







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在上一章中,我们了解了神经网络的基本构建块,并在 Python 中从头开始实现了前向和反向传播。
在本章中,我们将深入探讨使用 PyTorch 构建神经网络的基础知识,当我们了解图像分析中的各种用例时,我们将在后续章节中多次使用它。我们将首先了解 PyTorch 处理的核心数据类型——张量对象。然后,我们将深入研究可以在张量对象上执行的各种操作,以及在玩具数据集之上构建神经网络模型时如何利用它们(以便我们在逐步查看更现实的数据集之前加强我们的理解,开始与下一章)。这将使我们能够直观地了解如何使用 PyTorch 构建神经网络模型来映射输入和输出值。最后,
具体来说,本章将涵盖以下主题:
- 安装 PyTorch
- PyTorch 张量
- 使用 PyTorch 构建神经网络
- 使用sequential方法构建神经网络
- 保存和加载 PyTorch 模型
安装 PyTorch
PyTorch提供了多种功能来帮助构建神经网络——使用高级方法抽象各种组件,并为我们提供利用 GPU 更快地训练神经网络的张量对象。
在安装 PyTorch 之前,我们首先需要安装 Python,如下:
1.要安装 Python,我们将使用anaconda.com/distribution/平台来获取一个安装程序,该安装程序将自动为我们安装 Python 以及重要的深度学习专用库:

选择最新 Python 版本 3.xx(截至撰写本书时为 3.7)的图形安装程序并下载。
2.使用下载的安装程序安装它:
在安装过程中选择将Anaconda 添加到我的 PATH 环境变量python选项,因为这样可以在我们输入命令提示符/终端时轻松调用 Anaconda 的 Python 版本。

接下来,我们将安装同样简单的 PyTorch。
3.访问https://pytorch.org/网站上的QUICK START LOCALLY部分,然后选择您的操作系统(您的操作系统),为Package选择Conda,为Language选择Python,为CUDA选择None。如果你有 CUDA 库,你可以选择合适的版本:
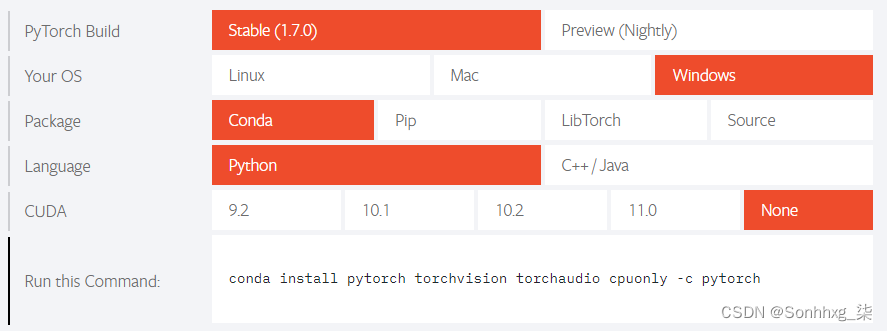
这将提示您conda install pytorch torchvision cpuonly -c pytorch在终端中运行命令。
4.在命令提示符/终端中运行命令,然后让 Anaconda 安装 PyTorch 和必要的依赖项。
如果您拥有 NVIDIA 显卡作为硬件组件,强烈建议安装 CUDA 驱动程序,它可以将深度学习训练速度提高几个数量级。有关如何安装 CUDA 驱动程序的说明,请参阅附录。安装它们后,您可以选择10.1作为 CUDA 版本并使用该命令来安装 PyTorch。
5.您可以python在命令提示符/终端中执行,然后键入以下内容以验证是否确实安装了 PyTorch:
import torch
print(torch.__version__)# '1.7.0'
至此,我们已经成功安装了 Python 和 PyTorch。我们现在将在 Python 中执行一些基本的张量操作,以帮助您掌握它。
PyTorch 张量
张量是 PyTorch 的基本数据类型。张量是类似于 NumPy 的 ndarrays 的多维矩阵:
- 标量可以表示为零维张量。
- 向量可以表示为一维张量。
- 二维矩阵可以表示为二维张量。
- 多维矩阵可以表示为多维张量。
如图所示,张量如下所示:
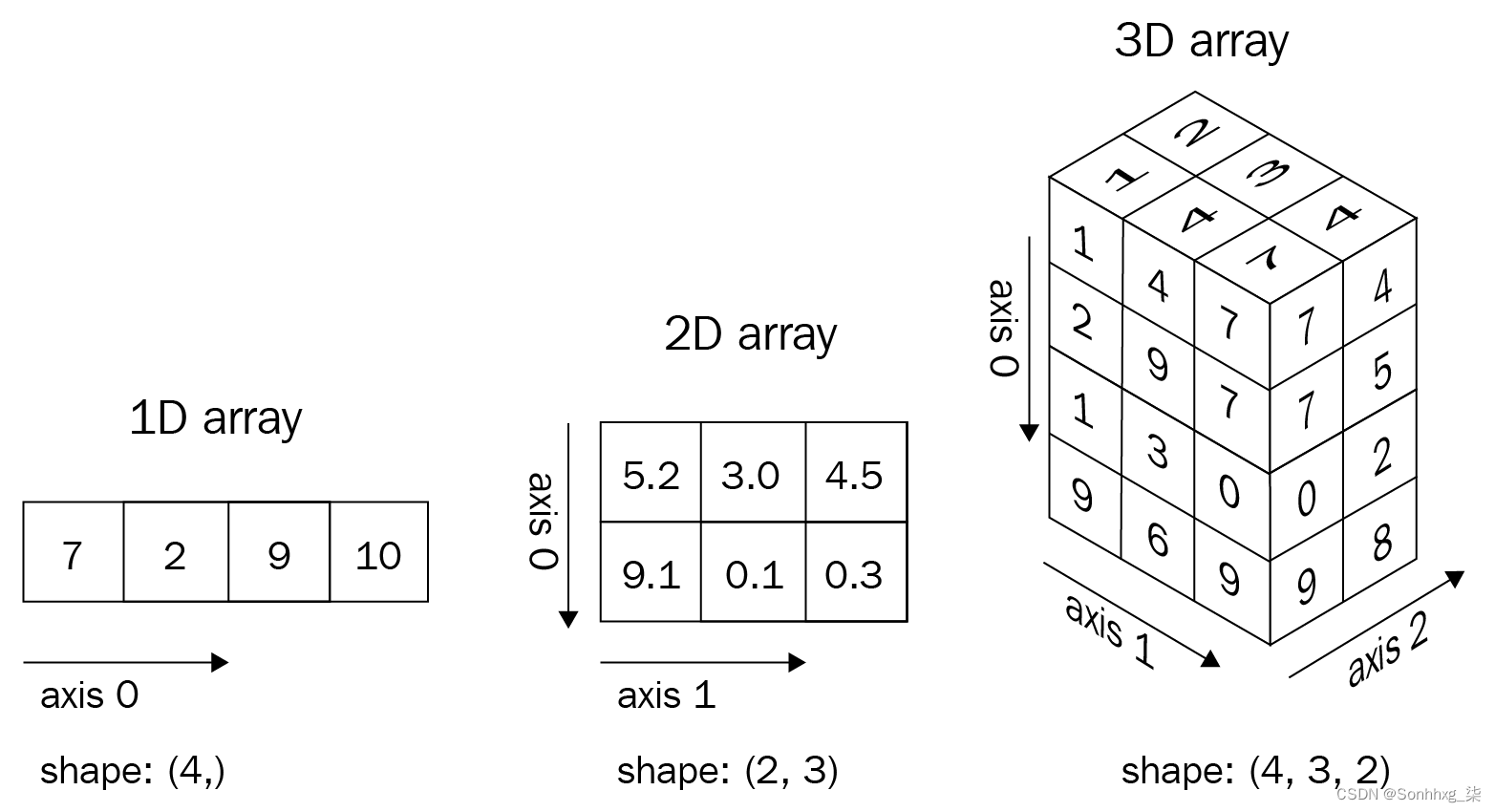
例如,我们可以将彩色图像视为像素值的三维张量,因为彩色图像由height x width x 3像素组成——其中三个通道对应于 RGB 通道。类似地,灰度图像可以被认为是二维张量,因为它由height x width像素组成。
在本节结束时,我们将了解张量为何有用以及如何初始化它们,以及在张量之上执行各种操作。这将作为我们在下一节中研究利用张量构建神经网络模型的基础。
初始化张量
张量有多种用途。除了将它们用作图像的基础数据结构之外,它们的一个更突出的用途是利用张量来初始化连接神经网络不同层的权重。
在本节中,我们将练习初始化张量对象的不同方法以下代码可Initializing_a_tensor.ipynb在
1.导入 PyTorch 并通过调用torch.tensor列表来初始化张量:
import torch
x = torch.tensor([[1,2]])
y = torch.tensor([[1],[2]])2.接下来,访问张量对象的形状和数据类型:
print(x.shape)
# torch.Size([1,2]) # one entity of two items
print(y.shape)
# torch.Size([2,1]) # two entities of one item each
print(x.dtype)
# torch.int64张量中所有元素的数据类型相同。这意味着如果张量包含不同数据类型的数据(例如布尔值、整数和浮点数),则整个张量将被强制转换为最通用的数据类型:
x = torch.tensor([False, 1, 2.0])
print(x)
# tensor([0., 1., 2.])正如您在前面代码的输出中看到的那样,False布尔值和1整数被转换为浮点数。
或者,类似于 NumPy,我们可以使用内置函数初始化张量对象。请注意,我们在张量和神经网络的权重之间绘制的相似之处现在已经显现——我们正在初始化张量,以便它们代表神经网络的权重初始化。
