






导读
自动驾驶汽车正走入我们的城市,但它们如何在复杂路况中安全协调?最新研究IntNet突破性地让车辆能够共享意图,而非仅仅交换位置数据。这种前瞻性通信让车辆能提前预测彼此行为,显著提高了在高速公路、交叉路口和车道合并等场景的安全性和效率。本文揭示这一创新框架如何通过多智能体强化学习,让自动驾驶汽车不仅能看到当前,更能预见未来,为智能交通系统开辟新篇章。
©️【深蓝AI】编译
该成果已被IEEE RAL收录
论文题目:IntNet: A Communication-Driven Multi-Agent Reinforcement Learning Framework for Cooperative Autonomous Driving
论文作者:Leandro Parada; Kevin Yu; Panagiotis Angeloudis
论文地址:https://ieeexplore.ieee.org/document/10844516
1. 研究背景
在动态城市环境中部署互联自动驾驶汽车(Connected and Autonomous Vehicles, CAVs)需要有效的协调来确保安全。虽然多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)在协调多机器人路径规划和导航等自主任务中展现出潜力,但将其应用于自动驾驶领域面临独特的挑战。城市环境的复杂动态性和部分可观测性使得实现高水平的安全和协调变得困难。此外,人类驾驶行为的不可预测性为这一挑战增添了一层复杂性。
