






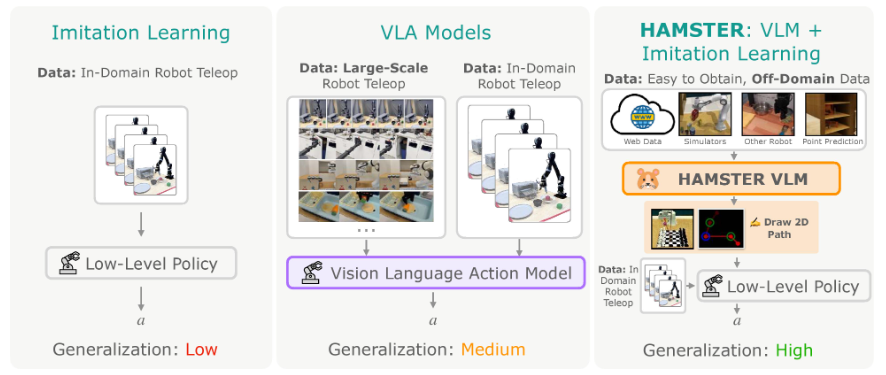
导读
当人类可以轻松看懂说明书组装家具时,机器人却常因场景变化陷入"人工智障"的窘境。传统机器人学习依赖海量真实操作数据,而获取这些数据就像让新手司机直接上高速练车——既危险又昂贵。来自NVIDIA的研究团队近日提出突破性解决方案:他们开发的分层式"视觉-语言-动作"模型,让机器人首次实现了像人类般"手脑协同"的跨领域学习能力。
这项研究的精妙之处在于"分工协作"的设计理念。高层模型化身"决策指挥官",通过观看普通视频就能规划出任务路径;底层模型则担任"执行专家",专注将二维路径转化为精准的三维动作。这种分层架构既突破了传统模型对专业数据的依赖,又能让机器人适应不同外观、机械结构甚至任务定义的巨大差异。实验显示,新方法在七大类现实场景中的成功率较现有最佳模型提升50%,当遇到从未见过的机械臂时,成功率竟能保持原有水平的80%。这项突破为机器人进入开放世界提供了关键钥匙,或许未来某天,看几段教学视频就能学会新技能的机器人管家,将真正走进千家万户。
©️【深蓝AI】编译
本文由paper一作——Yi Li授权【深蓝AI】编译发布!
论文标题:HAMSTER: HIERARCHICAL ACTION MODELS FOR OPEN-WORLD ROBOT MANIPULATION
论文作者:Yi Li、Yuquan Deng、Jesse Zhang、Joel Jang、Marius Memmel、Raymond Yu、Caelan Garrett、Fabio Ramos、Dieter Fox、Anqi Li、Abhishek Gupta、Ankit Goyal
论文地址:https://arxiv.org/abs/2502.05485
项目链接:https://hamster-robot.github.io/
▲图1| 该架构能够在经过容易收集的各种数据训练后,实现具有语义、视觉和几何泛化能力的机器人操作,这是非常具有优势的,因为这些模型几乎不需要特定领域的机器人数据,意味着“天下武功皆为我所用”。©️【深蓝AI】编译
01 引入
该研究探讨了如何将大规模视觉-语言模型(VLMs)的泛化能力与小型策略模型的效率、局部鲁棒性和灵巧性相结合。以往的研究中,单体视觉-语言-动作(VLA)模型通过微调现成的预训练VLMs来直接生成机器人动作。这些模型关键依赖于大型机器人数据集,其中包括机器人观察数据(如图像、本体状态)和动作。然而,收集机器人数据非常昂贵,因为端到端的观察-动作对通常需要通过遥操作等方式在机器人硬件上收集。尽管社区在构建大规模机器人数据集方面进行了广泛的努力,但现有的数据集的规模、质量和多样性仍然有限,且单体VLA模型尚未展现出与VLMs和LLMs在其他领域研究中相当的突现能力。除此之外,单体VLA模型在执行灵巧和动态的操作任务时,受限于推理频率,也面临困难。
另一方面,较小的机器人策略模型已展示出显著的灵巧性和鲁棒性。这些模型在多种复杂任务中表现优秀,特别是在涉及接触丰富的操作和三维推理任务中,涵盖了从桌面操作到精细灵巧操作的各个领域。虽然这些模型通常使用相对较小的数据集训练,但它们能表现出较强的局部鲁棒性,并且能够实现灵巧和高精度控制。然而,它们对环境的剧烈变化或任务的语义描述变化较为脆弱,也可能在有效利用模拟数据进行现实操作任务时遇到困难,原因在于从模拟到现实的视觉外观和系统动态之间存在差距。
