







推荐:write_own_pipeline.ipynb - Colab (google.com)
基本管道
一直显示NVIDIA有问题,所以就把.to("cuda")去掉了,使用Colab运行的,代码如下:
from diffusers import DDPMPipeline
ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256", use_safetensors=True)
image = ddpm(num_inference_steps=25).images[0]
image效果如下(有一点点诡异,再配一张好看的图QAQ,毕竟是鼻祖ddpm嘛~)


手撕基本管道

加载模型和调度程序
from diffusers import DDPMScheduler, UNet2DModel scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256") model = UNet2DModel.from_pretrained("google/ddpm-cat-256", use_safetensors=True)话说,这个scheduler和model是干什么的?

设置运行降噪过程的时间步长数
scheduler.set_timesteps(50)
设置调度程序时间步长会创建一个张量,其中的元素分布均匀,在本例中为 50。每个元素对应于模型对图像进行降噪的时间步长。稍后创建去噪循环时,将遍历此张量以对图像进行降噪

产生一些与所需输出形状相同的随机噪声
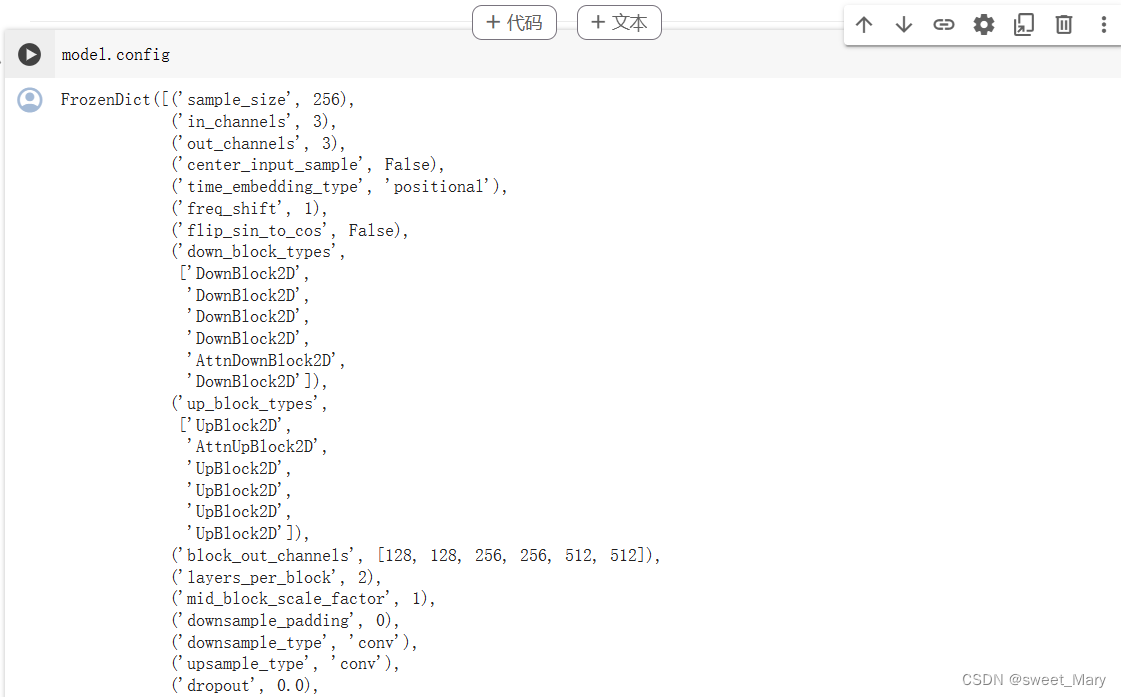
首先来看一下model.config(这里只截取了一部分)
import torch sample_size = model.config.sample_size noise = torch.randn((1, 3, sample_size, sample_size))至于为什么是(1,3,sample_size,sample_size)?

