










【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等

专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等
本专栏主要方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
专栏订阅:深度学习入门到进阶专栏
1.交叉熵损失函数
在物理学中,“熵”被用来表示热力学系统所呈现的无序程度。香农将这一概念引入信息论领域,提出了“信息熵”概念,通过对数函数来测量信息的不确定性。交叉熵(cross entropy)是信息论中的重要概念,主要用来度量两个概率分布间的差异。假定 p和 q是数据 x的两个概率分布,通过 q来表示 p的交叉熵可如下计算:
H ( p , q ) = − ∑ x p ( x ) log q ( x ) H\left(p,q\right)=-\sum\limits_{x}p\left(x\right)\log q\left(x\right) H(p,q)=−x∑p(x)logq(x)
交叉熵刻画了两个概率分布之间的距离,旨在描绘通过概率分布 q来表达概率分布 p的困难程度。根据公式不难理解,交叉熵越小,两个概率分布 p和 q越接近。
这里仍然以三类分类问题为例,假设数据 x属于类别 1。记数据x的类别分布概率为 y,显然 y=(1,0,0)代表数据 x的实际类别分布概率。记 y ^ \hat{y} y^代表模型预测所得类别分布概率。那么对于数据 x而言,其实际类别分布概率 y和模型预测类别分布概率 y ^ \hat{y} y^的交叉熵损失函数定义为:
c r o s s e n t r y y = − y × log ( y ^ ) cross entryy=-y\times\log(\hat{y}) crossentryy=−y×log(y^)
很显然,一个良好的神经网络要尽量保证对于每一个输入数据,神经网络所预测类别分布概率与实际类别分布概率之间的差距越小越好,即交叉熵越小越好。于是,可将交叉熵作为损失函数来训练神经网络。

图1 三类分类问题中输入x的交叉熵损失示意图(x 属于第一类)

在上面的例子中,假设所预测中间值 (z1,z2,z3)经过 Softmax映射后所得结果为 (0.34,0.46,0.20)。由于已知输入数据 x属于第一类,显然这个输出不理想而需要对模型参数进行优化。如果选择交叉熵损失函数来优化模型,则 (z1,z2,z3)这一层的偏导值为 (0.34−1,0.46,0.20)=(−0.66,0.46,0.20)。
可以看出, S o f t m a x Softmax Softmax和交叉熵损失函数相互结合,为偏导计算带来了极大便利。偏导计算使得损失误差从输出端向输入端传递,来对模型参数进行优化。在这里,交叉熵与Softmax函数结合在一起,因此也叫 S o f t m a x Softmax Softmax损失(Softmax with cross-entropy loss)。
2.均方差损失(Mean Square Error,MSE)
均方误差损失又称为二次损失、L2损失,常用于回归预测任务中。均方误差函数通过计算预测值和实际值之间距离(即误差)的平方来衡量模型优劣。即预测值和真实值越接近,两者的均方差就越小。
计算方式:假设有 n个训练数据 x i x_i xi,每个训练数据 x i x_i xi 的真实输出为 y i y_i yi,模型对 x i x_i xi的预测值为 y i ^ \hat{y_i} yi^。该模型在 n 个训练数据下所产生的均方误差损失可定义如下:
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE=\dfrac{1}{n}\sum\limits_{i=1}^n\left(y_i-\hat{y}_i\right)^2 MSE=n1i=1∑n(yi−y^i)2
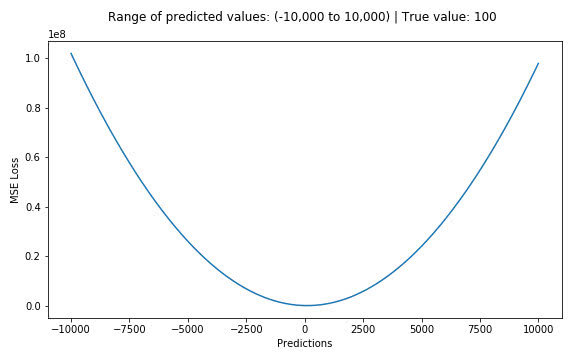
假设真实目标值为100,预测值在-10000到10000之间,我们绘制MSE函数曲线如 图1 所示。可以看到,当预测值越接近100时,MSE损失值越小。MSE损失的范围为0到∞。
3.CTC损失
3.1 CTC算法算法背景-----文字识别语音等序列问题
CTC 算法主要用来解决神经网络中标签和预测值无法对齐的情况,通常用于文字识别以及语音等序列学习领域。举例来说,在语音识别任务中,我们希望语音片段可以与对应的文本内容一一对应,这样才能方便我们后续的模型训练。但是对齐音频与文本是一件很困难的事,如 图1 所示,每个人的语速都不同,有人说话快,有人说话慢,我们很难按照时序信息将语音序列切分成一个个的字符片段。而手动对齐音频与字符又是一件非常耗时耗力的任务
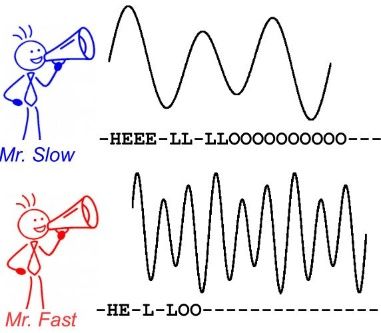
图1 语音识别任务中音频与文本无法对齐
在文本识别领域,由于字符间隔、图像变形等问题,相同的字符也会得到不同的预测结果,所以同样会会遇到标签和预测值无法对齐的情况。如 图2 所示。

