






Text2Reward: Reward Shaping with Language Models for Reinforcement Learning
摘要
设计奖励函数是强化学习(Reinforcement Learning, RL)中的一个长期挑战;它需要专业知识或领域数据,导致开发成本高昂。为了解决这个问题,本文介绍了TEXT2REWARD,一个 data-free 框架,可以基于大型语言模型(Large Language Models, LLMs)自动产生和成形密集奖励函数(dense reward functions)。给定一个用自然语言描述的目标,TEXT2REWARD生成成形的密集奖励函数,作为一种对环境紧凑表示(compact representation)的可执行程序。与逆强化学习和最近的使用LLMs编写时间步长上稀疏奖励代码(sparse reward codes)、或时间步上具有恒定函数的未成形的密集奖励的工作不同,TEXT2REWARD产生的是可解释的、自由形式(free-form)的密集奖励代码,这些代码覆盖了广泛的任务,利用了现有的包,并允许通过人工反馈进行迭代改进。本文在两个 robotic manipulation benchmarks (ManiSkill2, MetaWorld) 和MuJoCo的两个运动环境(locomotion environments)上评估TEXT2REWARD。在17个操作任务中的13个上,使用生成的奖励代码训练的策略,实现了比专家编写的 reward codes 相似或更好的任务成功率和收敛速度。对于运动任务(locomotion tasks),本文的方法学习到六种新的运动行为,成功率超过94%。最后,TEXT2REWARD通过人类反馈改进奖励函数,进一步提升了策略。视频结果可在https://text-to-reward.github.io获取。
1 引言
奖励构造(Ng et al., 1999_Reward_Shaping)一直是强化学习(Reinforcement Learning, RL)中的一个长期挑战;它旨在设计奖励函数以更高效地引导智能体实现期望行为。传统上,奖励构造通常是基于专家直觉和启发式方法手动设计奖励,这是一个耗时的过程,需要专业知识且可能是次优的。逆强化学习(Inverse reinforcement learning, IRL)(Ziebart et al., 2008_Maximum_Entropy_IRL; Wulfmeier et al., 2016_Deep_IRL; Finn et al., 2016_Guided_Cost_Learning)和偏好学习(preference learning)(Christiano et al., 2017_DRL_from_Human_Preferences; Ibarz et al., 2018_Reward_Learning; Lee et al., 2021_Pebble; Park et al., 2022_SURF)已成为奖励构造的潜在解决方案。奖励模型是从人类演示(human demonstrations)或基于偏好的反馈中学习到的。然而,这两种策略仍然需要相当大的人力或数据收集;此外,基于神经网络的奖励模型不具有可解释性,且无法推广到训练数据领域之外。
本文介绍了一种新的框架,TEXT2REWARD,基于 goal descriptions 生成和构造密集奖励代码(dense reward code)。给定一个强化学习目标(例如,“将椅子推到标记位置”),TEXT2REWARD基于大型语言模型(Large Language Models, LLMs),并以环境的 compact, Pythonic representation为基础(图1左侧),来生成密集奖励代码(图1中间)。
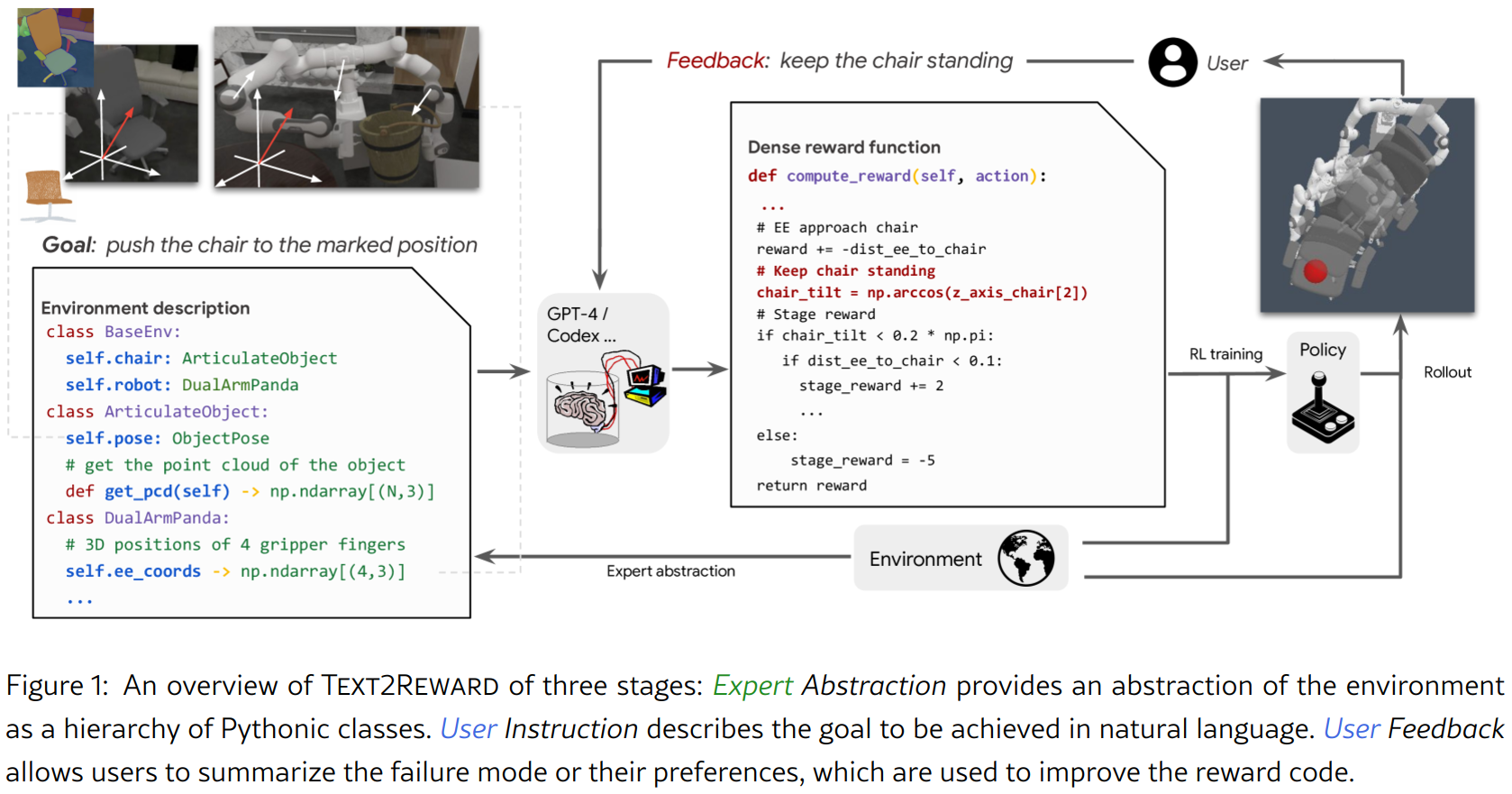