多智能体强化学习在自动驾驶领域有广泛应用,从交叉路口管理到交通优化,展示了其对该领域的影响。值得注意的研究强调了MARL在协作运动规划以及控制交通信号以提高城市机动性方面的有效性。尽管取得了这些显著进步,但在自动驾驶中实现有效协调和安全仍然是MARL最关键的挑战。虽然无模型MARL本身不提供安全保证,但它通过试错学习提供了一种强大的方法来解决安全问题,特别是在具有多样化和复杂配置的场景中。
智能体协调已在MARL社区中通过共享状态表示进行了广泛研究。然而,对于像自动驾驶这样的安全关键应用——其特点是高度动态场景——仅仅共享状态特征是不够的。了解他人的未来意图为智能体提供了可能无法获得的额外上下文信息,从而为更安全、更高效的决策创造机会。虽然一些研究已经探索了MARL中的意图共享,但它们的应用仅限于简单的网格状环境,缺乏自动驾驶的复杂性,如高维观测(例如摄像头、激光雷达)和自动交通动态。
为了解决现有的空白,本文引入了IntNet,一个为CAVs导航复杂城市环境安全高效定制的意图共享MARL框架。IntNet通过两个通信步骤运行:在第一步,智能体共享编码的消息和基于实际观察到的信息的最近决策策略;在第二步,它们通过未来预测范围H内传递估计的意图。每个智能体使用观察预测器来预测环境状态,在范围H上投射未来策略,以增强协调和主动决策。为了高效管理这个过程,使用调度器组件进行带宽优化,同时使用图注意力网络处理传入的消息。在端到端框架中整合每个组件使安全自然地从协调学习中出现,而不是依赖硬约束。整体架构采用演员-评论家损失,同时使用独立的监督损失来训练观察预测模块。训练直接从环境交互中进行,无需对观察预测器进行预训练。
