







 本文介绍了用于途中行程时间估计的自适应元学习模型MetaER-TTE。该模型针对现有方法在数据稀疏和轨迹特征差异问题上的不足,采用软聚类、聚类感知参数存储器和学习率生成器等技术。通过在两个真实数据集上实验,证明其能有效提高行程时间估计的准确性。
本文介绍了用于途中行程时间估计的自适应元学习模型MetaER-TTE。该模型针对现有方法在数据稀疏和轨迹特征差异问题上的不足,采用软聚类、聚类感知参数存储器和学习率生成器等技术。通过在两个真实数据集上实验,证明其能有效提高行程时间估计的准确性。
2022 [IJCAI] MetaER-TTE:用于途中行程时间估计的自适应元学习模型
论文标题: MetaER-TTE: An Adaptive Meta-learning Model for En Route Travel Time Estimation
作者: Yu Fan, Jiajie Xu* , Rui Zhou , Jianxin Li , Kai Zheng, Lu Chen, Chengfei Liu
机构: 苏州大学 ,斯威本科技大学,迪肯大学,电子科技大学
发表: the 31st International Joint Conference on Artificial Intelligence (IJCAI 2022)
引用格式:Fan Y, Xu J, Zhou R, et al. MetaER-TTE: An Adaptive Meta-learning Model for En Route Travel Time Estimation[C]//Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence. 2022, 23: 2023-2029.
**论文链接:**https://www.ijcai.org/proceedings/2022/0281

TL,DR:
0. 论文概述
途中行程时间估计(ER-TTE)旨在预测剩余路线的行程时间。由于行程的已行驶部分和剩余部分通常具有一些共同特征,例如行驶速度,因此需要探索这些特征以通过有效的适应来提高性能。由于行进的部分轨迹中的采样点很少,这仍然面临着数据稀疏的严重问题。由于具有不同上下文信息的轨迹往往具有不同的特征,现有的 ER-TTE 元学习方法不能很好地拟合每个轨迹,因为它对所有轨迹使用相同的模型。为此,本文提出了一种新的自适应元学习模型,称为 MetaER-TTE。利用软聚类并派生聚类感知的初始化参数,以更好地在具有相似上下文信息的轨迹之间传输共享知识。此外,采用分布感知方法进行自适应学习率优化,以避免在不平衡分布下的任务中用固定学习率引导初始参数时出现的任务过拟合。最后,进行了全面的实验来证明MetaER-TTE的优越性。
1. 问题动机
- 路线前行程时间估计(pre-route travel time estimation, PR-TTE)的问题:尽管 PR-TTE 方法也可以支持 ER-TTE,但它们不考虑行驶路线,从而导致结果次优。
- 途中行程时间估计遇到的问题:由于行驶路线中采样点较少而导致冷启动问题。
元学习的方法可以解决这个问题,首先通过元学习学习一个更通用的 ER-TTE 模型,然后通过对行驶路线进行微调,可以快速调整该通用模型来估计剩余路线的行驶时间。
- 现有采用元学习的方法的问题:
- 现有元学习用全局共享的参数设置不太可能在 ER-TTE 中获得更好的性能,因为具有不同上下文信息的轨迹往往具有不同的特征,包括行进速度,这将严重影响行进时间。
- 现有方法都基于任务均匀分布的假设,以固定的学习率将初始化的参数适应每个任务。在ER-TTE中,上下文信息分布不均匀会导致适应过程中任务过度拟合。(例如白天和午夜轨迹数量不同,用固定的学习率引导初始化参数往往会过度拟合白天的轨迹,因为这些轨迹占大多数并且拟合它们可以取得良好的平均性能。)
2. 本文贡献
