






引言:本文介绍了ProtoOcc,一种新颖的3D占用预测模型,旨在通过深度语义理解场景来预测3D体素的占用状态和语义类别。ProtoOcc在Occ3D-nuScenes基准测试中达到了45.02%的mIoU。针对单帧方法,它达到了39.56%的mIoU,超过了所有现有单帧方法,并且在NVIDIA RTX 3090上达到了12.83 FPS的推理速度。
©️【深蓝AI】编译
论文标题:ProtoOcc: Accurate, Efficient 3D Occupancy Prediction Using Dual Branch Encoder-Prototype Query Decoder
论文作者:Jungho Kim, Changwon Kang, Dongyoung Lee, Sehwan Choi, Jun Won Choi
论文链接:https://arxiv.org/abs/2412.08774
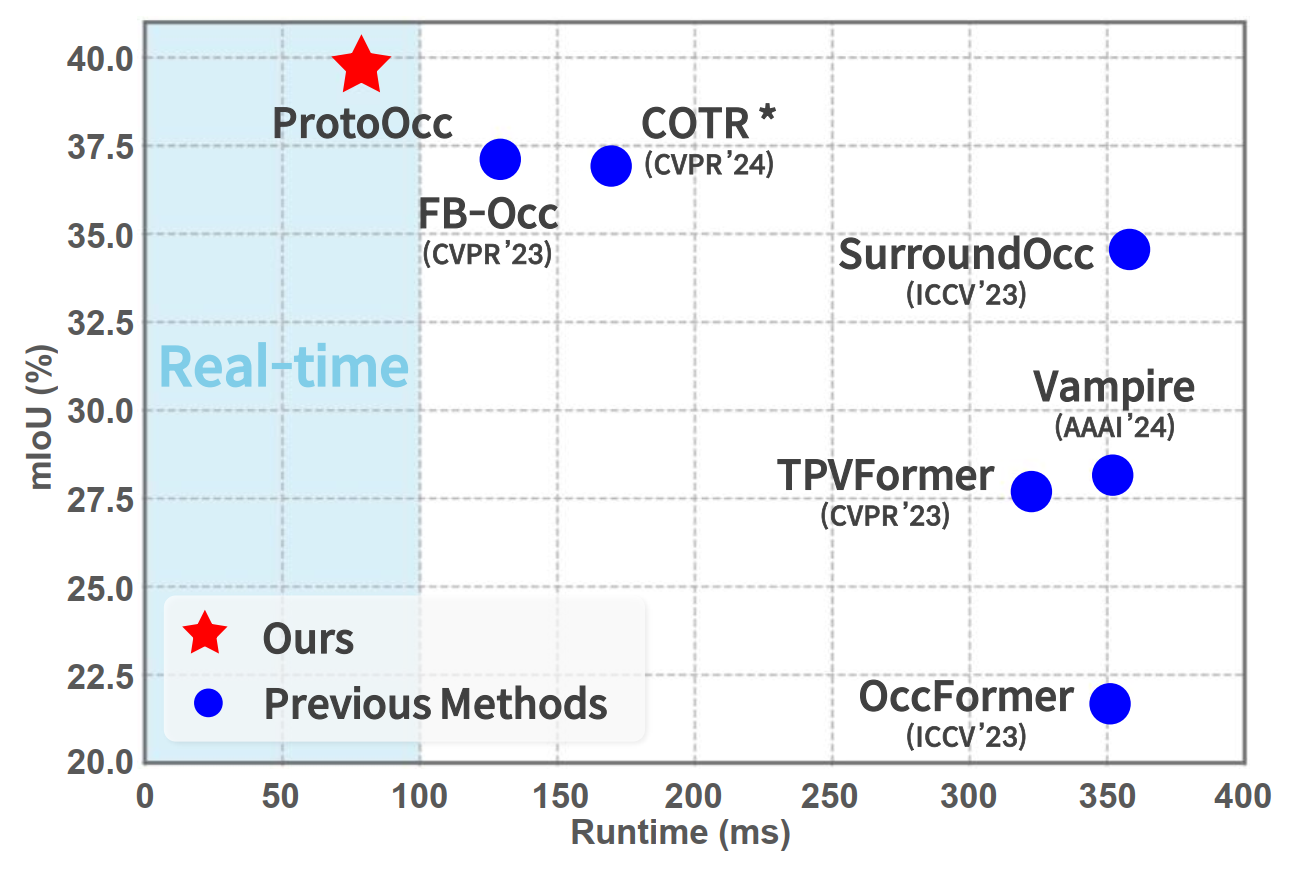
▲图1. 在Occ3D-nuScenes验证集上mIoU和运行时间的比较。©️【深蓝AI】编译
1. 问题引入
基于视觉的3D占用预测是自动驾驶中车辆自身周围场景全面理解的关键任务。该任务旨在同时使用3D空间中的多视图图像估计占用状态和语义类别,提供详细的3D场景信息。
以前的典型预测流程包括三个主要部分:1)视图转换模块,2)编码器,3)解码器。最初,从多视图图像中提取的特征图通过2D到3D视图转换转换为3D空间表示。然后编码器网络处理这些3D表示以产生高级语义空间特征,捕获整体场景上下文。最后,解码器网络使用这些编码的3D空间特征来预测组成场景的所有体素的语义占用。