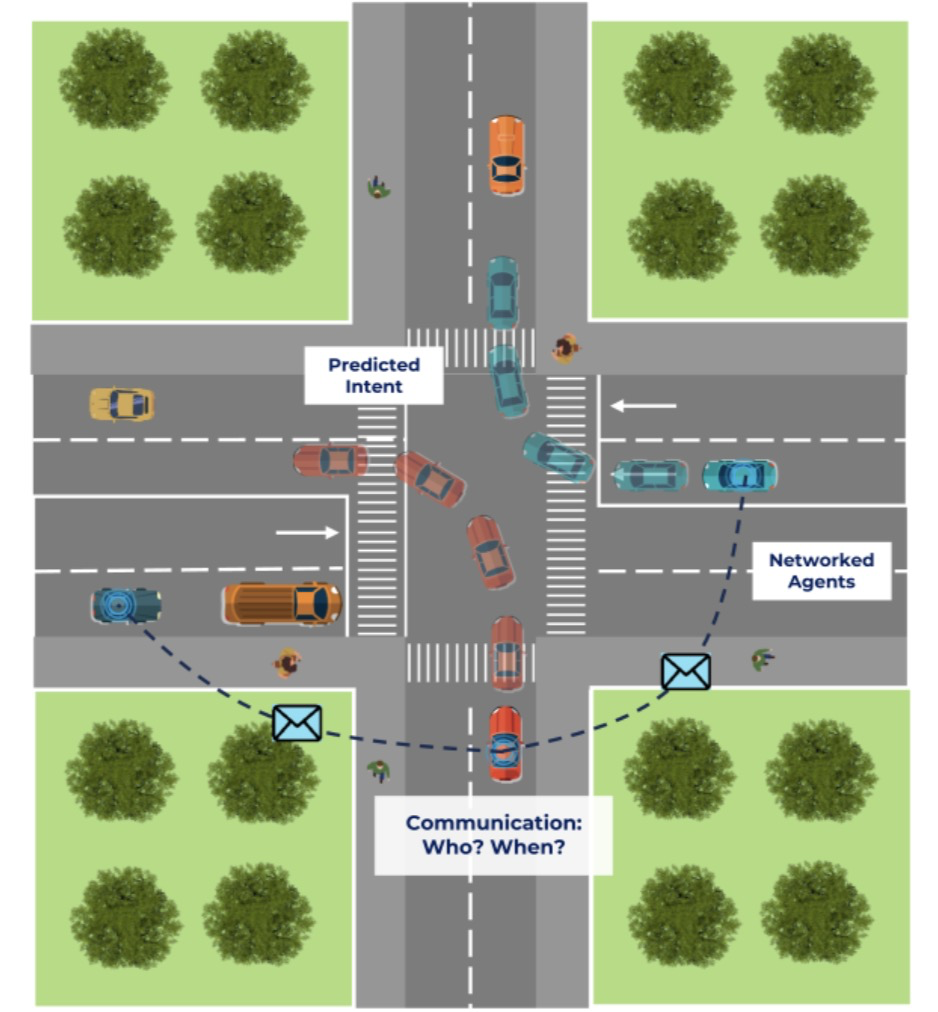
图1:对MARL的解释:图中展示了状态信息和车辆意图的交换过程和相互协调并进行实时决策的过程。
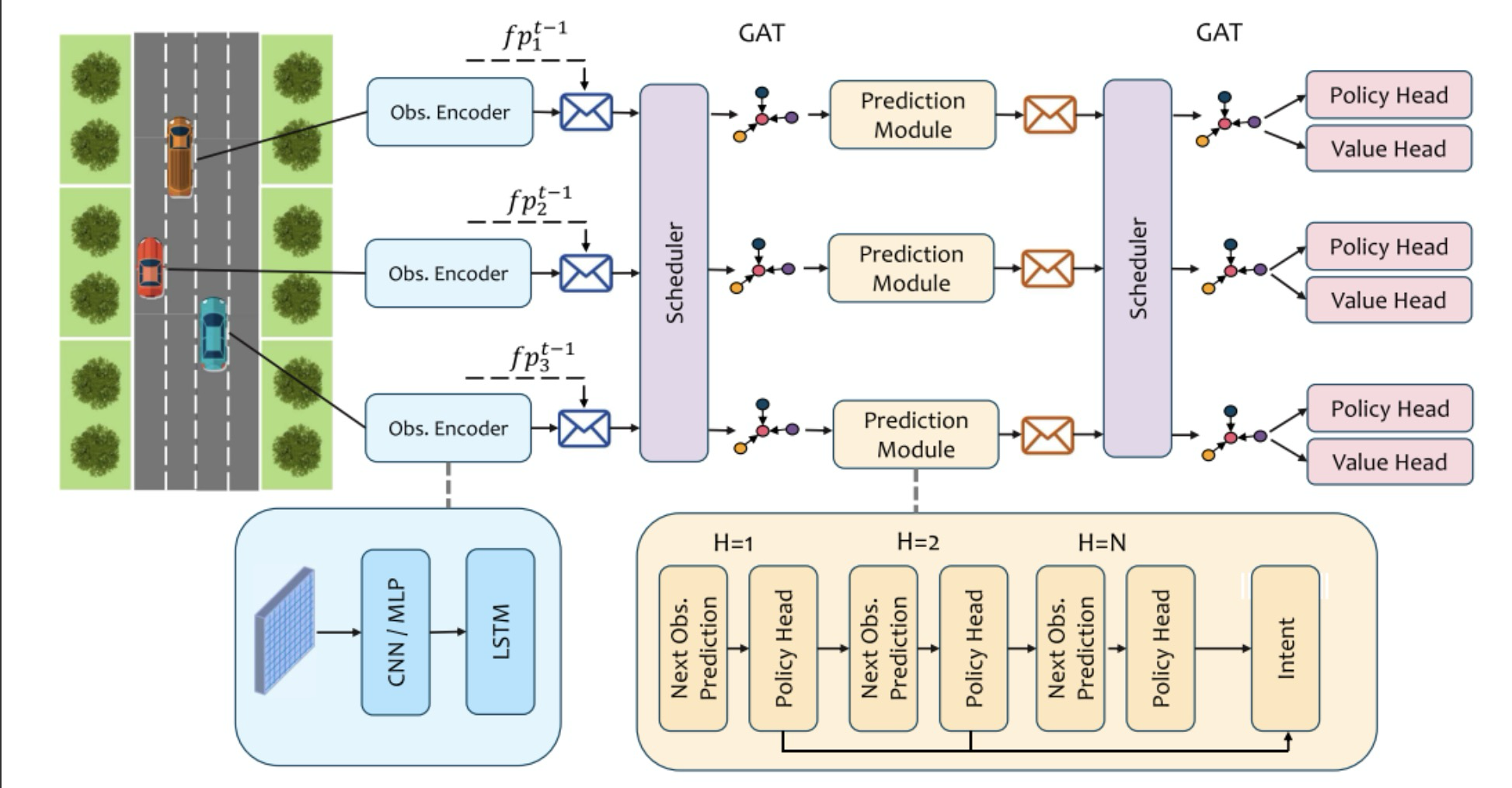
图2:IntNet框架,在该框架中,调度器优化了通信图,而GAT模块则处理传入消息,并优先处理决策所需的信息。
本文的主要贡献包括:
1. 提出了一个新颖的意图共享框架用于通信型MARL,集成了图注意力网络(GATs)处理共享消息和调度机制优化通信,增强协调并减少安全关键场景中的不确定性。
2. 开发了一个无需预训练的多智能体环境预测模块,允许智能体递归规划未来行动。
3. 超越了先前在网格环境中的工作,融入了高维观察和真实的车辆运动学,提供了更具代表性的自动驾驶场景中通信型MARL的评估。
2. 研究方法
2.1 基于通信的多智能体强化学习
我们将通信型多智能体强化学习(MACRL)建模为分散部分可观测马尔可夫决策过程(Dec-POMDP),用元组表示。其中,
是智能体数量;
表示所有可能的状态,
代表环境在时间
的状态;
包含所有可能的动作,每个智能体
在每个时间步选择动作
。
智能体通过观察接收部分信息,智能体动作导致的状态转换由转换函数
定义。奖励函数
决定即时奖励。当前和未来奖励通过折扣因子
平衡。
通信通过消息M进行,由协议管理,该协议定义消息如何聚合。总体目标是为每个智能体确定策略
,以最大化期望累积奖励。
2.2 基于意图共享的MARL框架