现在编写一个循环来迭代时间步长。在每个时间步,模型都会执行 UNet2DModel.forward() 传递并返回噪声残差。调度程序的 step() 方法采用噪声残差、时间步长和输入,并预测前一个时间步长的图像。此输出成为去噪循环中模型的下一个输入,它将重复直到到达数组的末尾。
input = noise for t in scheduler.timesteps: with torch.no_grad(): #在推理(图像生成)过程中通常不需要进行反向传播。 noisy_residual = model(input, t).sample previous_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample input = previous_noisy_sample这是整个去噪过程,可以使用相同的模式来编写任何扩散系统。
最后一步是将降噪输出转换为图像:
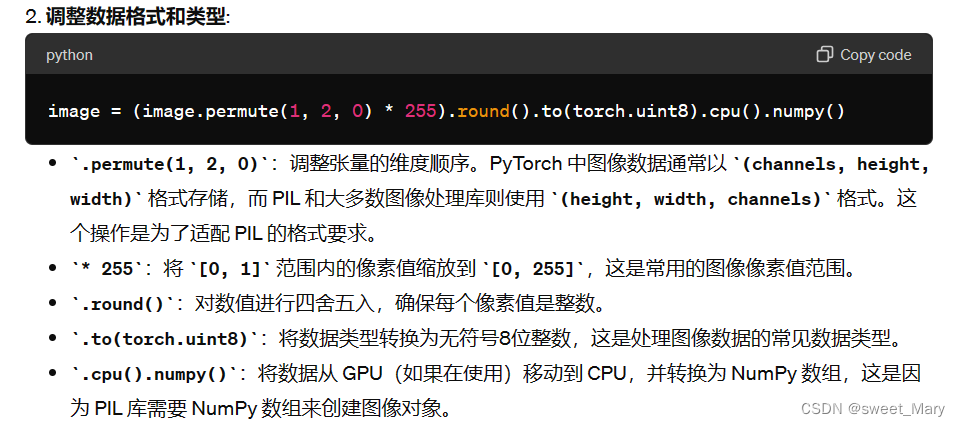
from PIL import Image import numpy as np image = (input / 2 + 0.5).clamp(0, 1).squeeze() image = (image.permute(1, 2, 0) * 255).round().to(torch.uint8).cpu().numpy() image = Image.fromarray(image)
这是猫在睡觉么??


手撕扩散模型流水线
编码器将图像压缩为较小的表示形式,解码器将压缩后的表示形式转换回图像。对于文本到图像模型,需要分词器和编码器来生成文本嵌入。正如你所看到的,这已经比仅包含UNet模型的DDPM管道更复杂。Stable Diffusion 模型有三个独立的预训练模型。
前置知识:




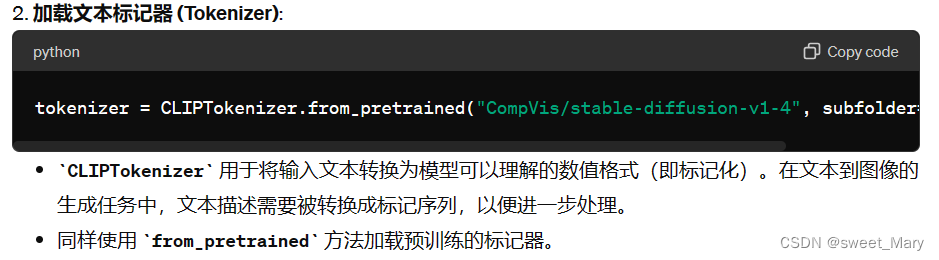
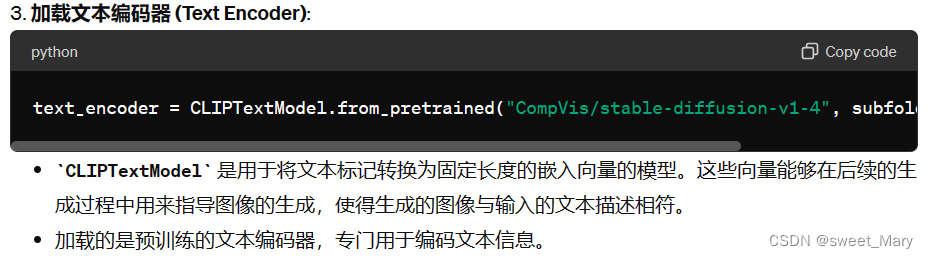
现在,您已经知道了 Stable Diffusion 管道所需的内容,请使用 from_pretrained() 方法加载所有这些组件。您可以在预训练的 runwayml/stable-diffusion-v1-5 检查点中找到它们,每个组件都存储在一个单独的子文件夹中
from PIL import Image import torch from transformers import CLIPTextModel, CLIPTokenizer from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae") tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer") text_encoder = CLIPTextModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="text_encoder") unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")