现有工作已经探索了增强编码器-解码器网络以提高3D占用预测的准确性和计算效率。各种尝试已经通过优化编码器来使用3D空间表示。图2(a)展示了两种常用的3D表示,包括体素表示和鸟瞰视图(BEV)表示。基于体素的编码方法利用3D卷积神经网络(CNN)来编码体素结构。然而,由于需要大量体素来覆盖3D环境,这种方法需要显著的内存和计算资源。减少这种复杂性的一种方法是通过减少3D CNN的容量,但这会以减少感受野为代价,这可能会限制整体性能。
相比之下,BEV表示将3D信息投影到2D平面上,与体素表示相比大大减少了内存和计算需求。在使用2D CNN编码BEV表示后,它被转换回3D体素结构以进行3D占用预测。然而,这种方法由于减少了高度维度,缺乏详细的3D几何信息。虽然可以通过整合额外的3D信息来改进BEV表示,但其性能仍然受到将3D场景表示为2D格式的固有限制。另一系列研究集中在增强解码器上。
如图2(b)所示,主要存在两种解码策略:1)基于CNN的解码器和2)基于查询的解码器。基于CNN的解码器使用轻量级3D CNN提取语义体素特征,而基于查询的解码器迭代地使用从编码器获得的3D表示来解码查询。尽管基于查询的解码器可以实现更好的预测精度,但它们需要通过多个解码层处理,导致计算复杂度更高和推理时间增加。因此,在保持查询基解码器的性能优势的同时减少这种复杂度至关重要。
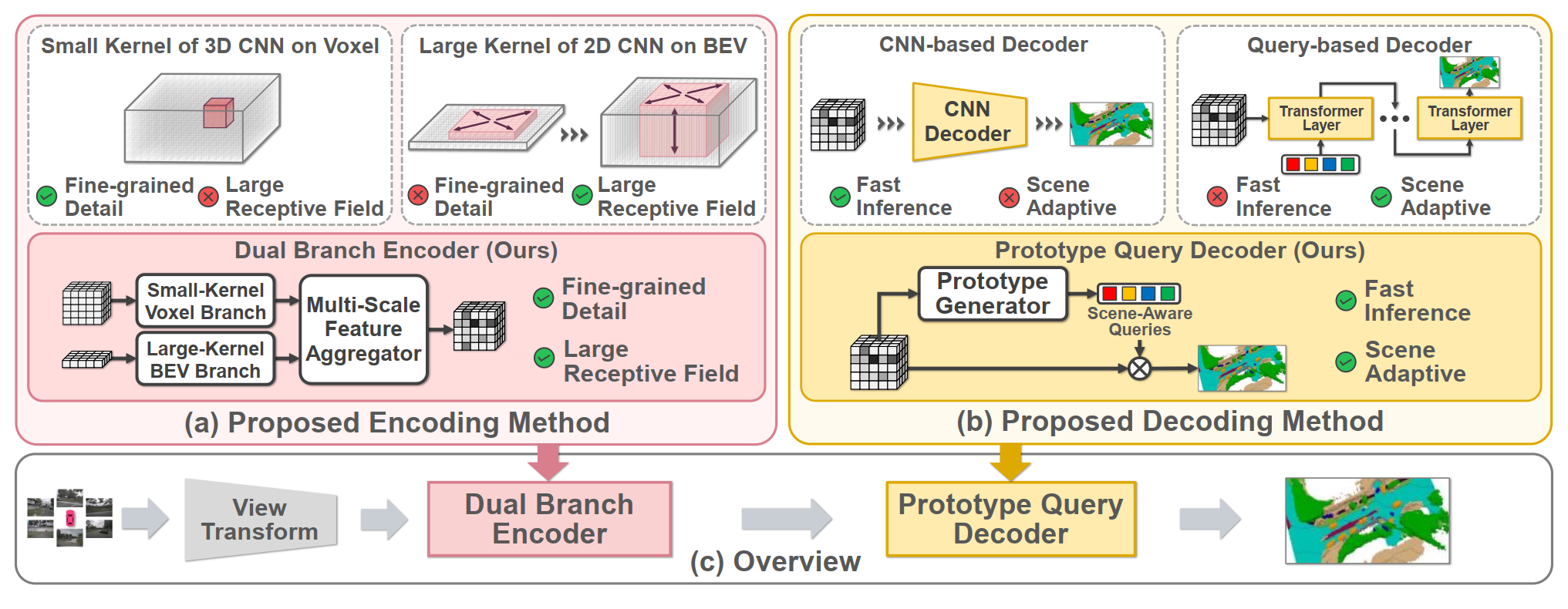
▲图2. ProtoOcc的整体结构。©️【深蓝AI】编译
2.方法提出
