







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
语言模型的内部运作方式以及LLMs对文本分类、生成和机器翻译等 NLP 任务的影响。近年来,LLMs的另一个强大应用越来越受到关注:语义搜索。
现在您可能会想,是时候最终学习与 ChatGPT 和 GPT-4 对话的最佳方法以获得最佳结果了。与此同时,我想向您展示我们还可以在这种新颖的变压器架构之上构建什么。虽然像 GPT 这样的文本到文本生成模型本身就非常令人印象深刻,但人工智能公司提供的最通用的解决方案之一是能够基于强大的LLMs生成文本嵌入。
文本嵌入是一种根据文本数据语料库中单词或短语的上下文含义将单词或短语表示为高维空间中的向量的方法。这个想法是,如果两个短语相似,那么表示这些短语的向量应该靠近在一起,反之亦然。如图 1 显示了一个简单搜索算法的示例。当用户搜索要购买的物品时(例如魔法采集交易卡),他们可能会简单地搜索“复古魔法卡”。然后,系统应该嵌入查询,以便如果两个彼此靠近的文本嵌入应该表明用于生成它们的短语是相似的。

图 1 表示相似短语的向量应该靠近,而表示不相似短语的向量应该远离。在这种情况下,如果用户想要一张交易卡,他们可能会要求“一张老式魔法卡”。正确的语义搜索系统应该以这样的方式嵌入查询:即使它们共享某些关键字,它最终也会靠近相关结果(例如“魔术卡”)并远离不相关的项目(例如“老式魔术套件”)。
这种从文本到向量的映射可以被认为是一种有意义的哈希。我们无法真正将向量反转回文本,而是它们是文本的表示,具有在编码状态下具有比较点的能力的额外好处。
支持 LLM 的文本嵌入使我们能够捕获单词和短语的语义价值,而不仅仅是其表面语法或拼写。我们可以依靠法学硕士的预训练和微调,利用有关语言使用的丰富信息源,在其之上构建几乎无限的应用程序。
关于使用LLMs的语义搜索世界,探索如何使用它们来创建强大的信息检索和分析工具。
话不多说,让我们直接进入正题吧?
任务
传统的搜索引擎通常会获取您输入的内容,然后为您提供一堆指向包含您输入的单词或字符排列的网站或项目的链接。因此,如果您在在市场中,您将获得标题/描述包含这些单词组合的项目。这是一种非常标准的搜索方式,但并不总是最好的方式。例如,我可能会得到老式魔法套装来帮助我学习如何从帽子里变出兔子。有趣但不是我所要求的。
您在搜索引擎中输入的术语可能并不总是与您想要查看的项目中使用的单词完全一致。查询中的单词可能过于笼统,导致出现大量不相关的结果。这个问题通常不仅仅局限于结果中的不同措辞;相同的单词可能具有与搜索的含义不同的含义。这就是语义搜索发挥作用的地方,如前面提到的万智牌场景所示。
非对称语义搜索
语义搜索系统可以理解搜索查询的含义和上下文,并将其与可检索文档的含义和上下文进行匹配。这种系统可以在数据库中找到相关结果,而不必依赖精确的关键字或 n-gram 匹配,而是依赖预先训练的 LLM 来理解查询和文档的细微差别(图 2 )。

图 2 传统的基于关键字的搜索可能会对老式魔术套件进行排名,其权重与我们实际想要的物品相同,而语义搜索系统可以理解我们正在搜索的实际概念
非对称语义搜索的不对称部分是指输入查询的语义信息(基本上是大小)与搜索系统必须检索的文档/信息之间通常存在不平衡。例如,搜索系统试图将“魔法收集卡”与市场上的商品描述段落进行匹配。四词搜索查询的信息比段落少得多,但尽管如此,它仍然是我们正在比较的内容。
即使您在搜索中没有使用完全正确的单词,非对称语义搜索系统也可以获得非常准确且相关的搜索结果。他们依赖于法学硕士的学习,而不是用户能够准确地知道要在大海捞针中寻找什么。
当然,我过于简单化了传统方法。有很多方法可以提高它们的性能,而无需切换到更复杂的法学硕士方法,而纯语义搜索系统并不总是答案。它们不仅仅是“更好的搜索方式”。语义算法有其自身的缺陷,例如:
- 1.他们可能对文本中的微小变化过于敏感,例如大小写或标点符号的差异。
2.他们与微妙的概念作斗争,例如依赖当地文化知识的讽刺或反讽。
3.与传统方法相比,它们的实施和维护在计算上可能更加昂贵,特别是在启动具有许多开源组件的本土系统时。