- 提出了一种针对 ER-TTE 的自适应元学习方法,该方法支持对每个轨迹进行个性化适应,以实现更准确的估计。
- 采用软聚类方法来导出聚类感知初始化参数,以便更好地在具有相似上下文信息的轨迹之间传输共享知识。
- 学习率生成器进一步设计为以合理的分布感知学习率自适应地引导每个轨迹的全局初始参数,以防止任务过度拟合。
- 对两个真实世界的数据集进行了广泛的实验,以证明方法的有效性。
3. 问题定义
轨迹 t t t 定义为路段序列,即 t = { r 1 , r 2 , . . . , r n } t = \{r_1, r_2, ..., r_n\} t={r1,r2,...,rn},其中 r i r_i ri 是该轨迹中的第 i i i 个路段。
将全部轨迹分为2类:
出行过程中已经采集到的出行路线: t t r = { r 1 , r 2 , . . . , r m } , m < n t_{tr}=\{r_1, r_2, ..., r_m\},m<n ttr={r1,r2,...,rm},m<n
剩余的路线: t r e = { r m + 1 , r m + 2 , . . . , r n } t_{re}=\{r_{m+1}, r_{m+2}, ..., r_n\} tre={rm+1,rm+2,...,rn}
ER-TTE任务目标:利用已行驶路线来估计剩余路线的行驶时间。
元学习设置:每个轨迹都被视为一个学习任务。轨迹分为训练集 T t r a i n \mathcal{T}^{train} Ttrain和测试集 T t e s t \mathcal{T}^{test} Ttest,对于每个轨迹 t t t,为了充分利用行驶路线中的时间标签,生成子轨迹 t t r = { r 1 , . . . , r m ∗ 20 % } , t t r = { r 1 , . . . , r m ∗ 40 % } , . . . , and t t r = { r 1 , . . . , r m } t_{tr}=\{r_1, ..., r_{m* 20\%}\},t_{tr}=\{r_1, ..., r_{m*40\%}\},...,\text{and} t_{tr}=\{r_1,..., r_m\} ttr={r1,...,rm∗20%},ttr={r1,...,rm∗40%},...,andttr={r1,...,rm}行程支持集 D s D^s Ds。支持集中的每个子轨迹都有一个行程时间,将剩余的路线作为查询集 D q D^q Dq。
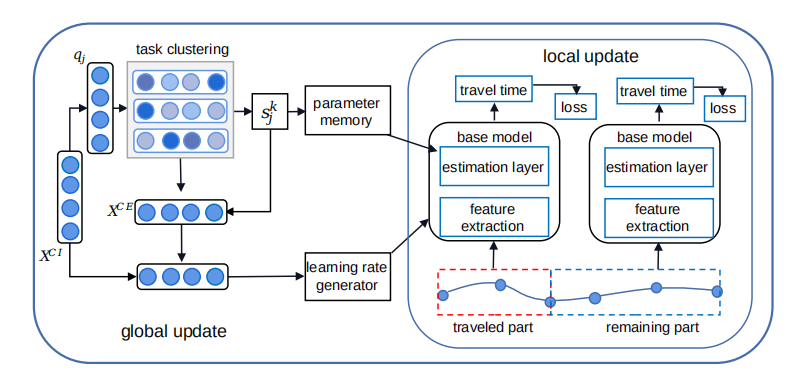
4. 模型架构
本文提出的方法是ER-TTE的自适应元学习(meta-learning)模型,称为MetaER-TTE。首先,介绍名为 ConSTGAT[2020 KDD]的基础模型 。是一种最先进的 TTE 方法,结合路段关系和交通预测来估计出行时间。其次,介绍了 MetaER-TTE 模型的详细信息,该模型支持有效适应每个轨迹,以在 ER-TTE 中实现更好的性能。
4.1 基础模型
采用百度在2020 KDD发表的ConSTGAT作为基础模型。对于每个路段
r
i
r_i
ri,学习其上下文表示
X
i
C
I
X^{CI}_i
XiCI,例如出发时间,工作日情况和天气情况。预测交通情况
X
i
T
C
X^{TC}_i
XiTC并捕获空间相关性
X
i
S
C
X^{SC}_i
XiSC。组合这些信息来估计
r
i
r_i
ri的行程时间。
y
^
i
=
F
C
θ
e
s
t
(
(
X
i
C
I
⊕
X
i
T
C
⊕
X
i
S
C
)
)
\hat y_i=FC_{\theta^{est}}((X^{CI}_i\oplus X^{TC}_i\oplus X^{SC}_i))
y^i=FCθest((XiCI⊕XiTC⊕XiSC))
其中
θ
e
s
t
∈
R
