







BN怎么计算(训练过程)
设有BN层,即一个BN层可学习的参数有
和
。
对一个mini-batch,。
- 第一步,计算当前batch的均值和方差(对同一层的所有节点):
;
- 第二步,进行规范化:
;
- 第三步,进行平移和缩放:
.
BN的推理过程(如何加速BN?)
采用在训练过程中收集的全局统计量来代替均值和方差:,
.
然后将上面两部分带入到中,得到:
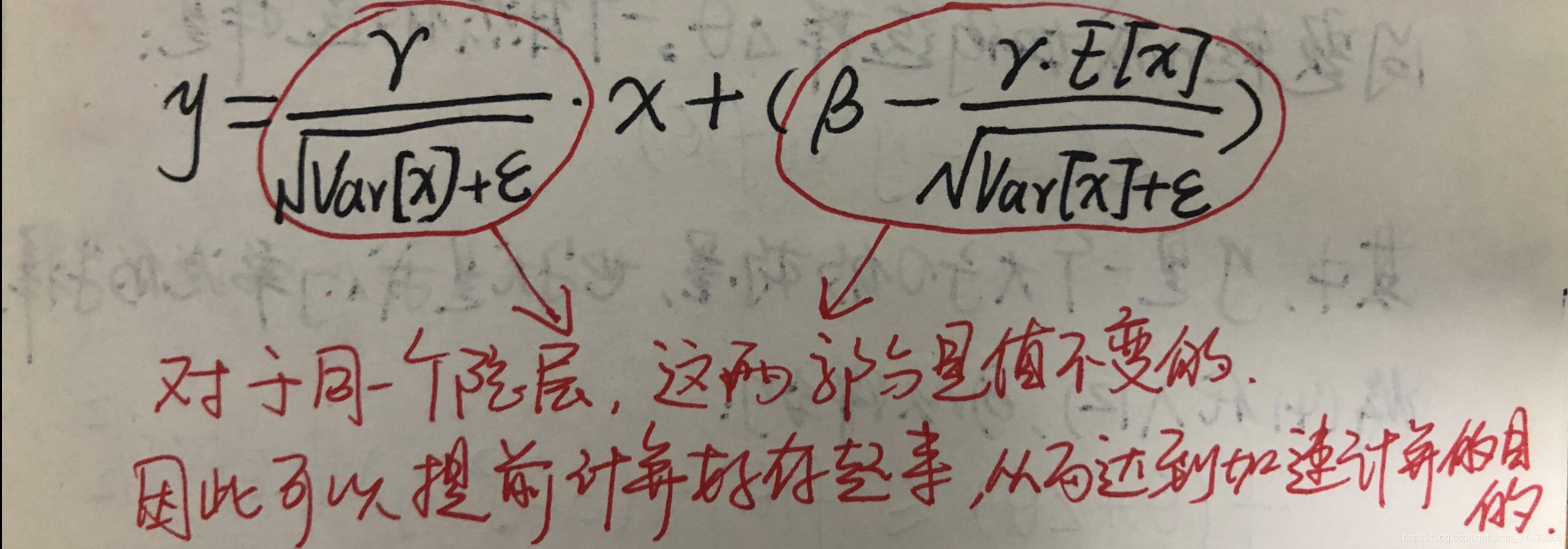
早期解释
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
将每一层的输入都归一化到上,减少所谓的内部协方差漂移(Internal Covariate Shift).
但问题在于,不论是哪一层的输入都不可能是严格满足正态分布的,所以这种解释有些牵强。
新的解释
《How does batch normalization help optimization?》
BN使得整个非线性函数的landscape更为平滑,从而使得训练过程变得更加平稳。
一种易理解的推导思路
设有损失函数,由利普希茨条件,得存在常数
使得下式成立:
通过构建辅助函数(推导过程略),可以推出:
因为训练过程讲究一个梯度下降,所以.
而显然,故只能要求
.
现在问题转化成如何选择合适的,一个自然的选择就是
.
其中,是一个大于0的标量,也就是我们常说的学习率。
将其带入上述不等式,可以得到:
为了保证梯度下降,一个充分条件是:
可以得到两个结论:
(1)足够小,换言之就是学习率足够小,但这样肯定是不可行的;
(2)足够小,这是可行的,还可以间接地允许我们增大学习率。
问题在于,是与
相关的,要想改变
,只能通过改动
实现。
最终得到的结论就是:BN有助于降低网络的常数。从而使得网络更容易训练,比如允许增大学习率等。
定性讨论,因为小了,根据利普希茨条件,也就表明在函数任一点及其邻域上函数值的变化程度不会太大,也就可以理解成函数的走势更平缓了,也就是所谓的landscape平滑了。
虽然想要降低
,但不能以牺牲网络拟合能力为代价,不然直接给
乘个0就完事了。。。因此,想到了要对网络输入做文章。两点讨论证明BN的作用的确如此:
结论1:将网络各层输入减去该层所有样本的均值,有助于在不降低网络拟合能力的情况下降低
结论2:将网络各层输入(减去均值后)除以所有样本的标准差,可以起到类似自适应学习率的作用。使得每一层参数的更新更为同步,减少在某一层过拟合的可能性。
最终结论
想要扩大学习率,提高训练速度,只需要在训练过程中,令每一层的输入都减去其均值,再除以去方差即可。
不过由于mini-batch只是样本整体的一个近似,故batch size还是越大越好,越大对均值和方差的估计更好,但同时对算力提出了一定要求。
此外,在训练过程中,需要维护一组变量将均值和方差保存下来,以便在推理的时候使用。
和
只是锦上添花,可能作用并不大。
完整的解释BN很难,BN的作用更像是多种因素共同起作用的结果。
另一种定性的解释思路
对于我们常用的一些激活函数,一般都是非线性较强的区间。所以,将网络输入归一化到
上,更有助于发挥激活函数的非线性,充分发挥网络的拟合能力。
参考链接:苏剑林. (2019, Oct 11). 《BN究竟起了什么作用?一个闭门造车的分析 》[Blog post]. Retrieved from https://kexue.fm/archives/6992

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