在某些情况下,语义搜索系统可能是一个有价值的工具,所以让我们直接讨论如何构建我们的解决方案。
解决方案概述
我们的非对称语义搜索系统的一般流程将遵循以下步骤:
第一部分 - 摄取文档(图 3)
1. 收集嵌入文件
2. 创建文本嵌入来编码语义信息
3. 将嵌入存储在数据库中,以便以后根据查询进行检索

图 3 放大第一部分,存储文档将包括对文档进行一些预处理、嵌入它们,然后将它们存储在某个数据库中
第二部分 - 检索文档(图 4)
1. 用户有一个可以被预处理和清理的查询
2. 检索候选人文件
3. 如有必要,对候选文件重新排序
4.返回最终搜索结果

图 4 放大第二部分,检索文档时,我们必须使用与文档相同的嵌入方案来嵌入查询,然后将它们与之前存储的文档进行比较,并返回最佳(最接近)的文档
组件
让我们更详细地了解每个组件,以了解我们正在做出的选择以及我们需要考虑哪些因素。
文本嵌入器
众所周知,任何语义搜索系统的核心都是文本嵌入器。该组件接收文本文档、单个单词或短语,并将其转换为向量。该向量对于该文本来说是唯一的,并且应该捕获该短语的上下文含义。
文本嵌入器的选择至关重要,因为它决定了文本矢量表示的质量。我们在如何使用 LLM 进行矢量化方面有很多选择,包括开源和闭源。为了更快地起步,我们将使用 OpenAI 的闭源“Embeddings”产品。在后面的部分中,我将介绍一些开源选项。
OpenAI的“Embeddings”是一个强大的工具,可以快速提供高质量的向量,但它是一个闭源产品,这意味着我们对其实现和潜在偏差的控制有限。重要的是要记住,在使用闭源产品时,我们可能无法访问底层算法,这可能会使解决可能出现的任何问题变得困难。
是什么让文本片段变得“相似”
一旦我们将文本转换为向量,我们就必须找到一种数学表示来确定文本片段是否“相似”。余弦相似度是衡量两个事物相似程度的一种方法。它查看两个向量之间的角度,并根据它们的方向接近程度给出分数。如果向量指向完全相同的方向,则余弦相似度为 1。如果它们垂直(相距 90 度),则为 0。如果它们指向相反的方向,则为 -1。向量的大小并不重要,重要的是它们的方向。
图 5 显示了余弦相似度如何帮助我们检索给定查询的文档。
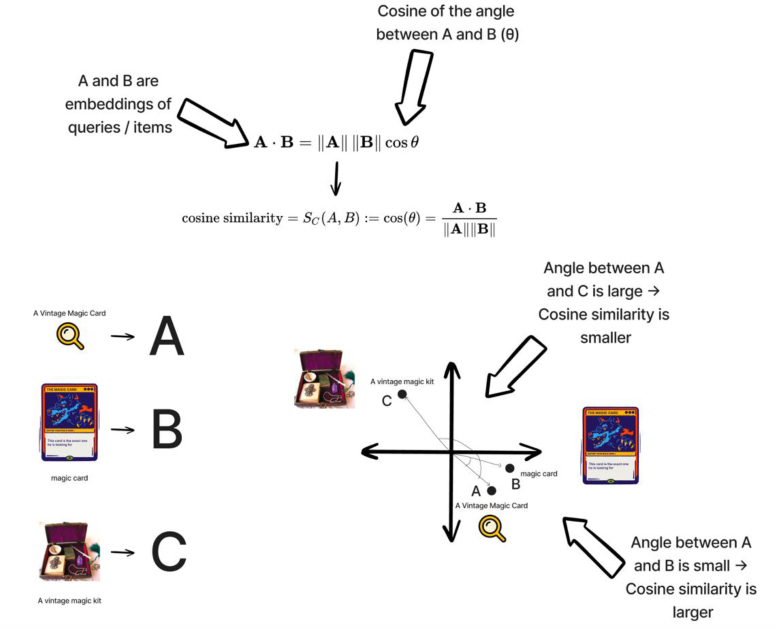
图 5 在理想的语义搜索场景中,余弦相似度(顶部给出的公式)为我们提供了一种计算有效的方法来大规模比较文本片段,假设嵌入被调整为将语义相似的文本片段放置在彼此附近(底部) )。我们首先嵌入所有项目 - 包括查询(左下角),然后检查它们之间的角度。角度越小,余弦相似度越大(右下)
我们还可以转向其他相似性度量,例如点积或欧几里得距离,但 OpenAI 嵌入有一个特殊的属性。它们向量的大小(长度)被归一化为长度 1,这基本上意味着我们在数学上受益于两个方面:
1.余弦相似度与点积相同
2.余弦相似度和欧氏距离将导致相同的排名
TL;DR:拥有归一化向量(大小均为 1)非常好,因为我们可以使用廉价的余弦计算来查看两个向量的接近程度,以及通过余弦相似度来了解两个短语在语义上的接近程度。
OpenAI 的嵌入
从 OpenAI 获取嵌入就像几行代码一样简单()。如前所述,整个系统依赖于一种嵌入机制,该机制将语义相似的项目放置在彼此附近,以便当项目实际上相似时,余弦相似度很大。我们可以使用多种方法来创建这些嵌入,但我们现在将依靠 OpenAI 的嵌入引擎来为我们完成这项工作。引擎是 OpenAI 提供的不同嵌入机制。我们将使用他们为大多数用例推荐的最新引擎。
从 OpenAI 获取文本嵌入
# 导入脚本运行所需的模块
import openai
from openai.embeddings_utils import get_embeddings, get_embedding
# 使用存储在环境变量“OpenAI_API_key”中的值设置OpenAI API密钥
openai.api_key = os.environ.get('OPENAI_API_KEY')
# 设置用于文本嵌入的引擎
ENGINE = 'text-embedding-ada-002'