然后,这个密集奖励代码被用于强化学习算法如PPO(Schulman et al., 2017_PPO)和SAC(Haarnoja et al., 2018_SAC)来训练策略(图1右侧)。不同于 inverse RL,TEXT2REWARD无需数据(data-free)且生成具有高可解释性的 symbolic reward。与近期使用LLMs编写的使用手工设计API(hand-designed APIs)的非构造的奖励代码的工作(Yu et al., 2023_Language_to_Rewards)不同,本文方法的自由形式(free-form)构造的密集奖励代码覆盖更广泛的任务,并且可以利用现有的编码包(例如,用于点云和智能体位置的NumPy运算)。最后,考虑到强化学习训练的敏感性(sensitivity)和语言的歧义性(ambiguity),强化学习策略可能无法达到目标或以非预期的方式达到目标。TEXT2REWARD通过在环境中执行学习到的策略,获取人类反馈,并相应地优化奖励函数来解决这个问题。
本文在两个机器人操作基准(ManiSkill2 (Gu et al., 2023), MetaWorld(Yu et al., 2020))和MuJoCo(Brockman et al., 2016)的两个运动环境上进行了系统实验。在17个操作任务中的13个任务上,本文方法生成的奖励代码训练的策略,在成功率和收敛速度上的表现,达到或超过了人类专家精心调整的 ground truth 奖励代码。在运动方面,TEXT2REWARD学会了6种创新的运动行为,成功率超过94%。本文还证明了在模拟器中训练的策略可以部署到真实的 Franka Panda 机器人上。在人工反馈次数不到3次的情况下,本文的方法可以迭代地将成功学习策略概率从0提高到接近100%,并且能够解决任务歧义问题。总之,实验结果表明,TEXT2REWARD可以生成具有可泛化性和可解释性的密集奖励代码(dense reward code),实现强化学习任务的广泛覆盖以及人在回路流程。本文希望这些结果能够启发强化学习和代码生成交叉领域的进一步探索。
2 方法
2.1 背景
奖励代码
强化学习 (Reinforcement Learning, RL) 旨在学习一个策略,使其能够在一个episode中最大化预期奖励。为了训练一个策略来实现一个目标,关键是设计一个指明目标的奖励函数。奖励函数可以采取各种形式,例如神经网络或一段 reward code。本文重点关注奖励代码,因其具有可解释性。在这种情况下,观测(observation)和动作被表示为变量,因此奖励不需要处理感知——它只需要代码中的抽象变量和API进行推理。
奖励构造
从 task completion rewards 中进行强化学习是困难的,因为奖励信号是稀疏(sparse)且延迟的(delayed)(Sutton & Barto, 2005)。一个成形的密集奖励函数是有用的,因为它鼓励 key intermediate steps 和regularization,帮助实现目标。以代码形式表示时,构造的(shaped)密集奖励可以在每个时间步采取不同的函数形式,而不是在时间步之间保持相同或仅在episode结束时出现。
2.2 零样本和小样本密集奖励生成
在这部分,本文将描述TEXT2REWARD进行 zero-shot 和 few-shot 密集奖励生成的核心内容。详细的提示示例(prompt examples)可以在附录C中找到。交互式生成将在下一小节中描述。
指令
Instruction是一个自然语言句子,描述了我们希望智能体实现的目标(例如“将椅子推到标记的位置”)。它可以由用户提供,或者可以是由LLM规划的长期任务中的其中一个子目标。
环境抽象
