







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
有时,您可能需要总结一份文件,无论是研究文章、财务收益报告还是电子邮件。如果你仔细想想,这需要一系列的能力,例如理解长篇文章,推理内容,以及产生包含原始文档主要主题的流畅文本。此外,准确地总结一篇新闻文章与总结一份法律合同有很大的不同,因此能够做到这一点需要复杂程度的领域概括。由于这些原因,文本摘要对于包括转换器在内的神经语言模型来说是一项艰巨的任务。尽管存在这些挑战,文本摘要为领域专家提供了显着加快其工作流程的前景,并被企业用来浓缩内部知识, 等等。
为了帮助您理解所涉及的挑战,本章将探讨我们如何利用预训练的转换器来总结文档。摘要是一个经典的序列到序列 (seq2seq) 任务,具有输入文本和目标文本。正如我们在 第 1 章中看到的,这就是编码器-解码器转换器擅长的地方。
在本章中,我们将构建自己的编码器-解码器模型,将几个人之间的对话浓缩成一个清晰的摘要。但在我们开始之前,让我们先看一下用于摘要的规范数据集之一:CNN/DailyMail 语料库。
CNN/每日邮报数据集
CNN/DailyMail 数据集包含大约 300,000 对新闻文章及其相应的摘要,由 CNN 和 DailyMail 附加到其文章的要点组成。数据集的一个重要方面是 摘要是抽象的而不是 提取的,这意味着它们由新句子而不是简单的摘录组成。数据集在Hub上可用 ;我们将使用 3.0.0 版本,这是一个为摘要而设置的非匿名版本。我们可以使用与第 4 章中看到的拆分类似的方式选择版本,使用version关键字。因此,让我们深入研究一下:
from datasets import load_dataset
dataset = load_dataset("cnn_dailymail", version="3.0.0")
print(f"Features: {dataset['train'].column_names}")Features: ['article', 'highlights', 'id']
数据集有三列:article,其中包含新闻文章,highlights带有摘要,并id唯一标识每篇文章。我们来看一篇文章的摘录:
sample = dataset["train"][1]
print(f"""
Article (excerpt of 500 characters, total length: {len(sample["article"])}):
""")
print(sample["article"][:500])
print(f'\nSummary (length: {len(sample["highlights"])}):')
print(sample["highlights"])
Article (excerpt of 500 characters, total length: 3192):
(CNN) -- Usain Bolt rounded off the world championships Sunday by claiming his
third gold in Moscow as he anchored Jamaica to victory in the men's 4x100m
relay. The fastest man in the world charged clear of United States rival Justin
Gatlin as the Jamaican quartet of Nesta Carter, Kemar Bailey-Cole, Nickel
Ashmeade and Bolt won in 37.36 seconds. The U.S finished second in 37.56 seconds
with Canada taking the bronze after Britain were disqualified for a faulty
handover. The 26-year-old Bolt has n
Summary (length: 180):
Usain Bolt wins third gold of world championship .
Anchors Jamaica to 4x100m relay victory .
Eighth gold at the championships for Bolt .
Jamaica double up in women's 4x100m relay .我们看到与目标摘要相比,文章可能会很长;在这种特殊情况下,差异是 17 倍。长文章对大多数 Transformer 模型构成挑战,因为上下文大小通常限制在 1,000 个左右,相当于几段文本。处理此问题以进行摘要的标准但粗略的方法是简单地截断超出模型上下文大小的文本。显然,文本末尾的摘要可能有重要信息,但现在我们需要忍受模型架构的这种限制。
文本摘要管道
让我们首先定性地查看前面示例的输出,看看一些最流行的用于汇总的 Transformer 模型是如何执行的。尽管我们将探索的模型架构具有不同的最大输入大小,但让我们将输入文本限制为 2,000 个字符,以使所有模型具有相同的输入,从而使输出更具可比性:
sample_text = dataset["train"][1]["article"][:2000]
# We'll collect the generated summaries of each model in a dictionary
summaries = {}摘要中的惯例是用换行符分隔摘要句子。我们可以在每个句号之后添加一个换行符,但是这种简单的启发式方法对于像“US”或“UN”这样的字符串会失败 自然语言工具包(NLTK)包包括一个更复杂的算法,可以区分句子的结尾和标点符号出现在缩写中:
import nltk
from nltk.tokenize import sent_tokenize
nltk.download("punkt")string = "The U.S. are a country. The U.N. is an organization."
sent_tokenize(string)['The U.S. are a country.', 'The U.N. is an organization.']