# 使用指定引擎生成给定文本的向量表示。
embedded_text = get_embedding('I love to be vectorized', engine=ENGINE)
# 检查结果向量的长度,以确保其为预期大小(1536)
len(embedded_text) == '1536'值得注意的是,OpenAI 提供了多种可用于文本嵌入的引擎选项。每个引擎可以提供不同级别的准确性,并且可以针对不同类型的文本数据进行优化。在撰写本文时,代码块中使用的引擎是最新的,也是他们推荐使用的引擎。
此外,还可以一次将多段文本传递给“get_embeddings”函数,该函数可以在单个 API 调用中为所有文本生成嵌入。这比为每个单独的文本多次调用“get_embedding”更有效。稍后我们会看到一个这样的例子。
开源嵌入替代方案
虽然 OpenAI 和其他公司提供了强大的文本嵌入产品,但也有几种可用于文本嵌入的开源替代方案。一种流行的方法是采用 BERT 的双编码器,这是一种强大的基于深度学习的算法,已被证明可以在一系列自然语言处理任务上产生最先进的结果。我们可以在许多开源存储库中找到预训练的双编码器,包括Sentence Transformers库,它为各种自然语言处理任务提供了现成的预训练模型。
双编码器涉及训练两个 BERT 模型,一个对输入文本进行编码,另一个对输出文本进行编码(图 6)。这两个模型在大量文本数据上同时进行训练,目的是最大化相应的输入和输出文本对之间的相似性。生成的嵌入捕获输入和输出文本之间的语义关系。
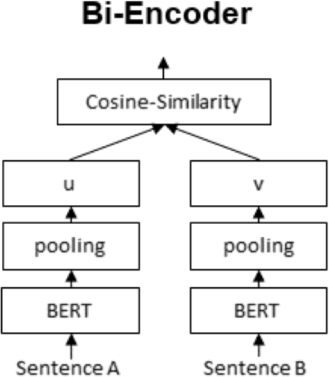
图 6 双编码器以独特的方式进行训练,并行训练单个 LLM 的两个克隆,以学习文档之间的相似性。例如,双编码器可以学习将问题与段落关联起来,以便它们在向量空间中彼此靠近
代码片段2 是使用带有“sentence_transformer”包的预训练双编码器嵌入文本的示例:
代码片段2 从预先训练的开源双编码器获取文本嵌入
# 导入SentenceTransformer库
from sentence_transformers import SentenceTransformer
# 用“multi-qa-mpnet-base-cos-v1”预训练模型初始化SentenceTransformer模型
model = SentenceTransformer(
'sentence-transformers/multi-qa-mpnet-base-cos-v1')
# 定义要生成嵌入的文档列表
docs = [
"Around 9 Million people live in London",
"London is known for its financial district"
]
# 为文档生成向量嵌入
doc_emb = model.encode(
docs, # 我们的文档(字符串的iterable)
batch_size=32, # 按此尺寸批处理嵌入件
show_progress_bar=True # 显示进度条
)
# 嵌入件的形状为(2,768),表示长度为768,生成了两个嵌入件
doc_emb.shape # == (2, 768)此代码创建“SentenceTransformer”类的一个实例,该实例使用预训练模型“multi-qa-mpnet-base-cos-v1”进行初始化。该模型是为多任务学习而设计的,特别是针对问答和文本分类等任务。特别是这个是使用非对称数据进行预训练的,因此我们知道它可以处理短查询和长文档,并且能够很好地比较它们。我们使用 SentenceTransformer 类中的“encode”函数来生成文档的向量嵌入,并将生成的嵌入存储在“doc_emb”变量中。
不同的算法可能对不同类型的文本数据表现更好,并且具有不同的向量大小。算法的选择会对嵌入结果的质量产生重大影响。此外,开源替代品可能比闭源产品需要更多的定制和微调,但它们也提供了更大的灵活性和对嵌入过程的控制。有关使用开源双编码器嵌入文本的更多示例,请查看本书的代码部分!