该研究提出,通过微调大规模VLMs,生成中间表示作为高层次指导来解决机器人操作任务,而不是直接预测机器人动作。低层次的策略模型可以基于这些中间表示生成动作,减少低层次策略模型在长时间规划和复杂语义推理中的负担。更进一步,如果选择的中间表示具有易于从图像序列中获得、与具身性无关且对细微动态变化具有鲁棒性等特点,则VLM可以通过离域数据进行微调,而无需依赖机器人动作数据。离域数据包括没有动作的免费视频数据、模拟数据、人类视频以及不同具身体型的机器人视频,这些数据通常更容易收集,并且在现有数据集中可能已经非常丰富。
该研究提出了一个分层架构的VLA模型——HAMSTER(分层动作模型与分离路径表示),其中,大型微调的VLM通过2D路径表示与低层次的策略模型连接。2D路径是机器人物体末端执行器的2D图像平面位置的粗略轨迹,以及抓取状态变化的位置信息(例如开闭状态)。这些2D路径可以通过从无动作视频或物理模拟中自动获取,利用点跟踪、手工描绘或本体投影等方法。这样的设计使得HAMSTER能够有效利用这些丰富且廉价的离域数据进行高层VLM的微调。HAMSTER的分层设计还通过解耦VLM训练和低层次动作预测,提供了额外的优势。具体来说,尽管高层VLM通过单目RGB摄像头输入预测语义轨迹,但低层策略模型可以操作更丰富的三维和本体输入。通过这种方式,HAMSTER结合了VLM的语义推理优势和三维策略模型的三维推理及空间意识优势。
在实验中,HAMSTER在七个不同泛化轴上的成功率平均提高了20%,相对增益达到50%。由于HAMSTER基于开源VLM和低层策略模型构建,它可以作为完全开源的工具,促进社区构建视觉-语言-动作模型。与其他提出分层VLA模型的研究不同,该研究提出的独特见解是,通过这种分层分解,模型能够利用丰富的离域数据来提升现实世界的控制能力。这为使用更廉价且更丰富的数据源训练大型视觉-语言-动作模型开辟了新的途径。
02 具体方法与实现
该研究提出了一种分层的视觉-语言-动作(VLA)模型架构——HAMSTER(Hierarchical Action Models with Separated Path Representations),旨在实现跨领域的转移能力,而不是仅仅依赖于昂贵的机器人收集的观察-语言-动作数据。HAMSTER展现了广泛的可泛化性和鲁棒性,能够有效进行机器人操作。该架构由两个互相连接的模型组成:首先是高层视觉-语言模型(VLM),该模型经过大规模的离域数据微调,用于生成中间的2D路径指导;其次是低层策略模型,该模型基于2D路径生成动作。通过这种分层的VLA模型,相较于直接生成动作的单体模型,具有以下三大优势:
1)分层VLM可以利用离域数据集中的精确动作数据缺失(如模拟数据和视频);
2)实验表明,生成2D路径的分层VLM比单体VLA模型在跨领域泛化方面表现更为有效;
3)分层设计提供了更多的感知模态灵活性,并允许异步查询大规模高层VLA模型和小规模低层策略模型。
▲图2| 全文方法总览©️【深蓝AI】编译
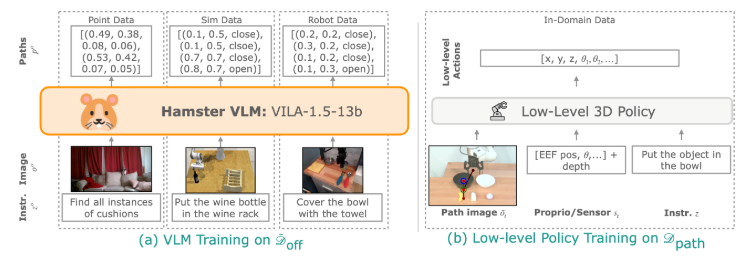
2.1. HAMSTER的高层VLM用于从离域数据中生成2D路径
HAMSTER的高层VLM预测一个粗略的2D路径p,以在给定的单目RGB图像和语言指令下完成任务。2D路径p描述了机器人末端执行器(或在人的视频中为人手)在输入图像上的粗略轨迹,同时包含抓取器状态信息。形式上,2D路径主要包括末端执行器(或手)在时间步t的位置的标准化像素坐标,并用一个二值值来表示抓取器状态(开或关),将多个时间t上的位置坐标进行连续化捕获即可获得连续的2D路径。