警告
在接下来的部分中,我们将加载几个大型模型。如果内存不足,您可以用较小的检查点(例如“gpt”、“t5-small”)替换大型模型,或者跳过本节并跳转到“在 CNN/DailyMail 数据集上评估 PEGASUS”。
总结基线
总结新闻文章的一个常见基线是简单地取文章的前三句话。使用 NLTK 的句子分词器,我们可以轻松实现这样的基线:
def three_sentence_summary(text):
return "\n".join(sent_tokenize(text)[:3])summaries["baseline"] = three_sentence_summary(sample_text)GPT-2
我们已经在第 5 章看到GPT-2 如何在给定提示的情况下生成文本。该模型令人惊讶的特性之一是,我们还可以通过在输入文本末尾简单地附加“TL;DR”来使用它来生成摘要。表达“TL;DR”(太长;没读过)经常在 Reddit 等平台上使用,表示长帖子的简短版本。我们将通过使用![]() Transformers中的
Transformers中的pipeline()函数 重新创建原始论文的过程来开始我们的总结实验。1我们创建一个文本生成管道并加载大型 GPT-2 模型:
from transformers import pipeline, set_seed
set_seed(42)
pipe = pipeline("text-generation", model="gpt2-xl")
gpt2_query = sample_text + "\nTL;DR:\n"
pipe_out = pipe(gpt2_query, max_length=512, clean_up_tokenization_spaces=True)
summaries["gpt2"] = "\n".join(
sent_tokenize(pipe_out[0]["generated_text"][len(gpt2_query) :]))在这里,我们只是通过切分输入查询来存储生成文本的摘要,并将结果保存在 Python 字典中以供以后比较。
T5
接下来让我们试试T5变压器。正如我们在 第 3 章中看到的,该模型的开发人员对 NLP 中的迁移学习进行了全面研究,并发现他们可以通过将所有任务制定为文本到文本的任务来创建通用的转换器架构。T5 检查点在无监督数据(用于重建掩码单词)和监督数据的混合上进行训练,以完成包括摘要在内的多项任务。因此,这些检查点可以直接用于执行汇总,而无需使用预训练期间使用的相同提示进行微调。在这个框架中,模型总结文档的输入格式是"summarize: <ARTICLE>",对于翻译它看起来像 "translate English to German: <TEXT>"。如图6-1,这使得 T5 非常通用,并允许您使用单个模型解决许多任务。
我们可以使用该函数直接加载 T5 进行汇总,该pipeline() 函数还负责将输入格式化为文本到文本格式,因此我们不需要在它们前面加上 "summarize":
pipe = pipeline("summarization", model="t5-large")
pipe_out = pipe(sample_text)
summaries["t5"] = "\n".join(sent_tokenize(pipe_out[0]["summary_text"]))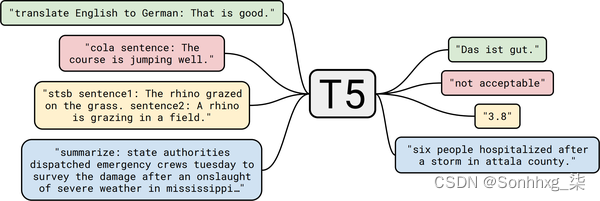
图 6-1。T5 的文本到文本框架图(Colin Raffel 提供);除了翻译和摘要,还展示了 CoLA(语言可接受性)和 STSB(语义相似性)任务
BART
BART 还使用编码器-解码器架构,并经过训练以重建损坏的输入。它结合了 BERT 和 GPT-2 的预训练方案。2我们将使用facebook/bart-large-ccn检查点,该检查点已在 CNN/DailyMail 数据集上进行了专门微调:
pipe = pipeline("summarization", model="facebook/bart-large-cnn")
pipe_out = pipe(sample_text)
summaries["bart"] = "\n".join(sent_tokenize(pipe_out[0]["summary_text"]))PEGASUS
与 BART 一样,PEGASUS 是一个编码器-解码器转换器。3如图 6-2所示 ,它的预训练目标是预测多句文本中的掩码句子。作者认为,预训练目标越接近下游任务,就越有效。为了找到比一般语言建模更接近摘要的预训练目标,他们在非常大的语料库中自动识别包含周围段落大部分内容的句子(使用摘要评估指标作为内容 重叠的启发式)并对 PEGASUS 模型进行预训练以重构这些句子,从而获得最先进的文本摘要模型。
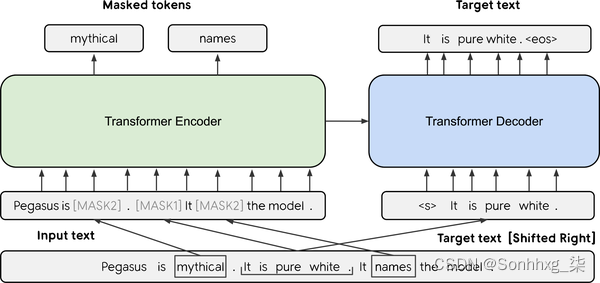
图 6-2。PEGASUS 架构图(由 Jingqing Zhang 等提供)
这个模型有一个特殊的换行符,这就是我们不需要这个sent_tokenize()函数的原因:
pipe = pipeline("summarization", model="google/pegasus-cnn_dailymail")
pipe_out = pipe(sample_text)
summaries["pegasus"] = pipe_out[0]["summary_text"].replace(" .<n>", ".\n")比较不同的摘要
现在我们已经用四种不同的模型生成了摘要,让我们比较一下结果。请记住,一个模型根本没有在数据集上进行过训练(GPT-2),一个模型已经在这个任务上进行了微调(T5),还有两个模型专门在这个任务上进行了微调(巴特和飞马)。让我们看一下这些模型生成的摘要:
print("GROUND TRUTH")
print(dataset["train"][1]["highlights"])
print("")
for model_name in summaries:
print(model_name.upper())
print(summaries[model_name])
print("")GROUND TRUTH Usain Bolt wins third gold of world championship . Anchors Jamaica to 4x100m relay victory . Eighth gold at the championships for Bolt . Jamaica double up in women's 4x100m relay . BASELINE (CNN) -- Usain Bolt rounded off the world championships Sunday by claiming his third gold in Moscow as he anchored Jamaica to victory in the men's 4x100m relay. The fastest man in the world charged clear of United States rival Justin Gatlin as the Jamaican quartet of Nesta Carter, Kemar Bailey-Cole, Nickel Ashmeade and Bolt won in 37.36 seconds. The U.S finished second in 37.56 seconds with Canada taking the bronze after Britain were disqualified for a faulty handover. GPT2 Nesta, the fastest man in the world. Gatlin, the most successful Olympian ever. Kemar, a Jamaican legend. Shelly-Ann, the fastest woman ever. Bolt, the world's greatest athlete. The team sport of pole vaulting T5 usain bolt wins his third gold medal of the world championships in the men's 4x100m relay . the 26-year-old anchored Jamaica to victory in the event in the Russian capital . he has now collected eight gold medals at the championships, equaling the record . BART Usain Bolt wins his third gold of the world championships in Moscow. Bolt anchors Jamaica to victory in the men's 4x100m relay. The 26-year-old has now won eight gold medals at world championships. Jamaica's women also win gold in the relay, beating France in the process. PEGASUS Usain Bolt wins third gold of world championships. Anchors Jamaica to victory in men's 4x100m relay. Eighth gold at the championships for Bolt. Jamaica also win women's 4x100m relay .