图2 不同表现形式的相同字符示意图
总结来说,假设我们有个输入(如字幅图片或音频信号)X ,对应的输出是 Y,在序列学习领域,通常会碰到如下难点:
-
X和 Y都是变长的;
-
X和 Y的长度比也是变化的;
-
X和 Y相应的元素之间无法严格对齐。
3.2 算法概述
引入CTC主要就是要解决上述问题。这里以文本识别算法CRNN为例,分析CTC的计算方式及作用。CRNN中,整体流程如 图3 所示。

图3 CRNN整体流程
CRNN中,首先使用CNN提取图片特征,特征图的维度为 m × T m×T m×T,特征图 x可以定义为:
x = ( x 1 , x 2 , . . . , x T ) x=(x^1,x^2,...,x^T)\quad\text{} x=(x1,x2,...,xT)
然后,将特征图的每一列作为一个时间片送入LSTM中。令 t为代表时间维度的值,且满足 1 < t < T 1<t<T 1<t<T,则每个时间片可以表示为:
x t = ( x 1 t , x 2 t , … , x m t ) x^t=(x_1^t,x_2^t,\ldots,x_m^t) xt=(x1t,x2t,…,xmt)
经过LSTM的计算后,使用softmax获取概率矩阵 y,定义为:
y = ( y 1 , y 2 , … , y T ) y=(y^1,y^2,\ldots,y^T) y=(y1,y2,…,yT)
经过LSTM的计算后,使用softmax获取概率矩阵 y t y^t yt,定义为:
y t = ( y 1 t , y 2 t , … , y n t ) y^t=(y_1^t,y_2^t,\ldots,y_n^t) yt=(y1t,y2t,…,ynt)
n为字符字典的长度,由于 y i t y_i^t yit是概率,所以 Σ i y i t = 1 \Sigma_i y_i^t=1 Σiyit=1 。对每一列 y t y^t yt求 argmax(),就可以获取每个类别的概率。
考虑到文本区域中字符之间存在间隔,也就是有的位置是没有字符的,所以这里定义分隔符 −来表示当前列的对应位置在图像中没有出现字符。用 L L L代表原始的字符字典,则此时新的字符字典 L ′ L′ L′为:
L ′ = L ∪ { − } L'=L\cup\{-\} L′=L∪{−}
此时,就回到了我们上文提到的问题上了,由于字符间隔、图像变形等问题,相同的字符可能会得到不同的预测结果。在CTC算法中,定义了 B变换来解决这个问题。 B变换简单来说就是将模型的预测结果去掉分割符以及重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有分割符,则表示该字符出现多次),使得不同表现形式的相同字符得到统一的结果。如 图4 所示。

