







 论文提出通过机器翻译任务训练的双向LSTM得到上下文向量CoVe,用于增强词向量并提升NLP任务(如情感分析、问题分类)的性能。实验表明,CoVe结合GloVe在多项任务中表现优于单独使用GloVe或随机初始化的词向量。
论文提出通过机器翻译任务训练的双向LSTM得到上下文向量CoVe,用于增强词向量并提升NLP任务(如情感分析、问题分类)的性能。实验表明,CoVe结合GloVe在多项任务中表现优于单独使用GloVe或随机初始化的词向量。
论文原文:Learned in Translation: Contextualized Word Vectors
题外话
前段时间一直在写自己的论文,目前论文基本成型,又要转入新一阶段的论文阅读了。由于对GAN等技术不是很了解,所以在挑选论文的时候有选择的避开了和这些技术有关的内容。由于之前一直在学习LSTM,所以就挑选了这篇和LSTM有关的论文进行阅读学习。后期希望能跟上目前NLP技术的脚步,了解一些比较新的技术。
引言
现在比较流行的词向量学习方法有Word2Vec、GloVe等,并且把这些词向量作为一些下游任务的初始化可以提升模型的性能。但是一个词在不同的上下文的意思是不同的,如果准确捕捉到精准的词义依然是NLP中的难题。作者发现,在图像识别领域,研究者经常把ImageNet上预训练的CNN用于其他图像识别模型。那么在NLP中,也可以把一个任务中训练好的模型用于另外一个任务。基于这样的想法,作者提出了将context vectors(CoVe)添加到原有的模型中的方法,并且通过实验证明在常见的NLP任务,例如情感分析、问题分类、推理和问答等,都起到了提升性能的作用。
基本思想
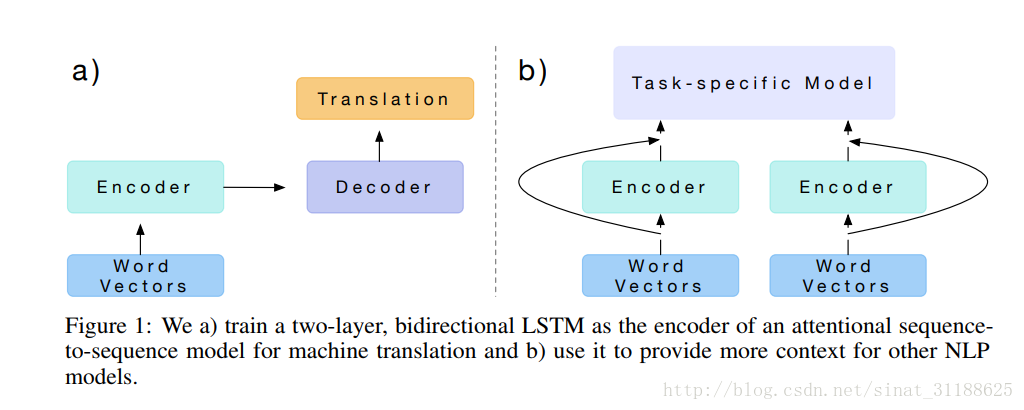
这是文章中给出的一个common architecture。
a)是一个典型的encoder-decoder模型,经常被用于机器翻译中。在这个工作中,作者训练了一个两层双向的LSTM模型作为基于注意力的sequence-to-sequence机器翻译模型的encoder并且将其应用于其他的NLP任务。
具体的,作者通过英语-德语机器翻译任务训练了一个神经网络模型(应该就是ab中的Encoder部分),然后得到上下文向量——CoVe。然后将CoVe和常用词向量通过一定方式结合得到用于特定任务的输入,最终提升任务模型的性能。
上下文向量CoVe
作者在文章中花了很大的篇幅介绍机器翻译模型(不了解机器翻译模型的建议阅读这位大神的博客Link),然而对于上下文相关向量的介绍却只有寥寥几行,因为所谓的上下文相关向量CoVe实际上就是通过机器翻译模型直接得到的:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2986
2986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