为了在环境中实现奖励生成,模型需要知道环境中如何表示 object states ,例如机器人和物体的配置(configuration),以及可以调用哪些函数。如图1所示,本文采用了Pythonic风格的紧凑表示,它利用 Python class, typing, and comment。相较于以列表或表格格式列出所有特定环境信息,Pythonic表示具有更高层次的抽象,使得能够在不同环境中编写 general, reusable 的提示。此外,这种Pythonic表示在LLMs预训练数据中很普遍,使LLM更容易理解环境。
背景知识
由于这些domains的数据稀缺,生成密集的奖励代码对LLMs来说 can be challenging。近期的研究表明,提供相关的函数信息和使用示例有助于代码生成(Shi et al., 2022_MBR-EXEC; Zhou et al., 2022_DocPrompting)。受此启发,本文提供了在这个环境中可能有用的函数作为背景知识(例如,用于成对距离(pairwise distance)和四元数计算(quaternion computation)的NumPy/SciPy函数,通过其输入输出类型和自然语言解释来指定)。
小样本示例
提供相关示例作为输入已被证明有助于LLMs解决任务。本文假设可以访问一个由指令对(pairs of instructions)和经过验证的奖励代码(verified reward codes)组成的池。这个库可以由专家初始化,然后通过生成的密集奖励代码持续扩展。本文使用 Su et al.(2022_INSTRUCTOR)的句子嵌入模型来编码每个指令(instruction)。给定一个新的指令,本文将使用嵌入检索最相似的 top- k k k个指令,并将指令-代码对(instruction-code pairs)组合为小样本示例。由于上下文长度限制,本文将 k k k设为1,并从检索池中过滤掉该任务的基准代码以确保大语言模型不会作弊。
通过代码执行减少错误
一旦生成了奖励代码,就会在代码解释器中执行该代码。这一步可以提供有价值的反馈,例如,syntax errors 和 runtime errors(例如,矩阵之间的形状不匹配)。参照之前的研究工作(Le et al., 2022; Olausson et al., 2023),我们利用代码执行的反馈作为在大语言模型中持续改进的工具。参照之前的研究工作(Le et al., 2022_CodeRL; Olausson et al., 2023_Self-Repair),本文利用代码执行的反馈作为工具,在LLM中进行持续改进。这个迭代过程有助于错误的systematic rectification,并持续到代码中没有错误为止。本文的实验表明,这一步将错误率从10%降低到接近零。
2.3 根据人类反馈改进奖励代码
人类很少在一次互动中指定精确的意图。在乐观的情况下,初始生成的奖励函数可能在语义上是正确的,但实际上是 sub-optimal。例如,指示机器人打开橱柜的用户可能可能没有具体说明是拉把手还是拉门边。尽管这两种方法都能打开柜子,但前者更可取,因为这样不太可能会损坏到家具和机器人。在悲观的情况下,最初生成的奖励函数可能难以完成(too difficult to accomplish)。例如,让机器人“清理桌子”比让机器人“拿起桌子上的物品然后将其放进下面的抽屉里”会导致更加困难的学习过程。尽管这两种描述都指定了相同的意图,但后者提供了简化 learning problem 的中间目标。
为了解决不明确(under-specified)指令导致次优奖励函数的问题,TEXT2REWARD会主动请求用户的人工反馈以改进生成的奖励函数。在每个 RL training cycle 之后,用户将获得当前策略执行任务的展示视频。随后,用户基于视频给出关键的见解和反馈,指出有待改进之处或存在的错误。然后,用户根据视频提供关键(critical)的见解和反馈,指出需要改进的地方或错误。该反馈被集成到后续提示中,以生成更精细、更有效的奖励函数。在第一个打开橱柜的例子中,用户可能会说“use the door handles”,以防止机器人通过拉门边缘打开而损坏自身和家具。在第二个清理桌子的例子中,用户可能会说“pick up the items and store them in the drawer”,以鼓励机器人解决子任务。值得注意的是,这种设置鼓励普通用户参与其中,即便他们没有编程或强化学习方面的专业知识,实现了一种通过自然语言指令优化系统功能的大众化的方法,进而消除了专家干预(expert intervention)的必要性。