这里举几个简单的例子便于理解,这里令T为10:
B ( − s − t − a a t i v e ) = s t a t e B ( s s − t − a − t − e ) = s t a t e B ( s s t t − a a t − e ) = s t a t e \begin{array}{c}B(-s-t-aative)=state\\ \\ B(ss-t-a-t-e)=state\\ \\ B(sstt-aat-e)=state\end{array} B(−s−t−aative)=stateB(ss−t−a−t−e)=stateB(sstt−aat−e)=state
对于字符中间有分隔符的重复字符则不进行合并:
B ( − s − t − t s t a t e ) = s t a t e B(-s-t-t state)=state B(−s−t−tstate)=state
当获得LSTM输出后,进行 B变换就可以得到最终结果。由于 B变换并不是一对一的映射,例如上边的3个不同的字符都可以变换为state,所以在LSTM的输入为 x的前提下,CTC的输出为 l的概率应该为:
p ( l ∣ x ) = Σ π ∈ B − 1 ( l ) p ( π ∣ x ) p(l|x)=\Sigma_{\pi\in B^{-1}(l)}p(\pi|x) p(l∣x)=Σπ∈B−1(l)p(π∣x)
其中, p i pi pi为LSTM的输出向量, π ∈ B − 1 ( l ) \pi\in B^{-1}(l) π∈B−1(l)代表所有能通过 B变换得到 l的 p i pi pi的集合。
而对于任意一个 π,又有:
p ( π ∣ x ) = Π t = 1 T y π t t p(\pi|x)=\Pi_{t=1}^T y_{\pi_t}^t p(π∣x)=Πt=1Tyπtt
其中, y π t t y_{\pi_t}^t yπtt代表 t时刻 π为对应值的概率,这里举一个例子进行说明:
π = − s − t − a a t t t e y π t t = y − 1 ∗ y s 2 ∗ y − 3 ∗ y t 4 ∗ y − 5 ∗ y a 6 ∗ y a 7 ∗ y t 8 ∗ y t 9 ∗ y e 1 0 \begin{array}{c}\pi=-s-t-aattte\\ y_{\pi_t}^t=y_-^1*y_s^2*y_-^3*y_t^4*y_-^5*y_a^6*y_a^7*y_t^8*y_t^9*y_e^10\\ \end{array} π=−s−t−aattteyπtt=y−1∗ys2∗y−3∗yt4∗y−5∗ya6∗ya7∗yt8∗yt9∗ye10
不难理解,使用CTC进行模型训练,本质上就是希望调整参数,使得 p ( π ∣ x ) p(\pi\text{}|x) p(π∣x) 取最大。
具体的参数调整方法,可以阅读以下论文进行了解:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
4.平衡 L1损失(Balanced L1 Loss)—目标检测
目标检测(object detection)的损失函数可以看做是一个多任务的损失函数,分为分类损失和检测框回归损失:
L p , u , t u , v = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L_{p,u,tu,v}=L_{cls}(p,u)+\lambda[u\geq1]L_{loc}(t^u,v) Lp,u,tu,v=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
L c l s L_cls Lcls表示分类损失函数、 L l o c L_loc Lloc表示检测框回归损失函数。在分类损失函数中,p表示预测值,u表示真实值。 t u t_u tu表示类别u的位置回归结果,v是位置回归目标。λ用于调整多任务损失权重。定义损失大于等于1.0的样本为outliers(困难样本,hard samples),剩余样本为inliers(简单样本,easy sample)。
平衡上述损失的一个常用方法就是调整两个任务损失的权重,然而,回归目标是没有边界的,直接增加检测框回归损失的权重将使得模型对outliers更加敏感,这些hard samples产生过大的梯度,不利于训练。inliers相比outliers对整体的梯度贡献度较低,相比hard sample,平均每个easy sample对梯度的贡献为hard sample的30%,基于上述分析,提出了balanced L1 Loss(Lb)。