d
e
s
t
\theta^{est}\in \mathbf{R}^{d_{est}}
θest∈Rdest表示估计层的参数。
⊕
\oplus
⊕表示张量连接。将各路段的预测出行时间相加,得到整条路线的预测出行时间。为获得3个表示
X
i
C
I
,
X
i
T
C
,
X
i
S
C
X^{CI}_i,X^{TC}_i,X^{SC}_i
XiCI,XiTC,XiSC的参数的网络参数记作
θ
∗
\theta^*
θ∗。基础模型的参数表示为:
θ
=
{
θ
∗
,
θ
e
s
t
}
\theta=\{\theta^*,\theta^{est}\}
θ={θ∗,θest}。
最后,ConSTGAT分别用Huber损失和绝对百分比误差(APE)计算路段
L
r
i
L_{r_i}
Lri和整条路线
L
t
j
L_{t_j}
Ltj的损失,并将它们组合起来得到联合损失:
L
j
o
i
n
t
=
1
h
∑
j
=
1
h
(
1
n
(
j
)
∑
i
=
1
n
(
j
)
L
r
i
+
L
t
j
)
L_{joint}=\frac{1}{h}\sum_{j=1}^{h}(\frac{1}{n^{(j)}}\sum_{i=1}^{n^{(j)}}L_{r_i}+L_{t_j})
Ljoint=h1j=1∑h(n(j)1i=1∑n(j)Lri+Ltj)
其中
h
h
h表示所有的路线数,
n
(
j
)
n{^{(j)}}
n(j)路线
t
j
t_j
tj中的路段数。
4.2 元优化(Meta Optimization)
针对ER-TTE的自适应元学习框架MetaER-TTE,初始化参数为 ϕ ∗ \phi^* ϕ∗支持对每个轨迹的适应,主要分为3个部分:任务聚类(task-clustering),聚类感知参数存储器(cluster-aware parameter memory)和学习率生成器(learning rate generator)。首先根据上下文信息将轨迹聚类为几个类别,然后导出聚类感知初始化参数,以便使用聚类感知参数存储器进行个性化估计。此外,学习率生成器为不同的轨迹提供不同的学习率,以自适应地将广义知识引导到每个轨迹。
任务聚类(Task-clustering)
利用软聚类方法根据上下文信息将训练轨迹分为几类以实现更好地在具有相似上下文信息的轨迹之间迁移共享知识。由于快速变化的交通状况,具有不同上下文信息的轨迹可能会共享知识。因此采用软聚类而不是硬聚类或分类。例如,受突发交通事故影响,非高峰时段的行驶速度可能与高峰时段一样慢。此外,软聚类可以保证可微性,并确保可以从不同类别的轨迹中集中学习相关知识。
首先,对每个轨迹的每个聚类进行聚类分配。投影上下文信息
X
C
I
∈
R
d
c
i
X^{CI}\in \mathbf{R}^{d_{ci}}
XCI∈Rdci去获取轨迹
t
j
t_j
tj的查询向量
q
j
∈
R
d
q
q_j\in \mathbf{R}^{d_q}
qj∈Rdq。表示为:
q
j
=
W
q
(
X
C
I
)
+
b
q
q_j=W_q(X^{CI})+b_q
qj=Wq(XCI)+bq
其中,
W
q
=
R
d
c
i
×
d
q
,
b
q
∈
R
d
q
W_q=\mathbf{R}^{d_{ci}\times d_q}, b_q\in \mathbf{R}^{d_q}
Wq=Rdci×dq,bq∈Rdq。接着使用查询向量来计算计算它与每个学习到的聚类中心
{
g
k
}
k
=
1
K
\{g_k\}^K_{k=1}
{gk}k=1K相似度得分
s
j
k
s^k_j
sjk
s
j
k
=
exp
(
⟨
q
j
,
g
k
⟩
)
∑
k
=
1
K
exp
(
⟨
q
j
,
g
k
⟩
)
