了~
1.4 lidar点云颜色渲染
第二个比较重要的应用就是渲染了,不管是最近大火的Nerf,还是世界模型、扩散模型基本上都会基于渲染的方式进行染色,从而实现逼真纹理,达到效果较好的虚拟现实或三维重建。那么我们可以通过坐标系转换的方式实现一个简易版本的颜色渲染,优点是渲染方式简单、效率块,缺点是缺少多视图,会存在部分点云无法染色,重建不够稠密等,直接上代码~:
import numpy as np
from nuscenes.nuscenes import NuScenes
from pyquaternion import Quaternion
import numpy as np
from pyquaternion import Quaternion
import cv2
def get_R_T(quat, trans):
"""
Args:
quat: 四元素,eg.[w,x,y,z]
trans: 偏移量,eg.[x',y',z']
Return:
RT: 转移矩阵
"""
RT = np.eye(4)
RT[:3,:3] = Quaternion(quat).rotation_matrix
RT[:3,3] = np.array(trans)
return RT
nusc = NuScenes(version='v1.0-trainval', dataroot='./data/nuscenes', verbose=True)
scene = nusc.scene[0]
def render_color(nusc, scene):
cur_sample = nusc.get('sample', scene['first_sample_token'])
lidar_path, gt_boxes, _ = nusc.get_sample_data(cur_sample['data']['LIDAR_TOP']) # 获取lidar路径
pts_lidar = np.fromfile(lidar_path, dtype=np.float32).reshape(-1,5) #读取lidar数据,前三维为x,y,z,此时点云处于lidar坐标系
#读取lidar传感器外参
sd_rec = nusc.get('sample_data', cur_sample['data']['LIDAR_TOP'])
cs_record = nusc.get('calibrated_sensor', sd_rec['calibrated_sensor_token'])
lidar2ego_translation = cs_record['translation']
lidar2ego_quat = cs_record['rotation']
#读取ego位姿信息
pose_record = nusc.get('ego_pose', sd_rec['ego_pose_token'])
ego2global_translation = pose_record['translation']
ego2global_rotation = pose_record['rotation']
#计算旋转矩阵
lidar2ego_RT = get_R_T(lidar2ego_quat, lidar2ego_translation) # lidar -> ego
ego2global_RT = get_R_T(ego2global_rotation, ego2global_translation) # lidarego -> global
# 初始化RGB颜色信息
color = np.ones((pts_lidar.shape[0],3)) * 255
#读取相机info
camera_types = [
'CAM_FRONT',
'CAM_FRONT_RIGHT',
'CAM_FRONT_LEFT',
'CAM_BACK',
'CAM_BACK_LEFT',
'CAM_BACK_RIGHT',
]
for cam in camera_types:
cam_token = cur_sample['data'][cam]
cam_path, _, K = nusc.get_sample_data(cam_token)
cam_rec = nusc.get('sample_data', cam_token)
cam_record = nusc.get('calibrated_sensor',
cam_rec['calibrated_sensor_token'])
cam2ego_translation = cam_record['translation']
cam2ego_rotation = cam_record['rotation']
cam_pose_record = nusc.get('ego_pose', cam_rec['ego_pose_token'])
camego2global_translation = cam_pose_record['translation']
camego2global_rotation = cam_pose_record['rotation']
img = cv2.imread(cam_path)
height, width,c = img.shape
cam2ego_RT = get_R_T(cam2ego_rotation, cam2ego_translation) # cam -> ego
camego2global_RT = get_R_T(camego2global_rotation, camego2global_translation) # camego -> global
lidar2global = ego2global_RT @ lidar2ego_RT # lidar -> global
cam2global = camego2global_RT @ cam2ego_RT # cam -> global
lidar2cam = np.linalg.inv(cam2global) @ lidar2global # lidar -> cam
cam2img = np.eye(4)
cam2img[:3,:3] = K
lidar2img = cam2img @ lidar2cam # lidar -> img
# 坐标系转换
point_img = (lidar2img[:3,:3] @ pts_lidar[:,:3].T).T + lidar2img[:3,3]
points = np.concatenate(
[point_img[:, :2] / point_img[:, 2:3],
point_img[:, 2:3]], 1).astype(np.float32)
coor = np.round(points[:, :2])
depth = points[:, 2]
kept1 = (coor[:, 0] >= 0) & (coor[:, 0] < width) & \
(coor[:, 1] >= 0) & (coor[:, 1] < height) & \
(depth < 80) & (depth > 0)
coor = coor.astype(np.int32)
#颜色渲染
color[kept1] = img[coor[kept1][:,1].astype(np.int32),
coor[kept1][:,0].astype(np.int32), :]
#可视化点云
import open3d
pts = open3d.geometry.PointCloud()
pts.points = open3d.utility.Vector3dVector(pts_lidar[:,:3])
pts.colors = open3d.utility.Vector3dVector(color / 255.)
open3d.io.write_point_cloud("./color_label.pcd", pts)
render_color(nusc, scene)核心逻辑就是通过lidar坐标系转换到img坐标系下,根据img对应的RGB值赋予点云,从而实现点云渲染功能。
可视化效果图:

可以看到由于自车周围的点云属于相机的盲区,所以无法染色,其他区域的点云都被渲染了对应的图像颜色。
2. 2D -> 3D的坐标系转换
从像素坐标系转换到相机坐标系本质上就是从2D逆变换到3D,通过对上式求逆,可得到以下公式:
此时,如可提前得知每个像素对应的深度值,即,那么便可转换到3D空间。那么如何获得像素的深度值呢?第一种方式就是通过lidar点投影的方式得到部分像素点的深度真值,第二种方式就是通过深度预测网络或者MVS多视角立体几何等方式预测稠密的深度图,从而可以转到到3D空间,为下游模块提供3D空间特征。
2D -> 3D的转换模块是BEV架构的重要组成部分,下一节我们将介绍BEV网络的开山之作——LSS架构,其中的bev特征提取网络就是使用了2D转3D的坐标系转换方法,这也使纯视觉或多模态性能良好的重要结构。
3. 总结
本篇内容主要还是阐述3D视觉中的重要坐标系转换,这也是入门3D视觉最重要的理论基础!后面我们将正式开始接触当前大火3D视觉核心模块——BEV模型啦~
如果觉得内容有所帮助的老铁,麻烦给个点赞、关注、收藏!!~
如有问题,劳烦指正!!~















 3875
3875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