为了解决上述挑战,作者入了ProtoOcc,这是一个高效的编码器-解码器框架,用于3D占用预测网络。如图1所示,ProtoOcc在单个NVIDIA RTX 3090 GPU上实现了77.9毫秒的相对快速推理,达到了最先进的性能。
如图2(a)所示,ProtoOCC利用具有双分支架构的双分支编码器(DBE)。体素分支使用小核大小的3D CNN生成体素特征,而BEV分支使用大核大小的2D CNN产生BEV特征。BEV和体素特征在多尺度上融合,产生综合体素特征。这种设计减少了与3D CNN相关的复杂性,同时有效地以较低的计算成本增加了感受野。此外,这种双编码方法有效地捕获了细粒度的3D结构和不同尺度上的长距离空间关系。
考虑到基于查询的解码由于需要在多个解码层上处理而需要高计算复杂度,作者引入了原型查询解码器(PQD)来加速解码过程。PQD通过使用基于原型的查询直接产生预测结果,消除了迭代解码的需求。为此,可以从输入样本的综合体素特征中生成场景自适应原型。虽然可以为输入中存在的语义类别计算原型,但当某些语义类别缺失时会出现挑战。为了解决这个问题,作者还设计了与场景无关的原型,这些原型是通过在训练阶段使用指数移动平均(EMA)方法过滤场景自适应原型获得的。PQD然后将场景自适应原型与场景无关原型合并以形成场景感知查询。
作者还开发了一种新颖的训练方法来增强所提出的解码器的性能。由于原型直接用于3D占用预测而没有迭代查询解码,原型的质量显著影响整体性能。为了确保鲁棒预测,作者设计了鲁棒原型学习框架,在原型生成过程中注入噪声,并在训练阶段训练模型以抵消这种噪声。
3. ProtoOcc
3.1. 概述