文档分块器
一旦我们设置了文本嵌入引擎,我们就需要考虑嵌入大型文档的挑战。将整个文档嵌入为单个向量通常是不切实际的,特别是在处理书籍或研究论文等长文档时。此问题的一种解决方案是使用文档分块,其中涉及将大型文档划分为更小、更易于管理的块以进行嵌入。
最大令牌窗口分块
文档分块的一种方法是最大令牌窗口分块。这是最容易实现的方法之一,涉及将文档分割成给定最大大小的块。因此,如果我们将令牌窗口设置为 500,那么我们预计每个块将略低于 500 个令牌。让我们的块大小大致相同也将有助于使我们的系统更加一致。
这种方法的一个常见问题是我们可能会意外地切断块之间的一些重要文本,从而分割上下文。为了缓解这种情况,我们可以设置具有指定数量令牌的重叠窗口来重叠,以便我们在块之间共享令牌。这当然会带来一种冗余感,但这通常可以满足更高的准确性和延迟。
让我们看一下带有一些示例文本的重叠窗口分块的示例(代码片段 3)。让我们从摄取一个大文档开始。我最近写的一本超过 400 页的书怎么样?
代码片段 3摄取整本教科书
# 使用PyPDF2库读取PDF文件
import PyPDF2
# 以读取二进制模式打开PDF文件
with open('../data/pds2.pdf', 'rb') as file:
# 创建PDF阅读器对象
reader = PyPDF2.PdfReader(file)
# 初始化空字符串以保存文本
principles_of_ds = ''
# 循环浏览PDF文件中的每个页面
for page in tqdm(reader.pages):
# 从页面中提取文本
text = page.extract_text()
# 找到要提取的文本的起点
# 在本例中,我们从字符串“]”开始提取文本
principles_of_ds += '\n\n' + text[text.find(' ]')+2:]
# 从结果字符串中去掉任何前导或尾随空格
principles_of_ds = principles_of_ds.strip()现在让我们通过获取至多特定令牌大小的块来对该文档进行分块(代码片段 4)。
代码片段 4 : 对有重叠和没有重叠的教科书进行分块
# 函数将文本拆分为最大数量的标记块。灵感来自OpenAI
def overlapping_chunks(text, max_tokens = 500, overlapping_factor = 5):
'''
max_tokens: 每个区块需要的令牌
overlapping_factor: 每个语块开始时与前一个语块重叠的句子数
'''
# 使用标点符号拆分文本
sentences = re.split(r'[.?!]', text)
# 获取每个句子的标记数
n_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences]
chunks, tokens_so_far, chunk = [], 0, []
# 循环遍历在元组中连接在一起的句子和标记
for sentence, token in zip(sentences, n_tokens):
# 如果到目前为止标记的数量加上当前句子中标记的数量更大
# 大于最大令牌数,然后将区块添加到区块列表并重置
# 到目前为止的区块和标记
if tokens_so_far + token > max_tokens:
chunks.append(". ".join(chunk) + ".")
if overlapping_factor > 0:
chunk = chunk[-overlapping_factor:]
tokens_so_far = sum([len(tokenizer.encode(c)) for c in chunk])
else:
chunk = []
tokens_so_far = 0
# 如果当前句子中的标记数大于
# tokens,转到下一句
if token > max_tokens:
continue
# 否则,将句子添加到chunk中,并将标记的数量添加到总数中
chunk.append(sentence)
tokens_so_far += token + 1
return chunks
split = overlapping_chunks(principles_of_ds, overlapping_factor=0)
avg_length = sum([len(tokenizer.encode(t)) for t in split]) / len(split)
print(f'non-overlapping chunking approach has {len(split)} documents with average length {avg_length:.1f} tokens')
# 每块有5个重叠句子
split = overlapping_chunks(principles_of_ds, overlapping_factor=5)
avg_length = sum([len(tokenizer.encode(t)) for t in split]) / len(split)