通过查看模型输出,我们首先注意到的是 GPT-2 生成的摘要与其他摘要完全不同。它不是对文本进行总结,而是对字符进行总结。GPT-2 模型通常会“产生幻觉”或创造事实,因为它没有经过明确的训练来生成真实的摘要。例如,在撰写本文时,内斯塔并不是世界上跑得最快的人,而是排在第九位。将其他三个模型摘要与基本事实进行比较,我们看到存在显着的重叠,其中 PEGASUS 的输出具有最惊人的 相似性。
现在我们已经检查了几个模型,让我们尝试决定我们将在生产环境中使用哪一个。所有四个模型似乎都提供了定性合理的结果,我们可以生成更多示例来帮助我们做出决定。但是,这不是确定最佳模型的系统方法!理想情况下,我们会定义一个指标,在某个基准数据集上为所有模型测量它,然后选择性能最好的一个。但是您如何定义文本生成的指标?我们看到的标准指标,如准确率、召回率和精度,并不容易应用于这项任务。对于人类编写的每个“黄金标准”摘要,其他数十个带有同义词、释义或稍微不同的事实表述方式的摘要也同样可以接受。
在下一节中,我们将介绍一些用于衡量生成文本质量的常用指标。
测量生成文本的质量
良好的评估指标很重要,因为我们不仅在训练模型时使用它们来衡量模型的性能,而且在以后的生产中也使用它们。如果我们有糟糕的指标,我们可能对模型退化视而不见,如果它们与业务目标不一致,我们可能不会创造任何价值。
衡量文本生成任务的性能并不像情感分析或命名实体识别等标准分类任务那么容易。以翻译为例;给了一个像“我爱狗!”这样的句子 用英语翻译成西班牙语可能有多种有效的可能性,比如“¡Me encantan los perros!” 或“¡Me gustan los perros!” 简单地检查与参考翻译的完全匹配并不是最佳的;即使是人类也会在这样的指标上表现不佳,因为我们写的文本彼此之间略有不同(甚至与我们自己不同,取决于一天或一年中的时间!)。幸运的是,还有其他选择。
用于评估生成文本的两个最常见的指标是 BLEU 和 ROUGE。让我们看看它们是如何定义的。
BLEU
BLEU 的想法很简单:4我们不看生成的文本中有多少标记与参考文本标记完全对齐,而是看单词或n- gram。BLEU 是一种基于精度的度量,这意味着当我们比较两个文本时,我们会计算参考中出现的一代中的单词数量,并将其除以一代的长度。
但是,这种普通的精度存在问题。假设生成的文本只是一遍又一遍地重复同一个词,并且这个词也出现在参考文献中。如果它重复的次数与参考文本的长度一样多,那么我们将获得完美的精度!出于这个原因,BLEU 论文的作者做了一个小小的修改:一个词只计算它在参考文献中出现的次数。为了说明这一点,假设我们有参考文本“the cat is on the mat”和生成的文本“the the the the the the”。
从这个简单的例子中,我们可以计算出精度值如下:
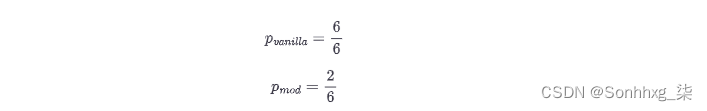
我们可以看到,简单的修正产生了一个更合理的值。现在让我们不仅查看单个单词,还查看n- gram 来扩展它。假设我们有一个生成的句子,sn吨,我们想与参考句子进行比较,sn吨'. 我们提取所有可能的n级n克 并进行计算以获得精度pn:
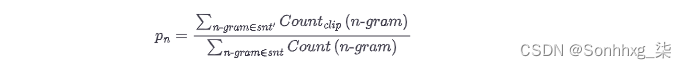
为了避免奖励重复生成,分子中的计数被裁剪。这意味着一个 n- gram 的出现次数被限制在它在参考句中出现的次数。另请注意,在此等式中,句子的定义不是很严格,如果您生成的文本跨越多个句子,您会将其视为一个句子。
一般来说,我们要评估的测试集中有多个样本,因此我们需要通过对语料库C中的所有样本求和来稍微扩展方程:
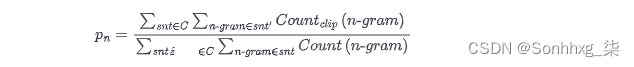
我们快到了。由于我们不考虑召回,因此与较长的句子相比,所有生成的短而精确的序列都有好处。因此,精度分数有利于短代。为了弥补 BLEU 的作者引入了一个额外的术语,简洁惩罚:
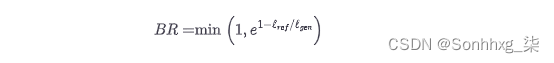
通过取最小值,我们确保这个惩罚永远不会超过 1,并且当生成的文本长度增加时,指数项变得指数级小lG和n小于参考文本 lr和F. 此时您可能会问,为什么我们不使用类似F 1的分数来计算召回率?答案是,在翻译数据集中通常有多个参考句子,而不仅仅是一个,所以如果我们也测量召回率,我们将激励使用所有参考文献中所有单词的翻译。因此,最好在翻译中寻找高精度,并确保翻译和参考具有相似的长度。
最后,我们可以将所有内容放在一起,得到 BLEU 分数的公式:
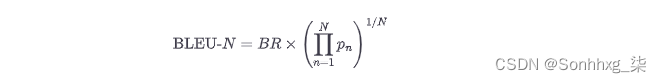
最后一项是修改精度的几何平均值,直到 n -gram N。在实践中,经常会报告 BLEU-4 分数。但是,您可能已经看到这个指标有很多限制;例如,它没有考虑同义词,并且推导中的许多步骤似乎是临时的且相当脆弱的启发式方法。您可以在 Rachel Tatman 的博客文章“评估 NLP 中的文本输出:BLEU 风险自负”中找到对 BLEU 缺陷的精彩阐述。
总的来说,文本生成领域仍在寻找更好的评估指标,寻找克服 BLEU 等指标限制的方法是一个活跃的研究领域。BLEU 度量的另一个弱点是它期望文本已经被标记化。如果不使用完全相同的文本标记化方法,这可能会导致不同的结果。SacreBLEU 指标通过内部化标记化步骤解决了这个问题;因此,它是基准测试的首选指标。
我们现在已经完成了一些理论,但我们真正想做的是计算一些生成文本的分数。这是否意味着我们需要在 Python 中实现所有这些逻辑?不要害怕, 数据集也提供指标!加载度量就像加载数据集一样:
from datasets import load_metric
