






十、模型优化技术
模型压缩方法包括:(a)剪枝、(b)量化和(c)知识蒸馏。
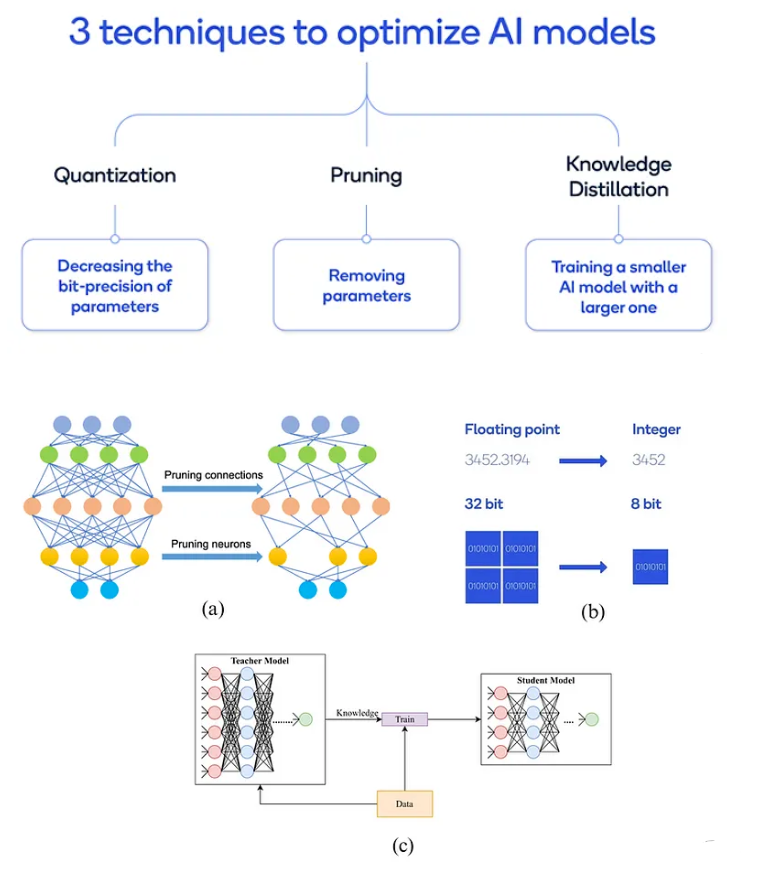
10.1 量化
模型量化是一种用于减小大型神经网络(包括大语言模型LLM)大小的技术,通过修改其权重的精度来实现。大语言模型的量化之所以可行,是因为实证结果表明,虽然神经网络训练和推理的某些操作必须使用高精度,但在某些情况下,可以使用低得多的精度(例如float16),这可以减小模型的整体大小,使其能够在性能和准确性可接受的情况下,在性能较弱的硬件上运行。
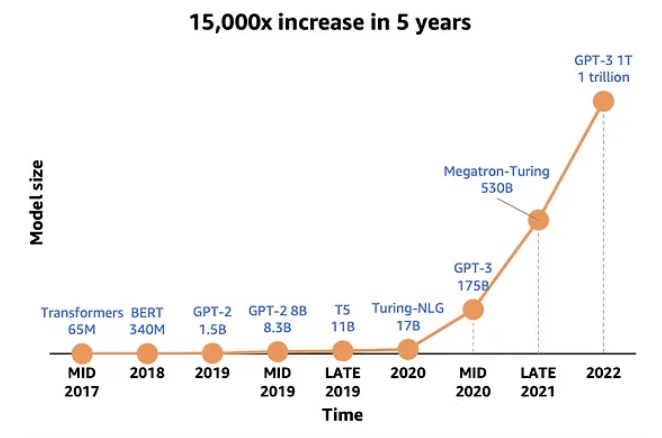
模型大小的趋势
一般来说,在神经网络中使用高精度与更高的准确性和更稳定的训练相关。使用高精度在计算上也更为昂贵,因为它需要更多且更昂贵的硬件。谷歌和英伟达的相关研究表明,神经网络的某些训练和推理操作可以使用较低的精度。
除了研究之外,这两家公司还开发了支持低精度操作的硬件和框架。例如,英伟达的T4加速器是低精度GPU,其张量核心技术比K80的效率要高得多。谷歌的TPU引入了bfloat16的概念,这是一种为神经网络优化的特殊基本数据类型。低精度的基本思想是,神经网络并不总是需要使用64位浮点数的全部范围才能表现良好。

bfloat16数值格式
随着神经网络越来越大,利用低精度的重要性对使用它们的能力产生了重大影响。对于大语言模型来说,这一点更为关键。
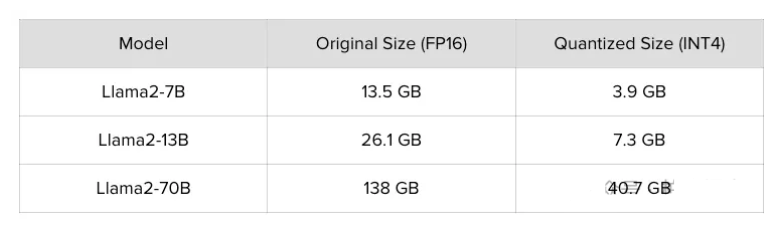
英伟达的A100 GPU最先进的版本有80GB内存。在下面的表格中可以看到,LLama2 - 70B模型大约需要138GB内存,这意味着要部署它,我们需要多个A100 GPU。在多个GPU上分布模型不仅意味着要购买更多的GPU,还需要额外的基础设施开销。另一方面,量化版本大约需要40GB内存,因此可以轻松地在一个A100上运行,显著降低了推理成本。这个例子甚至还没有提到在单个A100中,使用量化模型会使大多数单个计算操作执行得更快。
使用llama.cpp进行4位量化的示例,大小可能会因方法略有不同
-
量化如何缩小模型?:量化通过减少每个模型权重所需的比特数来显著减小模型的大小。一个典型的场景是将权重从FP16(16位浮点数)减少到INT4(4位整数)。这使得模型可以在更便宜的硬件上运行,并且 / 或者运行速度更快。然而,降低权重的精度也会对大语言模型的整体质量产生一定影响。研究表明,这种影响因使用的技术而异,并且较大的模型对精度变化的影响较小。较大的模型(超过约700亿参数)即使转换为4位,也能保持其性能,像NF4这样的一些技术表明对其性能没有影响。因此,对于这些较大的模型,4位似乎是在性能与大小 / 速度之间的最佳折衷,而6位或8位可能更适合较小的模型。