print(f'overlapping chunking approach has {len(split)} documents with average length {avg_length:.1f} tokens')
non-overlapping chunking approach has 286 documents with average length 474.1 tokens
overlapping chunking approach has 391 documents with average length 485.4 tokens
通过重叠,我们看到文档块的数量增加,但大小大致相同。重叠系数越高,我们在系统中引入的冗余就越多。最大令牌窗口方法没有考虑文档的自然结构,并且可能导致信息被分割成块或具有重叠信息的块,从而使检索系统混乱。
查找自定义分隔符
为了帮助我们的分块方法,我们可以搜索自定义自然分隔符。我们将识别文本中的自然空白,并使用它们来创建更有意义的文本单元,这些文本单元最终将形成最终嵌入的文档块(图7)。
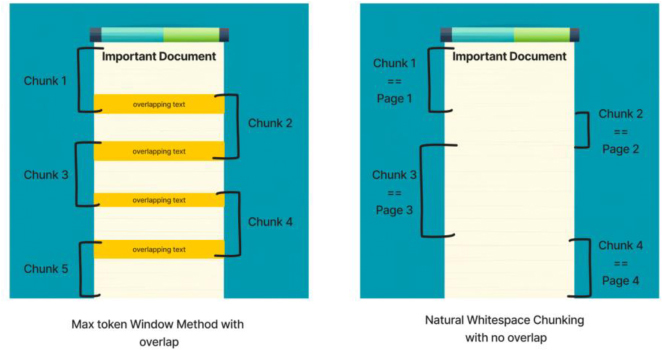
图 7 最大令牌分块(左侧)和自然空白分块(右侧)可以重叠或不重叠进行。自然的空白分块往往会导致块大小不一致。
让我们寻找课本中常见的空格(代码片段 5 )。
代码片段 5 :用自然空白对教科书进行分块
# 导入 Counter 和 re 库
from collections import Counter
import re
# 在“principles_of_ds”中查找一个或多个空格的所有匹配项
matches = re.findall(r'[\s]{1,}', principles_of_ds)
# 文档中出现频率最高的5个空格
most_common_spaces = Counter(matches).most_common(5)
# 打印最常见的空格及其频率
print(most_common_spaces)
[(' ', 82259),
('\n', 9220),
(' ', 1592),
('\n\n', 333),
('\n ', 250)]
最常见的双空格是连续的两个换行符,这实际上是我之前区分页面的方式,这是有意义的。书中最自然的空白是按页。在其他情况下,我们也可能在段落之间发现了自然的空白。这种方法非常实用,需要对源文档有足够的熟悉和了解。
我们还可以求助于更多的机器学习,在构建文档块的方式上变得更有创意。
使用聚类创建语义文档
文档分块的另一种方法是使用聚类来创建语义文档。这种方法涉及通过组合语义相似的小块信息来创建新文档(图 8)。这种方法需要一些创造力,因为对文档块的任何修改都会改变生成的向量。例如,我们可以使用 scikit-learn 中的聚合聚类实例,其中相似的句子或段落被分组在一起形成新文档。
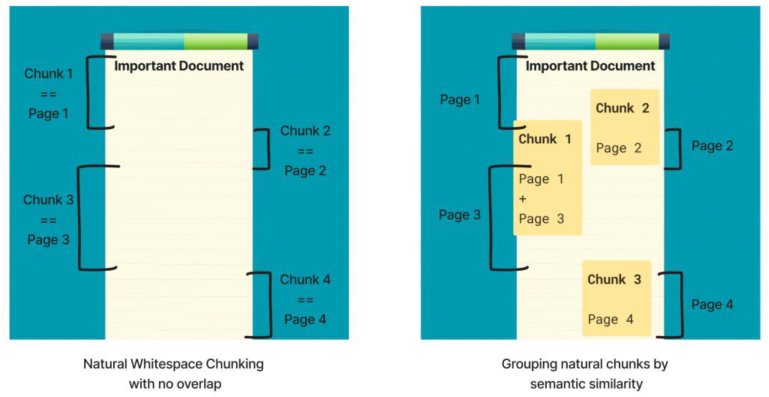
图 8 我们可以通过使用一些单独的语义聚类系统(如右图所示)将任何类型的文档块分组在一起,以创建包含彼此相似信息块的全新文档。
让我们尝试将我们在上一节中从教科书中找到的那些块聚集在一起(代码片段6)。
代码片段6 :通过语义相似度对文档页面进行聚类
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 假设您有一个名为“嵌入”的文本嵌入列表`
# 首先,计算所有嵌入对之间的余弦相似矩阵
cosine_sim_matrix = cosine_similarity(embeddings)
# 实例化AggregativeClustering模型
agg_clustering = AgglomerativeClustering(
n_clusters=None, # 该算法将根据数据确定最佳聚类数
distance_threshold=0.1, # 将形成簇,直到簇之间的所有成对距离大于0.1
affinity='precomputed', # 我们提供一个预计算的距离矩阵(1-相似矩阵)作为输入
linkage='complete' # 通过根据组件之间的最大距离迭代合并最小的簇形成簇
)
# 将模型拟合到余弦距离矩阵(1-相似矩阵)
agg_clustering.fit(1 - cosine_sim_matrix)
# 获取每个嵌入的集群标签
cluster_labels = agg_clustering.labels_
# 打印每个集群中嵌入的数量
unique_labels, counts = np.unique(cluster_labels, return_counts=True)
for label, count in zip(unique_labels, counts):
print(f'Cluster {label}: {count} embeddings')
Cluster 0: 2 embeddings
Cluster 1: 3 embeddings
Cluster 2: 4 embeddings
...