3 实验设置
本文在三个环境:MetaWorld、ManiSkill2和 Gym MuJoCo 中,在操作和移动任务上对Text2Reward进行了评估。本文使用 GPT-4 作为语言模型来展示我们的方法,并进一步附录F中检验了其他开源模型。这样做不仅是为了确保可重复性,也是为了明确当前任务的复杂性。本文选定了RL算法(PPO或SAC),并根据人工编写奖励函数的性能来设置默认超参数,且在该任务的所有实验中都固定这些超参数以进行强化学习训练。实验超参数列于附录A。
3.1 操作任务
本文 demonstrate manipulation 进行在MetaWorld上,MetaWorld是 Multi-task Robotics Learning 和 Preference-based Reinforcement Learning(Nair et al., 2022_R3M; Lee et al., 2021_PEBBLE; Hejna III & Sadigh, 2023_Few-Shot_Preference_Learning)的常用基准,以及MANISKILL2,一个在物理仿真环境中实现执行多种 object manipulation tasks 的平台。本文评估了一系列不同的操作任务,包括拾取及放置、装配、使用旋转或滑动关节的铰接式物体操作以及移动操作。对于所有任务,本文将Text2Reward与由人类专家调优的 oracle reward functions(由原始代码库提供)进行了比较。本文还通过调整Yu等人(2023_Language_to_Rewards)所提出的提示(prompt)来建立一个基线(baseline),以使其适用于本文的强化学习框架,这与Yu等人(2023_Language_to_Rewards)最初描述的模型预测控制(Model Predictive Control, MPC)设置有所不同,因为设计物理模型需要大量额外的专家人力投入。对于强化学习训练,本文调整了超参数,以确保标准奖励函数达到最佳结果,然后在运行TEXT2REWARD时保持这些参数不变。任务的完整列表、相应的输入说明和模拟环境的详细信息见附录B。
3.2 移动任务
对于移动任务,本文使用 Gym MuJoCo 来展示所提出的方法。由于缺乏针对移动任务的专家编写的奖励函数,本文参照之前的研究(Christiano et al., 2017_Learning_from_Human_Preferences; Lee et al., 2021_PEBBLE),根据对过程视频(rollout video)的人工判断来评估策略。本文为两种不同的移动智能体,Hopper (a 2D unipedal robot) 和Ant (a 3D quadruped robot) 开发了共六个新任务。这些任务包括Hopper的向前移动(Move Forward)、前空翻(Front Flip)和后空翻(Back Flip),以及Ant的向前移动(Move Forward)、躺下(Lie Down)和摆腿(Wave Leg)。
3.3 真实机器人操作
与MPC(Howell et al., 2022_MPC)等基于模型的方法不同,那些方法需要进一步的参数调整,而我们在模拟器中训练的强化学习智能体只需进行少量校准,并引入随机噪声以实现从模拟到现实的迁移,就能够直接部署到现实世界中。为了展示这一优点,并验证所生成reward训练的强化学习策略的泛化能力,本文使用 Franka Panda 机器人手臂进行了真实的机器人操作实验。本文在两个操作任务上验证了所提出的方法:拾取立方体和堆叠立方体(Pick Cube and Stack Cube)。为了获取RL策略所需的物体状态,本文使用Segment Anything Model (SAM) (Kirillov et al., 2023_SAM) 和一个深度相机来获得物体的估计姿态。具体而言,本文使用SAM对场景中的每个物体进行分割。分割图和深度图一起给出了一个不完整的点云。然后我们基于这个点云估计物体的姿态。
