









文章目录
线性SVM
感知机模型
感知机模型是二分类线性判别模型,将所有误分样本的几何间隔作为损失函数,使用随机梯度下降法求解. 所有样本点正确分类时,模型学习完成,最终超平面与初始参数、梯度更新次序有关.
样本离超平面的距离,可近似模型对样本分类的可靠程度. 对于所有满足条件的超平面,距最近样本点距离最大的超平面为最优超平面. 基于此建立的线性可分模型为凸优化模型,解唯一.
点到超平面距离
对于超平面
H
:
w
⊤
x
′
+
b
=
0
\mathcal H:w^\top x' + b=0
H:w⊤x′+b=0,则空间中任意点
x
x
x到
H
\mathcal H
H的距离为
distance
(
x
,
b
,
w
)
=
∣
w
⊤
∣
∣
w
∣
∣
(
x
−
x
′
)
∣
=
1
∣
∣
w
∣
∣
∣
w
⊤
x
+
b
∣
\text{distance}(x,b,w)=\left|\frac{w^\top}{||w||}(x-x')\right|=\frac{1}{||w||}|w^\top x+b|
distance(x,b,w)=∣∣∣∣∣∣w∣∣w⊤(x−x′)∣∣∣∣=∣∣w∣∣1∣w⊤x+b∣
证明: 若
x
′
x'
x′是
H
\mathcal H
H中的任意一点,
x
x
x到
H
\mathcal H
H的距离为
x
−
x
′
x-x'
x−x′在
H
\mathcal H
H法向量
w
w
w上的投影,即
distance
(
x
,
b
,
w
)
=
∣
porject
w
(
x
−
x
′
)
∣
=
∣
1
∣
∣
w
∣
∣
w
⋅
(
x
−
x
′
)
∣
\text{distance}(x,b,w)=|\text{porject}_{w}(x-x')|=\left|\frac{1}{||w||}w\cdot(x-x')\right|
distance(x,b,w)=∣porjectw(x−x′)∣=∣∣∣∣∣∣w∣∣1w⋅(x−x′)∣∣∣∣
点到分类超平面的距离
若样本标签
y
∈
−
1
,
+
1
y\in{-1,+1}
y∈−1,+1,样本
x
x
x的预测标签为
sign
(
w
⊤
x
+
b
)
\text{sign}(w^\top x+b)
sign(w⊤x+b),当超平面将
x
x
x正确划分,则始终满足
y
(
w
⊤
x
+
b
)
≥
0
y(w^\top x+b) \geq 0
y(w⊤x+b)≥0,因此正确划分的
x
x
x到
H
\mathcal H
H的距离等价于
distance
(
x
,
b
,
w
)
=
1
∣
∣
w
∣
∣
y
(
w
⊤
x
+
b
)
\text{distance}(x,b,w)=\frac{1}{||w||}y(w^\top x+b)
distance(x,b,w)=∣∣w∣∣1y(w⊤x+b)
最大化最小几何间隔
缩放
w
w
w可调整
x
x
x到
H
\mathcal H
H的函数间隔,为便于计算,令最小函数间隔为1,则最小函数间隔和几何间隔分别表示为
γ
=
y
i
(
w
T
x
i
+
b
)
=
1
,
γ
^
=
γ
∣
∣
w
∣
∣
=
1
∣
∣
w
∣
∣
\gamma=y_i(w^T x_i+b)=1,\quad\hat\gamma=\frac{\gamma}{|| w||}=\frac{1}{|| w||}
γ=yi(wTxi+b)=1,γ^=∣∣w∣∣γ=∣∣w∣∣1
基于 最大化最小几何间隔 建立模型,优化问题为
max
w
,
b
1
∣
∣
w
∣
∣
s.t.
min
y
i
(
w
T
x
i
+
b
)
=
1
\max_{w,b}\quad\frac{1}{|| w||}\quad\quad \text{s.t.}\quad \min\ y_i(w^Tx_i+b)=1
w,bmax∣∣w∣∣1s.t.min yi(wTxi+b)=1
最小函数间隔为1,等价于所有样本的函数间隔大于等于1,优化问题等价于
max
w
,
b
1
∣
∣
w
∣
∣
s.t.
y
(
w
T
x
+
b
)
≥
1
\max_{w,b}\quad\frac{1}{|| w||}\quad\quad \text{s.t.}\quad y(w^T x+b)\geq1
w,bmax∣∣w∣∣1s.t.y(wTx+b)≥1
等价形式为
max
w
,
b
1
2
∣
∣
w
∣
∣
2
s.t.
y
(
w
T
x
+
b
)
≥
1
\max_{w,b}\quad\frac{1}{2}||w||^2\quad\quad \text{s.t.}\quad y(w^T x+b)\geq1
w,bmax21∣∣w∣∣2s.t.y(wTx+b)≥1
上述问题为凸二次规划问题,有闭式最优解。
软间隔最大化线性SVM
线性不可分意味着存在一些样本点到超平面的函数间隔小于1,为解决这个问题,为每个样本点引入松弛变量
ξ
i
\xi_i
ξi,使得样本到超平面的函数间隔加上松弛变量后不小于1,并为每个松弛变量支付一个代价
ξ
i
\xi_i
ξi,则得软间隔最大化的线性SVM模型:
min
w
,
b
,
ξ
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
ξ
i
s.t.