这种方法往往会产生语义上更有凝聚力的块,但会受到内容片段与周围文本脱离上下文的影响。当已知您开始使用的块不一定彼此相关时,即块彼此更加独立时,这种方法很有效。
使用整个文档而不分块
或者,可以使用整个文档而不进行分块。总体而言,这种方法可能是最简单的选择,但当文档太长并且我们在嵌入文本时遇到上下文窗口限制时,就会有缺点。我们还可能成为文档中充满无关的不同上下文点的受害者,并且由此产生的嵌入可能会尝试编码太多,并且可能会降低质量。对于非常大(多页)的文档,这些缺点更加复杂。
在选择文档嵌入方法时,考虑分块和使用整个文档之间的权衡非常重要(表 1 )。一旦我们决定如何对文档进行分块,我们就需要为我们创建的嵌入提供一个家。在本地,我们可以依靠矩阵运算来快速检索,但我们正在为云构建,所以让我们看看我们的数据库选项。
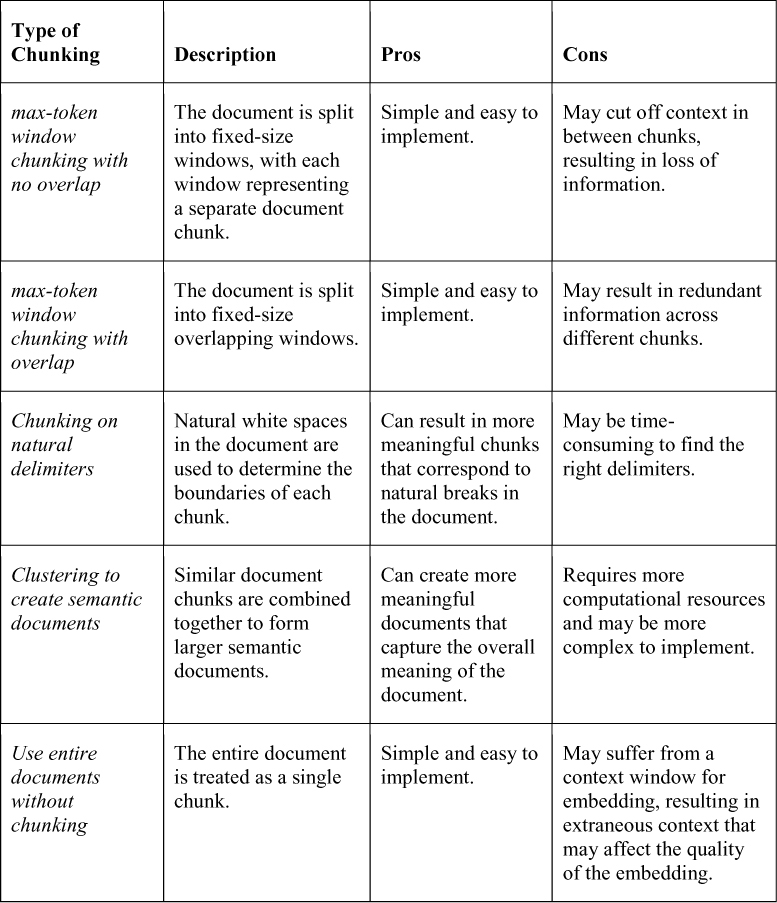
表 1 概述不同文档分块方法的优缺点
矢量数据库
矢量数据库是专门为快速存储和检索矢量而设计的数据存储系统。这种类型的数据库对于存储由法学硕士生成的嵌入非常有用,该嵌入对我们的文档或文档块的语义进行编码和存储。通过将嵌入存储在向量数据库中,我们可以有效地执行最近邻搜索,以根据语义检索相似的文本片段。
Pinecone
Pinecone 是一个矢量数据库,专为中小型数据集(通常适合少于 100 万个条目)而设计。免费开始使用 Pinecone 很容易,但它也有一个定价计划,可提供额外的功能和增强的可扩展性。Pinecone 针对快速矢量搜索和检索进行了优化,使其成为需要低延迟搜索的应用程序(例如推荐系统、搜索引擎和聊天机器人)的绝佳选择。
开源替代品
有几种 Pinecone 的开源替代品可用于构建 LLM 嵌入的向量数据库。其中一个替代方案是 Pgvector,它是一种 PostgreSQL 扩展,增加了对向量数据类型的支持并提供快速向量运算。另一个选择是 Weaviate,这是一个专为机器学习应用程序设计的云原生开源矢量数据库。Weaviate 提供对语义搜索的支持,并且可以与其他机器学习工具(例如 TensorFlow 和 PyTorch)集成。ANNOY 是一个用于近似最近邻搜索的开源库,针对大规模数据集进行了优化。它可用于构建针对特定用例定制的自定义矢量数据库。
对检索结果重新排序
使用余弦相似度等相似度从向量数据库中检索出给定查询的潜在结果后,对它们重新排序通常很有用,以确保向用户呈现最相关的结果(图 9 ) 。对结果进行重新排序的一种方法是使用交叉编码器,这是一种转换器模型,它采用成对的输入序列并预测一个分数,该分数表明第二个序列与第一个序列的相关程度。通过使用交叉编码器对搜索结果重新排名,我们可以考虑整个查询上下文而不仅仅是单个关键字。这当然会增加一些开销并恶化我们的延迟,但它可以在性能方面帮助我们。我将花时间在后面的部分中概述一些结果,以比较和对比使用和不使用交叉编码器。

图 9 交叉编码器(左)接收两段文本并输出相似度分数,而不返回文本的矢量化格式。另一方面,双编码器(右)预先将一堆文本嵌入到向量中,然后根据查询实时检索它们(例如查找“我是数据科学家”)
跨编码器模型的一个流行来源是 Sentence Transformers 库,我们之前在这里找到了双编码器。我们还可以在特定于任务的数据集上微调预训练的交叉编码器模型,以提高搜索结果的相关性并提供更准确的建议。
对搜索结果重新排名的另一种选择是使用传统的检索模型(如 BM25),该模型根据文档中查询术语的频率对结果进行排名,并考虑术语邻近度和逆文档频率。虽然 BM25 没有考虑整个查询上下文,但它仍然是对搜索结果重新排名并提高结果整体相关性的有用方法。