3.4 基于人类反馈的交互式生成
本文在 single-round 奖励代码生成的挑战性任务 Stack Cube 上 conduct human feedback,以研究人类反馈是否可以改进或修复奖励代码,使RL算法能够在给定环境中成功训练模型。该任务包括以下步骤:触及(reaching)立方体、抓取(grasping)立方体、将立方体放置(placing)在另一个立方体上方,并释放(releasing)立方体使其保持静止。本文从零样本和少样本方法中采样了3个生成的代码,并进行了两轮反馈的任务。此外,本文还在一个移动任务 Ant Lie Down 上进行了实验,其中初始训练结果未能满足用户的preference。提供反馈的普通用户只能看到执行视频(rollout video)和学习曲线(learning curve),而不会看到任何代码。研究作者根据描述的实验设置提供了反馈。
4 结果与分析
4.1 主要结果
This section 展示TEXT2REWARD在机器人manipulation和locomotion任务上的结果。生成的奖励函数的示例可以在附录D中找到。
在操作任务上TEXT2REWARD≃专家设计的奖励。
图2和图3显示了环境MANISKILL2和METAWORLD的定量结果。
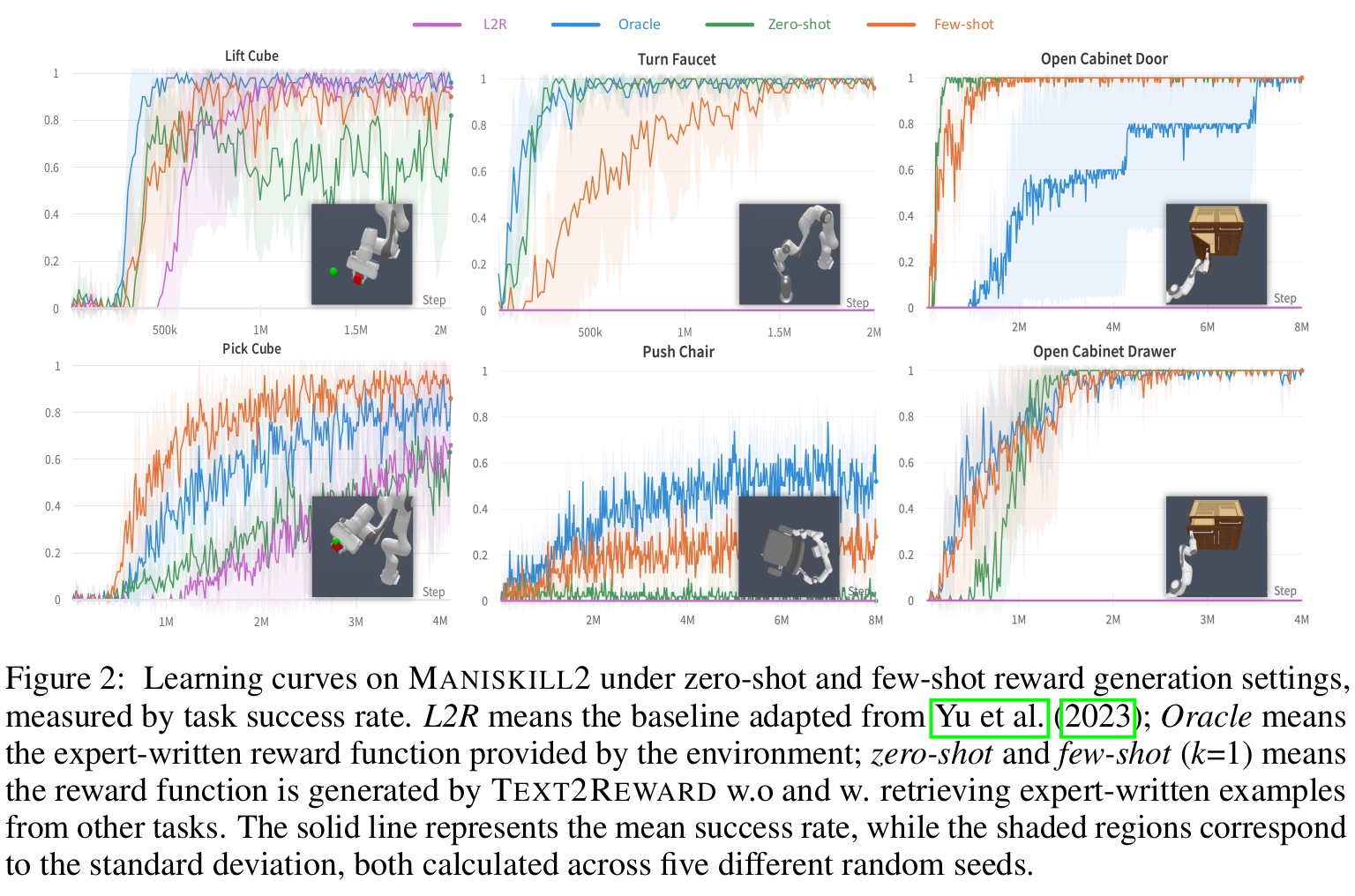
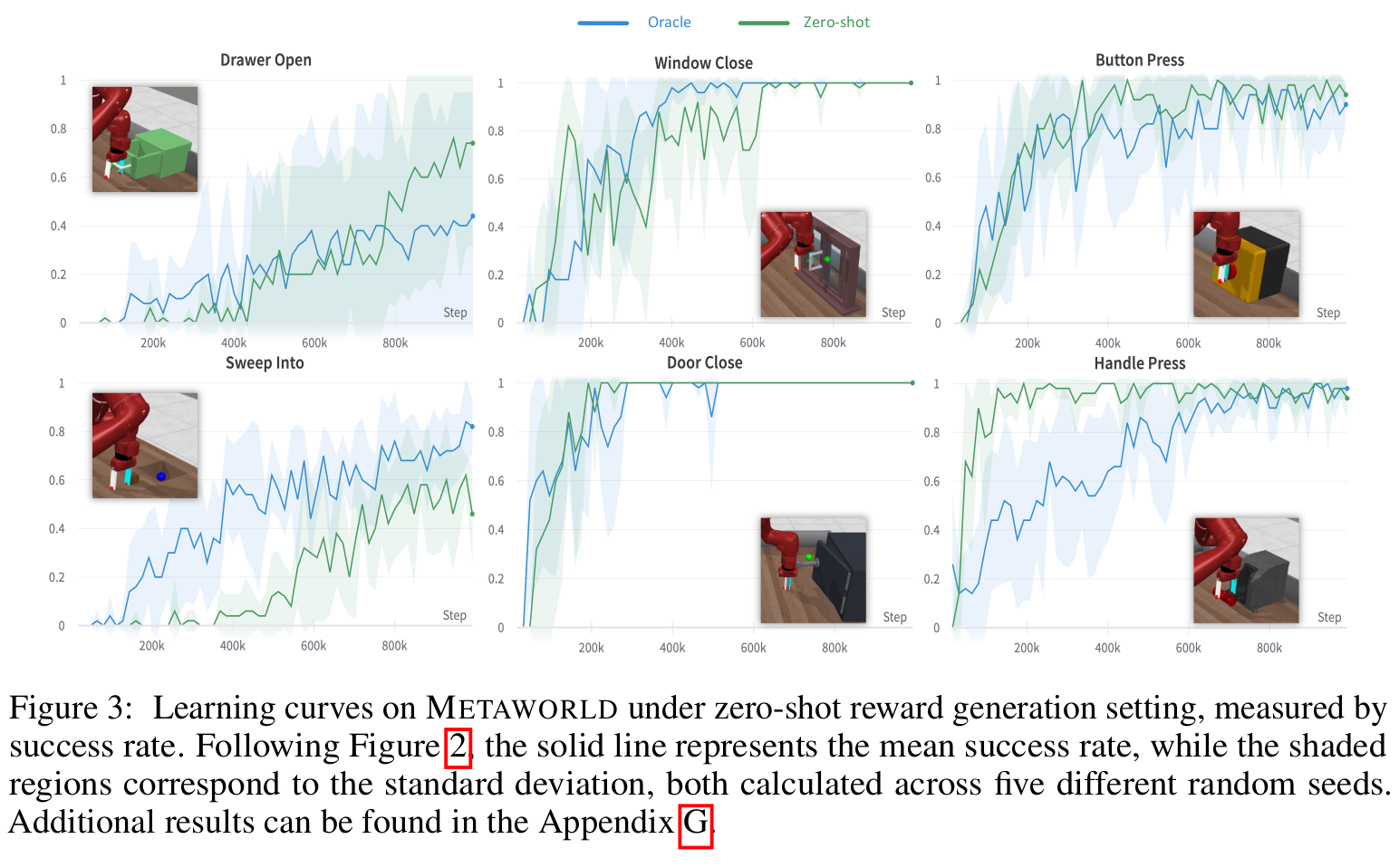
在图中,L2R代表由 baseline prompt 生成的奖励函数,该 baseline prompt 改编自Yu等人(2023_Language_to_Rewards);Oracle指的是environment提供的专家编写的 dense reward function;zero-shot and few-shot 分别代表在零样本和少样本提示范式下,由TEXT2REWARD生成的没有 human feedback 的密集奖励函数。在17个任务中的 13 个任务上,TEXT2REWARD的最终性能(即收敛后的成功率和收敛速度)与人类专家(human oracle)的性能相当。令人惊讶的是,在 17 个任务中的 4 个任务上,零样本和少样本的TEXT2REWARD甚至可以超越人类专家,无论是在收敛速度(例如,Maniskill2 中的 Open Cabinet Door,MetaWorld 中的 Handle Press)还是成功率(例如,Maniskill2 中的 Pick Cube,MetaWorld 中的 Drawer Open)方面。这表明,LLMs有潜力在没有任何人工干预的情况下草拟出高质量构造(high-quality shaped)的密集奖励函数(dense reward functions)。
正如图2所示,L2R基线只能有效地用于 ManiSkill2的两个任务,在这两个任务中,它取得的结果与 zero-shot 设置相当。然而,L2R在涉及具有复杂表面且不能用单个点充分描述的物体、例如人体工学椅的任务中表现不佳。在这些任务中,环境使用点云来表示物体的表面,而L2R无法对这种表示进行建模。为了更全面地评估构造的和分阶段的密集奖励(shaped and staged dense rewards)的必要性,本文在附录E中引入了一个额外的基线,它规避了L2R公式中上述的局限性。