s_{j}^{k}=\frac{\exp \left(\left\langle q_{j}, g_{k}\right\rangle\right)}{\sum_{k=1}^{K} \exp \left(\left\langle q_{j}, g_{k}\right\rangle\right)}
sjk=∑k=1Kexp(⟨qj,gk⟩)exp(⟨qj,gk⟩)
其中,K表示簇数,学习到的相似度得分将用于导出聚类感知的初始化参数以进行个性化行程时间估计,然后获得每个轨迹的聚类增强表示以生成更合理的学习率。在训练之前,我们随机初始化每个聚类中心,并在训练过程中更新聚类中心。
聚类感知参数存储器(Cluster-aware Parameter Memory)
此外,考虑到具有不同上下文信息(例如,出发时间、工作日、天气条件)的轨迹具有不同的特征,利用相同的全局参数来估计所有剩余部分轨迹的旅行时间是不合理的,因为存在来自不同轨迹的多样性。因此设计聚类感知参数存储器 M p ∈ R K × d q × d e s t M_p\in \mathbf{R}^{K\times d_q\times d_{est}} Mp∈RK×dq×dest。旨在存储不同簇的估计层参数。其目的是根据等式计算的相似度得分 s j k s^k_j sjk 为每个轨迹提供个性化的初始化参数。
存储空间
M
p
M_p
Mp具有用于检索存储器的读头和用于更新存储器的写头。轨迹
t
j
t_j
tj检索参数矩阵
M
j
,
p
∈
R
d
q
×
d
e
s
t
M_{j,p}\in \mathbf{R}^{{d_q}\times d_{est}}
Mj,p∈Rdq×dest得到:
M
j
,
p
=
s
j
k
⋅
M
p
M_{j,p}=s_j^k\cdot M_p
Mj,p=sjk⋅Mp
M
j
,
p
M_{j,p}
Mj,p作为估计层的个性化初始参数,以提供更准确的估计,并将在训练过程中本地更新为:
M
P
=
α
⋅
(
s
j
k
⊗
M
j
,
P
)
+
(
1
−
α
)
M
P
M_P=\alpha \cdot\left(s_j^k \otimes M_{j, P}\right)+(1-\alpha) M_P
MP=α⋅(sjk⊗Mj,P)+(1−α)MP
⊗
\otimes
⊗代表张量乘法,
α
\alpha
α表示用于控制将多少新参数信息添加到内存中。这里使用相似度分数
s
j
k
s_j^k
sjk 来确保新信息会被准确地添加到存储器中。
学习率生成器(Learning Rate Generator)
由于轨迹上下文信息分布不均匀,简单地使用与之前的元学习方法相同的学习率将导致ER-TTE中的任务过度拟合。
在 ER-TTE 中,轨迹上下文信息并不总是平衡的。例如,午夜的交通流量比白天低,因此白天收集的轨迹比午夜收集的轨迹多。采用固定的学习率进行适应会导致白天的轨迹过拟合,并且无法在午夜达到其他轨迹的最优参数,因为白天的轨迹占大多数,对其进行拟合可以取得良好的平均性能。为此,提出了学习率生成器,为每个轨迹提供分布感知的学习率。
由于学习率与上下文信息分布相关,因此具有相似上下文信息的轨迹可能具有相似的学习率。仅直接使用轨迹本身的上下文信息不足以生成合理的学习率,最好还考虑相似上下文信息之间的泛化。因此,充分利用聚类来获得簇增强表示,其中包含同一簇中共享的上下文信息。轨迹
t
j
t_j
tj的簇增强表示为
X
C
E
X^{CE}
XCE
X
C
E
=
∑
k
=
1
K
s
j
k
⋅
g
k
X^{CE}=\sum^K_{k=1}s^k_j \cdot g_k
XCE=k=1∑Ksjk⋅gk
接着,结合上下文信息
x
j
C
I
x^{CI}_j
xjCI 和簇增强表示
X
C
E
X^{CE}
XCE 作为参考来获得自适应学习率:
l
r
j
=
F
C
τ
(
X
C
I
⊕
X
C
E
)
l r_j=F C_\tau\left(X^{C I} \oplus X^{C E}\right)
lrj=FCτ(XCI⊕XCE)
其中
F
C
τ