3.生成一个三行四列用零填充的张量对象:
torch.zeros((3, 4))4.生成一个三行四列的张量对象:
torch.ones((3, 4))5.生成 0 到 10 之间的三行四列值(包括低值但不包括高值):
torch.randint(low= 0 , high= 10 , size=( 3 , 4 ))6.生成 0 到 1 之间的三行四列随机数:
torch.rand(3, 4)7.生成 服从三行四列正态分布的数字:
torch.randn((3,4))8.最后,我们可以使用以下方法直接将 NumPy 数组转换为 Torch 张量torch.tensor(<numpy-array>):
x = np.array([[10,20,30],[2,3,4]])
y = torch.tensor(x)
print(type(x), type(y))
# <class 'numpy. ndarray'> <class 'torch.Tensor'>现在我们已经了解了初始化张量对象,我们将在下一节学习如何在它们之上执行各种矩阵运算。
张量运算
与 NumPy 类似,您可以对张量对象执行各种基本操作。与神经网络操作类似的是输入与权重的矩阵乘法、偏置项的添加以及在需要时重新调整输入或权重值。这些和附加操作中的每一个都按如下方式完成:
- 可以使用以下代码执行xby中存在的所有元素的乘法:10
import torch
x = torch.tensor([[1,2,3,4], [5,6,7,8]])
print(x * 10)
# tensor([[10, 20, 30, 40],
# [50, 60, 70, 80]])- 可以使用以下代码执行添加10到 in 中的元素x并将结果张量存储在 in中:y
x = torch.tensor([[1,2,3,4], [5,6,7,8]])
y = x.add(10)
print(y)
# tensor([[11, 12, 13, 14],
# [15, 16, 17, 18]])- 可以使用以下代码对张量进行整形:
y = torch.tensor([2, 3, 1, 0])
# y.shape == (4)
y = y.view(4,1)
# y.shape == (4, 1)- 重塑张量的另一种方法是使用该squeeze方法,我们提供要删除的轴索引。请注意,这仅适用于我们要删除的轴在该维度中只有一项时:
x = torch.randn(10,1,10)
z1 = torch.squeeze(x, 1) # similar to np.squeeze()
# 可以直接对
# x 进行同样的操作,调用squeeze和要挤出的维度
z2 = x.squeeze(1)
assert torch.all(z1 == z2)
# 两个张量中的所有元素都相等
print('Squeeze:\n', x.shape, z1.shape)
# Squeeze: torch.Size([10, 1, 10]) torch.Size([10, 10])- 与之相反的squeeze是unsqueeze,这意味着我们给矩阵添加了一个维度,可以使用以下代码来执行:
x = torch.randn(10,10)
print(x.shape)
# torch.size(10,10)
z1 = x.unsqueeze(0)
print(z1.shape)
# torch.size(1,10,10)
# 同样可以使用 [None] 索引来实现
# 添加 None 将自动创建一个假的 dim
# 在指定的轴
x = torch.randn(10,10)
z2, z3, z4 = x[None], x[:,None], x[:,:,None]
print(z2.shape, z3.shape, z4.shape)
# torch.Size([1, 10, 10])
# torch.Size([10, 1, 10])
# torch.Size([10, 10, 1])如图None所示,用于索引是一种奇特的解压方式,并且在本书中经常用于创建假通道/批次维度。
- 可以使用以下代码执行两个不同张量的矩阵乘法:
x = torch.tensor ( [ [ 1 , 2 , 3 , 4 ] , [ 5 , 6 , 7 , 8 ] ] )
print ( torch.matmul ( x, y ) )
# tensor([[11],
# [35 ]])- 或者,也可以使用@运算符执行矩阵乘法:
print(x@y)
# tensor([[11],
# [35]]) - 与concatenateNumPy 类似,我们可以使用以下cat方法执行张量的连接:
import torch
x = torch.randn(10,10,10)
z = torch.cat([x,x], axis=0) # np.concatenate()
print('Cat axis 0:', x.shape, z.shape)
# Cat axis 0: torch.Size([10, 10, 10])
# torch.Size([20, 10, 10])
z = torch.cat([x,x], axis=1) # np.concatenate()
print('Cat axis 1:', x.shape, z.shape)