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
,
ξ
i
≥
0
\begin{aligned} \min_{ w,b, \xi} &\quad\frac{1}{2}|| w||^2+C\sum_i\xi_i\\[1ex] \quad \text{s.t.} &\quad y_i(w^T x_i+b)\geq 1-\xi_i,\quad \xi_i\geq0 \end{aligned}
w,b,ξmins.t.21∣∣w∣∣2+Ci∑ξiyi(wTxi+b)≥1−ξi,ξi≥0
优化目标是是几何间隔尽量大( ∣ ∣ w ∣ ∣ 2 尽 量 小 ||w||^2尽量小 ∣∣w∣∣2尽量小),同时使误分类点数尽量少( ξ i \xi_i ξi尽可能为0), 目标函数第一项为结构风险,第二项为经验风险。惩罚参数 C C C代表模型误分类代价, C C C越大,模型倾向于将所有样本正确划分,模型倾向于过拟合, C C C越小,模型允许部分样本分类错误,模型倾向与欠拟合。
软间隔最大化与合页损失
合页损失(HInge loss)函数
ξ
=
ℓ
hinge
(
z
)
=
max
(
0
,
1
−
z
)
⟹
ξ
≥
1
−
z
\xi=\ell_\text{hinge}(z)=\max(0,1-z)\implies \xi\geq 1-z
ξ=ℓhinge(z)=max(0,1−z)⟹ξ≥1−z
即
z
≥
1
z\geq 1
z≥1,
ξ
=
0
\xi=0
ξ=0;
z
<
0
z\lt0
z<0,
ξ
=
1
−
z
\xi=1-z
ξ=1−z.
令函数间隔
z
=
y
(
w
T
x
+
b
)
z=y(w^T x+b)
z=y(wTx+b),对于线性不可分问题,以合页函数作为损失函数并加入正则项,模型表示为(可用梯度下降法求解)
min
w
,
b
∑
i
ℓ
hinge
(
y
i
(
w
T
x
i
+
b
)
)
+
λ
∣
∣
w
∣
∣
2
\min_{ w,b}\quad \sum_i\ell_\text{hinge}(y_i(w^T x_i+b))+\lambda|| w||^2
w,bmini∑ℓhinge(yi(wTxi+b))+λ∣∣w∣∣2
令 λ = 1 / 2 C \lambda=1/2C λ=1/2C,则上述优化问题等价于软间隔最大化SVM模型。LR使用交叉熵损失,关注全局实例,输出具有自然概率意义。
目标函数的对偶形式
原始约束极值问题的构造拉格朗日形式为
min
w
,
b
,
ξ
max
α
,
μ
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
min
w
,
b
,
ξ
max
α
,
μ
{
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
ξ
i
−
∑
i
α
i
[
y
i
(
w
T
x
i
+
b
)
−
1
+
ξ
i
]
−
∑
i
μ
i
ξ
i
}
\min_{ w,b, \xi}\max_{ \alpha, \mu} L(w,b, \xi, \alpha, \mu) =\min_{ w,b, \xi}\max_{ \alpha, \mu} \left\{\frac{1}{2}||w||^2+C\sum_i\xi_i-\sum_i\alpha_i[y_i(w^T x_i+b)-1+\xi_i]-\sum_i\mu_i\xi_i\right\}
w,b,ξminα,μmaxL(w,b,ξ,α,μ)=w,b,ξminα,μmax{21∣∣w∣∣2+Ci∑ξi−i∑αi[yi(wTxi+b)−1+ξi]−i∑μiξi}
原问题内部极大化是不等式约束的等价形式:
- 若存在不满足约束的 x i x_i xi或 ξ i \xi_i ξi,令 α i → + ∞ \alpha_i\to+\infty αi→+∞或 μ i → + ∞ \mu_i\to+\infty μi→+∞,则 max α , μ L = + ∞ \max\limits_{ \alpha, \mu} L=+\infty α,μmaxL=+∞;
- 若任意 x i x_i xi满足约束,则 max α , μ L = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i ξ i \max\limits_{ \alpha, \mu} L=\dfrac{1}{2}||w||^2+ C\sum_i\xi_i α,μmaxL=21∣∣w∣∣2+C∑iξi;
i.
min
w
,
b
,
ξ
L
\min\limits_{ w,b, \xi}L
w,b,ξminL,求
w
,
b
,
ξ
w,b, \xi
w,b,ξ的偏导并令其为0,得
w
=
∑
i
α
i
y
i
x
i
,
∑
i
α
i
y
i
=
0
,
C
−
α
i
−
μ
i
=
0
w=\sum_i\alpha_iy_i x_i,\quad \sum_i\alpha_iy_i=0,\quad C-\alpha_i-\mu_i=0
w=i∑αiyixi,i∑αiyi=0,C−αi−μi=0
ii.
max
α
,
μ
L
\max\limits_{ \alpha, \mu}L
α,μmaxL,带入上述结果,最优化问题转换为
min
α
,
μ
1
2
∑
i
∑
j
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
α
i
s.t.