bleu_metric = load_metric("sacrebleu")该bleu_metric对象是Metric该类的一个实例,并且像聚合器一样工作:您可以通过添加单个实例add()或整个批次add_batch()。添加完所有需要评估的样本后,您就可以调用compute() 并计算指标。这将返回一个包含多个值的字典,例如每个n- gram 的精度、长度惩罚以及最终的 BLEU 分数。让我们看一下之前的例子:
import pandas as pd
import numpy as np
bleu_metric.add(
prediction="the the the the the the", reference=["the cat is on the mat"])
results = bleu_metric.compute(smooth_method="floor", smooth_value=0)
results["precisions"] = [np.round(p, 2) for p in results["precisions"]]
pd.DataFrame.from_dict(results, orient="index", columns=["Value"])| Value | |
|---|---|
| score | 0.0 |
| count | [2, 0, 0, 0] |
| totals | [6, 5, 4, 3] |
| precisions | [33.33, 0.0, 0.0, 0.0] |
| bp | 1.0 |
| sys_len | 6 |
| ref_len | 6 |
笔记
如果有多个参考翻译,BLEU 分数也适用。这就是为什么
reference作为列表传递的原因。为了使n- gram 中零计数的度量更平滑,BLEU 集成了修改精度计算的方法。一种方法是在分子中添加一个常数。这样,丢失的n- gram 不会导致分数自动变为零。为了解释这些值,我们通过设置将其关闭smooth_value=0。
我们可以看到 1-gram 的精度确实是 2/6,而 2/3/4-gram 的精度都是 0。(有关单个指标的更多信息,如计数和 bp,请参阅SacreBLEU 存储库.) 这意味着几何平均值为零,因此 BLEU 分数也为零。让我们看另一个预测几乎正确的例子:
bleu_metric.add(
prediction="the cat is on mat", reference=["the cat is on the mat"])
results = bleu_metric.compute(smooth_method="floor", smooth_value=0)
results["precisions"] = [np.round(p, 2) for p in results["precisions"]]
pd.DataFrame.from_dict(results, orient="index", columns=["Value"])| Value | |
|---|---|
| score | 57.893007 |
| counts | [5, 3, 2, 1] |
| totals | [5, 4, 3, 2] |
| precisions | [100.0, 75.0, 66.67, 50.0] |
| bp | 0.818731 |
| sys_len | 5 |
| ref_len | 6 |
我们观察到精度分数要好得多。预测中的 1-gram 都匹配,只有在精度分数中我们才能看到有什么不对劲。对于 4-gram,只有两个候选者, ["the", "cat", "is", "on"]和["cat", "is", "on", "mat"],最后一个不匹配,因此精度为 0.5。
BLEU 分数被广泛用于评估文本,尤其是在机器翻译中,因为精确翻译通常比包含所有可能和适当单词的翻译更受青睐。
还有其他应用程序,例如摘要,情况有所不同。在那里,我们想要生成文本中的所有重要信息,因此我们倾向于高召回率。这是通常使用 ROUGE 分数的地方。
ROUGE
ROUGE 分数是专门为摘要等应用开发的,在这些应用中,高召回率比精确度更重要。5该方法与 BLEU 分数非常相似,因为我们查看不同的 n- gram 并比较它们在生成的文本和参考文本中的出现。不同之处在于,使用 ROUGE,我们检查参考文本中有多少n -gram 也出现在生成的文本中。对于 BLEU,我们查看了生成文本中有多少n- gram 出现在参考文献中,因此我们可以重用精度公式,只需稍作修改,即在分母中计算生成文本中 参考n- gram的(未剪辑)出现次数:
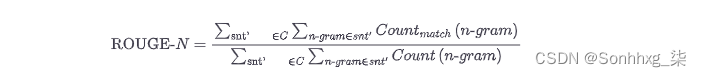
这是 ROUGE 最初的提议。随后,研究人员发现,完全去除精度会产生强烈的负面影响。回到没有裁剪计数的 BLEU 公式,我们也可以测量精度,然后我们可以结合调和平均值中的精度和召回 ROUGE 分数来获得 F 1分数。这个分数是现在通常为 ROUGE 报告的指标。
ROUGE中有一个单独的分数来衡量最长公共子串(LCS),称为ROUGE-L。可以为任何一对字符串计算 LCS。例如,“abab”和“abc”的 LCS 为“ab”,其长度为 2。如果我们想在两个样本之间比较这个值,我们需要以某种方式对其进行归一化,否则会产生更长的文本有优势。为了实现这一点,ROUGE 的发明者想出了一个F-score-like 方案,其中 LCS 使用参考和生成文本的长度进行归一化,然后将两个归一化的分数混合在一起: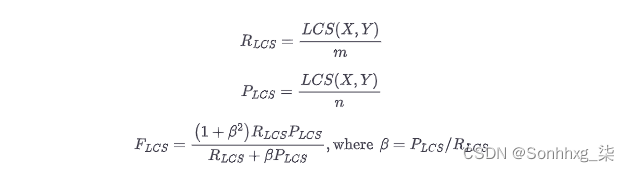
这样,LCS 分数就可以正确归一化,并且可以跨样本进行比较。在Datasets 实现中,计算了 ROUGE 的两种变体:一种计算每个句子的分数并将其平均用于摘要(ROUGE-L),另一种直接计算整个摘要(ROUGE-Lsum)。