虽然任何预训练的文本和图像输入的VLM都可以用于预测这样的2D路径,但预训练的VLMs在零样本预测这种路径时表现较差。因此,研究人员通过在离域数据集上微调预训练的VLMs,以生成路径预测。该离域数据包括互联网视觉问答数据、来自其他模态的机器人数据和模拟数据。这与某些研究不同,在这些研究中,预训练的VLM被要求直接进行空间相关路径生成。
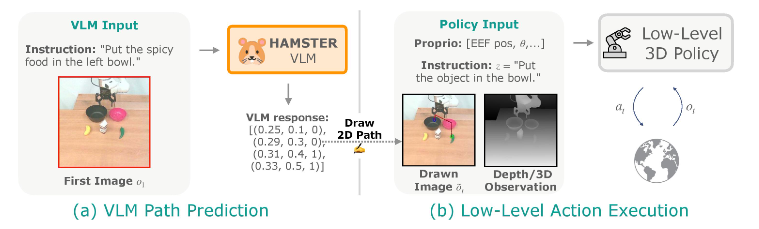 ▲图3| 在推理阶段,作者使用视觉语言模型(VLM)根据文本指令预测第一个观察结果 o1 的路径。这些路径会被绘制在策略所看到的所有图像上,然后它会执行低级环境动作。©️【深蓝AI】编译
▲图3| 在推理阶段,作者使用视觉语言模型(VLM)根据文本指令预测第一个观察结果 o1 的路径。这些路径会被绘制在策略所看到的所有图像上,然后它会执行低级环境动作。©️【深蓝AI】编译
2.2. 微调目标与数据集
预测末端执行器的2D路径需要理解任务中需要操作的物体的像素位置,并推理机器人如何执行任务。为此,研究人员汇总了一个多样的离域数据集Doff,涵盖了来自不同模态的数据,包括真实世界数据、视觉问答数据和模拟数据。重要的是,这些用于训练VLM的离域数据并未来自部署环境,从而强调了模型的可泛化性。
离域数据集Doff由以下三种类型的数据组成:
1)像素点预测任务(什么);
2)模拟机器人任务(什么和如何);
3)真实机器人数据集,包括轨迹(什么和如何)。
每种数据集的详细情况如下所述,并且附带了每种数据集的可视化示例。
像素点预测:使用RoboPoint数据集,通过770k个像素点预测任务,答案大多以2D点列表的形式表示,代表图像上的位置。示例包括任务提示“定位标记物之间的物体”,输入图像以及答案如[(0.25, 0.11), (0.22, 0.19), (0.53, 0.23)]。
模拟机器人数据:使用RLBench生成机器人任务数据集,RLBench是一个模拟Franka机器人执行桌面操作的模拟器,涵盖了广泛的抓取与非抓取任务。研究人员利用模拟器的内置规划算法自动生成成功的操作轨迹,并使用正向运动学和相机参数来提取2D路径。
真实机器人数据:使用来自Bridge数据集和DROID数据集的真实机器人数据,确保VLM能够根据场景推理物体和机器人抓取路径。两者的数据转化为视觉问答数据集,2D路径从本体感知和相机参数中提取。
2.3. 路径指导的低层策略学习
HAMSTER的低层策略模型是基于本体感知和视觉观测(可选)的语言指令,特别是2D路径进行动作生成。虽然低层控制策略可以在没有2D路径的情况下学习解决任务,但2D路径使得低层策略能够避免长时程和语义推理,而专注于局部和几何预测,从而生成更精确的机器人动作。在本文的实验中也表明,2D路径显著提高了低层策略的视觉和语义泛化能力。
HAMSTER的通用路径条件框架允许低层策略接收本体感知和视觉输入(例如,深度图像),这些输入不传递给高层VLM。研究人员考虑了基于3D感知信息的低层策略,例如在测试时基于标准深度摄像头的机器人平台上的数据。研究还探讨了两种策略架构,RVT-2和3D-DA,它们在流行的机器人操作基准上展示了最先进的成果。
