






动动发财的小手,点个赞吧!
1. 包加载
我们可以使用 rGREAT 包中提供的 GREAT Bioconductor 接口。
library(rGREAT)
2. GO和功能测试
要提交作业,我们可以使用 Myc 峰的 GRanges 并使用 submitGreatJob 函数指定基因组。
此函数返回一个 GreatJob 对象,其中包含对我们在 GREAT 服务器上的结果的引用。要查看可用结果的类别,我们可以在 GreatJob 对象上使用 availableCategories 函数。
great_Job <- submitGreatJob(macsPeaks_GR, species = "mm10", version = "3.0.0", request_interval = 1)
availableCategories(great_Job)

可以使用 getEnrichmentTables 函数检索结果表并指定我们希望查看的表。
在这里,我们检索包含 2 个独立数据库结果的“Regulatory Motifs”基因集的结果表。
great_ResultTable = getEnrichmentTables(great_Job, category = "Regulatory Motifs")
names(great_ResultTable)

现在我们可以在“MSigDB 预测的启动子基序”基因集的 TSS 中使用 Myc 峰查看我们的基因的富集情况。
msigProMotifs <- great_ResultTable[["MSigDB Predicted Promoter Motifs"]]
msigProMotifs[1:4, ]

3. Motifs 分析
3.1. Motifs
转录因子 ChIPseq 的一个常见做法是研究峰下富集的基序。可以在 R/Bioconductor 中进行从头富集基序,但这可能非常耗时。在这里,我们将使用在线提供的 MEME-ChIP 套件来识别新的基序。
MEME-ChIP 需要一个包含峰下序列的 FASTA 文件作为输入,因此我们使用 BSgenome 包提取它。
3.2. 序列提取
首先,我们需要为我们正在处理的基因组加载 BSgenome 对象,UCSC 为小鼠基因组构建的 mm10,BSgenome.Mmusculus.UCSC.mm10。
library(BSgenome)
library(BSgenome.Mmusculus.UCSC.mm10)
BSgenome.Mmusculus.UCSC.mm10
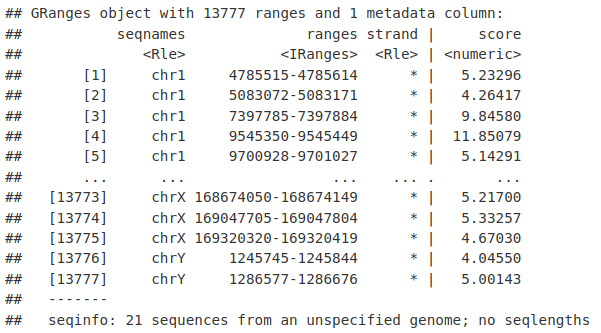
我们现在有一个 GRanges,以山顶为中心,每个山峰的最高信号点。
macsSummits_GR
一旦我们使峰重新居中,我们就可以将 getSeq 函数与调整大小的常见峰的 GRanges 和 mm10 的 BSgenome 对象一起使用。
getSeq 函数返回包含峰下序列的 DNAStringSet 对象。
peaksSequences <- getSeq(BSgenome.Mmusculus.UCSC.mm10, macsSummits_GR)
names(peaksSequences) <- paste0(seqnames(macsSummits_GR), ":", start(macsSummits_GR),
"-", end(macsSummits_GR))
peaksSequences[1:2, ]

3.3. 写入 FASTA 文件
writeXStringSet 函数允许用户将 DNA/RNA/AA(氨基酸)StringSet 对象写入文件。默认情况下,writeXStringSet 函数以 FASTA 格式写入序列信息(根据 MEME-ChIP 的要求)。
writeXStringSet(peaksSequences, file = "mycMel_rep1.fa")
3.4. MEME-ChIP
现在文件“mycMel_rep1.fa”包含适合 MEME-ChIP 中 Motif 分析的峰几何中心周围的序列。
在您自己的工作中,您通常会在本地安装了 MEME 的笔记本电脑上运行它,但今天我们会将生成的 FASTA 文件上传到他们的门户网站[1]。按照此处[2]的说明在本地安装 MEME。可以在此处[3]找到 MEME-ChIP 的结果文件
3.5. 结果解析
我们可以从 FIMO 输出中检索 MEME-ChIP 中识别的 Myc 基序的位置。
FIMO 将 Myc 基序位置报告为 GFF3 文件,我们应该能够在 IGV 中对其进行可视化。遗憾的是,这个 GFF 文件的命名约定只导致报告了一小部分图案。

3.6. FIMO to R
幸运的是,我们可以将 motif 的 GFF 文件解析为 R 并使用 rtracklayer 包中的导入函数解决这个问题。
library(rtracklayer)
motifGFF <- import("~/Downloads/fimo.gff")
3.7. 获取有效 GFF3
我们可以给序列一些更合理的名称并将 GFF 导出到文件以在 IGV 中可视化。
motifGFF$Name <- paste0(seqnames(motifGFF), ":", start(motifGFF), "-", end(motifGFF))
motifGFF$ID <- paste0(seqnames(motifGFF), ":", start(motifGFF), "-", end(motifGFF))
export.gff3(motifGFF, con = "~/Downloads/fimoUpdated.gff")

3.8. 扫描已知 motifs
我们之前看到我们可以使用一些 Biostrings 功能 matchPattern 来扫描序列。通常使用 ChIPseq,我们可能知道我们正在寻找的基序,或者我们可以使用来自数据库(例如 JASPAR)的一组已知基序。
library(JASPAR2020)
JASPAR2020

3.9. 使用 TFBStools 从 JASPAR 获取 motifs
我们可以使用 TFBSTools 包及其 getMatrixByName 函数访问我们感兴趣的motif的模型。
library(TFBSTools)
pfm <- getMatrixByName(JASPAR2020, name = "MYC")
pfm

3.10. 使用 motifmathr 进行 motifs 扫描
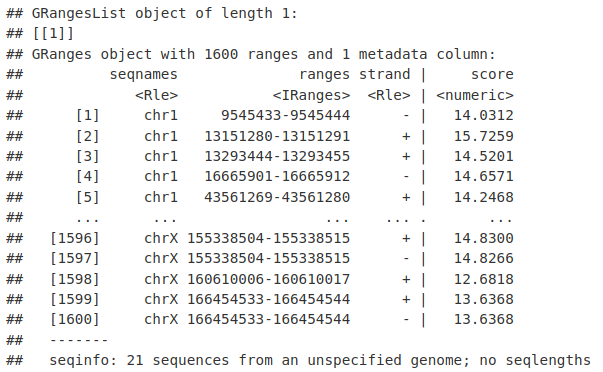
有了这个 PWM,我们可以使用 motifmathr 包来扫描我们的山峰以寻找 Myc motif并返回motif的位置。 我们需要提供我们的 PWM、要在内部扫描的 GRanges 和要从中提取序列的 BSGenome 对象。我们还将输出参数设置为这个实例的位置。
library(motifmatchr)
MycMotifs <- matchMotifs(pfm, macsSummits_GR, BSgenome.Mmusculus.UCSC.mm10, out = "positions")
MycMotifs
3.11. 导出匹配的 motifs
我们可以导出峰内的 Myc 基序位置,以便稍后在 IGV 中使用或用于元图可视化。
export.bed(MycMotifs[[1]], con = "MycMotifs.bed")
参考资料
MEME: http://meme-suite.org/tools/meme-chip
[2]Installation: http://meme-suite.org/doc/download.html
[3]结果: http://rockefelleruniversity.github.io/myc_Meme_Example/meme-chip.html
本文由 mdnice 多平台发布















 3942
3942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









