







 今天我就来讲讲有关于CUDA的编程模型:
今天我就来讲讲有关于CUDA的编程模型:
1.主机和设备
CUDA 编程模型将CPU作为主机(Host),GPU作为协处理器或者设备(Device),在一个系统中可以存在一个主机和若干个设备。
在这个模型中,CPU与CPU协同工作,各司其职。CPU负责进行逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU、GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。
一旦确定了程序的并行部分,就可以考虑把这部分计算工作交给GPU。
能够使用GPU计算的程序必须具有以下特点:需要处理的数据量比较大,数据以数组或矩阵形式有序存储,并且对这些数据要进行的处理方式基本相同,各个数据之间的依赖性或者说耦合很小,需要复杂数据结构的计算如树,图等,则不适用于使用GPU进行计算。找到程序中满足这些要求的部分后,就能将该部分程序移植GPU上。运行在GPU上的程序被称为内核(Kernel)。内核并不是完整的程序,只是整个程序中的一个可以使用数据并行处理的步骤。一个完整的程序由若干个内核函数以及CPU上的串行处理共同组成。一个完整的程序的计算流程如下所示:

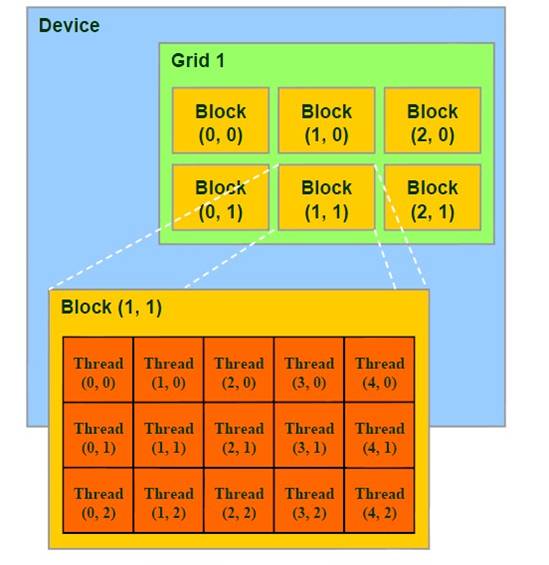
2. 线程结构
内核以线程网格(Grid)的形式组织,每个线程网格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。实质上,内核(kernel)是以block为单位执行的,CUDA引入grid只是用来表示一系列可以被并行执行的block的集合,各block的集合。各block是并行执行的,block间无法通信,也没有执行顺序。
目前一个内核(kernel)函数中只有一个grid,而未来的支持DX11的硬件采用MIMD(多指令多数据)结构,允许一个kernel中存在多个不同的grid。(目前是使用SIMT(单指令多线程)。
为简便起见,threadIdx是一个有3个组件的向量,所以线程可以使用一维,二维,三维索引标识,形成一维,二维,三维的线程块。这提供了一种自然的方式来调用作用在域内元素上的计算,如向量,矩阵,体元(volume)(译者注:目前还没见过使用三维的,原因可能在于网格不支持三维)。
线程索引和线程ID直接相关:对于一维的块,它们相同;对于二维长度为(Dx,Dy)的块,线程索引为(x,y)的线程ID是(x+yDx);对于三维长度为(Dx,Dy,Dz)的块,索引为(x,y,z)的线程ID为(x+yDx+zDxDy)
实例代码:

















 2615
2615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