此外,低层策略训练通过在机器人硬件上收集相对较小的任务特定数据集进行,并使用正向运动学和相机参数生成2D路径,从而构建路径标注数据集。在训练过程中,策略通过标准的监督模仿学习目标优化,以最大化数据集动作的对数似然性。由于HAMSTER采用分层设计,能够在每个回合中只查询一次或少数几次VLM,生成2D路径并让低层策略在多个步骤中跟随,从而在推理速度上节省了大量开销。这使得HAMSTER能够扩展到大型VLM骨架,而无需用户关注推理速度。
03 实验
纵观实验的整个结果(如图4所示),能够分析得到HAMSTER 在适应新任务变化方面,相较于 OpenVLA 和 3D 模仿学习(RVT2、3DDA)策略,表现更胜一筹。
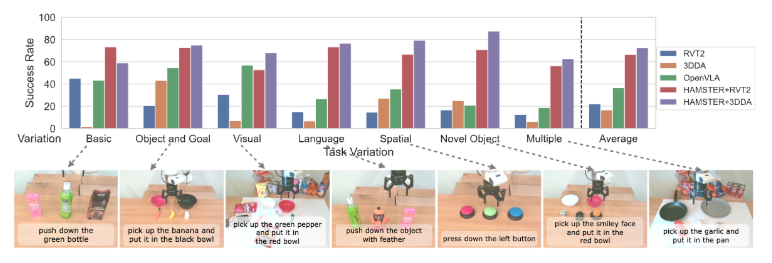 ▲图4| 总体实验结果©️【深蓝AI】编译
▲图4| 总体实验结果©️【深蓝AI】编译
作者在图5中展示了机器人对于不同的任务和不同的描述的处理能力,同时提供了视频和Demo来展示这些机器人执行任务操作的流畅程度感兴趣的读者,可以请参见作者的预告视频,链接为:https://hamster-robot.github.io/.。
 ▲图5| 机器人操作演示Demo©️【深蓝AI】编译
▲图5| 机器人操作演示Demo©️【深蓝AI】编译
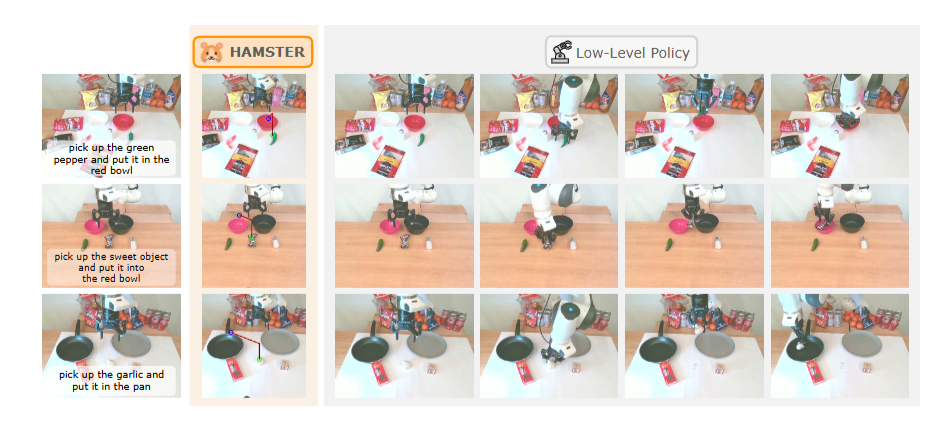 ▲图6| 真实世界机器人操作实验(面对不同形状的物体)©️【深蓝AI】编译
▲图6| 真实世界机器人操作实验(面对不同形状的物体)©️【深蓝AI】编译
在真实世界的场景中,HAMSTER也展示了卓越的性能,能够成功完成各种复杂的机器人操作任务。这一成果得益于其分层架构:高级视觉语言模型(VLM)通过泛化能力生成粗略的 2D 路径,而低级 3D 策略则负责精确执行动作。这种设计不仅使 HAMSTER 能够在视觉和语义层面实现泛化,还能在面对不同物体和任务时灵活调整操作策略。图6所示的实验中,即使物体的高度和形状各异,低级 3D 策略也能根据相同的路径条件进行推理,成功完成任务!
随后作者还对比了方法的运行速度,如图6所示:

 ▲图7| 数值实验结果©️【深蓝AI】编译
▲图7| 数值实验结果©️【深蓝AI】编译
最后作者也提供了数值实验的结果,但是从前面的可视化实验和Demo来看,数值实验的结果已经早早的能够预见到了,在各个数据集上都做到了领先,可见本文的方法确实开创了一个不错的思路,让机器人能够通过类似于看视频上网课的形式来自己训练自己,并取得不粗的成绩,是sim2real模式的一大创新。
04 总结
HAMSTER 研究了分层 VLA 模型的潜力,在机器人操作中实现了强大的泛化能力。该模型包括一个经过微调的 VLM,能够准确预测机器人操作的 2D 路径,以及一个低级策略,该策略学习使用 2D 路径生成动作。这种两步架构实现了跨显著域变化的视觉泛化和语义推理,同时使得数据高效的专业策略(如基于 3D 输入的策略)能够执行低级动作。
这项工作代表了开发多功能、分层 VLA 方法的第一步,未来有众多改进和扩展的机会。目前提出的工作仅在 2D 空间中生成点,而没有进行原生的 3D 预测。这阻碍了 VLM 形成真正的空间 3D 理解。此外,仅使用 2D 路径的接口是一个带宽有限的接口,无法传达诸如力或旋转等细微差别。未来,研究可学习的中间接口是一个有前景的方向。此外,直接从大规模人类视频数据集中训练这些 VLM 也将是很有前景的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