ProtoOcc的整体架构如图2(c)所示。首先,2D到3D视图转换从多视图相机图像中生成3D体素和BEV特征。DBE然后结合这些特征在多尺度上产生综合体素特征。接下来,PQD从当前场景计算场景感知原型。它使用场景自适应和场景无关原型初始化查询,并执行查询与综合体素特征之间的点积操作以预测3D占用。
2D到3D视图转换。2D到3D视图转换过程采用Lift-Splat-Shoot(LSS)方法将多视图相机输入转换为体素和BEV格式的3D特征。使用例如ResNet的骨干网络从多视图图像中提取2D特征图。然后这些特征被送入深度网络以预测深度分布。通过计算2D特征图和深度分布的外积生成锥形特征。体素池方法将这些锥形特征转换为统一的3D体素特征。最后,BEV特征
从
沿通道维度重塑,从
变为
,其中D表示通道维度,
表示体积尺度。
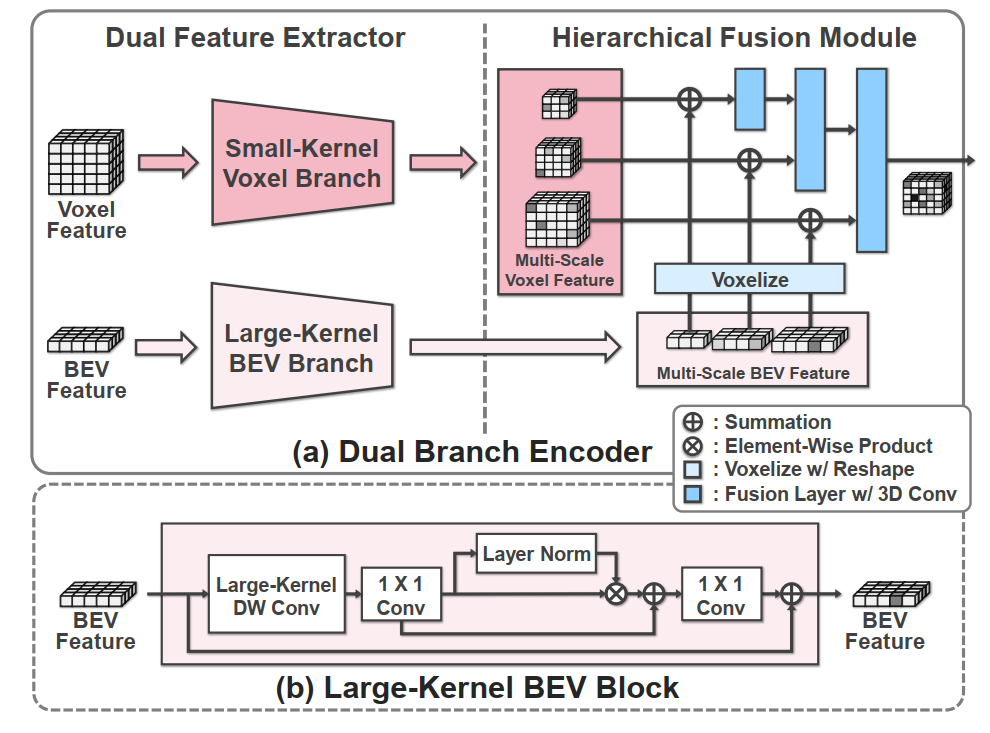
▲图3:双分支编码器的详细结构。©️【深蓝AI】编译
3.2. 双分支编码器
DBE的整体架构如图3(a)所示。DBE由两个主要组件组成:双特征提取器(DFE)和层级融合模块(HFM)。DFE提取多尺度双特征,以捕获体素和BEV域中的细粒度3D结构和长距离空间关系。HFM层次聚合多尺度双特征,以生成不同细节级别的综合上下文特征。
双特征提取器。DFE由使用小核大小的3D CNN的体素分支和使用大核大小的2D CNN的BEV分支组成,每个分支旨在提取多尺度特征。在此双分支框架中,2D表示通过沿通道维度重塑
得到,从而整合3D信息。DFE通过增加BEV域中2D CNN的核大小来扩展3D感受野,减少与3D CNN相关的复杂性,同时以较低的计算成本实现扩展。表1通过展示在3D卷积中扩大核尺寸会大幅增加计算成本,而在2D卷积中只会导致微小的延迟增加,从而证明了这种方法的显著计算效率。