# Cat axis 1: torch.Size([10, 10, 10])
# torch.Size([10, 20, 10])- 可以使用以下代码执行张量中最大值的提取:
x = torch.arange(25).reshape(5,5)
print('Max:', x.shape, x.max())
# Max: torch.Size([5, 5]) tensor(24)- 我们可以提取最大值以及存在最大值的行索引:
x.max(dim=0)
# torch.return_types.max(values=tensor([20, 21, 22, 23, 24]),
# indices=tensor([4, 4, 4, 4, 4]))请注意,在前面的输出中,我们正在跨维度获取最大值0,这是张量的行。因此,所有行中的最大值是第 4个索引中存在的值,因此indices输出也是四肢。此外,.max返回最大值和最大值的位置 ( argmax)。
同样,跨列取最大值时的输出如下:
m, argm = x.max(dim=1)
print('Max in axis 1:\n', m, argm)
# Max in axis 1: tensor([ 4, 9, 14, 19, 24])
# tensor([4, 4, 4, 4, 4])该min操作与 完全相同,max但在适用的情况下返回最小值和 arg-minimum。
- 置换张量对象的维度:
x = torch.randn(10,20,30)
z = x.permute(2,0,1) # np.permute()
print('Permute dimensions:', x.shape, z.shape)
# Permute dimensions: torch.Size([10, 20, 30])
# torch.Size([30, 10, 20])请注意,当我们在原始张量之上执行置换时,张量的形状会发生变化。
永远不要重塑(即使用tensor.view)张量来交换尺寸。即使 Torch 不会抛出错误,但这是错误的,并且会在训练期间产生无法预料的结果。如果需要交换维度,请始终使用 permute。
由于很难涵盖本书中所有可用的操作,因此重要的是要知道您可以在 PyTorch 中使用与 NumPy 几乎相同的语法来执行几乎所有 NumPy 操作。标准数学运算,例如abs, add, argsort, ceil, floor, sin, cos, tan, cumsum, cumprod, diag, eig, exp, log, log2, , log10, mean, median, mode, resize, round, sigmoid, softmax, square, sqrt,svd和transpose, 等等,可以在任何有或没有轴的张量上直接调用在适用的情况下。您可以随时运行dir(torch.Tensor) 以查看 Torch 张量的所有可能方法和help(torch.Tensor.<method>) 浏览该方法的官方帮助和文档。
接下来,我们将学习如何利用张量在数据之上执行梯度计算——这是在神经网络中执行反向传播的一个关键方面。
张量对象的自动渐变
正如我们在前一章中看到的,微分和计算梯度在更新神经网络的权重中起着至关重要的作用。PyTorch 的张量对象具有计算梯度的内置功能。
在本节中,我们将了解如何使用 PyTorch 计算张量对象的梯度:
1.定义一个张量对象,并指定它需要计算梯度:
import torch
x = torch.tensor([[2., -1.], [1., 1.]], requires_grad=True)
print(x)在上述代码中,requires_grad 参数指定要为张量对象计算梯度。
2.接下来,定义计算输出的方法,在这种特定情况下是所有输入的平方和:
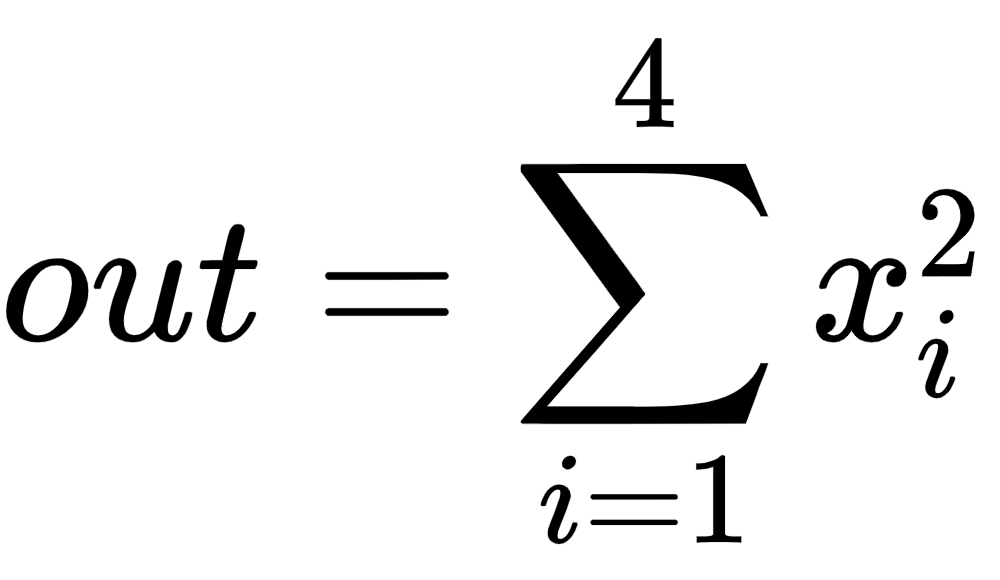
这在代码中使用以下行表示:
out = x.pow(2).sum()我们知道前面函数的梯度是2*x。让我们使用 PyTorch 提供的内置函数来验证这一点。
3.可以通过调用该值的backward()方法来计算一个值的梯度。在我们的例子中,我们计算梯度—— (输出)的变化(输入)out的微小变化x——如下:
out.backward()4.我们现在可以得到关于 的梯度out,x如下所示:
x.grad这将产生以下输出:

请注意,先前获得的梯度与直观的梯度值匹配(是x值的两倍)。
作为练习,尝试使用 PyTorch重新创建第 1 章“人工神经网络基础Chain rule.ipynb”中的场景。在进行前向传递并进行单次更新后计算梯度。验证更新后的权重是否与我们在笔记本中计算的一致。
到目前为止,我们已经了解了在张量对象之上初始化、操作和计算梯度——它们共同构成了神经网络的基本构建块。除了计算自动梯度外,还可以使用 NumPy 数组来执行初始化和操作数据。这要求我们理解在构建神经网络时应该在 NumPy 数组上使用张量对象的原因——我们将在下一节中介绍。
PyTorch 的张量相对于 NumPy 的 ndarray 的优势
在上一章中,我们看到在计算最佳权重值时,我们会稍微改变每个权重,并了解它对降低整体损失值的影响。注意,基于一个权重的权重更新的损失计算不影响同一迭代中其他权重的权重更新的损失计算。因此,如果每个权重更新由不同的核心并行进行,而不是顺序更新权重,则可以优化此过程。在这种情况下,GPU 会派上用场,因为与 CPU 相比,它包含数千个内核(通常,CPU 可能有 <=64 个内核)。