我们提出的意图共享MARL框架旨在通过通信型演员-评论家模型促进协作环境中智能体间的通信。该框架通过两个通信步骤运行:一个用于共享当前观察和策略指纹,另一个用于在未来预测范围内交换估计意图。
1)观察编码和策略指纹
在第一步中,每个智能体在时间步
使用编码函数
将其局部观察
编码为消息
。编码消息
有效地概括了可与其他智能体共享的观察状态信息。
同时,每个智能体也广播其前一时间步的策略指纹,表示为。此指纹总结了智能体的最近决策上下文,作为其策略的特征签名。策略指纹定义为动作空间
上的概率分布,其中包含了智能体
在
时间步的局部观察和从其他智能体接收的消息。这种方法使智能体能够同时共享当前观察和最近决策上下文,为协作行动规划奠定基础。
2)意图预测和共享
在第二步中,每个智能体预测并共享其在特定时间范围$H$内的未来意图。这些预测通过一系列未来策略指纹表示,总结了智能体在未来
步的预计决策策略。
意图集包含从
到
时间步的多个未来策略指纹
。每个未来策略指纹使用观察预测模块
计算,该模块递归地从智能体当前观察
和来自其他智能体的策略指纹开始。
对于(第一步预测),函数
使用智能体当前观察
和前一时间步其他智能体的策略指纹作为输入。对于
,
递归更新预测观察,将前一步预测观察和对应的策略指纹作为输入。通过这种递归机制,
有效捕捉环境不断演变的动态,使每个智能体能够形成对其在范围H内预期观察的连贯前瞻性计划,从而实现更明智、协调的决策。
3)通信调度和图注意力
考虑到自动驾驶中有限带宽和高维状态空间,我们的方法为每个通信步骤包含了一个调度器。该调度器通过构建邻接矩阵确定每个时间步t智能体间的通信链接。这种设置允许通过减少不必要的数据交换来优化通信,从而提高带宽效率。
