







01
导读
人类对自身的研究和模仿由来已久,在我国2000多年前的《列子·汤问》里就描述了有能工巧匠制作出会说话会舞动的类人机器人的故事。声音包含丰富的个体特征及情感情绪信息,对话作为人类最常使用亲切自然的交互模式,是连接人与智能世界至关重要的环节。
近日,阿里通义实验室发布并开源了语音大模型项目FunAudioLLM,旨在深化人类与大型语言模型(LLMs)之间的自然语音交互体验。这一框架的核心是两个创新模型:SenseVoice和CosyVoice。
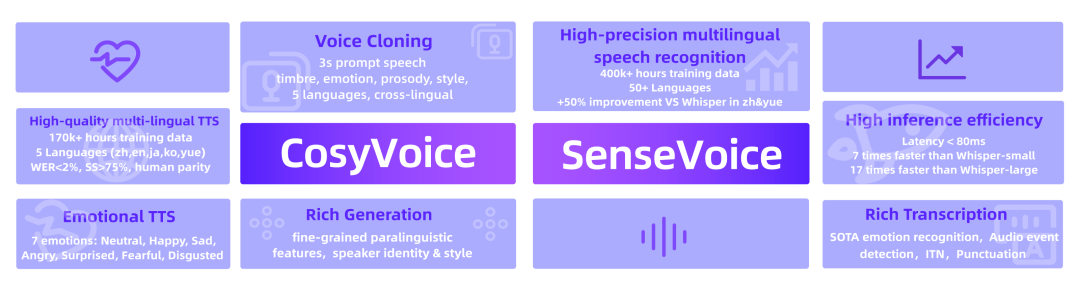
CosyVoice 致力于自然语音生成,支持多语言、音色和情感控制,在多语言语音生成、零样本语音生成、跨语言声音合成和指令执行能力方面表现卓越。
-
多语言合成:采用了总共超15万小时的数据训练,支持中英日粤韩5种语言的合成,合成效果显著优于传统语音合成模型。
-
极速音色模拟:仅需要3~10s的原始音频,即可生成模拟音色,甚至包括韵律、情感等细节。在跨语种的语音合成中,也有不俗的表现。
-
富文本或自然语言的细粒度控制:支持以富文本或自然语言的形式,对合成语音的情感、韵律进行细粒度的控制,合成音频在情感表现力上得到明显提升。
SenseVoice 则专注于高精度多语言语音识别、情感辨识和音频事件检测。
-
多语言识别:采用超过40万小时数据训练,支持超过50种语言,识别效果上优于Whisper模型,中文与粤语上提升50%以上。
-
富文本识别:
-
具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
-
支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
-
推理速度:SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,10s音频推理仅耗时70ms,15倍优于Whisper-large。
02
应用场景
基于SenseVoice和CosyVoice模型,FunAudioLLM可支持较多的人机交互应用场景,例如音色情感生成的多语言语音翻译、情绪语音对话、互动播客、有声读物等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2404
2404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