与 NumPy 相比,Torch 张量对象经过优化以与 GPU 一起使用。为了进一步理解这一点,让我们做一个小实验,我们在一个场景中使用 NumPy 数组和在另一个场景中使用张量对象执行矩阵乘法运算,并比较在两种情况下执行矩阵乘法所花费的时间:
1.生成两个不同的torch对象:
import torch
x = torch.rand(1, 6400)
y = torch.rand(6400, 5000)2.定义我们将存储在步骤 1中创建的张量对象的设备:
device = 'cuda' if torch.cuda.is_available() else 'cpu'请注意,如果您没有 GPU 设备,则该设备将是cpu(此外,您不会注意到使用 CPU 时执行时间的巨大差异)。
3.将步骤 1中创建的张量对象注册到设备中。注册张量对象意味着将信息存储在设备中:
x, y = x.to(device), y.to(device)4.执行 Torch 对象的矩阵乘法并对其计时,以便我们可以比较在 NumPy 数组上执行矩阵乘法的场景中的速度:
%timeit z=(x@y)
# 平均需要 0.515 毫秒
# 执行矩阵乘法5.在 上执行相同张量的矩阵乘法cpu:
x, y = x.cpu(), y.cpu()
%timeit z=(x@y)
# 平均需要 9 毫秒
# 执行矩阵乘法6.执行相同的矩阵乘法,这次是在 NumPy 数组上:
import numpy as np
x = np.random.random(( 1 , 6400 ))
y = np.random.random(( 6400 , 5000 ))
%timeit z = np.matmul(x,y)
# 需要19毫秒平均
# 执行矩阵乘法您会注意到,在 GPU 上对 Torch 对象执行的矩阵乘法比在 CPU 上的 Torch 对象快约 18 倍,比在 NumPy 数组上执行的矩阵乘法快约 40 倍。一般来说,matmul在 CPU 上使用 Torch 张量仍然比 NumPy 快。请注意,只有当您拥有 GPU 设备时,您才会注意到这种加速。如果您在 CPU 设备上工作,您不会注意到速度的显着提高。这就是为什么如果您没有 GPU,我们建议您使用 Google Colab 笔记本,因为该服务提供免费的 GPU。
现在我们已经了解了张量对象如何在神经网络的各个单独组件/操作中被利用,以及如何使用 GPU 来加速计算,在下一节中,我们将学习如何将所有这些放在一起以使用火炬。
使用 PyTorch 构建神经网络
在上一章中,我们学习了从零开始构建神经网络,其中神经网络的组件如下:
- 隐藏层数
- 隐藏层中的单元数
- 在各个层执行的激活函数
- 我们尝试优化的损失函数
- 与神经网络相关的学习率
- 用于构建神经网络的数据批量大小
- 正向和反向传播的 epoch 数
然而,对于所有这些,我们使用 Python 中的 NumPy 数组从头开始构建它们。在本节中,我们将学习如何在玩具数据集上使用 PyTorch 实现所有这些。请注意,在使用 PyTorch 构建神经网络时,我们将利用迄今为止关于初始化张量对象、在它们之上执行各种操作以及计算梯度值以更新权重的学习。
请注意,在本章中,为了获得执行各种操作的直觉,我们将在玩具数据集上构建神经网络。从下一章开始,我们将处理更现实的问题和数据集。
为了理解使用 PyTorch 实现神经网络,我们将解决的玩具问题是两个数字的简单相加,我们将数据集初始化如 :
1.定义输入 ( x) 和输出 ( y) 值:
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]请注意,在前面的输入和输出变量初始化中,输入和输出是一个列表列表,其中输入列表中的值之和就是输出列表中的值。
2.将输入列表转换为张量对象:
X = torch.tensor(x).float()
Y = torch.tensor(y).float()请注意,在前面的代码中,我们已将张量对象转换为浮点对象。将张量对象作为浮点数或长整数是一种很好的做法,因为它们无论如何都会乘以十进制值(权重)。
此外,我们将输入 ( X) 和输出 ( Y) 数据点注册到设备 -cuda如果您有 GPU 并且cpu如果您没有 GPU:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
X = X.to(device)
Y = Y.to(device)3.定义神经网络架构:
- 该 torch.nn模块包含有助于构建神经网络模型的函数:
import torch.nn as nn- 我们将创建一个MyNeuralNet可以构成我们的神经网络架构的类 ( )。创建模型架构时必须继承自nn.Module,因为它是所有神经网络模块的基类:
class MyNeuralNet(nn.Module):- 在类中,我们使用该__init__方法初始化神经网络的所有组件。我们应该调用super().__init__()以确保该类继承nn.Module:
def __init__(self):
super().__init__()使用前面的代码,通过指定super().__init__(),我们现在可以利用为 编写的所有预构建功能nn.Module。将在方法中初始化的组件将init在类中的不同方法中使用MyNeuralNet。
- 定义神经网络中的层:
self.input_to_hidden_layer = nn.Linear(2,8)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(8,1)在前面的代码行中,我们指定了神经网络的所有层——一个线性层 ( self.input_to_hidden_layer),然后是 ReLU 激活 ( self.hidden_layer_activation),最后是一个线性层 ( self.hidden_to_output_layer)。请注意,目前,层数和激活的选择是任意的。我们将在下一章更详细地了解层中单元数量和层激活的影响。
- 此外,让我们通过打印方法的输出来了解前面代码中的函数在做什么nn.Linear:
# 注意 - 这行代码不是模型构建的一部分,
# 这仅用于说明线性方法
print(nn.Linear( 2 , 7 ))
Linear(in_features=2, out_features=7, bias=True)在前面的代码中,线性方法以两个值作为输入并输出七个值,并且还具有与之关联的偏差参数。此外,nn.ReLU()调用 ReLU 激活,然后可以在其他方法中使用。
其他一些常用的激活函数如下:
- Sigmoid
- Softmax
- Tanh
现在我们已经定义了神经网络的组件,让我们将组件连接在一起,同时定义网络的前向传播:
def forward(self, x):
x = self.input_to_hidden_layer(x)
x = self.hidden_layer_activation(x)
x = self.hidden_to_output_layer(x)
return x必须使用forward函数名,因为 PyTorch 已将此函数保留为执行前向传播的方法。在其位置使用任何其他名称都会引发错误。
至此,我们已经搭建好了模型架构;让我们在下一步检查随机初始化的权重值。
4.您可以通过执行以下步骤访问每个组件的初始权重:
- 创建MyNeuralNet我们之前定义的类对象的实例并将其注册到device:
mynet = MyNeuralNet().to(device)- 可以通过指定以下内容来访问每一层的权重和偏差:
# 注意 - 这行代码不是模型构建的一部分,
# 这仅用于说明
# 如何获取给定层的参数
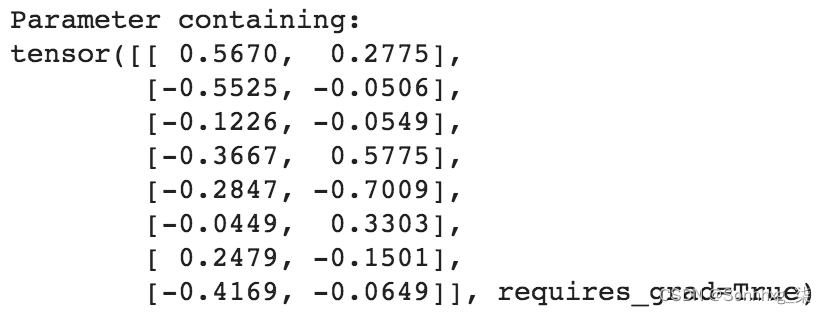
mynet.input_to_hidden_layer.weight上述代码的输出如下:
您的输出中的值将与前面的不同,因为神经网络每次都使用随机值进行初始化。如果您希望它们在执行相同代码的多次迭代中保持相同,则需要使用manual_seedTorch 中的方法指定种子,torch.manual_seed(0)就像在创建类对象的实例之前一样
- 一个神经网络的所有参数都可以通过以下代码获得:
# 注意 - 这行代码不是模型构建的一部分,
# 这仅用于说明
# 如何获取模型中所有层的参数
mynet.parameters()前面的代码返回一个生成器对象。
- 最后通过生成器循环获取参数,如下:
# 注意- 这行代码不是模型构建的一部分,
# 这仅用于说明如何
# 获取模型中所有层的参数
# 通过在mynet.parameters()中循环生成par的生成器对象
for par in mynet.parameters():
print(par)前面的代码产生以下输出:

该模型已将这些张量注册为跟踪前向和反向传播所必需的特殊对象。在方法中定义任何nn层时,它会自动创建相应的张量并同时注册它们。您也可以使用函数手动注册这些参数。因此,下面的代码等价于我们之前定义的神经网络类。 __init__ nn.Parameter(<tensor>)
- 使用该nn.Parameter函数定义模型的另一种方法如下:
# 仅用于说明
class MyNeuralNet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Parameter(\
torch.rand(2,8))
self.hidden_layer_activation = nn.ReLU ()
self.hidden_to_output_layer = nn.Parameter(\
torch.rand(8,1))
def forward(self, x):
x = x @ self.input_to_hidden_layer
x = self.hidden_layer_activation(x)
x = x @ self.hidden_to_output_layer
return x5.定义我们优化的损失函数。鉴于我们正在预测连续输出,我们将针对均方误差进行优化:
loss_func = nn.MSELoss()其他突出的损失函数如下:
- CrossEntropyLoss (用于多项分类)
- BCELoss (二元分类的二元交叉熵损失)
- 神经网络的损失值可以通过将输入值传递给neuralnet对象然后计算MSELoss给定的输入来计算:
_Y = mynet(X)
loss_value = loss_func(_Y,Y)
print (loss_value)
# tensor(91.5550, grad_fn=<MseLossBackward>)
# 注意损失值在你的实例中可能不同
# 由于不同的随机权重初始化在前面的代码中,mynet(X)计算输入通过神经网络时的输出值。此外,该loss_func函数计算与MSELoss神经网络的预测值 ( _Y) 和实际值 ( Y) 对应的值。
作为惯例,在本书中,我们将使用_<variable>对应于 ground truth 的预测来关联<variable>。上面<variable>是Y.