此外,如图2所示,在6个 not fully solvable 的任务中的2个任务上,the few-shot paradigm 明显优于 the zero-shot approach。这突显了利用本文 skills library 中的少样本示例来增强强化学习训练奖励函数的有效性的好处。
TEXT2REWARD可以学习新的运动行为。
Table1展示了在 zero-shot 设置下生成的奖励所训练的所有六个任务的成功率,该成功率是通过人类观看 rollout videos 来评估的。结果表明,本文的方法可以生成能泛化到新移动任务上的密集奖励函数(dense reward functions)。来自 Gym Mujoco 环境的三个选定任务的图像示例如Figure4所示。
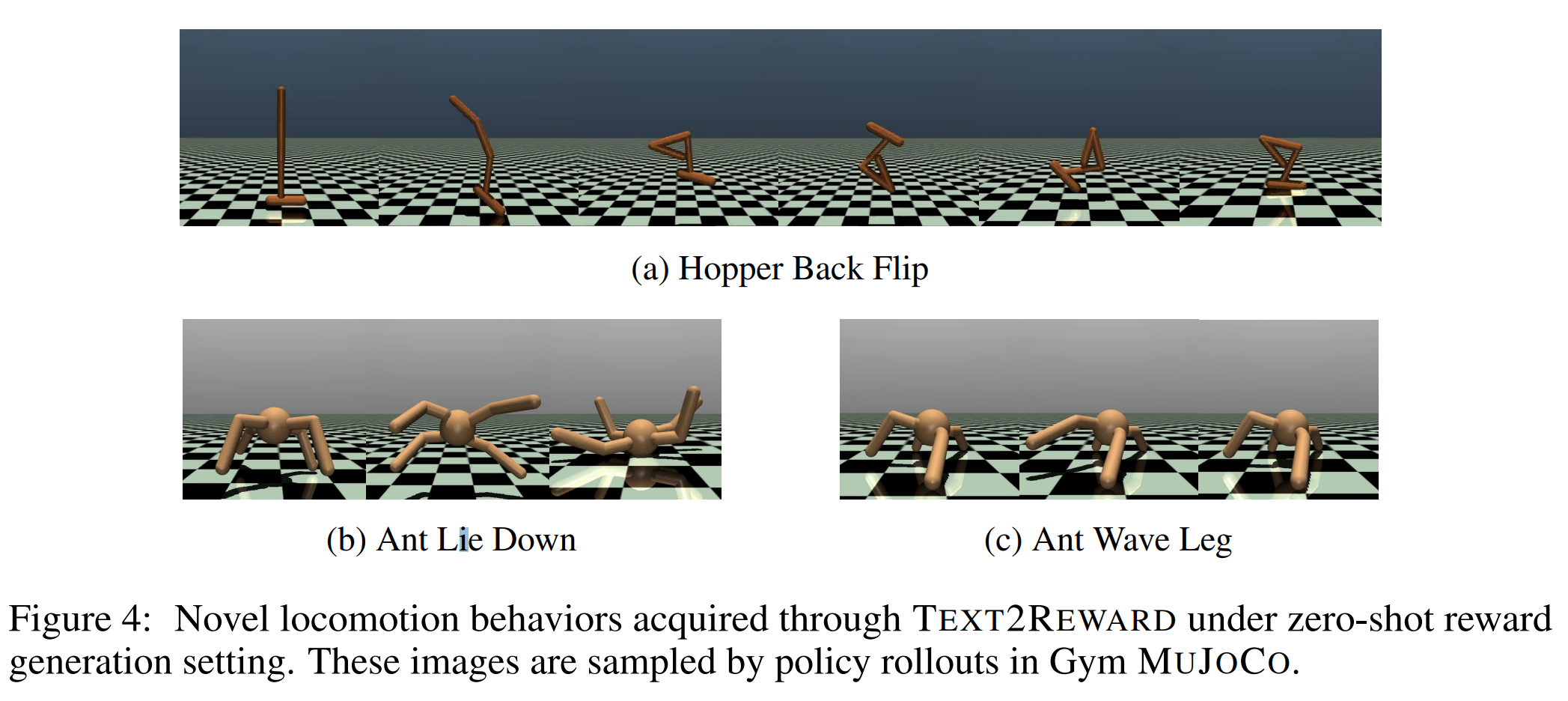
相应的完整视频结果可在here。
在真实的机器人上展示TEXT2REWARD。
Figure5展示了在两项任务(Pick Cube and Stack Cube)上真实机器人操作的关键帧。

这里,我们使用相同的 7 DoF Franka Panda 机器人手臂作为ManiSkill2仿真环境。结果表明,在模拟器中使用TEXT2REWARD生成的密集奖励函数训练的RL策略可以成功地部署到真实世界中。机器人执行的完整视频在本文的项目页面上。
TEXT2REWARD可以解决人类反馈中的歧义。
为了证明TEXT2REWARD解决这个问题的能力,本文将展示了一个案例,其中“control the Ant to lie down”本身在Ant的方向方面具有模糊性,如Figure6所示。

在观察该指令的训练结果之后,用户可以用自然语言给出反馈,例如,“the Ant’s torso should be top down, not bottom up”。然后TEXT2REWARD将重新生成奖励代码,并训练出一个新的策略,成功满足了用户的意图。
TEXT2REWARD可以根据人类反馈改进RL训练。
由于RL训练的敏感性,有时 single-turn generation 不能生成足够好的奖励函数来完成任务。在这些情况下,TEXT2REWARD会询问人类对 failure mode 的反馈,并尝试改进 dense reward。在Figure7中,本文以 Stack Cube 任务为例展示了这一点,这里在单轮(single turn)中零样本(zero-shot)和少样本(few-shot)生成均未能稳定地解决该任务。对于 few-shot 生成,本文观察到带有人工反馈的交互式 code generation 可以将成功率 from zero to one,并加快训练的收敛速度。然而,这种改进容易受到最初(i.e. iter0)生成的奖励函数的质量的影响。对于质量相对较低的奖励函数(例如零样本生成代码),经过多次反馈迭代后成功率的提升不如少样本生成代码那样明显。该问题可以通过 sparse-to-dense 的奖励函数生成方式来解决,即首先生成 stage reward 然后interactively地生成reward terms。本文将这种范式(paradigm)留作未来可能的研究方向。
4.2 定性分析
本节总结了生成的奖励函数(zero-shot, few-shot)和oracle奖励函数之间的差异。由于篇幅所限,本文将引用到的奖励函数放在附录D中。
少样本优于零样本
在下游任务的表现上,few-shot 设置通常优于 zero-shot 设置。在 Lift Cube and Pick Cube 任务中,few-shot generated 的代码使用 conditional statements 更清楚地描述了各个阶段—— approach, grasp, and lift。相比之下,zero-shot代码以线性方式 stacks and sums 对不同阶段的奖励,降低了有效性。在 Push Chair 任务中也体现了这一点,该任务需要nuanced常识性步骤,而 zero-shot 代码只能部分捕捉到这些步骤。由于阶段奖励格式在少样本示例中进行了展示,GPT-4能够将这种模式泛化到新任务上。目前,即使指导它这样做,这种能力也无法在 zero-shot 中完全展现出来,这可能会随着LLMs的出现而得到改善。