应用程序编程接口
我们现在需要一个地方来放置所有这些组件,以便用户可以快速、安全且轻松地访问文档。为此,我们创建一个 API。
FastAPI
FastAPI是一个用于使用 Python 快速构建 API 的 Web 框架。它的设计既快速又易于设置,使其成为我们语义搜索 API 的绝佳选择。FastAPI使用Pydantic数据验证库来验证请求和响应数据,并使用高性能ASGI服务器uvicorn。
设置 FastAPI 项目非常简单,并且需要最少的配置。FastAPI 提供符合 OpenAPI 标准的自动文档生成功能,可以轻松构建 API 文档和客户端库。代码片段 7 是该文件的框架。
代码片段 7 : FastAPI骨架代码
import hashlib
import os
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
openai.api_key = os.environ.get('OPENAI_API_KEY', '')
pinecone_key = os.environ.get('PINECONE_KEY', '')
# 使用必要的属性在Pinecone中创建索引
def my_hash(s):
# 以十六进制字符串形式返回输入字符串的MD5哈希
return hashlib.md5(s.encode()).hexdigest()
class DocumentInputRequest(BaseModel):
# define input /document/ingest
class DocumentInputResponse(BaseModel):
# define output from /document/ingest
class DocumentRetrieveRequest(BaseModel):
# define input to /document/retrieve
class DocumentRetrieveResponse(BaseModel):
# define output from /document/retrieve
# API route to ingest documents
@app.post("/document/ingest", response_model=DocumentInputResponse)
async def document_ingest(request: DocumentInputRequest):
# 解析请求数据并将其分块
# 为每个区块创建嵌入和元数据
# 向Pinecone上插入嵌入和元数据
# 返回追加的块数
return DocumentInputResponse(chunks_count=num_chunks)
# API route to retrieve documents
@app.post("/document/retrieve", response_model=DocumentRetrieveResponse)
async def document_retrieve(request: DocumentRetrieveRequest):
# 解析请求数据并查询Pinecone以匹配嵌入
# 根据重新排序策略(如有)对结果排序
# 返回文档响应列表
return DocumentRetrieveResponse(documents=documents)
if __name__ == "__main__":
uvicorn.run("api:app", host="0.0.0.0", port=8000, reload=True)要获得完整的文件,请务必查看本书的代码存储库!