-
大语言模型量化的类型:获得量化模型的技术可以分为两类。
-
训练后量化(PTQ):将已经训练好的模型的权重转换为较低精度,而无需任何重新训练。虽然这种方法简单直接且易于实现,但由于权重值精度的损失,可能会使模型性能略有下降。
-
量化感知训练(QAT):与PTQ不同,QAT在训练阶段就整合了权重转换过程。这通常会带来更好的模型性能,但计算要求更高。一种常用的QAT技术是QLoRA。
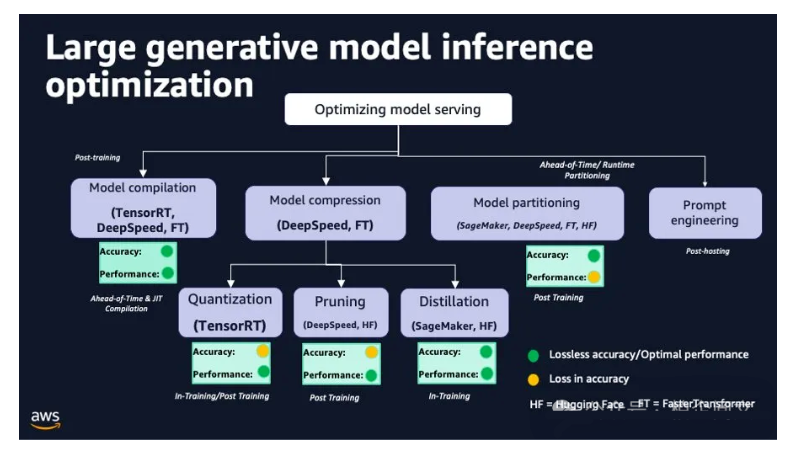
本文将只关注PTQ策略及其关键区别。
-
更大的量化模型与更小的未量化模型:我们知道降低精度会降低模型的准确性,那么你会选择较小的全精度模型,还是选择推理成本相当的更大的量化模型呢?尽管理想的选择可能因多种因素而异,但Meta的最新研究提供了一些有见地的指导。虽然我们预期降低精度会导致准确性下降,但Meta的研究人员已经证明,在某些情况下,量化模型不仅表现更优,而且还能减少延迟并提高吞吐量。在比较8位的130亿参数模型和16位的70亿参数模型时,也可以观察到相同的趋势。本质上,在比较推理成本相似的模型时,更大的量化模型可以超越更小的未量化模型。随着网络规模的增大,这种优势更加明显,因为大型网络在量化时质量损失较小。
-
在哪里可以找到已经量化的模型?:幸运的是,在Hugging Face Hub上可以找到许多已经使用GPTQ(有些与ExLLama兼容)、NF4或GGML进行量化的模型版本。快速浏览一下就会发现,这些模型中有很大一部分是由大语言模型社区中一位有影响力且备受尊敬的人物TheBloke量化的。该用户发布了多个使用不同量化方法的模型,因此人们可以根据具体的用例选择最合适的模型。要轻松试用这些模型,可以打开一个Google Colab,并确保将运行时更改为GPU(有免费的GPU可供使用)。首先安装Hugging Face维护的transformers库以及所有必要的库。由于我们将使用由Auto - GPTQ量化的模型,因此还需要安装相应的库:
!pip install transformers
!pip install accelerate
!pip install optimum
!pip install auto - gptq