我们可以按如下方式加载指标:
rouge_metric = load_metric("rouge")我们已经使用 GPT-2 和其他模型生成了一组摘要,现在我们有了一个指标来系统地比较这些摘要。让我们将 ROUGE 分数应用于模型生成的所有摘要:
reference = dataset["train"][1]["highlights"]
records = []
rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
for model_name in summaries:
rouge_metric.add(prediction=summaries[model_name], reference=reference)
score = rouge_metric.compute()
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
records.append(rouge_dict)
pd.DataFrame.from_records(records, index=summaries.keys())| rouge1 | rouge2 | rougeL | rougeLsum | |
|---|---|---|---|---|
| baseline | 0.303571 | 0.090909 | 0.214286 | 0.232143 |
| gpt2 | 0.187500 | 0.000000 | 0.125000 | 0.187500 |
| t5 | 0.486486 | 0.222222 | 0.378378 | 0.486486 |
| bart | 0.582278 | 0.207792 | 0.455696 | 0.506329 |
| pegasus | 0.866667 | 0.655172 | 0.800000 | 0.833333 |
笔记
数据集库中的 ROUGE 指标还计算置信区间(默认情况下,第 5 和第 95 个百分位数)。平均值存储在属性中
mid,可以使用low和检索区间high。
这些结果显然不是很可靠,因为我们只查看了一个样本,但我们可以比较该示例的摘要质量。该表证实了我们的观察,即在我们考虑的模型中,GPT-2 表现最差。这并不奇怪,因为它是该组中唯一没有经过明确训练总结的模型。然而,令人惊讶的是,与具有大约十亿个参数的变压器模型相比,简单的前三句基线并没有太差!PEGASUS 和 BART 是总体上最好的模型(ROUGE 分数越高越好),但 T5 在 ROUGE-1 和 LCS 分数上略胜一筹。这些结果将 T5 和 PEGASUS 列为最佳模型,但同样应谨慎对待这些结果,因为我们仅在单个示例上评估了模型。
在 CNN/DailyMail 数据集上评估 PEGASUS
我们现在已经准备好正确评估模型的所有部分:我们有一个包含来自 CNN/DailyMail 的测试集的数据集,我们有一个包含 ROUGE 的度量,我们有一个汇总模型。我们只需要把这些碎片拼凑起来。我们先来评估一下三句baseline的表现:
def evaluate_summaries_baseline(dataset, metric,
column_text="article",
column_summary="highlights"):
summaries = [three_sentence_summary(text) for text in dataset[column_text]]
metric.add_batch(predictions=summaries,
references=dataset[column_summary])
score = metric.compute()
return score现在我们将该函数应用于数据的子集。由于 CNN/DailyMail 数据集的测试部分包含大约 10,000 个样本,因此为所有这些文章生成摘要需要大量时间。回想第 5 章,每个生成的令牌都需要通过模型进行前向传递;因此,为每个样本只生成 100 个标记将需要 100 万次前向传递,如果我们使用光束搜索,这个数字将乘以光束的数量。为了保持计算相对较快,我们将对测试集进行二次抽样,然后对 1,000 个样本进行评估。这应该给我们一个更稳定的分数估计,同时在一个 GPU 上为 PEGASUS 模型在不到一小时的时间内完成:
test_sampled = dataset["test"].shuffle(seed=42).select(range(1000))
score = evaluate_summaries_baseline(test_sampled, rouge_metric)
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame.from_dict(rouge_dict, orient="index", columns=["baseline"]).T| rouge1 | rouge2 | rougeL | rougeLsum | |
|---|---|---|---|---|
| baseline | 0.396061 | 0.173995 | 0.245815 | 0.361158 |
分数大多比前面的例子差,但仍然比 GPT-2 的分数要好!现在让我们实现相同的评估函数来评估 PEGASUS 模型:
from tqdm import tqdm
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
def chunks(list_of_elements, batch_size):
"""Yield successive batch-sized chunks from list_of_elements."""