把它们放在一起
我们现在拥有适用于所有组件的解决方案。让我们看看我们的解决方案处于什么位置。粗体项目是我们上次概述此解决方案时新增的项目。
第一部分 - 摄取文档
1. 收集用于嵌入的文档 -将它们分块
2. 创建文本嵌入来编码语义信息 - OpenAI's Embedding
3. 将嵌入存储在数据库中,以便以后根据查询进行检索 - Pinecone
第二部分 - 检索文件
1. 用户有一个可以预处理和清理的查询 - FastAPI
2. 检索候选文档——OpenAI的Embedding + Pinecone
3. 如有必要,对候选文档重新排序 - Cross-Encoder
4.返回最终搜索结果-FastAPI
有了所有这些移动部件,让我们看看中图 10 的最终系统架构。

图 10 我们使用两个闭源系统(OpenAI 和 Pinecone)和一个开源 API 框架(FastAPI)的完整语义搜索架构
我们现在为语义搜索提供了完整的端到端解决方案。让我们看看系统在验证集上的表现如何。
表现
我概述了语义搜索问题的解决方案,但我还想谈谈如何测试这些不同组件如何协同工作。为此,我们使用一个众所周知的数据集来运行:BoolQ数据集 - 是/否问题的问答数据集,包含近 16K 个示例。该数据集具有成对的(问题,段落),表明对于给定的问题,该段落将是回答该问题的最佳段落。
我使用嵌入器、重新排名解决方案和一些微调的组合来尝试看看系统在两个方面的表现如何:
1. 性能 - 由最高结果准确度表示。对于我们的 BoolQ 验证集中的每对已知的(问题、段落) - 3,270 个示例,我们将测试系统的最高结果是否是预期的段落。这不是我们可以使用的唯一指标。Sentence_transformers 库还有其他指标,包括排名评估、相关性评估等
2. 延迟 - 我想看看使用 Pinecone 运行这些示例需要多长时间,因此对于每个嵌入器,我重置索引并上传新向量,并在笔记本电脑内存中使用交叉编码器以保持简单和标准化。我将测量针对 BoolQ 数据集的验证集运行所需的分钟延迟
表 2 针对 BoolQ 验证集的各种组合的性能结果


我没有尝试过的一些实验包括:
1. 微调交叉编码器以适应更多时期,并花费更多时间寻找最佳学习参数(例如权重衰减、学习率调度程序等)
2.使用其他OpenAI嵌入引擎
3. 在训练集上微调开源双编码器
请注意,我用于交叉编码器和双编码器的模型都是针对类似于非对称语义搜索的数据进行专门预训练的。这很重要,因为我们希望嵌入器为短查询和长文档生成向量,并在它们相关时将它们放置在彼此附近。
假设我们希望保持简单,让事情顺利进行,并且仅使用 OpenAI 嵌入器,并且在我们的应用程序中不进行重新排名(第 1 行)。让我们考虑一下使用 FastAPI、Pinecone 和 OpenAI 进行文本嵌入的相关成本。
闭源的成本
我们有一些正在使用的组件,但并非所有组件都是免费的。幸运的是FastAPI是一个开源框架,不需要任何许可费用。我们使用 FastAPI 的成本是托管,根据我们使用的服务,托管可能是免费的。我喜欢 Render,它有免费套餐,但价格从每月 7 美元起,可实现 100% 的正常运行时间。在撰写本文时,Pinecone 提供免费套餐,限制为 100,000 个嵌入和最多 3 个索引,但除此之外,他们根据使用的嵌入和索引的数量收费。他们的标准计划每月收费 49 美元,最多可支持 100 万个嵌入和 10 个索引。
OpenAI 提供免费的文本嵌入服务,但每月限制为 100,000 个请求。除此之外,他们对我们使用的嵌入引擎 - Ada-002 收取每 1,000 个代币 0.0004 美元的费用。如果我们假设每个文档平均有 500 个代币,则每个文档的成本将为 0.0002 美元。例如,如果我们想嵌入 100 万份文档,大约需要花费 200 美元。
如果我们想要构建一个具有 100 万个嵌入的系统,并且我们希望每月使用全新的嵌入更新一次索引,那么每月的总成本将为:
Pinecone成本 = 49美元
OpenAI 成本 = 200 美元
FastAPI 成本 = 7 美元
总成本 = 49美元 + 200美元 + 7美元 = 256 美元/月
一个不错的二进制数:)不是故意的,但仍然很有趣。
随着系统的扩展,这些成本会迅速增加,并且可能值得探索开源替代方案或其他策略来降低成本 - 例如使用开源双编码器进行嵌入或使用 Pgvector 作为向量数据库。
概括
考虑到所有这些组件,我们的便士加起来,以及每一步都可用的替代方案,我将把一切留给你们。享受设置新的语义搜索系统的乐趣,并确保在本书的代码存储库上查看完整的代码 - 包括一个完全运行的 FastAPI 应用程序以及如何部署它的说明 - 并根据你的内心内容进行实验以尝试实现这一点尽可能地处理您的特定领域数据。
















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