你可能需要重新启动运行时,以便安装的库可用。然后,只需加载已经量化的模型,这里我们加载一个之前使用Auto - GPTQ量化的Llama - 2 - 7B - Chat模型,如下所示:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
- 量化大语言模型:如前所述,Hugging Face Hub上已经有大量量化模型,在许多情况下,无需自己压缩模型。然而,在某些情况下,你可能希望使用尚未量化的模型,或者你可能希望自己压缩模型。这可以通过使用适合你特定领域的数据集来实现。为了演示如何使用AutoGPTQ和Transformers库轻松量化模型,我们采用了Optimum(Hugging Face用于优化训练和推理的解决方案)中简化版的AutoGPTQ接口:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
模型压缩可能很耗时。例如,一个1750亿参数的模型至少需要4个GPU小时,尤其是使用像 “c4” 这样的大型数据集时。值得注意的是,量化过程中的比特数或数据集可以通过GPTQConfig的参数轻松修改。更改数据集会影响量化的方式,因此,如果可能的话,使用与推理时看到的数据相似的数据集,以最大化性能。 6. 量化技术:在模型量化领域已经出现了几种最先进的方法。让我们深入了解一些突出的方法:
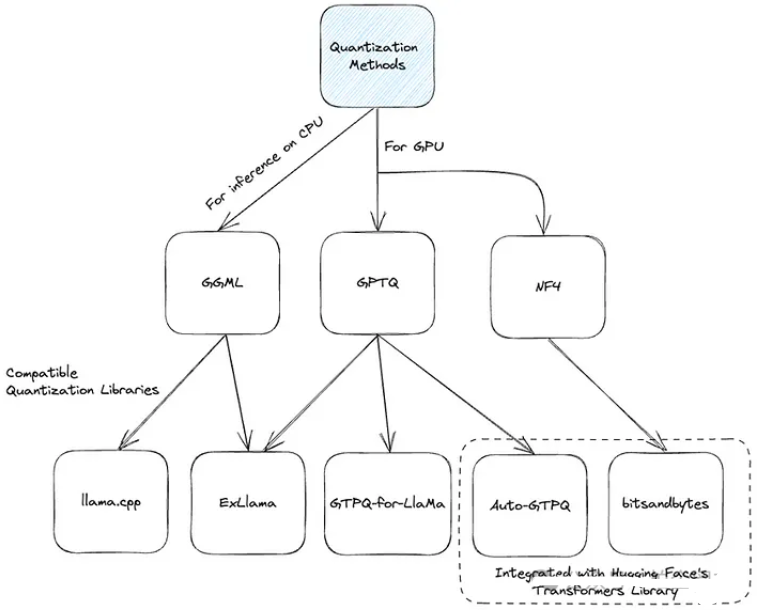
- GPTQ:有一些实现选项,如AutoGPTQ、ExLlama和GPTQ - for - LLaMa,这种方法主要侧重于GPU执行。 - NF4:在bitsandbytes库中实现,它与Hugging Face的transformers库紧密合作。它主要被QLoRA方法使用,以4位精度加载模型进行微调。 - GGML:这个C库与llama.cpp库紧密合作。它为大语言模型提供了一种独特的二进制格式,允许快速加载和易于读取。值得注意的是,它最近转换为GGUF格式,以确保未来的可扩展性和兼容性。
许多量化库支持多种不同的量化策略(例如4位、5位和8位量化),每种策略在效率和性能之间都提供了不同的权衡。
10.2 蒸馏
知识蒸馏(KD; Hinton等人,2015年;Gou等人,2020年)Distilling the Knowledge in a Neural Network[11]是一种构建更小、成本更低模型(“学生模型”)的直接方法,通过将预训练的高成本模型(“教师模型”)的能力转移到学生模型中,来加快推理速度。除了要求学生模型的输出空间与教师模型匹配,以便构建合适的学习目标之外,对学生模型的架构构建方式并没有太多限制。