∑
i
α
i
y
i
=
0
,
α
i
≥
0
,
C
−
α
i
−
μ
i
=
0
,
μ
i
≥
0
\begin{aligned} &\min_{ \alpha, \mu}\quad \frac{1}{2}\sum_i\sum_j\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)-\sum_i\alpha_i\\[0.5ex] &\text{s.t.}\quad\ \ \sum_i\alpha_iy_i=0,\quad \alpha_i\geq0,\quad C-\alpha_i-\mu_i=0,\quad\mu_i\geq0 \end{aligned}
α,μmin21i∑j∑αiαjyiyj(xi⋅xj)−i∑αis.t. i∑αiyi=0,αi≥0,C−αi−μi=0,μi≥0
消去
μ
i
\mu_i
μi得
min
α
1
2
∑
i
∑
j
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
α
i
s.t.
∑
i
α
i
y
i
=
0
,
0
≤
α
i
≤
C
\begin{aligned} &\min_{ \alpha}\quad \frac{1}{2}\sum_i\sum_j\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)-\sum_i\alpha_i\\[0.5ex] &\text{s.t.}\quad\ \ \sum_i\alpha_iy_i=0,\quad 0\leq\alpha_i\leq C \end{aligned}
αmin21i∑j∑αiαjyiyj(xi⋅xj)−i∑αis.t. i∑αiyi=0,0≤αi≤C
基于SMO算法求解约束方程解, α = ( α 1 , α 2 , ⋯ , α n ) T \alpha=(\alpha_1,\alpha_2, \cdots,\alpha_n)^T α=(α1,α2,⋯,αn)T。
令
S
\mathcal S
S表示
0
<
α
<
C
0<\alpha<C
0<α<C的集合,则
y
i
(
w
T
x
i
+
b
)
−
1
=
0
y_i(w^T x_i+b)-1=0
yi(wTxi+b)−1=0,模型参数
w
∗
=
∑
i
∈
S
α
i
y
i
x
i
,
b
∗
=
1
∣
S
∣
∑
i
∈
S
(
y
i
−
w
T
x
i
)
w^*=\sum_{i\in\mathcal S}\alpha_iy_i x_i,\quad b^*=\frac{1}{|\mathcal S|}\sum_{i\in\mathcal S}(y_i- w^T x_i)
w∗=i∈S∑αiyixi,b∗=∣S∣1i∈S∑(yi−wTxi)
实例点计算仅以內积形式出现,可自然引入核函数。
KKT条件和支持向量
KKT条件(最优解必要条件)
{
∇
w
=
w
−
∑
i
α
i
y
i
x
i
=
0
∇
b
=
−
∑
i
α
i
y
i
=
0
∇
ξ
=
C
−
α
−
μ
=
0
α
i
(
y
i
(
w
T
x
i
+
b
)
−
1
+
ξ
i
)
=
0
μ
⋅
ξ
=
0
y
i
(
w
T
x
i
+
b
)
−
1
+
ξ
i
≥
0
ξ
,
α
,
μ
≥
0
\begin{cases} \nabla_{ w}= w-\sum_i\alpha_iy_i x_i= 0\\[1ex] \nabla_{b}=-\sum_i\alpha_iy_i=0\\[1ex] \nabla_{ \xi}= C- \alpha- \mu= 0\\[1ex] \alpha_i(y_i(w^T x_i+b)-1+\xi_i)=0\\[1ex] \mu\cdot \xi= 0\\[1ex] y_i(w^T x_i+b)-1+\xi_i\geq0\\[1ex] \xi, \alpha, \mu\geq 0 \end{cases}
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∇w=w−∑iαiyixi=0∇b=−∑iαiyi=0∇ξ=C−α−μ=0αi(yi(wTxi+b)−1+ξi)=0μ⋅ξ=0yi(wTxi+b)−1+ξi≥0ξ,α,μ≥0
α
i
>
0
\alpha_i>0
αi>0对应的实例为支持向量,由KKT条件知支持向量满足
y
i
(
w
T
x
i
+
b
)
−
1
+
ξ
i
=
0
y_i(w^T x_i+b)-1+\xi_i=0
yi(wTxi+b)−1+ξi=0
- α i = 0 \alpha_i=0 αi=0, ξ i = 0 \xi_i=0 ξi=0,样本位于边界之外(分类正确);
- 0 < α i < C 0<\alpha_i<C 0<αi<C, ξ i = 0 \xi_i=0 ξi=0,样本位于边界上(分类正确);
- α i = C \alpha_i=C αi=C, 0 < ξ i < 1 0\lt\xi_i\lt 1 0<ξi<1,样本位于超平面与边界之间(分类正确); ξ i = 1 \xi_i=1 ξi=1,样本位于超平面上; ξ i > 1 \xi_i>1 ξi>1,样本位于边界之外(分类错误);
非线性SVM和核函数
对于有限维数据,一定存在高维特征空间使样本线性可分. 对于非线性分类问题,首先需将原空间数据变换至新的特征空间(一般为高维),然后在新空间中使用线性分类方法学习分类模型.
SVM中引入核函数,得SVM的决策函数
f
(
x
)
=
sign
(
∑
i
α
i
∗
y
i
K
(
x
i
,
x
)
+
b
∗
)
f(x)=\text{sign}\left(\sum_i\alpha_i^*y_iK(x_i, x)+b^*\right)
f(x)=sign(i∑αi∗yiK(xi,x)+b∗)
核技巧
设
ϕ
(
x
)
\phi(x)
ϕ(x)是一个从
X
\mathcal X
X到
H
\mathcal H
H的映射,对所有的
x
,
z
∈
X
x, z\in \mathcal X
x,z∈X满足
K
(
x
,
z
)
=
ϕ
(
x
)
⋅
ϕ
(
z
)
K(x, z)=\phi(x)\cdot\phi(z)
K(x,z)=ϕ(x)⋅ϕ(z)
定义核函数使得学习隐式地在特征空间中进行,不需要显式定义新的特征空间和映射函数,避免在新的高维空间中做內积运算.