另请注意,在计算损失时,我们总是先发送预测,然后发送基本事实。这是一个 PyTorch 约定。
现在我们已经定义了损失函数,我们将定义尝试降低损失值的优化器。优化器的输入将是与神经网络相对应的参数(权重和偏差)以及更新权重时的学习率。
对于这个例子,我们将考虑随机梯度下降(在下一章中更多关于不同的优化器和学习率的影响)。
6.从模块中导入SGD方法torch.optim,然后将神经网络对象 ( mynet) 和学习率 ( lr) 作为参数传递给SGD方法:
from torch.optim import SGD
opt = SGD(mynet.parameters(), lr = 0.001 )7.一起执行一个 epoch 中要完成的所有步骤:
- 计算给定输入和输出对应的损失值。
- 计算每个参数对应的梯度。
- 根据每个参数的学习率和梯度更新权重。
- 更新权重后,确保在下一个 epoch 计算梯度之前刷新上一步中计算的梯度:
# 注意- 这行代码不是模型构建的一部分,
# 这仅用于说明我们如何执行
opt.zero_grad() # 刷新前一个 epoch 的梯度
loss_value = loss_func(mynet(X),Y) # 计算loss
loss_value.backward() # 执行反向传播
opt.step() # 根据计算的梯度更新权重- for使用循环重复上述步骤的次数与 epoch 的数量一样多。在以下示例中,我们将执行总共 50 个 epoch 的权重更新过程。此外,我们将损失值存储在列表中的每个时期 - loss_history:
loss_history = []
for _ in range(50):
opt.zero_grad()
loss_value = loss_func(mynet(X),Y)
loss_value.backward()
opt.step()
loss_history.append(loss_value)- 让我们画出随着 epoch 增加而损失的变化(正如我们在前一章中看到的,我们更新权重以使整体损失值随着 epoch 增加而减小):
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(loss_history)
plt.title('Loss variation over increasing epochs')
plt.xlabel('epochs')
plt.ylabel('loss value')前面的代码导致以下绘图:
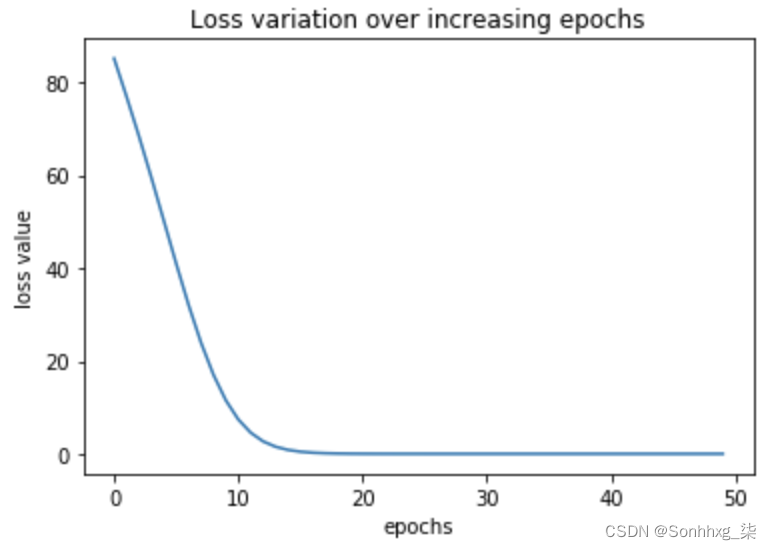
请注意,正如预期的那样,损失值随着时期的增加而减小。
到目前为止,在本节中,我们已经通过基于输入数据集中提供的所有数据点计算损失来更新神经网络的权重。在下一节中,我们将了解每次权重更新仅使用输入数据点样本的优势。
数据集、DataLoader 和批量大小
我们尚未考虑的神经网络中的一个超参数是批量大小。批量大小是指计算损失值或更新权重时考虑的数据点数。
这个超参数在有数百万个数据点的场景中特别有用,并且将所有数据点用于一个权重更新实例并不是最佳的,因为内存无法容纳这么多信息。此外,样本可以充分代表数据。批量大小有助于获取具有足够代表性但不一定 100% 代表总数据的多个数据样本。
在本节中,我们将提出一种方法来指定计算权重梯度时要考虑的批量大小,以更新权重,而权重又用于计算更新后的损失值:
1.导入有助于加载数据和处理数据集的方法:
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn2.导入数据,将数据转换为浮点数,并将它们注册到设备:
- 提供要处理的数据点:
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]- 将数据转换为浮点数:
X = torch.tensor(x).float()
Y = torch.tensor(y).float()- 将数据注册到设备——假设我们正在使用 GPU,我们指定设备是'cuda'. 如果您在 CPU 上工作,请将设备指定为'cpu':
device = 'cuda' if torch.cuda.is_available() else 'cpu'
X = X.to(device)
Y = Y.to(device)3.实例化数据集的一个类 - MyDataset:
class MyDataset(Dataset):在MyDataset类中,我们存储信息以一次获取一个数据点,以便可以将一批数据点捆绑在一起(使用DataLoader)并通过一次前向和一次反向传播发送以更新权重:
- 定义一个__init__接受输入和输出对并将它们转换为 Torch 浮点对象的方法:
def __init__(self,x,y):
self.x = torch.tensor(x).float()
self.y = torch.tensor(y).float()- 指定输入数据集的长度 ( __len__):
def __len__(self):
return len(self.x)- 最后,该__getitem__方法用于获取特定行:
def __getitem__(self, ix):
return self.x[ix], self.y[ix]在上述代码中,ix指的是要从数据集中获取的行的索引。
4.创建已定义类的实例:
ds = MyDataset(X, Y)5.传递之前定义的数据集实例,以从原始输入和输出张量对象DataLoader中获取batch_size数据点的数量:
dl = DataLoader(ds, batch_size=2, shuffle=True)此外,在前面的代码中,我们还指定从原始输入数据集shuffle=True(batch_size=2ds
- 要从中获取批次dl,我们遍历它:
# 注意- 这行代码不是模型构建的一部分,
# 这仅用于说明
# 如何在 dl 中打印批次数据
for x,y in dl:
print(x,y)这将产生以下输出:

请注意,前面的代码生成了两组输入-输出对,因为原始数据集中共有四个数据点,而指定的批量大小为2.