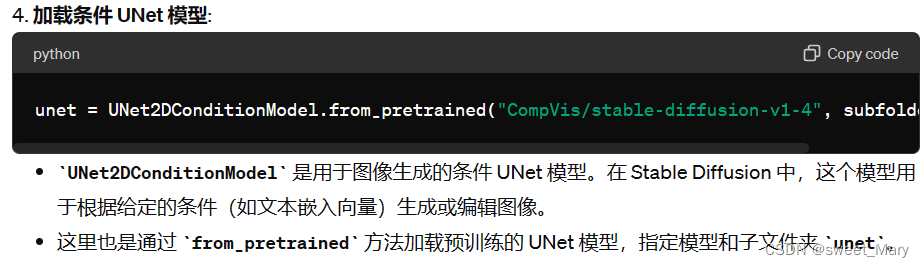
代替默认的 PNDMScheduler,将其换成 UniPCMultistepScheduler,以了解插入其他计划程序是多么容易
from diffusers import UniPCMultistepScheduler scheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
为了加快推理速度,请将模型移动到 GPU
torch_device = "cuda" vae.to(torch_device) text_encoder.to(torch_device) unet.to(torch_device)
创建文本嵌入
下一步是标记文本以生成嵌入。该文本用于调节 UNet 模型,并将扩散过程引导到类似于输入提示的内容。
prompt = ["a photograph of an astronaut riding a horse"] height = 512 # default height of Stable Diffusion width = 512 # default width of Stable Diffusion num_inference_steps = 25 # Number of denoising steps guidance_scale = 7.5 # 在生成图像时应为提示赋予多少权重 generator = torch.manual_seed(0) # 这里通过设置一个固定的种子(seed)值来初始化 PyTorch 的随机数生成器。这确保了每次运行代码时生成的初始潜在噪声(和因此生成的图像)保持一致性,有助于复现结果或调试。 batch_size = len(prompt) # 由于这里只有一个提示文本,批处理大小为 1。
标记文本并从提示生成嵌入:
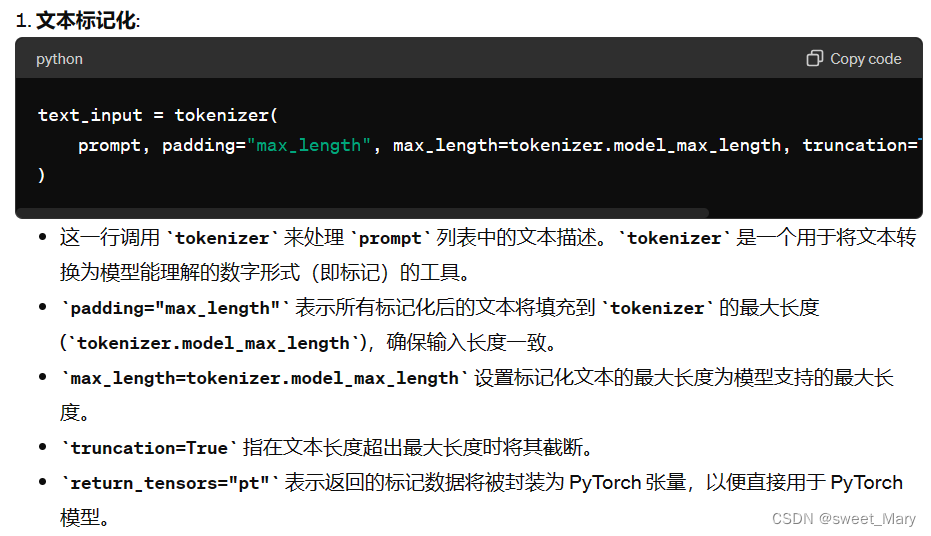
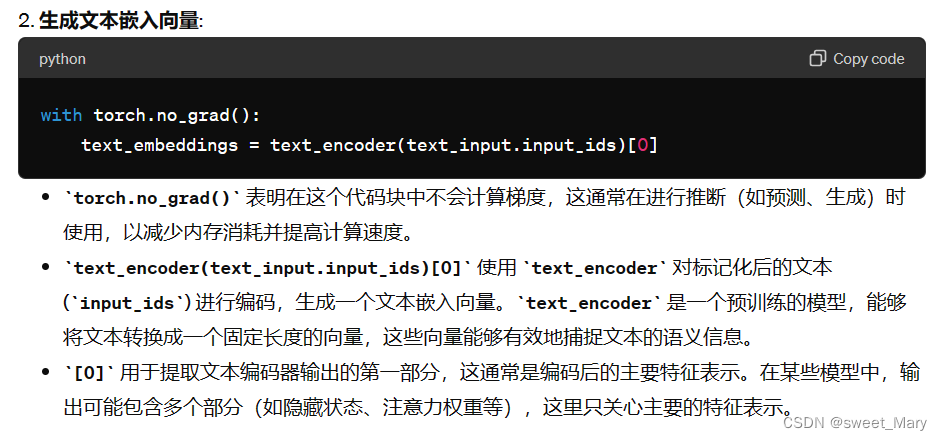
text_input = tokenizer( prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt" ) with torch.no_grad(): text_embeddings = text_encoder(text_input.input_ids)[0]您还需要生成无条件文本嵌入,这些嵌入是填充令牌的嵌入。它们需要具有与条件相同的形状(和):
batch_sizeseq_lengthtext_embeddingsmax_length = text_input.input_ids.shape[-1] uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt") uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]让我们将有条件和无条件嵌入连接到一个批处理中,以避免执行两次前向传递
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
产生随机噪声
接下来,生成一些初始随机噪声作为扩散过程的起点。这是图像的潜在表示,它将逐渐去噪。此时,图像小于最终图像大小,但这没关系,因为模型稍后会将其转换为最终的 512x512 图像尺寸。
共4层,下采样3次
latents = torch.randn( (batch_size, unet.in_channels, height // 8, width // 8), generator=generator, )