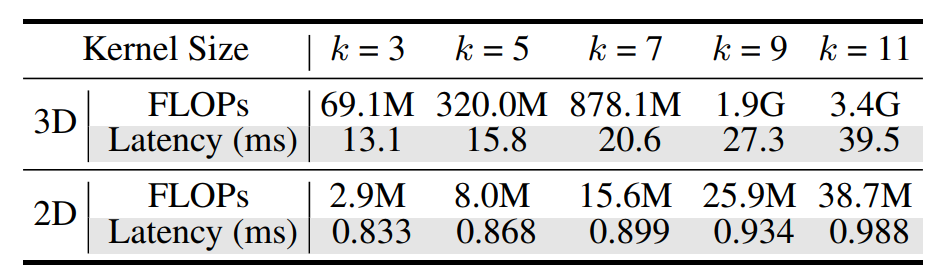
▲表1:不同核尺寸的2D和3D卷积的比较。©️【深蓝AI】编译
为了为每个域提取多尺度特征,通过基于小核3D CNN的下采样层进行处理,得到
,其中i表示尺度索引,S表示尺度总数。同时,多尺度BEV特征
以类似的方式从
中提取。关键区别在于使用大核(见图3(b))的2D CNN来考虑长距离依赖关系,灵感来自ConvNeXt。
层级融合模块。HFM在多尺度上整合体素和BEV信息,利用两种表示的优势生成综合体素特征。多尺度双特征通过一系列上采样层的顺序处理,然后通过3D CNN进行聚合。在每一层中,BEV特征在第i尺度通过重塑操作体素化为
。随后,融合的体素特征
通过聚合体素特征
,体素化的BEV特征
以及从前一层的上采样融合体素特征
得出,如下所示:
其中Up表示通过三线性插值的上采样层,Conv表示小核尺寸的3D卷积层。经过S个上采样层的处理后,DBE最终得到综合体素特征。
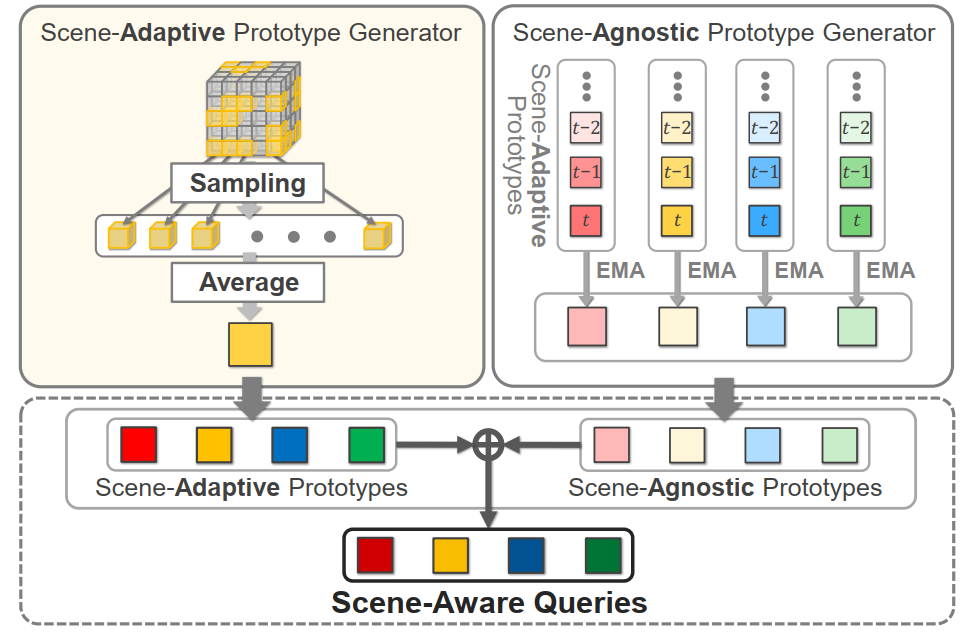
▲图4. 原型生成的细节。©️【深蓝AI】编译
3.3. 原型查询解码器
如图4所示,PQD包括两个组件:场景自适应原型生成器(AdaPG)和场景无关原型生成器(AgnoPG)。AdaPG生成场景自适应原型,以捕获当前场景中每个类别的独特特征。AgnoPG通过EMA方法产生场景无关原型,代表不同场景中所有单个类别的泛化特征。最后,PQD通过在综合体素特征和由AdaPG和AgnoPG生成的原型产生的查询之间执行点积操作来预测所有体素的语义占用。