6.现在,我们定义上一节中定义的神经网络类:
class MyNeuralNet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(2,8)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(8,1)
def forward(self, x):
x = self.input_to_hidden_layer(x)
x = self.hidden_layer_activation(x)
x = self.hidden_to_output_layer(x)
return x7.接下来,我们还定义了模型对象 ( mynet)、损失函数 ( loss_func) 和优化器 ( opt),如上一节中所定义:
mynet = MyNeuralNet().to(device)
loss_func = nn.MSELoss()
from torch.optim import SGD
opt = SGD(mynet.parameters(), lr = 0.001)8.最后,循环遍历一批数据点以最小化损失值,就像我们在上一节的第 6 步中所做的那样:
import time
loss_history = []
start = time.time()
for _ in range(50):
for data in dl:
x, y = data
opt.zero_grad()
loss_value = loss_func(mynet(x),y)
loss_value.backward()
opt.step()
loss_history.append(loss_value)
end = time.time()
print(end - start)请注意,虽然前面的代码看起来与我们在上一节中的代码非常相似,但与上一节中更新权重的次数相比,我们执行的每个 epoch 的权重更新次数是 2 倍,因为本节中2的批大小是上一节中的批大小4(数据点的总数)。
现在我们已经训练了一个模型,在下一节中,我们将学习如何预测一组新的数据点。
预测新数据点
在上一节中,我们学习了如何在已知数据点上拟合模型。在本节中,我们将学习如何利用mynet上一节训练模型中定义的前向方法来预测看不见的数据点。我们将从上一节中构建的代码继续:
1.创建我们要测试模型的数据点:
val_x = [[10,11]]请注意,新数据集 ( val_x) 也将是列表列表,因为输入数据集是列表列表。
2.将新数据点转换为张量浮点对象并注册到设备:
val_x = torch.tensor(val_x).float().to(device)3.通过训练好的神经网络传递张量对象mynet——就好像它是一个 Python 函数一样。这与通过已构建的模型执行前向传播相同:
mynet(val_x)
# 20.99前面的代码返回与输入数据点关联的预测输出值。
到目前为止,我们已经能够训练我们的神经网络来映射输入和输出,我们通过执行反向传播来更新权重值以最小化损失值(使用预定义的损失函数计算)。
在下一节中,我们将学习如何构建我们自己的自定义损失函数,而不是使用预定义的损失函数。
实现自定义损失函数
在某些情况下,我们可能必须实现针对我们正在解决的问题定制的损失函数——尤其是在涉及对象检测/生成对抗网络( GAN ) 的复杂用例中。PyTorch 为我们提供了通过编写自己的函数来构建自定义损失函数的功能。
MSELoss在本节中,我们将实现一个自定义损失函数,该函数与预构建的函数执行相同的工作nn.Module:
1.导入数据,构建数据集和DataLoader,并定义神经网络,如上一节所述:
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]
import torch
X = torch.tensor(x).float()
Y = torch.tensor(y).float()
import torch.nn as nn
device = 'cuda' if torch.cuda.is_available() else 'cpu'
X = X.to(device)
Y = Y.to(device)
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self,x,y):
self.x = torch.tensor(x).float()
self.y = torch.tensor(y).float()
def __len__(self):
return len(self.x)
def __getitem__(self, ix):
return self.x[ix], self.y[ix]
ds = MyDataset(X, Y)
dl = DataLoader(ds, batch_size=2, shuffle=True)
class MyNeuralNet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(2,8)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(8,1)
def forward(self, x):
x = self.input_to_hidden_layer(x)
x = self.hidden_layer_activation(x)
x = self.hidden_to_output_layer(x)
return x
mynet = MyNeuralNet().to(device)2.通过将两个张量对象作为输入来定义自定义损失函数,取它们的差,并将它们平方并返回两者之间平方差的平均值:
def my_mean_squared_error(_y, y):
loss = (_y-y)**2
loss = loss.mean()
return loss3.对于我们在上一节nn.MSELoss中使用的相同输入和输出组合,用于获取均方误差损失,如下所示:
loss_func = nn.MSELoss()
loss_value = loss_func(mynet(X),Y)
print(loss_value)
# 92.75344.同样,当我们使用我们在步骤 2中定义的函数时,损失值的输出如下:
my_mean_squared_error(mynet(X),Y)
# 92.7534请注意,结果匹配。我们使用了内置MSELoss函数并将其结果与我们构建的自定义函数进行了比较。
我们可以定义我们选择的自定义函数,具体取决于我们正在解决的问题。
在到目前为止的部分中,我们已经了解了如何计算最后一层的输出。到目前为止,中间层的值一直是一个黑匣子。在下一节中,我们将学习获取神经网络的中间层值。
获取中间层的值
在某些情况下,获取神经网络的中间层值是有帮助的(当我们在后面的章节中讨论风格迁移和迁移学习用例时会详细介绍这一点)。
PyTorch提供了以两种方式获取神经网络中间值的功能:
- 一种方法是直接调用层,就好像它们是函数一样。这可以按如下方式完成:
input_to_hidden = mynet.input_to_hidden_layer(X)
hidden_activation = mynet.hidden_layer_activation(\
input_to_hidden)
print(hidden_activation)请注意,我们必须在调用input_to_hidden_layer之前调用激活,hidden_layer_activation因为输出input_to_hidden_layer是层的输入hidden_layer_activation。
- 另一种方法是在方法中指定我们要查看的层forward。
让我们看看本章中我们一直在研究的模型在激活后的隐藏层值。
虽然以下所有代码都与我们在上一节中看到的相同,但我们确保该forward方法不仅返回输出,还返回激活后的隐藏层值 ( hidden2):
class neuralnet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(2,8)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(8,1)
def forward(self, x):
hidden1 = self.input_to_hidden_layer(x)
hidden2 = self.hidden_layer_activation(hidden1)
output = self.hidden_to_output_layer(hidden2)
return output, hidden2我们现在可以通过指定以下内容来访问隐藏层值:
mynet = neuralnet().to(device)
mynet(X)[1]请注意,第 0个索引输出mynet是我们定义的——网络上前向传播的最终输出——而第一个索引输出是激活后的隐藏层值。
到目前为止,我们已经了解了如何使用我们手动构建每一层的神经网络类来实现神经网络。然而,除非我们正在构建一个复杂的网络,否则构建神经网络架构的步骤很简单,我们指定层和层堆叠的顺序。在下一节中,我们将学习一种更简单的定义神经网络架构的方法。
使用sequential方法构建神经网络