for i in range(0, len(list_of_elements), batch_size):
yield list_of_elements[i : i + batch_size]
def evaluate_summaries_pegasus(dataset, metric, model, tokenizer,
batch_size=16, device=device,
column_text="article",
column_summary="highlights"):
article_batches = list(chunks(dataset[column_text], batch_size))
target_batches = list(chunks(dataset[column_summary], batch_size))
for article_batch, target_batch in tqdm(
zip(article_batches, target_batches), total=len(article_batches)):
inputs = tokenizer(article_batch, max_length=1024, truncation=True,
padding="max_length", return_tensors="pt")
summaries = model.generate(input_ids=inputs["input_ids"].to(device),
attention_mask=inputs["attention_mask"].to(device),
length_penalty=0.8, num_beams=8, max_length=128)
decoded_summaries = [tokenizer.decode(s, skip_special_tokens=True,
clean_up_tokenization_spaces=True)
for s in summaries]
decoded_summaries = [d.replace("<n>", " ") for d in decoded_summaries]
metric.add_batch(predictions=decoded_summaries, references=target_batch)
score = metric.compute()
return score让我们稍微解开这个评估代码。首先,我们将数据集分成更小的批次,我们可以同时处理这些批次。然后对于每个批次,我们对输入文章进行标记并将它们提供给 generate()函数以使用波束搜索生成摘要。我们使用与论文中提出的相同的生成参数。长度惩罚的新参数确保模型不会生成太长的序列。最后,我们对生成的文本进行解码,替换<n>标记,并将解码的文本与对度量的引用一起添加。最后,我们计算并返回 ROUGE 分数。现在让我们再次使用 AutoModelForSeq2SeqLM类加载模型,用于 seq2seq 生成任务,并评估它:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_ckpt = "google/pegasus-cnn_dailymail"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModelForSeq2SeqLM.from_pretrained(model_ckpt).to(device)
score = evaluate_summaries_pegasus(test_sampled, rouge_metric,
model, tokenizer, batch_size=8)
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame(rouge_dict, index=["pegasus"])| rouge1 | rouge2 | rougeL | rougeLsum | |
|---|---|---|---|---|
| pegasus | 0.434381 | 0.210883 | 0.307195 | 0.373231 |
这些数字与公布的结果非常接近。这里要注意的一件事是,损失和每个令牌的准确性在某种程度上与 ROUGE 分数脱钩。损失与解码策略无关,而 ROUGE 分数是强耦合的。
由于 ROUGE 和 BLEU 与人类判断的相关性要好于损失或准确性,因此我们应该关注它们,在构建文本生成模型时仔细探索和选择解码策略。然而,这些指标远非完美,人们也应该始终考虑人类的判断。
现在我们已经配备了评估功能,是时候训练我们自己的总结模型了。
训练总结模型
我们已经完成了很多关于文本摘要和评估的细节,所以让我们用它来训练自定义文本摘要模型!对于我们的应用程序,我们将使用三星开发的 SAMSum 数据集,该数据集由一组对话和简短摘要组成。在企业环境中,这些对话可能代表客户与支持中心之间的交互,因此生成准确的摘要有助于改善客户服务并检测客户请求中的常见模式。让我们加载它并看一个 例子:
dataset_samsum = load_dataset("samsum")
split_lengths = [len(dataset_samsum[split])for split in dataset_samsum]
print(f"Split lengths: {split_lengths}")
print(f"Features: {dataset_samsum['train'].column_names}")
print("\nDialogue:")
print(dataset_samsum["test"][0]["dialogue"])
print("\nSummary:")
print(dataset_samsum["test"][0]["summary"])Split lengths: [14732, 819, 818] Features: ['id', 'dialogue', 'summary'] Dialogue: Hannah: Hey, do you have Betty's number? Amanda: Lemme check Hannah: <file_gif> Amanda: Sorry, can't find it. Amanda: Ask Larry Amanda: He called her last time we were at the park together Hannah: I don't know him well Hannah: <file_gif> Amanda: Don't be shy, he's very nice Hannah: If you say so.. Hannah: I'd rather you texted him Amanda: Just text him Hannah: Urgh.. Alright Hannah: Bye Amanda: Bye bye Summary: Hannah needs Betty's number but Amanda doesn't have it. She needs to contact Larry.
这些对话看起来就像您通过 SMS 或 WhatsApp 进行的聊天所期望的一样,包括表情符号和 GIF 的占位符。该dialogue 字段包含全文和summary摘要对话。在 CNN/DailyMail 数据集上进行微调的模型可以解决这个问题吗?让我们来了解一下!