对于映射
ϕ
(
x
)
=
(
x
1
2
,
2
x
1
x
2
,
x
2
2
)
T
\phi(x)=(x_1^2,\sqrt2x_1x_2,x_2^2)^T
ϕ(x)=(x12,2x1x2,x22)T,则
K
(
x
,
z
)
=
(
x
⋅
z
)
2
=
x
1
2
z
1
2
+
2
x
1
z
1
x
2
z
2
+
x
2
2
z
2
2
=
ϕ
(
x
)
⋅
ϕ
(
z
)
K(x, z)=(x\cdot z)^2=x_1^2z_1^2+2x_1z_1x_2z_2+x_2^2z_2^2=\phi(x)\cdot\phi(z)
K(x,z)=(x⋅z)2=x12z12+2x1z1x2z2+x22z22=ϕ(x)⋅ϕ(z)
在低维空间定义的运算等价于中完成高维空间的內积运算,二维空间
(
x
⋅
z
)
2
(x\cdot z)^2
(x⋅z)2等价于三维空间中
ϕ
(
x
)
⋅
ϕ
(
z
)
\phi(x)\cdot\phi(z)
ϕ(x)⋅ϕ(z).
正定核
核函数的条件:K对称,K对应的Gram矩阵半正定.
RBF核(Radial Basis Function Kernel,RBF)
K ( x , z ) = exp ( − 1 2 ∣ ∣ x − z ∣ ∣ 2 ) K(x, z)=\exp(-\frac{1}{2}|| x- z||_2) K(x,z)=exp(−21∣∣x−z∣∣2)
泰勒展开得
K
(
x
,
z
)
=
exp
(
−
1
2
∣
∣
x
∣
∣
2
)
exp
(
−
1
2
∣
∣
z
∣
∣
2
)
exp
(
x
⋅
z
)
=
C
x
C
z
exp
(
x
⋅
z
)
=
C
x
C
z
[
1
+
x
⋅
z
+
1
2
(
x
⋅
z
)
2
+
⋯
]
\begin{aligned} K(x, z) &=\exp(-\frac{1}{2}|| x||_2)\exp(-\frac{1}{2}|| z||_2)\exp(x\cdot z) =C_{ x}C_{ z}\exp(x\cdot z)\\[0.5ex] &=C_{ x}C_{ z}\left[1+ x\cdot z+\frac{1}{2}(x\cdot z)^2+\cdots\right] \end{aligned}
K(x,z)=exp(−21∣∣x∣∣2)exp(−21∣∣z∣∣2)exp(x⋅z)=CxCzexp(x⋅z)=CxCz[1+x⋅z+21(x⋅z)2+⋯]
RBF核等价于在无穷维空间中做內积,容易过拟合.
Sigmoid核
K ( x , z ) = tanh ( x ⋅ z ) K(x, z)=\text{tanh}(x\cdot z) K(x,z)=tanh(x⋅z)
决策函数
f
(
x
)
=
∑
i
α
i
∗
y
i
tanh
(
x
i
⋅
x
)
+
b
∗
f(x)=\sum_i\alpha_i^*y_i\text{tanh}(x_i\cdot x) + b^*
f(x)=i∑αi∗yitanh(xi⋅x)+b∗
等价于仅含有一层隐藏层的神经网络,隐藏层神经元个数等于支持向量数,激活函数为tanh函数.
序列最小最优化(Sequential Minimal Optimization,SMO)
引入核函数的线性SVM的对偶问题
min
α
1
2
∑
i
∑
j
α
i
α
j
y
i
y
j
K
(
x
i
⋅
x
j
)
−
∑
i
α
i
s.t.
∑
i
α
i
y
i
=
0
,
0
≤
α
i
≤
C
\begin{aligned} &\min_{ \alpha}\quad \frac{1}{2}\sum_i\sum_j\alpha_i\alpha_jy_iy_jK(x_i\cdot x_j)-\sum_i\alpha_i\\[0.5ex] &\text{s.t.}\quad\ \ \sum_i\alpha_iy_i=0,\quad 0\leq\alpha_i\leq C \end{aligned}
αmin21i∑j∑αiαjyiyjK(xi⋅xj)−i∑αis.t. i∑αiyi=0,0≤αi≤C
SMO算法启发式求解,若所有解满足KKT条件知,则所得解为最优解. SMO算法每次迭代只优化两个变量(等式约束限制,实际仅优化一个自由变量),固定其它变量,构建二次规划逐渐逼近最优解.
未剪辑解
假定优化变量
α
1
,
α
2
\alpha_1,\alpha_2
α1,α2,则最优化问题等价于
min
α
1
,
α
2
W
(
α
1
,
α
2
)
=
1
2
K
11
α
1
2
+
1
2
K
22
α
2
2
+
y
1
y
2
K
12
α
1
α
2
−
(
α
1
+
α
2
)
+
y
1
α
1
∑
i
=
3
N
y
i
α
i
K
i
1
+
y
2
α
2
∑
i
=
3
N
y
i
α
i
K
i
2
s.t.