智能体在每次通信步骤后使用图注意力网络(GAT)合并和处理接收到的消息。GAT采用注意力机制动态地权衡每个消息的重要性,允许智能体优先处理最相关的信息。这种优先级对于有效决策至关重要,特别是在高维、带宽受限的环境中,无法同等考虑所有信息。GAT可以自适应地从最相关邻居优先获取信息,有效地将传输的消息整合为增强决策的有意义特征。最后,智能体处理完传入消息后,通过独立的线性层确定策略和价值输出。
2.3 训练
观察预测模块和策略使用从情节回放中收集的数据同步训练。与以往方法不同,我们不对
进行预训练。相反,在回放期间存储的转换同时用于更新预测模块和策略。
为训练观察预测模块,每个情节步骤生成转换,从中我们编译一个监督数据集,输入为
,目标为
。观察经过归一化,变量分为连续或分类。fobs使用均方误差(MSE)损失训练。
同时,策略使用演员-评论家损失训练,结合演员(策略)和评论家(价值)的损失。这种并行训练设置允许观察预测模块实时提高策略对环境动态的理解,无需单独的预训练阶段。
2.4 环境描述
我们使用修改版的Highway-env,适用于多智能体城市导航,智能体避免碰撞并到达目的地以最大化奖励。虽然Highway-Env作为基础模拟器,但增加实时通信功能和动态图学习显著增加了场景复杂性。智能体必须实时处理通信,构建动态图进行决策,并在多智能体环境中协调,这带来了巨大的计算和学习挑战。为增强适应性,我们在车辆速度、位置和目的地中引入随机性,并将智能体通信限制在60米内,以符合DSRC协议约束。