对图像进行降噪
首先使用初始噪声分布 sigma(噪声标度值)缩放输入,这是改进的调度程序(如 UniPCMultistepScheduler)所必需的:
latents = latents * scheduler.init_noise_sigma
最后一步是创建去噪循环,该循环将逐步将纯噪声转换为提示描述的图像。请记住,去噪循环需要做三件事:
- 设置调度程序的时间步长以在降噪期间使用。
- 遍历时间步长。
- 在每个时间步,调用 UNet 模型来预测噪声残差,并将其传递给调度程序以计算前一个噪声样本。
from tqdm.auto import tqdm #进度条 scheduler.set_timesteps(num_inference_steps) #设置了模型的时间步长 for t in tqdm(scheduler.timesteps): # expand the latents if we are doing classifier-free guidance to avoid doing two forward passes. '''将潜在变量latents复制一份并与原始的潜变量连接,生成了latent_model_input。这通常用于模型预测时的条件自由引导(classifier-free guidance) ,可以避免进行两次前向传播。接着,scheduler.scale_model_input根据当前时间步t对输入进行缩放,这是控制生成过程中噪声水平的一个重要步骤。''' latent_model_input = torch.cat([latents] * 2) latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t) # predict the noise residual ''' 在这一步中,UNet网络根据当前的潜在输入、时间步和文本嵌入来预测噪声残差。 ''' with torch.no_grad(): noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample # perform guidance ''' 无条件和有条件的预测。通过将它们相减并乘以引导比例(guidance_scale),可以在保留有条件部分的同时减少无条件部分的影响。 ''' noise_pred_uncond, noise_pred_text = noise_pred.chunk(2) noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond) # compute the previous noisy sample x_t -> x_t-1 ''' 根据预测的噪声和当前时间步来更新潜在变量,这一步计算了从当前噪声样本到前一时间步的噪声样本的逆过程。 ''' latents = scheduler.step(noise_pred, t, latents).prev_sample
解码图像
最后一步是使用vae将潜在表示解码为图像,并使用以下命令获得解码后的输出:
vaesample# scale and decode the image latents with vae latents = 1 / 0.18215 * latents with torch.no_grad(): image = vae.decode(latents).sampleimage = (image / 2 + 0.5).clamp(0, 1) image = image.detach().cpu().permute(0, 2, 3, 1).numpy() images = (image * 255).round().astype("uint8") pil_images = [Image.fromarray(image) for image in images] pil_images[0]
Emmmm...















 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