场景自适应原型生成器。AdaPG生成场景自适应原型,以捕获当前场景中每个类别的独特语义。具体来说,AdaPG使用浅层3D CNN分类器产生体素级类别概率,其中C表示语义类别的数量,包括空类别。然后使用
生成类别特定掩码
,通过将每个体素分配给概率最高的类别。这些类别特定掩码用于为每个类别采样体素特征,如下所示:
然后场景自适应原型通过在x、y和z域中的平均池化计算得出:
其中表示
中非零体素的数量,
表示逐元素乘积。如果
为零,则原型
初始化为零向量。随后,得到的
在AgnoPG和查询生成中使用。
场景无关原型生成器。尽管AdaPG有效地捕获了输入样本中的类别特定特征,但它存在潜在的遗漏某些类别的限制。为了解决这个问题,AgnoPG通过EMA方法利用产生场景无关原型
。这个过程旨在捕获所有单个类别的一致和泛化特征,即使是当前样本中不存在的类别。
逐渐通过整合来自多个样本的
更新,重点关注每个样本中存在的类别。因此,
如下所示:
其中t表示当前训练迭代,α是EMA系数。
原型驱动占用预测。PQD通过求和和
,然后通过MLP处理,生成场景感知查询
。这些查询提供了捕获独特和一致类别属性的综合特征。然后使用得到的
来预测语义 logit。随后,占用掩码通过在综合体素特征和
之间沿通道维度执行点积操作获得,并对掩码应用sigmoid函数进行归一化。最终的3D语义占用预测是通过利用占用掩码和语义 logits计算得出的。这种方法通过生成由综合体素特征派生的查询,消除了迭代解码的需求。由原型生成的查询直接而有效地在单步中预测语义占用。
3.4. 训练
鲁棒原型学习。ProtoOcc使用AdaPG中的类别特定掩码生成场景自适应原型