环境的元素包括:
1)智能体:具有有限可见性的CAVs,能够通过车对车通信网络交换消息
2)观测:使用射线投射的类激光雷达方法,分割智能体周围360°区域,探测80米范围内的其他车辆
3)动作:包括加速、减速、保持速度和变道(左右)的离散元动作
4)奖励:为协作游戏设计的奖励函数,包含速度、避撞、到达和合作并道奖励组件
3.实验
我们将我们的方法与基线在三种场景下进行基准比较:高速公路、四向交叉路口和车道合并,如图3所示,包括原理图和实际环境表示以说明观察情况。高速公路和车道合并环境包含自动驾驶车辆(CAVs)和人类驾驶车辆(HDV),而交叉路口环境仅由CAVs组成。为模拟HDVs,我们使用IDM/MOBIL车辆跟随模型,这在文献中已广泛用于通过简单分析模型表示人类驾驶行为。
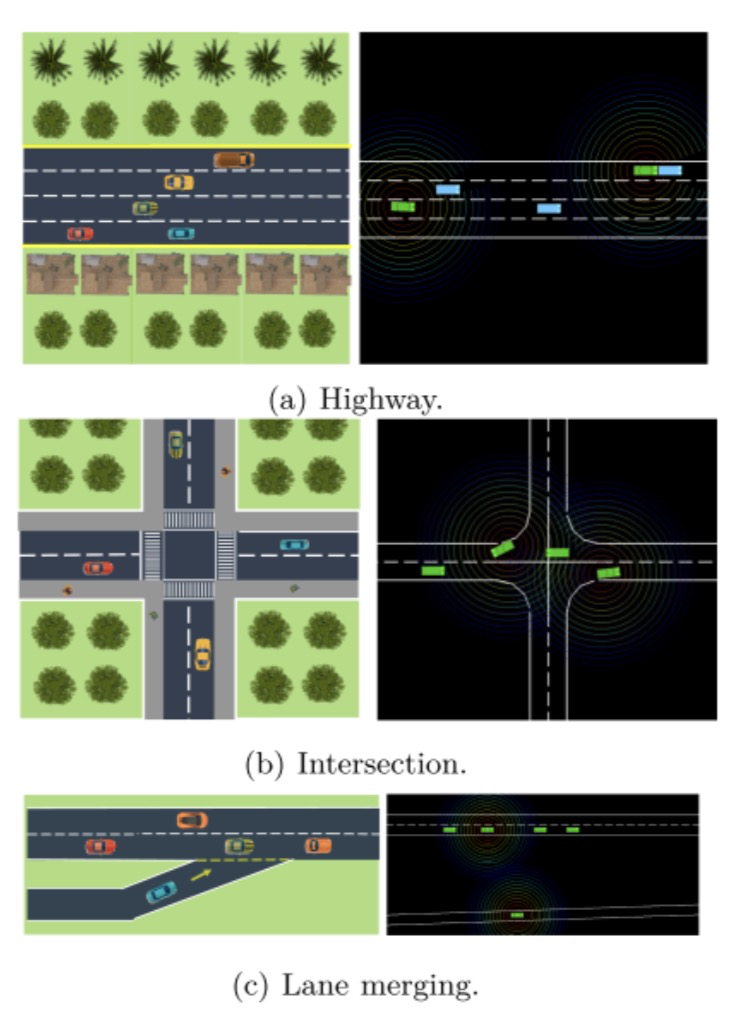
图3:实验场景
我们研究的主要评估指标是平均到达率和碰撞率,以百分比表示。到达率量化所有CAVs成功达到目的地的场景百分比,而碰撞率测量涉及至少一次CAV碰撞的场景百分比。此外,还评估平均团队收益以评估整体表现。为确定我们训练结果的稳健性,我们使用三个独立的种子生成学习曲线,并在100个测试场景中验证结果。所有实验的预测范围设为H=2,基于初步实验,其结果在附录中提供。
3.1 基线比较
我们与已建立的基于通信的MARL方法对比评估了我们方法的性能,这些方法主要关注共享状态或状态特征。比较包括三种基线方法:无通信、CommNet、IC3Net和MAGIC。