在 SAMSum 上评估 PEGASUS
首先,我们将使用 PEGASUS 运行相同的汇总管道,以查看输出的样子。我们可以重用我们用于 CNN/DailyMail 摘要生成的代码:
pipe_out = pipe(dataset_samsum["test"][0]["dialogue"])
print("Summary:")
print(pipe_out[0]["summary_text"].replace(" .<n>", ".\n"))Summary: Amanda: Ask Larry Amanda: He called her last time we were at the park together. Hannah: I'd rather you texted him. Amanda: Just text him .
我们可以看到,该模型主要通过从对话中提取关键句子来尝试进行总结。这可能在 CNN/DailyMail 数据集上效果较好,但 SAMSum 中的摘要更抽象。让我们通过在测试集上运行完整的 ROUGE 评估来确认这一点:
score = evaluate_summaries_pegasus(dataset_samsum["test"], rouge_metric, model,
tokenizer, column_text="dialogue",
column_summary="summary", batch_size=8)
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame(rouge_dict, index=["pegasus"])| rouge1 | rouge2 | rougeL | rougeLsum | |
|---|---|---|---|---|
| pegasus | 0.296168 | 0.087803 | 0.229604 | 0.229514 |
嗯,结果不是很好,但这并不意外,因为我们已经远离了 CNN/DailyMail 数据分布。尽管如此,在训练之前建立评估管道有两个优点:我们可以直接用度量来衡量训练的成功,并且我们有一个很好的基线。在我们的数据集上微调模型应该会立即改善 ROUGE 指标,如果不是这样,我们就会知道我们的训练循环有问题。
微调pegasus
在我们处理数据进行训练之前,让我们快速看一下输入和输出的长度分布:
d_len = [len(tokenizer.encode(s)) for s in dataset_samsum["train"]["dialogue"]]
s_len = [len(tokenizer.encode(s)) for s in dataset_samsum["train"]["summary"]]
fig, axes = plt.subplots(1, 2, figsize=(10, 3.5), sharey=True)
axes[0].hist(d_len, bins=20, color="C0", edgecolor="C0")
axes[0].set_title("Dialogue Token Length")
axes[0].set_xlabel("Length")
axes[0].set_ylabel("Count")
axes[1].hist(s_len, bins=20, color="C0", edgecolor="C0")
axes[1].set_title("Summary Token Length")
axes[1].set_xlabel("Length")
plt.tight_layout()
plt.show()
我们看到大多数对话比 CNN/DailyMail 文章短得多,每个对话有 100-200 个标记。同样,摘要要短得多,大约有 20-40 个标记(一条推文的平均长度)。
让我们在为Trainer. 首先,我们需要对数据集进行标记。现在,我们将对话和摘要的最大长度分别设置为 1024 和 128:
def convert_examples_to_features(example_batch):
input_encodings = tokenizer(example_batch["dialogue"], max_length=1024,
truncation=True)
with tokenizer.as_target_tokenizer():
target_encodings = tokenizer(example_batch["summary"], max_length=128,
truncation=True)
return {"input_ids": input_encodings["input_ids"],
"attention_mask": input_encodings["attention_mask"],
"labels": target_encodings["input_ids"]}
dataset_samsum_pt = dataset_samsum.map(convert_examples_to_features,
batched=True)
columns = ["input_ids", "labels", "attention_mask"]
dataset_samsum_pt.set_format(type="torch", columns=columns)使用标记化步骤的一个新事物是 tokenizer.as_target_tokenizer()上下文。某些模型需要解码器输入中的特殊标记,因此区分编码器和解码器输入的标记化很重要。在with语句(称为上下文管理器)中,分词器知道它正在为解码器分词,并可以相应地处理序列。
现在,我们需要创建数据整理器。该函数在 Trainer就在批次通过模型馈送之前。在大多数情况下,我们可以使用默认的整理器,它从批次中收集所有张量并简单地堆叠它们。对于摘要任务,我们不仅需要堆叠输入,还需要在解码器端准备目标。PEGASUS 是一个编码器-解码器转换器,因此具有经典的 seq2seq 架构。在 seq2seq 设置中,一种常见的方法是在解码器中应用“教师强制”。使用这种策略,解码器接收输入令牌(就像在 GPT-2 等仅解码器模型中一样),除了编码器输出之外,还包括移位了的标签;因此,在对下一个标记进行预测时,解码器将地面实况移动一个作为输入,如下表所示:
| decoder_input | label | |
|---|---|---|
| step | ||
| 1 | [PAD] | Transformers |
| 2 | [PAD, Transformers] | are |
| 3 | [PAD, Transformers, are] | awesome |
| 4 | [PAD, Transformers, are, awesome] | for |
| 5 | [PAD, Transformers, are, awesome, for] | text |
| 6 | [PAD, Transformers, are, awesome, for, text] | summarization |
我们将其移动一个,以便解码器只看到以前的真实标签,而不是当前或未来的标签。单独移位就足够了,因为解码器已经掩盖了自我注意,它掩盖了当前和未来的所有输入。
因此,当我们准备批处理时,我们通过将标签向右移动一个来设置解码器输入。之后,我们通过将标签中的填充标记设置为 –100 来确保它们被损失函数忽略。不过,我们实际上不必手动执行此操作,因为DataCollatorForSeq2Seq它可以进行救援并为我们处理所有这些步骤:
from transformers import DataCollatorForSeq2Seq
seq2seq_data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)然后,像往常一样,我们设置了一个TrainingArguments用于训练的:
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir='pegasus-samsum', num_train_epochs=1, warmup_steps=500,
per_device_train_batch_size=1, per_device_eval_batch_size=1,
