







 本文探讨了在深度学习优化中,Adam等自适应梯度方法使用L2正则化时存在的问题。作者指出,L2正则化在Adam中与Weight Decay不等价,导致权重更新不一致。为解决这个问题,提出了新的算法AdamW,通过将Weight Decay与学习率解耦,提高了优化效果。实验结果显示,这种方法在多种模型上的表现优于传统实现,简化了参数调整,有助于找到最优解。
本文探讨了在深度学习优化中,Adam等自适应梯度方法使用L2正则化时存在的问题。作者指出,L2正则化在Adam中与Weight Decay不等价,导致权重更新不一致。为解决这个问题,提出了新的算法AdamW,通过将Weight Decay与学习率解耦,提高了优化效果。实验结果显示,这种方法在多种模型上的表现优于传统实现,简化了参数调整,有助于找到最优解。
引言
Adam作为一个常用的深度学习优化方法,提出来的时候论文里的数据表现都非常好,但实际在使用中发现了不少问题,在许多数据集上表现都不如SGDM这类方法。
后续有许多工作针对Adam做了研究,之前整理过关于优化算法的发展历程:从Stochastic Gradient Descent到Adaptive Moment Estimation,里面也介绍了一些对于Adam效果不好的研究工作。
这篇论文依旧以此作为研究对象,原文参考:DECOUPLED WEIGHT DECAY REGULARIZATION。作者提出了一个简单, 但是很少有人注意的事实, 那就是现行的所有深度学习框架在处理Weight Decay的时候,都采用了L2正则的方法来做,但实际上,L2正则在自适应梯度方法中,如Adam,与Weight Decay并不等价。
算法
Weight Decay在优化算法中的意义,在于限制值比较大的权重,让整体模型的权重更加接近于零,这也是符合奥卡姆剃刀原理的,权重更小的模型被认为是更简单的模型,从而拥有更好的泛化性能。
对于SGD来说,L2正则与Weight Decay都可以用以下形式表达:
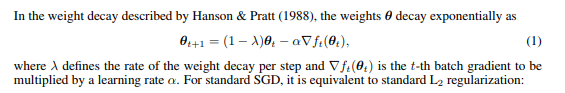
区别在于正则化操作在目标函数加上权
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