图4和图5分别展示了所有方法在三种场景下的团队奖励和到达统计,IntNet在所有场景中始终获得更高的奖励和成功率。到达率的变化表明,意图共享在特定场景中特别有益,如车道合并场景,这对安全导航至关重要,而在交叉路口场景中的影响较小。表I进一步详细说明了这些场景中100个独立场景的测试到达率性能,支持这些观察结果。
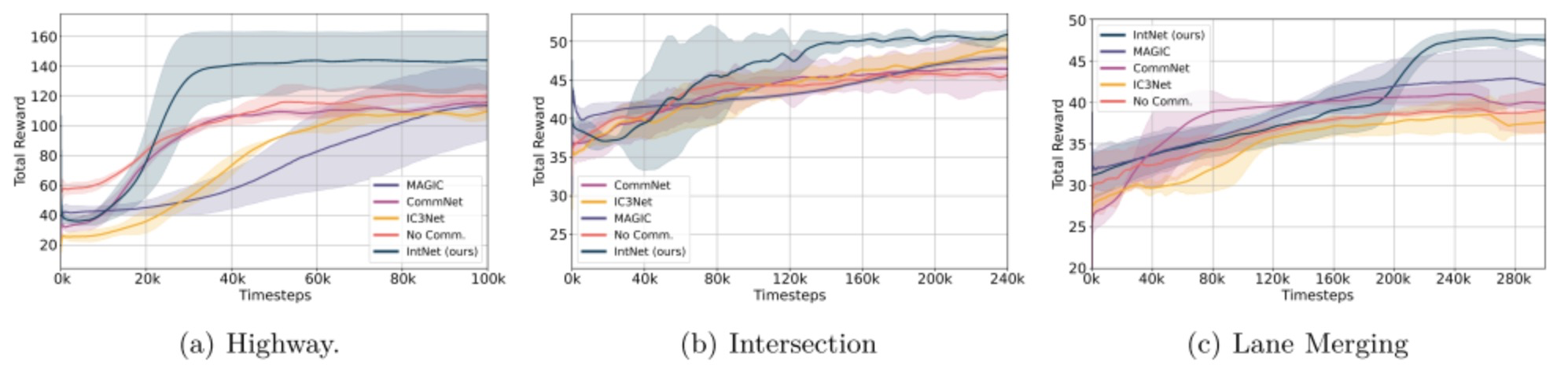
图4:训练过程中的奖励
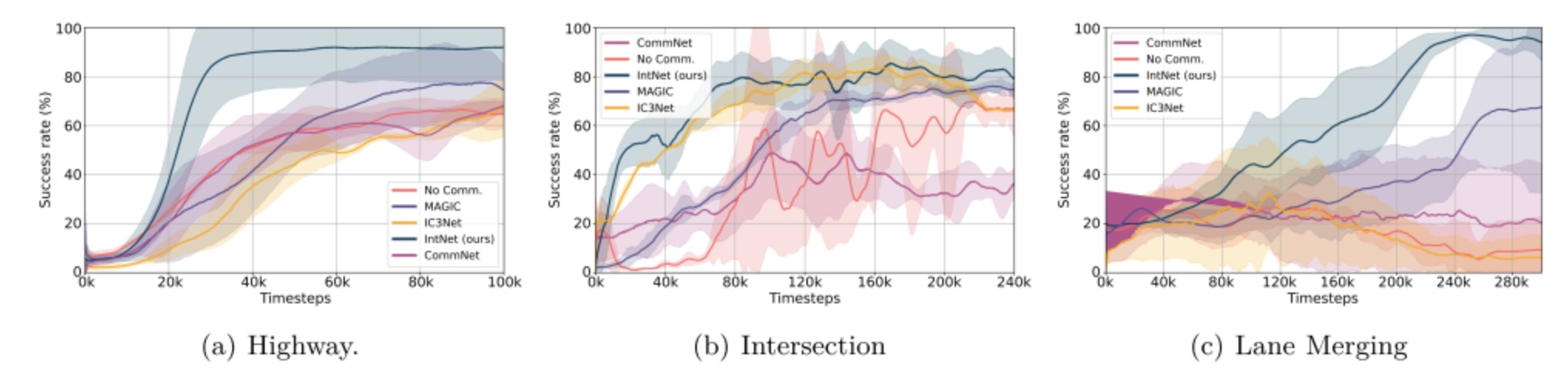
图5:训练过程中的成功率
在高速公路场景中,我们提出的方法使智能体只需10万训练场景就能达到高成功水平,而基线方法需要约20万场景才能获得类似的成功和安全结果。在交叉路口场景中,虽然IC3Net展现了与我们的IntNet方法相当的成功,但我们的方法提供了更快速和一致的学习曲线。我们发现所有基线算法在车道合并场景中表现不佳。这个场景要求三个场景中最多的合作,导致基线算法学习不一致,通常倾向于以牺牲安全为代价提高速度的解决方案,导致更多碰撞。
3.2 可扩展性
为评估我们方法的可扩展性,我们在交叉路口场景中进行了实验,逐渐增加网络中的智能体数量。结果如图6所示,展示了智能体数量变化时的测试碰撞率(%)。正如预期,环境复杂度随着每个额外智能体的增加而提高,使得维持零碰撞率变得越来越困难。尽管如此,当增加智能体数量时,我们的IntNet方法相比IC3Net模型产生了显著更低的碰撞率。随着更多智能体的加入,IC3Net模型展示了越来越多的碰撞,当环境包含十个智能体时,碰撞率超过15%,突显了即使有通信,在更拥挤设置中扩展的挑战。