weight_decay=0.01, logging_steps=10, push_to_hub=True,
evaluation_strategy='steps', eval_steps=500, save_steps=1e6,
gradient_accumulation_steps=16)与以前的设置不同的一件事是新参数gradient_accumulation_steps. 由于模型很大,我们不得不将批量大小设置为 1。但是,批量大小太小会影响收敛。为了解决这个问题,我们可以使用一种称为梯度累积的绝妙技术。顾名思义,我们不是一次计算整个批次的梯度,而是制作更小的批次并聚合梯度。当我们聚合了足够多的梯度时,我们运行优化步骤。当然,这比一次性完成要慢一些,但它为我们节省了大量的 GPU 内存。
现在让我们确保我们已登录到 Hugging Face,以便我们可以在训练后将模型推送到 Hub:
from huggingface_hub import notebook_login
notebook_login()现在,我们拥有了使用模型、标记器、训练参数和数据收集器以及训练和评估集初始化训练器所需的一切:
trainer = Trainer(model=model, args=training_args,
tokenizer=tokenizer, data_collator=seq2seq_data_collator,
train_dataset=dataset_samsum_pt["train"],
eval_dataset=dataset_samsum_pt["validation"])我们准备好接受培训了。训练完成后,我们可以直接在测试集上运行评估函数,看看模型的表现如何:
trainer.train()
score = evaluate_summaries_pegasus(
dataset_samsum["test"], rouge_metric, trainer.model, tokenizer,
batch_size=2, column_text="dialogue", column_summary="summary")
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame(rouge_dict, index=[f"pegasus"])| rouge1 | rouge2 | rougeL | rougeLsum | |
|---|---|---|---|---|
| pegasus | 0.427614 | 0.200571 | 0.340648 | 0.340738 |
我们看到,在没有微调的情况下,ROUGE 分数比模型有很大提高,因此即使之前的模型也经过了总结训练,但它并不能很好地适应新领域。让我们将模型推送到 Hub:
trainer.push_to_hub("Training complete!")在下一节中,我们将使用该模型为我们生成一些摘要。
生成对话摘要
从损失和 ROUGE 分数来看,该模型似乎比仅在 CNN/DailyMail 上训练的原始模型有了显着改进。让我们看看在测试集中的样本上生成的摘要是什么样的:
gen_kwargs = {"length_penalty": 0.8, "num_beams":8, "max_length": 128}
sample_text = dataset_samsum["test"][0]["dialogue"]
reference = dataset_samsum["test"][0]["summary"]
pipe = pipeline("summarization", model="transformersbook/pegasus-samsum")
print("Dialogue:")
print(sample_text)
print("\nReference Summary:")
print(reference)
print("\nModel Summary:")
print(pipe(sample_text, **gen_kwargs)[0]["summary_text"])Dialogue: Hannah: Hey, do you have Betty's number? Amanda: Lemme check Hannah: <file_gif> Amanda: Sorry, can't find it. Amanda: Ask Larry Amanda: He called her last time we were at the park together Hannah: I don't know him well Hannah: <file_gif> Amanda: Don't be shy, he's very nice Hannah: If you say so.. Hannah: I'd rather you texted him Amanda: Just text him Hannah: Urgh.. Alright Hannah: Bye Amanda: Bye bye Reference Summary: Hannah needs Betty's number but Amanda doesn't have it. She needs to contact Larry. Model Summary: Amanda can't find Betty's number. Larry called Betty last time they were at the park together. Hannah wants Amanda to text Larry instead of calling Betty.
这看起来更像参考摘要。该模型似乎已经学会了将对话合成为摘要,而不仅仅是提取段落。现在,终极测试:模型在自定义输入上的效果如何?
custom_dialogue = """\
Thom: Hi guys, have you heard of transformers?
Lewis: Yes, I used them recently!
Leandro: Indeed, there is a great library by Hugging Face.
Thom: I know, I helped build it ;)
Lewis: Cool, maybe we should write a book about it. What do you think?
Leandro: Great idea, how hard can it be?!
Thom: I am in!
Lewis: Awesome, let's do it together!
"""
print(pipe(custom_dialogue, **gen_kwargs)[0]["summary_text"])Thom, Lewis and Leandro are going to write a book about transformers. Thom helped build a library by Hugging Face. They are going to do it together.
自定义对话的生成摘要是有意义的。它很好地总结了讨论中的所有人都想一起写这本书,而不是简单地提取单个句子。例如,它将第三行和第四行合成为逻辑组合。
结论
与其他可以作为分类任务的任务相比,文本摘要提出了一些独特的挑战,如情感分析、命名实体识别或问答。诸如准确性之类的传统指标并不能反映生成文本的质量。正如我们所见,BLEU 和 ROUGE 指标可以更好地评估生成的文本;然而,人的判断仍然是最好的衡量标准。
使用摘要模型时的一个常见问题是我们如何总结文本长于模型上下文长度的文档。不幸的是,没有单一的策略来解决这个问题,迄今为止,这仍然是一个开放且活跃的研究问题。例如,OpenAI 最近的工作展示了如何通过递归地将摘要应用于长文档并在循环中使用人工反馈来扩展摘要。6
在下一章中,我们将讨论问答,这是根据文本段落为问题提供答案的任务。与摘要相反,对于这项任务,存在处理长文档或多文档的好策略,我们将向您展示如何将问题回答扩展到数千个文档。

















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











