






GNNAutoScale(GAS),是一个将任意MPGNN扩展到大型图的框架。GAS通过利用先前训练迭代中的历史嵌入来修剪计算图的整个子树,从而在不删除任何数据的情况下,保持输入节点大小方面的GPU内存消耗不变。我们的方法可以证明能够保持原始GNN的表达能力。我们通过提供历史嵌入的近似误差范围来实现这一点,并展示如何在实践中收紧它们。
GNN目前困境:很难拓展到大型图上。假设可以访问所有层中的所有隐藏节点嵌入,虽然GNN中的完整梯度很容易计算,但由于GPU内存限制,这在大规模图形中是不可行的。故考虑用随机minibatch近似fullbatch。由于节点对各层的依赖性呈指数级增长,这种随机梯度的获取成本仍然很高。称为邻域爆炸,整个计算图需要存储在GPU上。目的:使内存消耗相对于输入节点的数量保持恒定或次线性,这样就可以扩展到大型图。
解决方案:采样。但其可能无法保留呈现有意义拓扑结构的边。除此外,现有工作大多局限于浅层网络、不可交换的GNN操作,或局限于表达能力降低的GNN操作,或只考虑特定的GNN(无法推广到广泛GNN的框架)。还有一些工作将传播和预测解耦分离,作为预处理或后处理步骤,但其不能应用于任意GNN,因为其传播是不可训练的,因此降低了模型复杂度。一种不同的可伸缩性技术基于孤立地训练每个GNN层的想法。虽然该方案解决了邻居爆炸问题并考虑了所有边,但它无法推断连续层之间的复杂交互。
本文提出了GNNAutoScale(GAS)框架,该框架将GNNs的可伸缩性方面与其底层的消息传递实现分离开来。历史嵌入的概念,其被定义为在之前的训练迭代中获得的节点嵌入。对于给定的小批量节点,GAS修剪GNN计算图,以便仅保留当前小批量中的节点及其直接1跳邻居,而不受GNN深度的影响。历史嵌入充当离线存储,用于准确填写out_of_mini_batch的相互依赖信息。通过与输入节点大小相关的恒定内存消耗,GAS能够将GNN的训练扩展到大型图,同时仍然考虑所有可用的邻域信息。
我们证明了历史信息引起的近似误差完全是由历史的陈旧性和学习函数的Lipschitz连续性引起的,并提出了在实践中收紧已证明界限的解决方案。将可伸缩性与表达性联系起来,并从理论上说明了在何种条件下,历史嵌入允许学习大型图上的表达节点表示。
MPGNN传播规则:
加入历史嵌入:
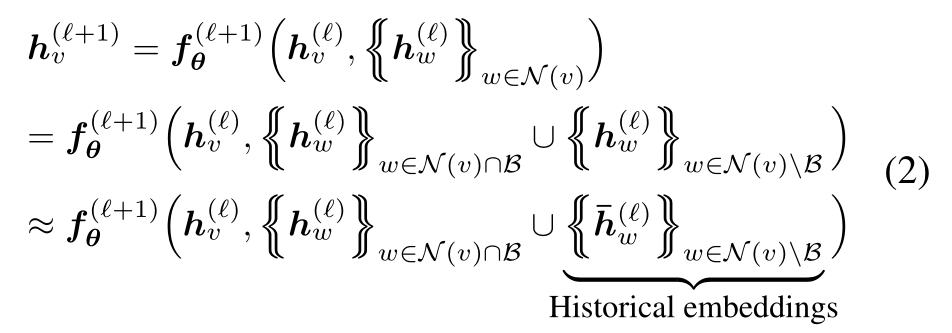
其中![]() ,将邻域的信息分为两部分,(1)邻域信息是当前mini-batch B的一部分(2)邻域信息不包括在当前mini-batch B中。就是将其邻居分成两种,一种是属于mini-batch的,另一种不属于mini-batch。对于out-of-mini-batch的节点,我们通过在之前的训练迭代中获得的历史嵌入来近似它们的嵌入,表示为
,将邻域的信息分为两部分,(1)邻域信息是当前mini-batch B的一部分(2)邻域信息不包括在当前mini-batch B中。就是将其邻居分成两种,一种是属于mini-batch的,另一种不属于mini-batch。对于out-of-mini-batch的节点,我们通过在之前的训练迭代中获得的历史嵌入来近似它们的嵌入,表示为![]() 。每一步训练结束,新得到的嵌入
。每一步训练结束,新得到的嵌入![]() 都会被推入到历史中作为未来迭代的历史嵌入
都会被推入到历史中作为未来迭代的历史嵌入![]() 。
。
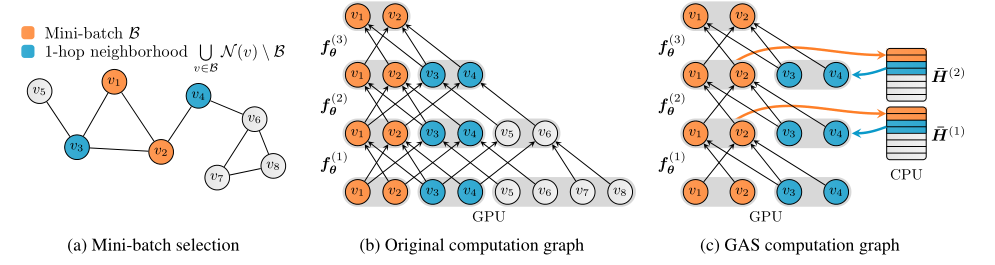
其中橙色代表当前mini-batch中的节点,蓝色代表这些节点的直接1跳邻居。图(b)显示GPU内存和计算成本随着GNN深度呈指数增长,即使只考虑一小批节点进行损失计算,在经过几层后,可能整个输入图的嵌入都需要存储。引入历史嵌入,通过近似整个子树来解决此问题,所需的历史嵌入是从脱机/离线存储中提取的,而不是在每次迭代中重新计算,从而将每个batch的所需信息保存在本地。图(c)显示与输入节点大小相关的恒定GPU内存消耗,与深度/层数呈线性比例。当前mini-batch中的节点将其更新的嵌入推送到历史“H”,而其直接邻居则从“H”中提取其最新的历史嵌入以进行进一步处理。
用![]() 代表经由GAS估计的嵌入,以将其与未经历史近似获得的精确嵌入区分开来。与现有的基于子采样边的缩放解决方案相比,在GAS中使用的历史嵌入提供了以下额外优势:
代表经由GAS估计的嵌入,以将其与未经历史近似获得的精确嵌入区分开来。与现有的基于子采样边的缩放解决方案相比,在GAS中使用的历史嵌入提供了以下额外优势:
(1)在所有数据上训练,在GAS中,GNN将利用所有可用的图信息,即没有边被dropped,这会导致更低的方差和更准确的估计。对于单一循环中单一层,每个边只被使用一次。更精确的估计将进一步加强反向传播期间的梯度估计。
(2)保持恒定的推理时间复杂性,由于我们可以直接使用最后一层的历史嵌入来推导测试节点的预测,因此模型推理的时间复杂度降低到一个常数因子。
(3)实现简单
(4)有理论保证,如果模型权重固定,经过固定数量的迭代后,![]() 会等于
会等于![]()
利用历史嵌入![]() 计算精确嵌入
计算精确嵌入![]() 的近似
的近似![]() 。近似误差
。近似误差![]() 可以分解为两个方差来源(1)估计输入值与其精确值的接近程度,即
可以分解为两个方差来源(1)估计输入值与其精确值的接近程度,即![]()
(2)历史嵌入的陈旧性,即![]()















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