α
1
y
1
+
α
2
y
2
=
−
∑
i
=
3
N
α
i
y
i
=
ξ
,
0
≤
α
1
,
α
2
≤
C
\begin{aligned} \min\limits_{\alpha_1,\alpha_2}&\quad W(\alpha_1, \alpha_2)=\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{22}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2-(\alpha_1+\alpha_2)\\ &\qquad\qquad\qquad\ \ +y_1\alpha_1\sum_{i=3}^Ny_i\alpha_iK_{i1}+y_2\alpha_2\sum_{i=3}^Ny_i\alpha_iK_{i2}\\ \text{s.t.} &\quad\alpha_1y_1+\alpha_2y_2=-\sum\limits_{i=3}^N\alpha_iy_i=\xi,\quad 0\leq\alpha_1,\alpha_2\leq C \end{aligned}
α1,α2mins.t.W(α1,α2)=21K11α12+21K22α22+y1y2K12α1α2−(α1+α2) +y1α1i=3∑NyiαiKi1+y2α2i=3∑NyiαiKi2α1y1+α2y2=−i=3∑Nαiyi=ξ,0≤α1,α2≤C
α
2
\alpha_2
α2为自由变量,替换
α
1
\alpha_1
α1,令
W
W
W对
α
2
\alpha_2
α2的偏导为0,得
(
K
11
+
K
22
−
2
K
12
)
α
2
∗
=
y
2
(
y
2
−
y
1
+
ξ
K
12
−
ξ
K
12
+
∑
i
=
3
N
y
i
α
i
K
i
1
−
∑
i
=
3
N
y
i
α
i
K
i
2
)
(K_{11}+K_{22}-2K_{12})\alpha_2^*=y_2(y_2-y_1+\xi K_{12}-\xi K_{12}+\sum_{i=3}^Ny_i\alpha_iK_{i1}-\sum_{i=3}^Ny_i\alpha_iK_{i2})
(K11+K22−2K12)α2∗=y2(y2−y1+ξK12−ξK12+i=3∑NyiαiKi1−i=3∑NyiαiKi2)
令迭代前的预测偏差
E
j
=
∑
i
=
1
N
α
i
y
i
K
i
j
+
b
−
y
j
E_j=\sum_{i=1}^N\alpha_iy_iK_{ij}+b-y_j
Ej=∑i=1NαiyiKij+b−yj,因此未剪短的最优解为
α
2
new,unc
=
α
2
old
+
y
2
(
E
1
−
E
2
)
K
11
+
K
22
−
2
K
12
\alpha_2^{\text{new,unc}}=\alpha_2^{\text{old}}+\frac{y_2(E_1-E_2)}{K_{11}+K_{22}-2K_{12}}
α2new,unc=α2old+K11+K22−2K12y2(E1−E2)
剪辑解
由约束条件知,最优解位于平行于边长为C的正方形的对角线的线段上,如下所示

当
y
1
=
−
y
2
y_1=-y_2
y1=−y2,最优解
α
2
\alpha_2
α2的界限
L
=
max
(
0
,
α
2
old
−
α
1
old
)
,
H
=
min
(
C
,
C
+
α
2
old
−
α
1
old
)
L=\max(0,\alpha_2^{\text{old}}-\alpha_1^{\text{old}}),\quad H=\min(C,C+\alpha_2^{\text{old}}-\alpha_1^{\text{old}})
L=max(0,α2old−α1old),H=min(C,C+α2old−α1old)
当
y
1
=
y
2
y_1=y_2
y1=y2,最优解
α
2
\alpha_2
α2的界限
L
=
max
(
0
,
α
1
old
+
α
2
old
−
C
)
,
H
=
min
(
C
,
α
1
old
+
α
1
old
)
L=\max(0,\alpha_1^{\text{old}}+\alpha_2^{\text{old}}-C),\quad H=\min(C,\alpha_1^{\text{old}}+\alpha_1^{\text{old}})
L=max(0,α1old+α2old−C),H=min(C,α1old+α1old)
因此剪短之后的最优解
α
2
new
=
max
(
L
,
min
(
H
,
α
2
new,unc
)
)
,
α
1
new
=
α
1
old
+
y
1
y
2
(
α
2
old
−
α
2
new
)
\alpha_2^{\text{new}}=\max(L,\min(H,\alpha_2^{\text{new,unc}})),\quad \alpha_1^{\text{new}}=\alpha_{1}^{\text{old}}+y_1y_2(\alpha_2^{\text{old}}-\alpha_2^{\text{new}})
α2new=max(L,min(H,α2new,unc)),α1new=α1old+y1y2(α2old−α2new)
变量选择
初始 α = 0 \alpha= 0 α=0,迭代时变量选择
- α 1 \alpha_1 α1选择违反KKT条件最严重的变量,具体做法是 0 < α i < C 0<\alpha_i<C 0<αi<C的不满足KKT条件的实例,若均满足则在余下实例中查找;
- α 2 \alpha_2 α2选择更新后变化较大的变量, α 2 \alpha_2 α2更新后变化程度正比于 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣,为简化计算,选择具有较大 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣的变量;
如何检验是否满足KKT条件(
ϵ
\epsilon
ϵ误差范围内检验)?