。当使用不准确的掩码对每个类别的体素特征进行平均池化时,会包含实际上属于不同类别的体素的特征。这阻止了原型准确代表每个类别的独特特征,降低了预测精度。为了解决这个问题,作者引入了鲁棒原型学习(RPL),RPL向
添加噪声以生成噪声场景自适应原型
,这些原型与
结合产生噪声场景感知查询
。这些查询与
连接,然后独立预测体素占用和类别。这个过程训练模型去噪
,使模型即使在
不准确时也能进行鲁棒的占用预测。这种方法在训练阶段应用,增强了模型的能力,不影响推理时间。为了增强3D场景理解的鲁棒性,作者引入了两种类型的噪声,缩放噪声和随机翻转噪声。缩放噪声根据车辆自身的位置调整
的大小,解决深度歧义问题。随机翻转噪声随机重新分配体素网格类别,减轻了类似类别(如拖车和卡车)的误分类问题。
训练损失。用于训练ProtoOcc的总损失由下式给出:
其中用于深度估计,
用于AdaPG中类别特定掩码预测,
用于基于查询的占用预测,
用于RPL中的
。具体来说,
使用激光雷达点云投影到图像上,采用交叉熵损失。
包括Lovasz和Dice损失,用于AdaPG中用于场景自适应原型生成的类别特定掩码预测。
在没有二分图匹配过程的情况下计算,查询数量等于类别数量。这个损失使用分类的CE损失和与Dice损失结合的焦点损失来预测掩码。
对RPL中的
使用与
相同的函数。
4. 实验
Occ-3D nuScenes上的基准测试表明,ProtoOcc的mIoU为39.56%,超过了所有现有单帧方法的性能,同时在NVIDIA RTX 3090上以12.83 FPS的速度运行。ProtoOcc与多帧时间融合也达到了以前多帧方法中的最佳性能,mIoU为45.02%。
