






现有的GNN仍受到其本地消息传递体系结构的限制,并且其表达能力受到了可证明的限制。在这项工作中,我们提出了一种新的GNN架构——神经树。神经树结构不在输入图上执行消息传递,而是在从输入图构造的树结构图上执行消息传递,称为H树。H-树中的节点对应于输入图中的子图,它们以分层方式重新组织,使得H-树中节点的父节点始终对应于输入图中较大的子图。我们证明了神经树结构可以逼近无向图上的任何光滑概率分布函数。还证明了实现分布函数的![]() 近似需要参数的数目对输入图的树宽呈指数,对输入图的大小呈线性。我们证明了任何连续的G-不变/等变函数都可以通过G上此类概率分布函数的非线性组合来逼近。通过使用图子抽样技术,我们还展示了神经树结构对大树宽引用网络的适用性。
近似需要参数的数目对输入图的树宽呈指数,对输入图的大小呈线性。我们证明了任何连续的G-不变/等变函数都可以通过G上此类概率分布函数的非线性组合来逼近。通过使用图子抽样技术,我们还展示了神经树结构对大树宽引用网络的适用性。
局部消息传递GNN不能作为所有G-不变(等变)函数的通用近似器。之前工作证明了图同构测试的能力与逼近任何G-不变函数的能力之间的等价性。
需要一种新的方式来看待构建GNN体系结构。数据的图形结构决定了节点及其特征之间的相互依赖关系。概率图形模型为阐明和处理数据中的这种相互依赖关系提供了一种合理且成熟的方法。在神经网络出现之前,基于此类图形模型的推理算法已成功应用于许多实际问题。因此,我们提出,在图形上运行的GNN架构应该至少具有概率图形模型的表达能力,即它应该能够近似概率图形模型定义的任何分布。
概率图形模型上进行精确推理(类似于学习分布或其边缘),而对输入图形没有任何结构约束,被认为是一个NP难问题。即使是概率图形模型上的近似推理,通常也是NP难的。执行精确推理的一个常见技巧是为输入图构建连接树,并在连接树上执行消息传递。在连接树中,每个节点对应于输入图的一个子集。对于树宽有界的图,连接树算法仍然是可处理的,且之前工作表明树宽是唯一的结构参数,给其界限,就允许在图形模型上进行可处理的推理。
本文贡献:1.定义了G-相容函数的概念,认为近似G-相容函数等价于近似概率图形模型上的任何概率分布,G-不变\等变函数可以用G-相容函数的非线性组合来近似。
2.提出了一种新的GNN架构——神经树——它可以近似任何G兼容函数。神经树不在输入图上执行消息传递,而是在由输入图构造的树结构图(称为H树)上执行消息传递。H-树中的每个节点对应于输入图的一个子图。这些子图在H-树中分层排列,使得H-树中节点的父节点始终对应于输入图中较大的子图。H-树中的叶节点对应于输入图的单例子集(即单个节点)。H-树是通过递归计算输入图及其子图的树分解,并将它们彼此连接以形成层次结构来构造的。通过H-树传递的神经信息为输入图的所有节点和重要子图生成表示。
3.之后证明了神经树结构可以逼近给定无向图上定义的任何光滑G-相容函数。还限制了神经树结构所需的参数数量,以获得任意(光滑)G-相容函数的![]() 逼近。证明了参数的数量在输入图的树宽上呈指数增长,但在输入图的大小上仅呈线性增长。因此,对于树宽有界的图,神经树可以容易地逼近任何光滑分布函数。
逼近。证明了参数的数量在输入图的树宽上呈指数增长,但在输入图的大小上仅呈线性增长。因此,对于树宽有界的图,神经树可以容易地逼近任何光滑分布函数。
4.引文网络通常有较大的树宽;因此,我们利用最近提出的有界树宽图子采样算法,对输入图进行子采样(即删除边),以将其树宽减少到指定的数字。我们表明,将神经树结构与这种子采样算法相结合,可以使我们的结构在保持其相对于传统结构的优势的同时,可扩展到大型图。