Balanced L1 Loss受Smooth L1损失的启发,Smooth L1损失通过设置一个拐点来分类inliers与outliers,并对outliers通过一个 m a x ( p , 1.0 ) max(p,1.0) max(p,1.0)进行梯度截断。相比smooth l1 loss,Balanced l1 loss能显著提升inliers点的梯度,进而使这些准确的点能够在训练中扮演更重要的角色。设置一个拐点区分outliers和inliers,对于那些outliers,将梯度固定为1,如下图所示:
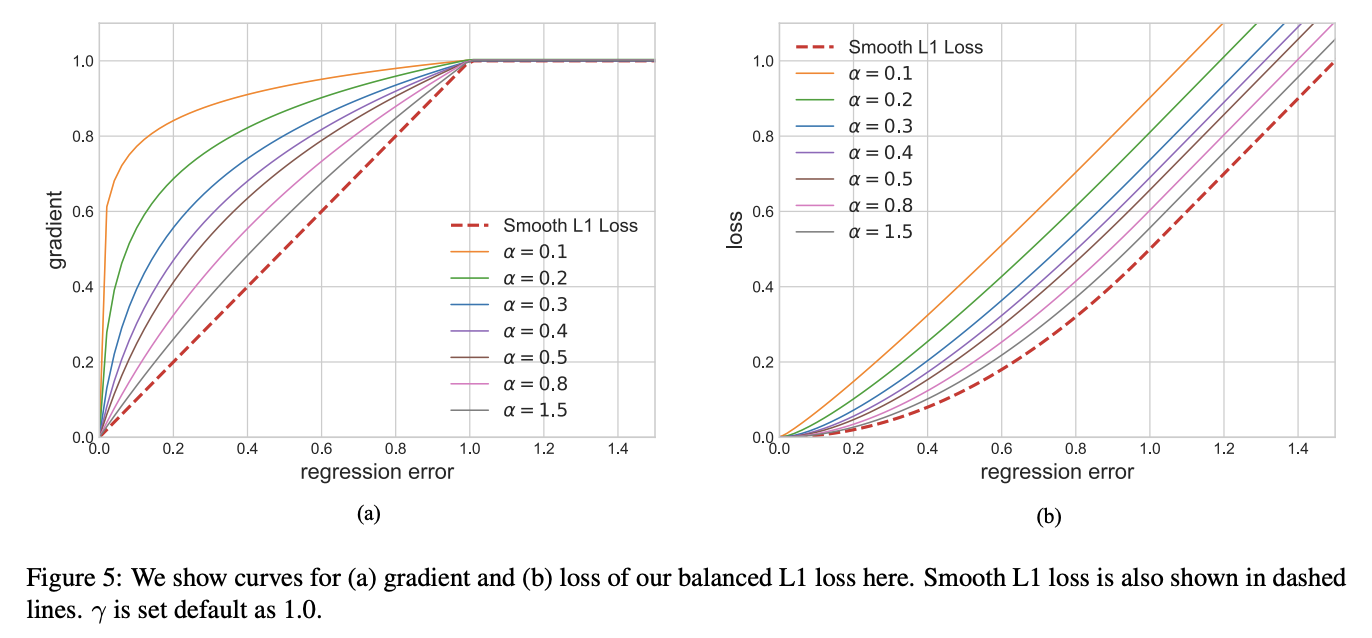
Balanced L1 Loss的核心思想是提升关键的回归梯度(来自inliers准确样本的梯度),进而平衡包含的样本及任务。从而可以在分类、整体定位及精确定位中实现更平衡的训练,Balanced L1 Loss的检测框回归损失如下:
L l o c = ∑ i ∈ x , y , w , h L b ( t i u − v i ) L_{loc}=\sum\limits_{i\in x,y,w,h}L_b(t_i^u-v_i) Lloc=i∈x,y,w,h∑Lb(tiu−vi)
其相应的梯度公示如下:
∂ L l o c ∂ w ∝ ∂ L b ∂ t i u ∝ ∂ L b ∂ x \dfrac{\partial L_{loc}}{\partial w}\propto\dfrac{\partial L_b}{\partial t_i^u}\propto\dfrac{\partial L_b}{\partial x} ∂w∂Lloc∝∂tiu∂Lb∝∂x∂Lb
基于上述公式,设计了一种推广的梯度公式为:
∂ L b ∂ x = { α l n ( b ∣ x ∣ + 1 ) , i f ∣ x ∣ < 1 γ , o t h e r w i s e \dfrac{\partial L_b}{\partial x}=\begin{cases}\alpha ln(b|x|+1),if|x|<1\\ \gamma,otherwise\end{cases} ∂x∂Lb={αln(b∣x∣+1),if∣x∣<1γ,otherwise
其中, α α α控制着inliers梯度的提升;一个较小的α会提升inliers的梯度同时不影响outliers的值。 γ γ γ来调整回归误差的上界,能够使得不同任务间更加平衡。α,γ从样本和任务层面控制平衡,通过调整这两个参数,从而达到更加平衡的训练。Balanced L1 Loss公式如下:
L b ( x ) = { a b ( b ∣ x ∣ + 1 ) l n ( b ∣ x ∣ + 1 ) − α ∣ x ∣ , i f ∣ x ∣ < 1 γ ∣ x ∣ + C , o t h e r w i s e L_b(x)=\begin{cases}\frac ab(b|x|+1)ln(b|x|+1)-\alpha|x|,if|x|<1\\ \gamma|x|+C,otherwise\end{cases} Lb(x)={ba(b∣x∣+1)ln(b∣x∣+1)−α∣x∣,if∣x∣<1γ∣x∣+C,otherwise
其中参数满足下述条件:
α l n ( b ∣ x ∣ + 1 ) = γ \alpha ln(b|x|+1)=\gamma\quad\text{} αln(b∣x∣+1)=γ
默认参数设置:α = 0.5,γ=1.5
Libra R-CNN: Towards Balanced Learning for Object Detection
|x|<1\ \gamma|x|+C,otherwise\end{cases}$
其中参数满足下述条件:
α l n ( b ∣ x ∣ + 1 ) = γ \alpha ln(b|x|+1)=\gamma\quad\text{} αln(b∣x∣+1)=γ
默认参数设置:α = 0.5,γ=1.5















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