α
=
{
0
,
y
g
(
x
)
≥
1
,
y
E
≥
−
ϵ
(
0
,
C
)
,
y
g
(
x
)
=
1
,
−
ϵ
≤
y
E
≤
ϵ
C
,
y
g
(
x
)
≤
1
,
y
E
≤
ϵ
\alpha=\begin{cases} 0,&yg(x)\geq1,&yE\geq-\epsilon\\[1ex] (0,C),&yg(x)=1,&-\epsilon\leq yE\leq\epsilon\\[1ex] C,&yg(x)\leq1,&yE\leq\epsilon\\ \end{cases}
α=⎩⎪⎪⎨⎪⎪⎧0,(0,C),C,yg(x)≥1,yg(x)=1,yg(x)≤1,yE≥−ϵ−ϵ≤yE≤ϵyE≤ϵ
综上,不满足KKT条件等价于,当
α
i
<
C
\alpha_i \lt C
αi<C,
y
i
E
i
<
−
ϵ
y_iE_i \lt -\epsilon
yiEi<−ϵ,或当
α
i
>
0
\alpha_i \gt0
αi>0,
y
i
E
i
>
ϵ
y_iE_i \gt \epsilon
yiEi>ϵ.
如何更新
b
b
b值?
利用间隔边界上的点
α
1
\alpha_1
α1或
α
2
\alpha_2
α2更新
b
b
b值,假定
α
1
\alpha_1
α1位于间隔边界(任一间隔边界上的点均可),
0
<
α
1
<
C
0<\alpha_1<C
0<α1<C,则
b
new
=
y
1
−
∑
i
=
3
N
α
i
y
i
K
i
1
−
α
1
new
y
1
K
11
−
α
2
new
y
2
K
12
=
−
E
1
−
y
1
K
11
(
α
1
new
−
α
1
old
)
−
y
2
K
12
(
α
2
new
−
α
2
old
)
+
b
old
\begin{aligned} b^{\text{new}} &=y_1 -\sum_{i=3}^N\alpha_iy_iK_{i1} - \alpha_1^{\text{new}}y_1K_{11}-\alpha_2^{\text{new}}y_2K_{12}\\ &=-E_1-y_1K_{11}(\alpha_1^{\text{new}}-\alpha_1^{\text{old}})-y_2K_{12}(\alpha_2^{\text{new}}-\alpha_2^{\text{old}})+b^{\text{old}} \end{aligned}
bnew=y1−i=3∑NαiyiKi1−α1newy1K11−α2newy2K12=−E1−y1K11(α1new−α1old)−y2K12(α2new−α2old)+bold
若
α
1
\alpha_1
α1和
α
2
\alpha_2
α2均位于间隔边界,则分别计算取均值作为新的
b
b
b值. 可见,保存并更新预测误差能加速计算.
如何更新误差
E
E
E值?
若每次更新
α
1
\alpha_1
α1和
α
2
\alpha_2
α2两个变量,比较更新前后误差值
E
j
=
{
∑
i
=
3
N
α
i
y
i
K
i
j
+
α
1
old
y
1
K
j
1
+
α
1
old
y
1
K
j
1
+
b
old
,
更
新
前
∑
i
=
3
N
α
i
y
i
K
i
j
+
α
1
new
y
1
K
j
1
+
α
1
new
y
1
K
j
1
+
b
new
,
更
新
后
E_j= \begin{cases} \displaystyle\sum_{i=3}^N\alpha_iy_iK_{ij}+\alpha_1^{\text{old}}y_1K_{j1}+\alpha_1^{\text{old}}y_1K_{j1}+b^{\text{old}},&更新前\\ \displaystyle\sum_{i=3}^N\alpha_iy_iK_{ij}+\alpha_1^{\text{new}}y_1K_{j1}+\alpha_1^{\text{new}}y_1K_{j1}+b^{\text{new}},&更新后 \end{cases}
Ej=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧i=3∑NαiyiKij+α1oldy1Kj1+α1oldy1Kj1+bold,i=3∑NαiyiKij+α1newy1Kj1+α1newy1Kj1+bnew,更新前更新后
因此,误差的更新公式为
E
j
new
=
E
j
old
+
(
α
1
new
−
α
1
old
)
y
1
K
j
1
+
(
α
2
new
−
α
2
old
)
y
2
K
j
2
+
b
new
−
b
old
E_j^{\text{new}}=E_j^{\text{old}}+(\alpha_1^{\text{new}}-\alpha_1^{\text{old}})y_1K_{j1}+(\alpha_2^{\text{new}}-\alpha_2^{\text{old}})y_2K_{j2}+b^{\text{new}}-b^{\text{old}}
Ejnew=Ejold+(α1new−α1old)y1Kj1+(α2new−α2old)y2Kj2+bnew−bold
Python实现SVC
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
from numpy import *
class Kernel:
@staticmethod
def linear():
return lambda x, y: float(inner(x, y))
@staticmethod
def gaussian(sigma):
return lambda x, y: exp(
float(linalg.norm(x - y)) ** 2 / (-2 * sigma ** 2))
@staticmethod
def _polykernel(dimension, offset):
return lambda x, y: (offset + float(inner(x, y))) ** dimension
@classmethod
def inhomogenous_polynomial(cls, dimension):
return cls._polykernel(dimension=dimension, offset=1.0)
class SVC:
def __init__(self, kernel, C=0.5, max_iter=1000, eps=1e-3):
"""
构造函数
:param kernel: 核函数指针
:param C: 惩罚参数
:param max_iter: 无任何变量改变时的最大迭代次数
:param eps: KKT条件检验范围(容错率)
"""
self.C = C
self.kernel = kernel
self.max_iter = max_iter
self.eps = eps