FC_\tau
FCτ 是带有参数
τ
\tau
τ的全连接层,将在全局更新中进行训练。分布感知学习率用于指导初始化参数,从而找到任务自适应参数。
局部更新(Local Update)
传统的模型训练中,神经网络的参数基于大量的训练数据进行初始化并收敛到良好的局部最优。类似地,局部训练的优化目标是通过基于支持集最小化损失函数来更新每个轨迹的局部参数。因此任务
t
j
t_j
tj 的局部参数将更新如下:
θ
j
∗
←
θ
j
∗
−
l
r
j
⋅
∇
θ
j
L
joint
D
s
θ
j
est
←
θ
j
est
−
l
r
j
⋅
∇
θ
j
L
joint
D
s
\begin{gathered} \theta_j^* \leftarrow \theta_j^*-l r_j \cdot \nabla_{\theta_j} L_{\text {joint }}^{\mathcal{D}^s} \\ \theta_j^{\text {est }} \leftarrow \theta_j^{\text {est }}-l r_j \cdot \nabla_{\theta_j} L_{\text {joint }}^{\mathcal{D}^s} \end{gathered}
θj∗←θj∗−lrj⋅∇θjLjoint Dsθjest ←θjest −lrj⋅∇θjLjoint Ds
θ
j
∗
\theta_j^*
θj∗和
θ
j
e
s
t
\theta_j^{est}
θjest分别由全局参数初始化
ϕ
∗
\phi^*
ϕ∗和
M
j
,
p
M_{j,p}
Mj,p得到。
全局更新(Global Update)
在元优化过程中,目标是最小化查询集上的损失函数。所有需要全局更新的参数用
Θ
\Theta
Θ 表示,包括共享的初始参数
ϕ
∗
\phi^*
ϕ∗、用于聚类的参数以及用于知识适应的参数(例如
τ
\tau
τ)。采用一步梯度下降来更新全局参数
Θ
\Theta
Θ 。
Θ
←
Θ
−
γ
∑
t
∈
T
train
∇
Θ
L
joint
D
q
\Theta \leftarrow \Theta-\gamma \sum_{t \in \mathcal{T}^{\text {train }}} \nabla_{\Theta} L_{\text {joint }}^{\mathcal{D}^q}
Θ←Θ−γt∈Ttrain ∑∇ΘLjoint Dq
其中
γ
\gamma
γ是用于更新全局参数初始化的固定学习率。
5. 实验
5.1 数据集
在两个真实轨迹数据集(北京和波尔图)上进行实验。北京数据集中的轨迹采集时间为2016年5月1日至18日。共有1041584条轨迹覆盖路网。 Porto 数据集是公开的,包含 2013 年 7 月 1 日至 2014 年 7 月 1 日生成的 737063 条轨迹。我们将 GPS 轨迹映射到路网上,分别得到两个数据集相应的路段序列。然后,我们删除行驶时间极短(即 < 120 秒)或路段很少(即 <10个)的噪声记录。对于北京数据集,80%的轨迹用于训练模型,其余20%用于测试。对于 Porto 数据集,我们选择最后2个月用于测试模型,剩余10个月用于训练。
5.2 评估指标和配置
使用三个指标来评估我们的方法的性能,包括平均绝对百分比误差(MAPE)、平均平均误差(MAE)和均方根误差(RMSE)。时间间隔设置为30分钟,以避免由于数据稀疏而缺乏历史交通状况。基础模型的其他设置与 ConstGAT 相同。对于每条轨迹,我们将其分为 30% 作为已行驶路线,70% 作为剩余路线,在北京数据集中,已行驶轨迹和剩余轨迹中的平均路段数分别为 15、34 个,在北京数据集中为 14、31 个。波尔图数据集。根据图2中不同簇数的比较,将两个数据集的簇数设置为3。全局更新的初始学习率设置为0.0001。
5.3 Baselines
- DeepTTE: 2018 AAAI