到目前为止,我们已经通过定义一个类来构建神经网络,我们在该类中定义了层以及层之间的连接方式。在本节中,我们将学习使用Sequential该类定义神经网络架构的简化方法。我们将执行与前面部分相同的步骤,除了用于手动定义神经网络架构的Sequential类将替换为用于创建神经网络架构的类。
让我们为我们在本章中处理的相同玩具数据编写网络代码:
1.定义玩具数据集:
x = [[1,2],[3,4],[5,6],[7,8]]
y = [[3],[7],[11],[15]]2.导入相关包并定义我们将使用的设备:
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import Dataset, DataLoader
device = 'cuda' if torch.cuda.is_available() else 'cpu' 3.现在,我们定义数据集类 ( MyDataset):
class MyDataset(Dataset):
def __init__(self, x, y):
self.x = torch.tensor(x).float().to(device)
self.y = torch.tensor(y).float().to(device)
def __getitem__(self, ix):
return self.x[ix], self.y[ix]
def __len__(self):
return len(self.x)4.定义 dataset ( ds) 和 dataloader ( dl) 对象:
ds = MyDataset(x, y)
dl = DataLoader(ds, batch_size= 2 , shuffle= True )5.Sequential使用包中可用的方法定义模型架构nn:
model = nn.Sequential(
nn.Linear(2, 8),
nn.ReLU(),
nn.Linear(8, 1)
).to(device)请注意,在前面的代码中,我们定义了与前面部分中定义的相同的网络架构,但定义不同。nn.Linear接受二维输入并为每个数据点提供八维输出。此外,nn.ReLU在八维输出之上执行 ReLU 激活,最后,八维输入使用最后nn.Linear一层给出一维输出(在我们的例子中是两个输入相加的输出)。
6.打印我们在步骤 5中定义的模型的摘要:
- 安装并导入使我们能够打印模型摘要的包:
!pip install torch_summary
from torchsummary import summary- 打印模型的摘要,其中需要模型的名称以及模型的输入大小:
summary(model, torch.zeros(1,2))前面的代码给出以下输出:

注意第一层的输出形状是(-1, 8),其中-1表示可以有与batch size一样多的数据点,8表示对于每个数据点,我们有一个八维的输出产生形状批量大小 x 8 的输出。接下来两层的解释是相似的。
7.接下来,我们定义损失函数 ( loss_func) 和优化器 ( opt) 并训练模型,就像我们在上一节中所做的那样。请注意,在这种情况下,我们不需要定义模型对象;在这种情况下,网络未在类中定义:
loss_func = nn.MSELoss()
from torch.optim import SGD
opt = SGD(model.parameters(), lr = 0.001)
import time
loss_history = []
start = time.time()
for _ in range(50):
for ix , iy in dl:
opt.zero_grad()
loss_value = loss_func(model(ix),iy)
loss_value.backward()
opt.step()
loss_history.append(loss_value)
end = time.time()
print(end - start)8.现在我们已经训练了模型,我们可以预测我们现在定义的验证数据集的值:
- 定义验证数据集:
val = [[8,9],[10,11],[1.5,2.5]]- 预测通过模型传递验证列表的输出(请注意,期望值是列表列表中每个列表的两个输入的总和)。正如数据集类中定义的那样,我们首先将列表列表转换为浮点数,然后将它们转换为张量对象并将它们注册到设备:
model(torch.tensor(val).float().to(device))
# tensor([[16.9051], [20.8352], [ 4.0773]],
# device='cuda:0', grad_fn=<AddmmBackward>)请注意,前面代码的输出(如注释中所示)接近预期(即输入值的总和)。
现在我们已经了解了如何利用顺序方法来定义和训练模型,在下一节中,我们将学习如何保存和加载模型以进行推理。
保存和加载 PyTorch 模型
处理神经网络模型的一个重要方面是在训练后保存和加载模型。考虑一个场景,您必须从已经训练好的模型中进行推断。您将加载经过训练的模型,而不是再次对其进行训练。
在通过相关命令执行此操作之前,以前面的示例为例,让我们了解完整定义神经网络的所有重要组件是什么。我们需要以下内容:
- 每个张量(参数)的唯一名称(键)
- 将网络中的每个张量与一个或另一个连接的逻辑
- 每个张量的值(权重/偏差值)
第一点是在__init__定义阶段处理的,而第二点是在forward方法定义期间处理的。默认情况下,张量中的值在__init__阶段期间随机初始化。但我们想要的是加载一组在训练模型时学习到的特定权重(或值),并将每个值与特定名称相关联。这是您通过调用特殊方法获得的结果,如以下部分所述。
状态命令
该model.state_dict()命令是了解保存和加载 PyTorch 模型的工作原理的基础。中的字典model.state_dict()对应于模型对应的参数名称(键)和值(权重和偏差值)。state指模型的当前快照(其中快照是每个张量处的一组值)。
OrderedDict它返回键和值的字典 ( ):

键是模型层的名称,值对应于这些层的权重。
保存(Saving)
运行torch.save(model.state_dict(), 'mymodel.pth')会将此模型以 Python 序列化格式保存在磁盘上,名称为mymodel.pth. 一个好的做法是在调用之前将模型传输到 CPU,torch.save因为这会将张量保存为 CPU 张量,而不是 CUDA 张量。这将有助于将模型加载到任何机器上,无论它是否包含 CUDA 功能。
我们使用以下代码保存模型:
torch.save(model.to('cpu').state_dict(), 'mymodel.pth')现在我们了解了保存模型,在下一节中,我们将学习加载模型。
加载(Loading)
加载模型需要我们先用随机权重初始化模型,然后从 加载权重state_dict:
1.使用最初在训练时使用的相同命令创建一个空模型:
model = nn.Sequential(
nn.Linear(2, 8),
nn.ReLU(),
nn.Linear(8, 1)
).to(device)2.从磁盘加载模型并对其进行反序列化以创建一个orderedDict值:
state_dict = torch.load('mymodel.pth')3.加载state_dict到model、注册到device并进行预测:
model.load_state_dict(state_dict)
# <All keys matched successfully>
model.to(device)
model(torch.tensor(val).float().to(device))如果模型中存在所有权重名称,那么您会收到一条消息,说明所有键都匹配。这意味着我们能够从磁盘加载我们的模型,用于所有目的,在世界上的任何机器上。
接下来,我们可以将模型注册到设备并对新数据点进行推理,正如我们在上一节中所学到的。
概括
在本章中,我们了解了 PyTorch 的构建块——张量对象并在它们之上执行各种操作。我们进一步在玩具数据集上构建了一个神经网络,我们首先构建了一个初始化前馈架构的类,通过指定批量大小从数据集中获取数据点,并定义损失函数和优化器,循环多个时代。最后,我们还了解了如何定义自定义损失函数来优化选择的度量,并利用顺序方法来简化定义网络架构的过程。
所有前面的步骤构成了构建神经网络的基础,我们将在后续章节中构建的各种用例中多次使用该神经网络。
了解了使用 PyTorch 构建神经网络的各个组成部分后,我们将继续下一章,在那里我们将了解在图像数据集上处理神经网络超参数的各个实际方面。
问题
- 为什么我们应该在训练期间将整数输入转换为浮点值?
- 重塑张量对象的各种方法是什么?
- 为什么张量对象在 NumPy 数组上的计算速度更快?
- 什么构成了神经网络类中的 init 魔术函数?
- 为什么我们在执行反向传播之前执行零梯度?
- 哪些魔术函数构成了数据集类?
- 我们如何对新数据点进行预测?
- 我们如何获取神经网络的中间层值?
- 顺序方法如何帮助简化定义神经网络的架构?

















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