def fit(self, X, y):
"""
训练模型
:param X: 输入特征集, 样本数*特征数
:param y: 输入标签集, 1*样本数, 类别为+1或-1
:return: self
"""
self._X = mat(X, dtype=float64)
self._Y = mat(y, int8).T
n_samples, n_features = X.shape
# 初始化alpha、gram矩阵、误差矩阵
self._K = self.__gram_matrix(self._X)
self._E = mat(-self._Y, dtype=float64)
self._alphas = mat(zeros((n_samples, 1)))
self.b = 0
# 是否遍历全部变量
entire = True
# 内循环有效更改变量次数
pair_changed = 0
for _ in range(self.max_iter):
print('iter:', _)
# 若已遍历全部变量, 变量未有效更新, 则终止循环
if not entire and pair_changed == 0:
break
pair_changed = 0
if entire:
for i in range(n_samples):
pair_changed += self.__inner_loop(i)
else:
for i in where((self._alphas > 0) & (self._alphas < self.C))[0]:
pair_changed += self.__inner_loop(i)
# 若已遍历全部变量, 则下次一定遍历边界变量;
# 若已遍历边界变量, 变量得到有效更新,则下次仍遍历边界变量;
entire = False if entire else pair_changed == 0
# 计算模型
sv = where(self._alphas > 0)[0]
self.sv_X = self._X[sv]
self.sv_Y = self._Y[sv]
self.sv_alphas = self._alphas[sv]
self.w = (multiply(self.sv_alphas, self.sv_Y).T * self.sv_X).T
return self
def __inner_loop(self, i):
"""内循环"""
# 临时变量, 用于减少访问, 加速计算
alphas, b, C, E, K = self._alphas, self.b, self.C, self._E, self._K
alphaIold, Yi, Ei = alphas[i, 0], self._Y[i, 0], E[i, 0]
# 满足KKT条件, 则跳出本次循环
if not (
alphaIold < C and Yi * Ei < -self.eps or alphaIold > 0 and Yi
* Ei > self.eps):
return 0
# 选择第二个变量
j = self.__select_j(i)
alphaJold, Yj, Ej = alphas[j, 0], self._Y[j, 0], E[j, 0]
# 计算剪辑边界
if Yi == Yj:
L = max(0, alphaJold + alphaIold - C)
H = min(C, alphaJold + alphaIold)
else:
L = max(0, alphaJold - alphaIold)
H = min(C, C + alphaJold - alphaIold)
if L == H:
return 0
eta = K[i, i] + K[j, j] - 2.0 * K[i, j]
if eta == 0:
return 0
# 更新第二个变量
unc = alphaJold + Yj * (Ei - Ej) / eta
alphas[j, 0] = H if unc > H else L if unc < L else unc
deltaJ = Yj * (alphas[j, 0] - alphaJold)
# 更新第一个变量
alphas[i, 0] -= Yi * deltaJ
# 更新b值
deltaI = Yi * (alphas[i, 0] - alphaIold)
b1 = b - Ei - deltaI * K[i, i] - deltaJ * K[i, j]
b2 = b - Ej - deltaI * K[i, j] - deltaJ * K[j, j]
if 0 < alphas[i, 0] < C:
self.b = b1
elif 0 < alphas[j, 0] < C:
self.b = b2
else:
self.b = 0.5 * (b1 + b2)
# 更新误差矩阵
E += ([deltaI, deltaJ] * K[[i, j]]).T + (self.b - b)
return 1 if abs(deltaJ) > 0.00001 else 0
def score(self, X, y):
"""
计算模型预测正确率
:param X: 输入特征集, m*n
:param y: 输入标签集, 1*m
:return: 0~1
"""
y_ptd = self.predict(X)
error_nums = len(where(y_ptd != mat(y).T)[0])
return 1 - error_nums / len(X)
def predict(self, X):
"""
预测类别
:param X: 输入特征集, m*n
:return: 各样本类别, m*1
"""
X = mat(X)
kernel = self.kernel
sv_X = self.sv_X
K = mat([[kernel(x, xi) for xi in sv_X] for x in X])
y = mat([1] * len(X)).T
y[K * multiply(self.sv_alphas, self.sv_Y) + self.b < 0] = -1
return y
def __gram_matrix(self, X):
"""
计算gram矩阵, 用于加速计算
:param X: 输入特征集
:return: gram矩阵
"""
n_samples, n_features = X.shape
K = mat(zeros((n_samples, n_samples)))
# 利用核函数计算内积
for i, x_i in enumerate(X):
for j, x_j in enumerate(X[:i + 1]):
K[i, j] = K[j, i] = self.kernel(x_i, x_j)
return K
def __select_j(self, i):
"""
通过最大化步长的方式来获取第二个alpha值的索引.