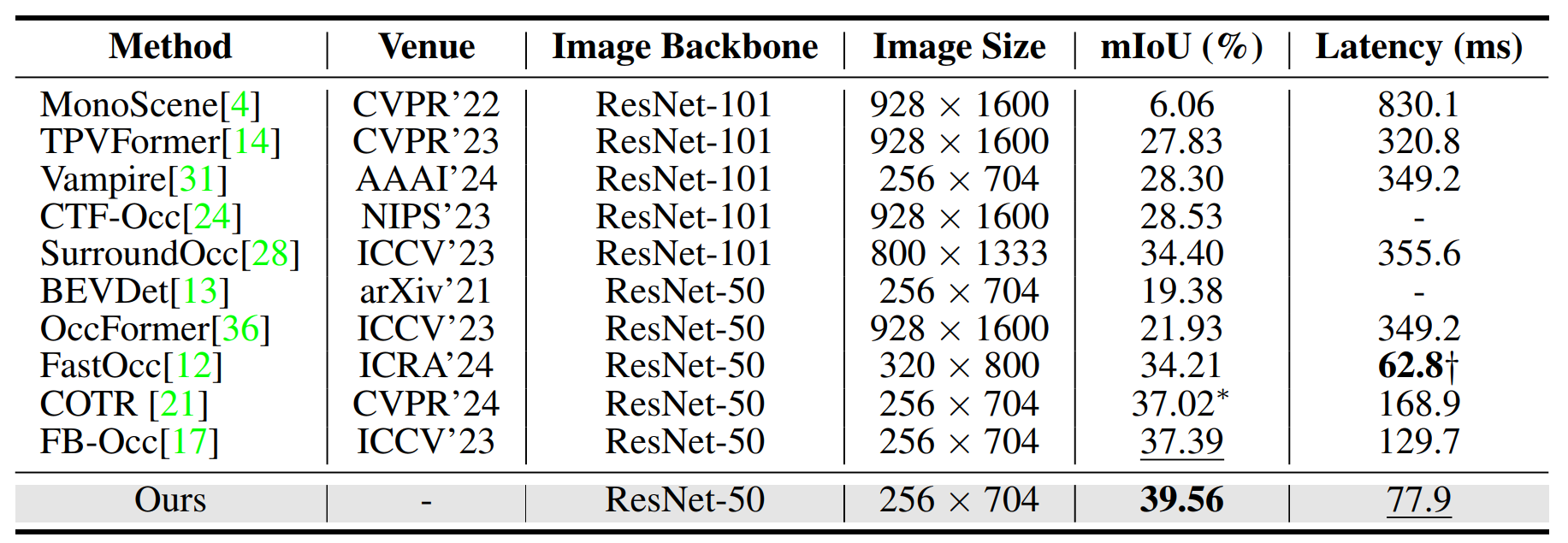
▲表2: 在Occ3D-nuScenes验证集上与单帧方法的比较。©️【深蓝AI】编译

▲表3: 在Occ3D-nuScenes验证集上与多帧方法的比较。©️【深蓝AI】编译
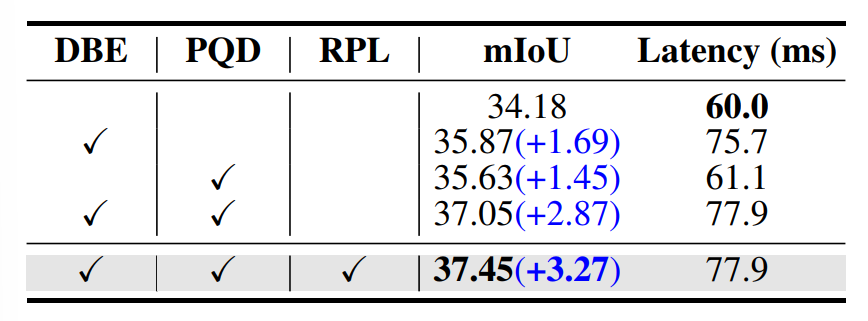
▲表4: ProtoOcc主要组件的消融研究。©️【深蓝AI】编译
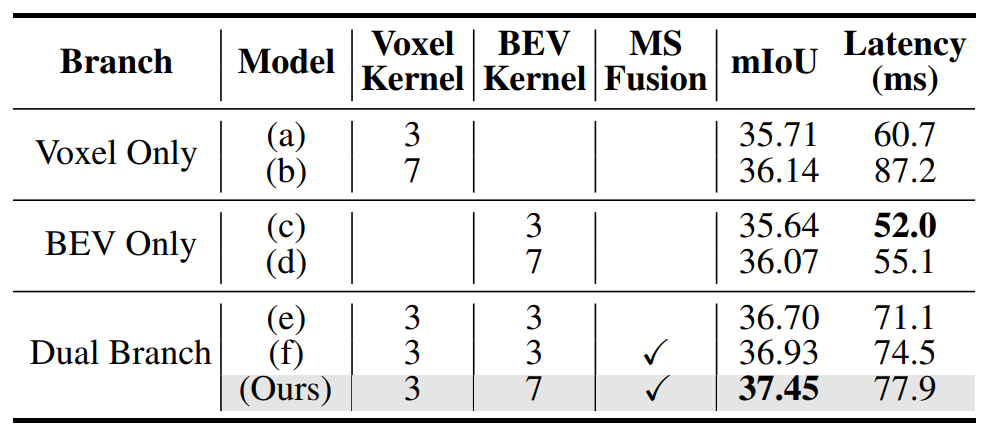
▲表5: 双分支架构的消融研究。©️【深蓝AI】编译

▲表6: 解码器类型的消融研究。©️【深蓝AI】编译
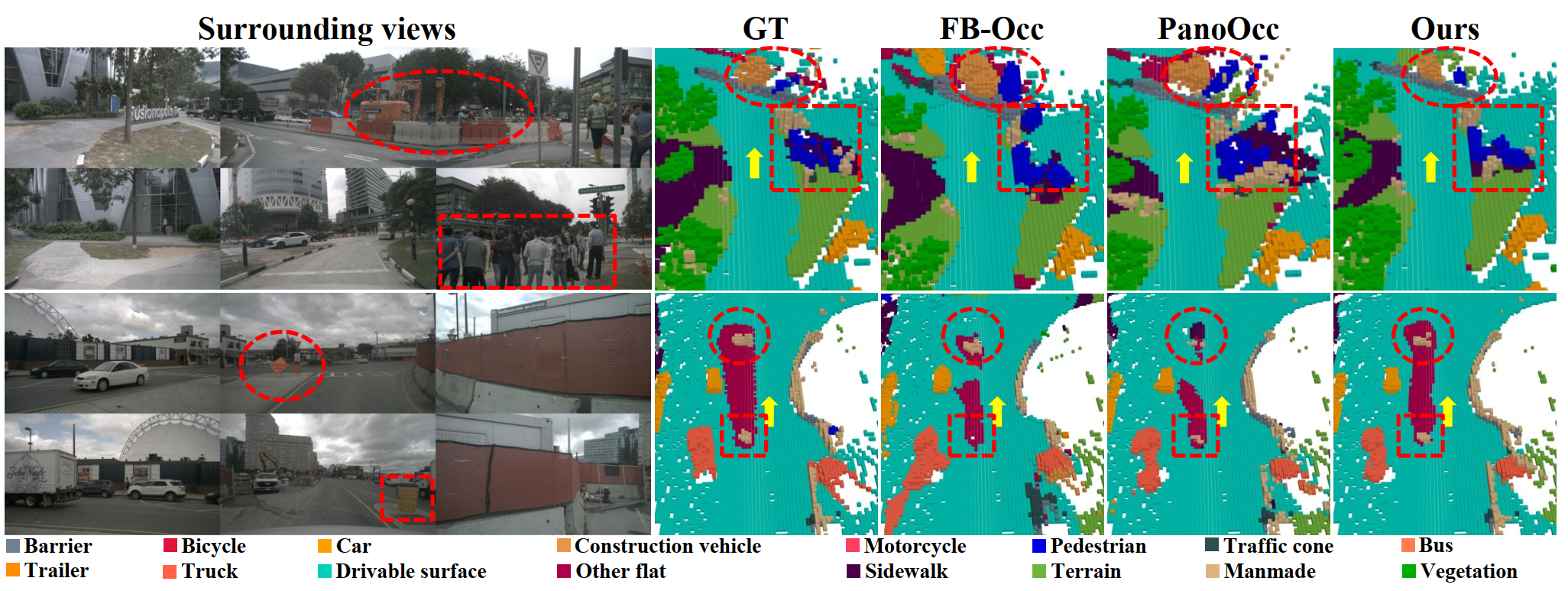
▲图5: 在nuScenes验证集上的定性结果。©️【深蓝AI】编译
总结
本文介绍了一个名为ProtoOcc的高效的编码器-解码器框架,用于3D占用预测。DBE(双分支编码器)通过结合体素和BEV(鸟瞰视图)表示,并捕获细粒度的交互作用,同时有效地模拟长距离空间关系,从而增强了编码器的性能。随后,PQD(原型查询解码器)利用场景自适应和场景无关原型作为查询,消除了迭代解码过程的需要,显著降低了计算复杂性。另外,本文还介绍了RPL(鲁棒原型学习)来提高模型对原型不准确性的鲁棒性。ProtoOcc方法在Occ3D-nuScenes基准测试中实现了最先进的性能,同时显著提高了推理速度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