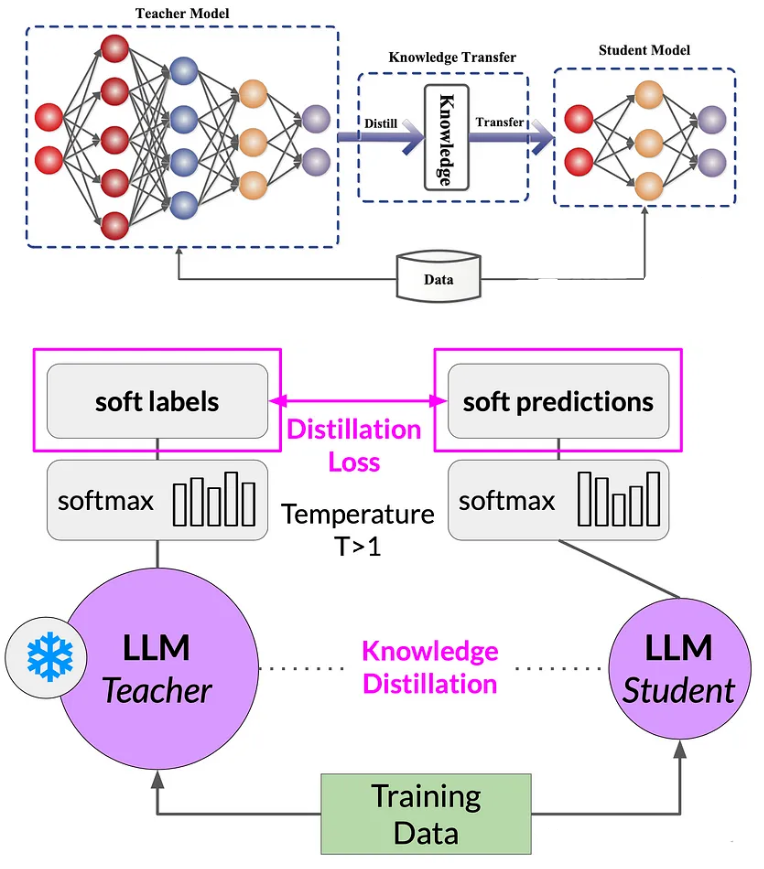
教师模型已经在训练数据上进行了微调,因此,其概率分布可能与真实数据非常接近,并且在生成的token上不会有太多变化。
当温度>1时,概率分布会变得更宽泛。
- T > 1时 => 教师模型的输出 -> 软标签 学生模型的输出 -> 软预测
- T = 1时 => 教师模型的输出 -> 硬标签 学生模型的输出 -> 硬预测
蒸馏对于生成式解码器模型的效果并不显著,它对仅编码器模型(如BERT)更为有效,因为这类模型存在大量的表示冗余。
10.3 剪枝
网络剪枝是指在保持模型能力的同时,通过修剪不重要的模型权重或连接来减小模型大小。这一过程可能需要也可能不需要重新训练。剪枝可分为非结构化剪枝和结构化剪枝。
非结构化剪枝允许删除任何权重或连接,因此不会保留原始网络架构。非结构化剪枝通常与现代硬件的适配性不佳,并且无法真正加快推理速度。
结构化剪枝旨在保持矩阵乘法中部分元素为零的密集形式。为了适配硬件内核的支持,它们可能需要遵循特定的模式限制。这里我们主要关注结构化剪枝,以在Transformer模型中实现高稀疏性。
构建剪枝网络的常规工作流程包含三个步骤:
- 训练一个密集网络直至收敛;
- 对网络进行剪枝,去除不需要的结构;
- 可选步骤,重新训练网络,通过新的权重恢复模型性能 。
通过网络剪枝在密集模型中发现稀疏结构,同时使稀疏网络仍能保持相似性能,这一想法的灵感来源于彩票假设(LTH):一个随机初始化的、密集的前馈网络包含多个子网络,其中只有一部分(稀疏网络)是 “中奖彩票”,当单独训练时,这些子网络能够达到最佳性能。
十一、结论
我们探索了检索增强生成(RAG)应用中的文本生成部分,重点介绍了大语言模型(LLM)的使用。内容涵盖了语言建模、预训练面临的挑战、量化技术、分布式训练方法,以及大语言模型的微调。此外,还讨论了参数高效微调(PEFT)技术,包括适配器、LoRA和QLoRA;介绍了提示策略、模型压缩方法(如剪枝和量化),以及各种量化技术(GPTQ、NF4、GGML)。最后,对用于减小模型大小的蒸馏和剪枝技术进行了讲解。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 7174
7174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