零样本有时会优于少样本
实验还表明,zero-shot学习偶尔会优于few-shot学习,这在诸如 Turn Faucet 和 Open Doors 等任务中可以看到。通过检查生成的代码,本文发现少样本示例的质量(quality)和相关性(relevance)是关键因素。例如,在 Open Door 任务中,few-shot学习表现落后,因其忽略了一个关键的奖励项 - 门的位置变化 - 从而阻碍了学习。类似地,在 Turn Faucet 任务中,zero-shot奖励通过允许单侧抓手动作从而更容易成功,这带来了更好的效果。
零样本有时会优于范例
在某些情况下,few-shot学习甚至比专家精心制作的oracle奖励函数更好。对 Open Door 任务奖励函数的分析表明,few-shot 生成的代码省略了稳定门的最后阶段,简化了策略学习过程,改善了学习曲线,并以略微不同的manner完成任务。在 Pick Cube 任务中,few-shot and oracle codes 在结构上是相似的,但 weight terms 不同。这表明LLMs不仅可以改进奖励结构和逻辑,而且还可以调整超参数。虽然这不是本文关注的重点,但它可能是一个有前途的方向。
5 相关工作
奖励构造
Reward shaping 在强化学习(Reinforcement Learning, RL)领域一直是一个persistent挑战。传统上,人们会采用人工制定的奖励函数,但是制定精确的奖励函数是一个耗时的过程,需要专业知识。逆向强化学习(Inverse reinforcement learning, IRL)作为一个潜在的解决方案出现,它从专家轨迹(expert trajectories)中恢复一个非线性奖励模型来促进强化学习(Ziebart et al., 2008_Maximum_Entropy; Wulfmeier et al., 2016_Deep_Inverse_Reinforcement_Learning; Finn et al., 2016_Guided_Cost_Learning)。然而,这种技术需要大量高质量的轨迹数据,这对于复杂(complex)和罕见(rare)的任务来说可能难以获得。另一种方法是偏好学习,它基于人类偏好开发奖励模型(Christiano et al., 2017_Human_Preferences; Ibarz et al., 2018_Reward_Learning; Lee et al., 2021_PEBBLE; Park et al., 2022_SURF; Zhu et al., 2023_Feedback_from_Comparisons)。在这种方法中,人类区分动作对(pairs of actions)之间的偏好,然后使用偏好数据(preference data)构建奖励模型。尽管如此,这种策略仍然需要一些人工标注的偏好数据,而这些数据在某些情况下是既昂贵又难以收集的。这两种常见的奖励构造方法都需要大量高质量的数据,于是泛化性不佳且效率低下。相比之下,TEXT2REWARD在limited(或甚至zero)数据输入的情况下表现出色,并且可以轻松地推广到environment中的新任务。
强化学习中的语言模型