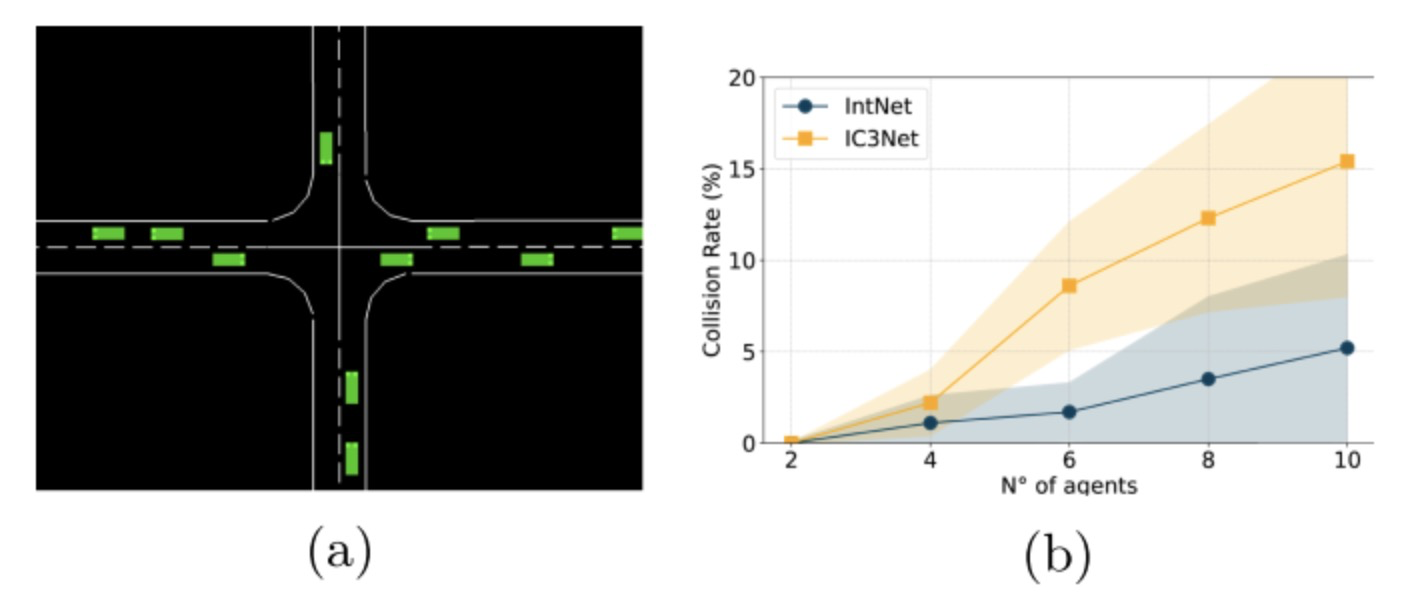
图6:智能体数量对算法的影响
3.3通信效率
我们的架构包括一个调度器组件,优化消息传输,减少通信网络负载。我们通过在仅有CAVs的交叉路口场景中进行实验评估了其影响,对比了有无调度器的网络性能。没有调度器时,系统默认为完全连接网络,促进范围内所有智能体间的通信。
智能体仅在安全导航的关键时刻通信,如图7所示,展示了交叉路口环境中两个关键时刻的通信图。图7(a)揭示了智能体接近交叉路口时的图,图7(b)显示了大多数智能体离开时的图,7(b)中的链接(车辆ID 0到3)表示仍在交叉路口的车辆。
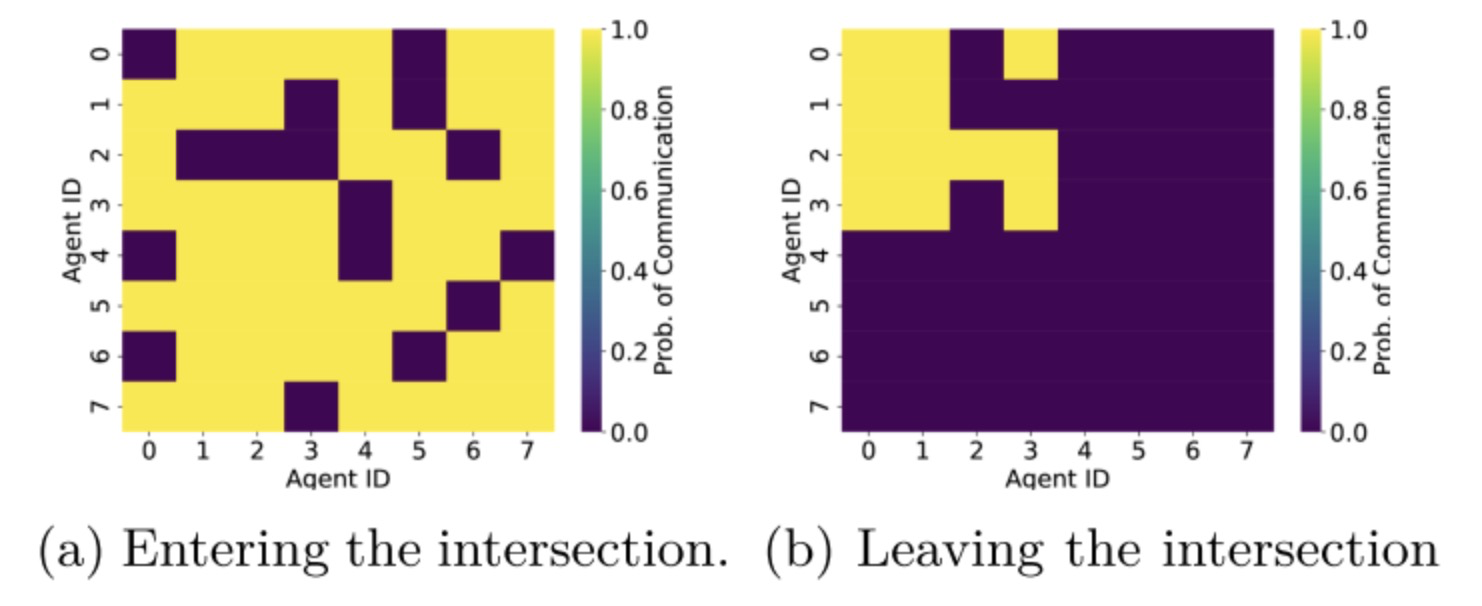
图7:通信状态
4. 结论
本研究引入了IntNet,一个以通信为驱动的MARL框架,用于协作自动驾驶,旨在通过共享车辆意图增强协调和安全。我们通过将观察预测模块纳入通信型演员-评论家架构实现这一目标。我们的无模型训练方法使用在场景回放中记录的转换同时训练观察预测器和策略。结果证明了我们的意图共享策略在促进复杂城市环境中更安全、更高效的策略方面的有效性,同时最小化通信图密度。我们的发现还表明,共享意图不仅增强了安全和效率,还加速了学习收敛,简化了在复杂多智能体环境中达到最优策略的路径。未来工作将专注于扩展该方法在不同城市场景和不同预测范围H的适用性,同时考虑通信延迟和数据包丢失。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