- CompactETA:2020 KDD
- ConstGAT 2020 KDD
- TransferTTE :基于迁移学习,在训练集上训练基本模型 ConstGAT,并在行驶路线上微调模型以进行测试。
- MAML:2017 ICML 是一种经典的元学习方法,旨在从多个任务中学习通用初始化并使其适应新任务。
- SSML:2021 KDD 是一种最先进的 ER-TTE 元学习模型,它旨在学习元知识以快速适应用户的驾驶偏好。
5.4 性能比较
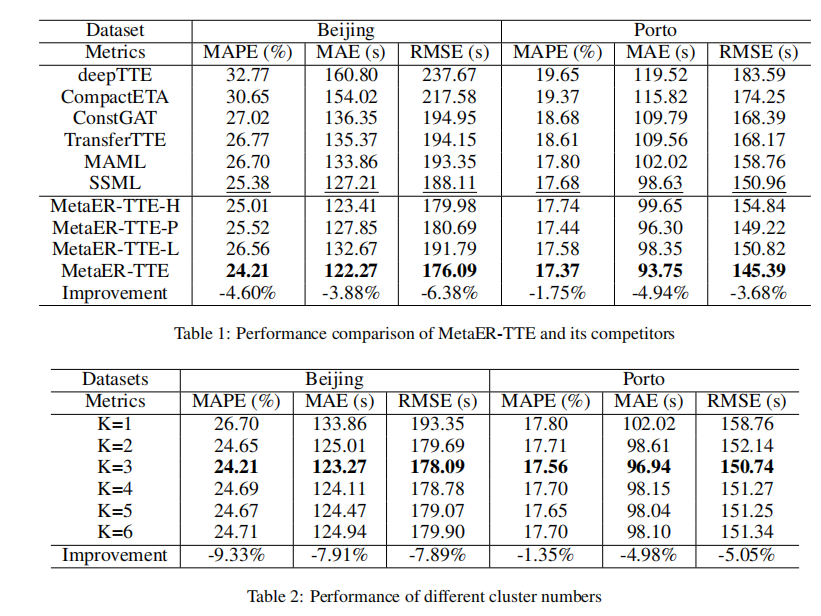
基本模型比较:元学习的框架是基于基本模型。需要选择一个相对较好的基础模型,可以有较好性能。如表1所示,充分利用空间和时间信息的联合关系的ConSTGAT模型具有最好的性能。因此选择ConSTGAT作为基础模型。
元学习策略比较:接下来,评估 ER-TTE 元学习策略的有效性。如表1所示,我们可以观察到TransferTTE的性能优于所有PR-TTE方法,这表明从行驶路线中学习可以提高剩余路线估计的准确性。然后,基于元学习的模型(MAML、SSML、MetaERTTE)在两个数据集上都优于 TransferTTE,这表明元学习可以通过缓解 ER-TTE 中的冷启动问题来进一步提高性能。 SSML 将自监督学习融入元学习范式,其性能比 MAML 好,但比我们的方法差,因为它不能很好地适应每个轨迹。
与变体的比较(消融实验):
-
MetaER-TTE-H 使用硬聚类而不是软聚类方法。簇的数量设置为 3 与我们的模型相同。
-
MetaER-TTE-P 删除了聚类感知参数内存,并在所有轨迹之间传输共享特征,即它们可能具有完全不同的上下文信息。
-
MetaER-TTE-L 删除了该变体中的学习率生成器,并使用设置为 0.00001 的固定学习率使初始化适应每个轨迹。
聚类簇数的影响:表 2 中的改进计算为最佳性能 (K=3) 和 1 个类的性能与该指标上 1 个类的性能之间的差异,以百分比显示。如表 2 所示,K=3 时获得最佳性能。这是因为出发时间在聚类中占主导地位。当K=3时,大致有早高峰、晚高峰和非高峰3类。因此,我们将簇数设置为3。
6. 结论
提出了一种新颖的 ER-TTE 自适应元学习方法,称为 MetaER-TTE。具体来说:
- 在初始化步骤中采用软聚类方法和聚类感知参数存储器来导出聚类感知网络参数,以便更好地在具有相似上下文信息的轨迹之间传输共享特征。
- 此外,为了防止任务过度拟合,设计了一个学习率生成器,以合理的学习率指导每个轨迹的初始化参数。
- 最后,两个真实世界的数据集进行了广泛的实验,以验证我们提出的模型的有效性。
参考文献:
[1] Fang X, Huang J, Wang F, et al. Constgat: Contextual spatial-temporal graph attention network for travel time estimation at baidu maps[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2697-2705.
graph attention network for travel time estimation at baidu maps[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2697-2705.
[2] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//International conference on machine learning. PMLR, 2017: 1126-1135.

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