大语言模型(Large Language Models, LLMs)展现出了出色的推理(reasoning)和规划(planning)能力(Wei et al., 2022_Chain-of-Thought; Huang et al., 2022a_Zero-Shot_Planners)。近期的工作表明,LLMs中的知识能有助于RL,并且可以transform获取数据驱动的策略网络paradigm(Carta et al., 2023_Grounding_Large_Language_Models; Wu et al., 2023_Read_and_Reap)。这一趋势使得基于LLM的自主智能体(agents)逐渐成为主流,越来越多的方法在强化学习过程中使用LLMs作为策略网络,表明这一领域具有良好的发展前景(Yao et al., 2022_ReAct; Shinn et al., 2023_Reflexion; Lin et al., 2023_SwiftSage; Wang et al., 2023_Voyager; Xu et al., 2023_ReWOO; Yao et al., 2023_Retroformer; Hao et al., 2023_LLM-reasoners)。不同于直接使用LLMs作为策略模型或奖励模型,TEXT2REWARD生成成形的密集奖励代码来训练RL策略,这在智能体模型类型的灵活性和推理效率方面具有优势。
机器人领域的语言模型
将LLMs用于具身应用已成为一个时兴的研究趋势,典型的研究方向包括通过 language model generation(Ahn et al., 2022_Robotic_Affordances; Zeng et al., 2022_Socratic_Models; Liang et al., 2022_Code_as_Policies; Huang et al., 2022b_Inner_Monologue; Singh et al., 2023_ProgPrompt; Song et al., 2022_LLM-Planner)进行planning和reasoning。近期的工作已经使用LLMs的能力来辅助学习primitive任务(Brohan et al., 2022_RT1; Huang et al., 2023_VoxPoser; Brohan et al., 2023_RT2; Mu et al., 2023_EmbodiedGPT),通过在 robotic trajectories 上微调LLMs来预测primitive动作,而TEXT2REWARD则是生成奖励代码来学习较小的策略网络。近期一项工作L2R将奖励生成(reward generation)和模型预测控制(Model Predictive Control, MPC)相结合来合成机器人动作。尽管这些奖励在设计良好的MPC下对许多任务都能很好地工作,但本文的实验表明,对未经构造的奖励进行强化学习训练是具有挑战性的,尤其是在复杂的任务中。与这些方法不同,TEXT2REWARD采用了更灵活的程序结构,如 if-else conditions and point cloud queries,以提供更高的灵活性,并 work for 那些unshaped密集奖励常常失败的任务。
6 结论
本文提出了TEXT2REWARD,这是一个interactive的奖励代码生成框架,它使用LLMs来自动化强化学习的reward shaping。本文的实验展示了所提方法的有效性,因为用本文生成的奖励代码训练的RL策略在大多数任务中能够match甚至surpass专家设计的代码。本文还通过在真实机器人上部署在模拟器中训练的策略,展示了该方法的实际应用性(real-world applicability)。通过引入人类反馈,本文的方法能够迭代优化生成的奖励代码,解决了语言描述中的模糊性问题,并提高了学习策略的成功率。这种交互式学习过程能够更好地与人类需求和偏好对齐,从而提供更robust和efficient的强化学习解决方案。
总之,TEXT2REWARD展示了如何通过自然语言将人类意图和大语言模型的知识转化为奖励函数,进而转化为策略函数。本文希望这份工作能够激励来自不同领域的研究者,包括但不限于强化学习和代码生成,进一步探索这一充满前景的交叉领域,并为这些领域的持续研究进展做出贡献。

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