一般认为,为了提高GNN的表达能力,必须提取与重要子图对应的特征,并对其进行操作。从一开始,图形神经网络就作为函数逼近器被研究
消息传递GNN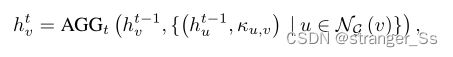
提取节点标签![]()
图兼容函数允许我们与概率图形模型和G-不变/等变函数建立联系。G-相容函数一个函数![]() 与图G兼容或是G兼容的,如果它能分解成
与图G兼容或是G兼容的,如果它能分解成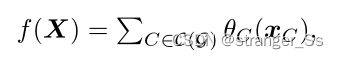 C(G)表示G中所有最大团的集合,θC是映射
C(G)表示G中所有最大团的集合,θC是映射![]() (团C中的节点特征集)到一个实数。相容函数出现在概率图形模型中。
(团C中的节点特征集)到一个实数。相容函数出现在概率图形模型中。
任何连续的G-不变或G-等变函数都可以写成G-相容函数的有限和,每个函数由一个特定的非线性函数组成。一个能逼近任意G-相容函数的GNN结构也能逼近任意图不变和等变函数。
神经树结构
对于图G,树分解是一个元组![]() ,其中
,其中![]() 是一个树图
是一个树图![]() 是一组包,
是一组包,![]() ,
,![]() ,该元组满足以下两个属性:(1)连通性:对于任意
,该元组满足以下两个属性:(1)连通性:对于任意![]()
![]() 是T的连通子图(2)覆盖性:对于G中任意边
是T的连通子图(2)覆盖性:对于G中任意边![]() ,存在一个节点
,存在一个节点![]() 使
使![]()
树分解(T,B)的树宽定义为最大包的大小减去1。图G的树宽定义为G的所有树分解中能达到的最小树宽。用![]() 来代表图G的一个树分解。
来代表图G的一个树分解。
H-树
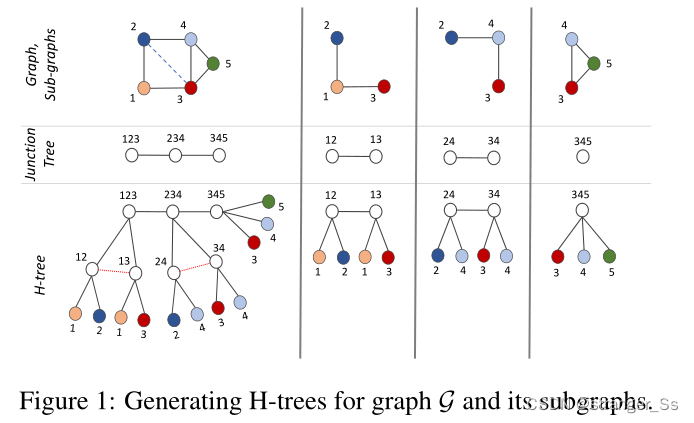
完整图:对于具有n个节点的完整图G,H-树是星型图,根节点表示G中的单个最大团,每个叶节点对应于G中的一个节点。如最左边一列,图中包含节点{3,4,5}的唯一团标记为C=(345)。为了清晰起见,在定义H树时,我们总是使用根节点集。图G的H-树由一个元组(JG,R)给出,JG是树形图,R是根节点集。
H-树是通过递归地对输入图和通过树分解得到的子图应用树分解来计算的。最终的H-树JG是通过将所有获得的树分解连接为一个层次来计算的。

为了避免循环,我们还删除了J'(第12行)中根节点R'之间的边。
H-树(图G的)中的每个节点对应于图G中的一个节点子集。JG中的每个叶节点l对应于G中的一个节点v。对于JG中的每个叶节点l,我们用κ(l)表示该节点。在构建H-树时,我们还将节点输入特征xv分配给JG中的每个节点l,其中κ(l)=v。注意,多个叶节点可能对应于图G中的单个节点v,对于JG中的多个叶节点l,我们可以有κ(l)=v。
H树上的消息传递
给定一个具有输入节点特征的图G,我们构造一个H-树(JG,R),并在JG上执行消息传递。通过聚合JG中相邻节点的表示向量,为H-树JG中的每个节点生成表示向量。
![]()
![]()
![]()
经过T次消息传递迭代后,我们通过组合JG的叶节点l的表示向量提取节点v的标签![]()
![]()
所提出的神经树算法可分为三个步骤,通过从叶节点到H树中的根节点的消息传递、根节点之间的消息传递以及从根节点到叶节点的消息传递















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