:param i: 第一个变量编号
:return: 第二个变量编号
"""
j, E = i, self._E
# 查找最小误差的变量编号
if E[i] > 0:
min_error = inf
for k in where((self._alphas > 0) & (self._alphas < self.C))[0]:
if k != i and E[k] < min_error:
j, min_error = k, E[k]
# 查找最大误差的变量编号
else:
max_error = -inf
for k in where((self._alphas > 0) & (self._alphas < self.C))[0]:
if k != i and E[k] > max_error:
j, max_error = k, E[k]
while j == i:
j = random.randint(0, self._X.shape[0])
return j
if __name__ == '__main__':
def load_data(filename):
"""读取数据"""
X, y = [], []
with open(filename) as f:
for line in f.read().strip().split('\n'):
line_array = line.split('\t')
X.append(line_array[:-1])
y.append(line_array[-1])
return array(X, float64), array(y, float64)
def plot_2Dsvm(X, y, w, b, alphas):
"""显示二维SVM"""
X, y = array(X), array(y)
fig = plt.figure()
ax = fig.add_subplot(111)
# 绘制样本散点图
colors = array(['g'] * X.shape[0])
colors[y > 0] = 'b'
ax.scatter(X[:, 0], X[:, 1], s=30, c=colors, alpha=0.5)
# w1x+w2y+b=0, 取两点绘制超平面及间隔
x_min = X[where(X[:, 0] == X[:, 0].min())[0], 0]
x_max = X[where(X[:, 0] == X[:, 0].max())[0], 0]
x = array([x_min, x_max])
y = (- b - w[0, 0] * x) / w[1, 0]
y1 = (- b - linalg.norm(w, 2) - w[0, 0] * x) / w[1, 0]
y2 = (- b + linalg.norm(w, 2) - w[0, 0] * x) / w[1, 0]
ax.plot(x, y, 'r')
ax.plot(x, y1, 'r--', alpha=0.2)
ax.plot(x, y2, 'r--', alpha=0.2)
for k in where(alphas > 0)[0]:
plt.scatter(X[k, 0], X[k, 1], color='', edgecolors='r', marker='o',
s=150)
plt.show()
X, y = load_data(r"D:\testSet.txt")
svc = SVC(kernel=Kernel.linear(), C=2)
# svc = SVC(kernel=Kernel.gaussian(0.6), C=20)
svc.fit(X, y)
print(svc.score(X, y))
plot_2Dsvm(X, y, svc.w, svc.b, svc._alphas)
数据集百度云链接:https://pan.baidu.com/s/1BmphBTCQLUV-djorG8JdwQ 提取码:krs9
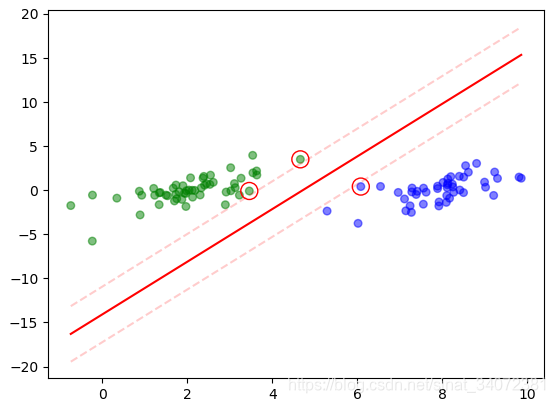 | 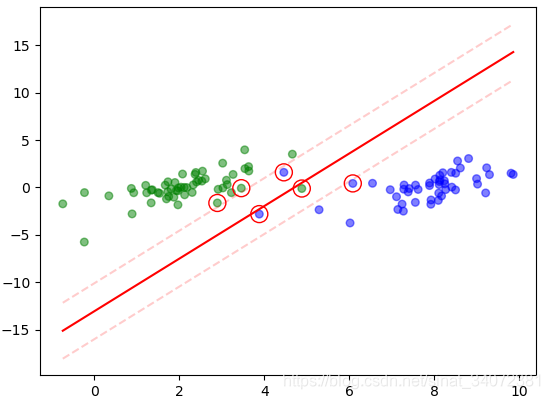 |
|---|---|
| 线性可分SVM | 线性不可分SVM |
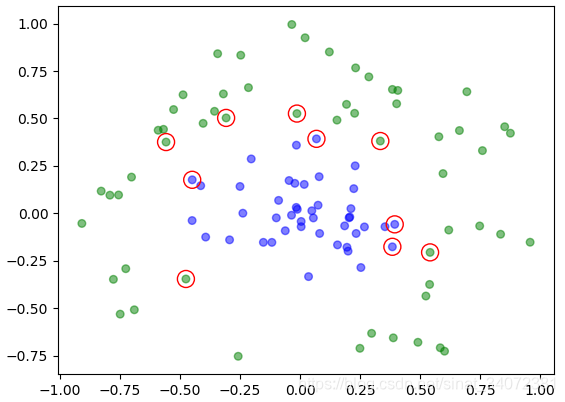 | 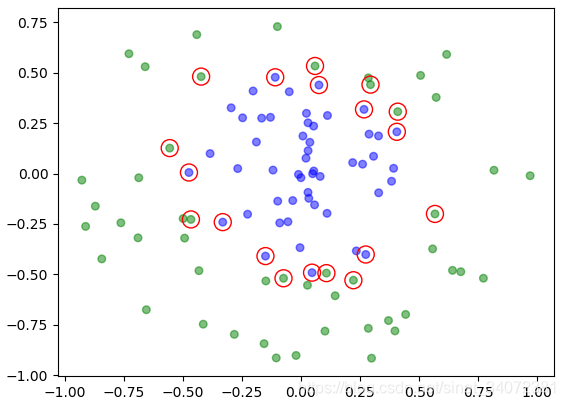 |
| 非线性SVM-1 | 非线性SVM-2 |

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









