







来源:时序人
本文约2500字,建议阅读7分钟
本文介绍一篇 AAAI 2025 中的工作,研究者提出了一个专为时间序列预测设计的开创性测试时自适应框架——TAFAS。深度神经网络(DNN)在时间序列预测方面取得了显著进展,而时间序列预测是时间序列建模的主要任务之一。然而,时间序列的非平稳性削弱了预训练的时间序列预测模型在关键部署环境中的可靠性。
本文介绍一篇 AAAI 2025 中的工作,研究者提出了一个专为时间序列预测设计的开创性测试时自适应框架——TAFAS。它能够灵活地使源预测模型适应不断变化的测试分布,同时又保留了预训练期间学到的核心语义信息。通过创新性地利用部分可观测的真实数据和门控校准模块,TAFAS 实现了对源预测模型的主动、鲁棒且与模型无关的自适应。

【论文标题】
Battling the Non-stationarity in Time Series Forecasting via Test-time Adaptation
【论文地址】
https://arxiv.org/abs/2501.04970
【论文源码】
https://github.com/kimanki/TAFAS
论文背景
现实世界中时间序列数据的非平稳性导致数据分布持续变化,这是预训练时间序列预测模型可靠部署的一个关键瓶颈。以往减轻非平稳性影响的工作目的是通过改进预训练过程来提高时间序列预测模型的鲁棒性。然而,随着非平稳性加剧训练和测试数据之间的分布差异,即使预训练模型已经从训练数据中学习了有意义的时序语义,其预测结果也会变得越来越不可靠。图1(a)展示了不断变化的非平稳测试数据如何对预训练时间序列预测模型的预测结果产生负面影响。
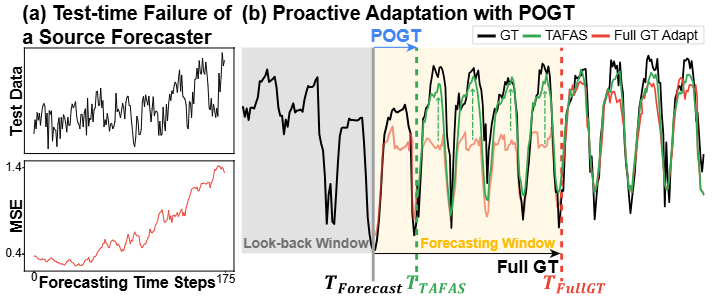
图1
现有方法的这一缺陷凸显了在保持其核心语义的同时,对预训练的源预测器在测试时输入发生偏移的情况下进行持续适应的必要性。通过使源预测器适应测试时输入中包含的新时间变化语义,可以使其反映不断变化的测试分布。
测试时自适应(TTA)主要在计算机视觉领域的分类设置下进行研究,它会根据测试输入动态调整预训练的分类器;TTA 的这一目标与上述使源预测器适应新到达的测试数据的动机高度契合。传统上,TTA 在测试输入性质方面基于两个主要假设运作。首先,TTA 假设测试标签完全缺失,因为在测试时手动标注输入是不可行的。其次,由于大多数图像数据都被假定为独立同分布,TTA 通常也在相同的独立同分布假设下运作。然而,在时间序列预测的测试时自适应(TSF-TTA)中,由于时间序列数据的固有特性,这些假设不再成立。
与 TTA 的第一个假设不同,在 TSF-TTA 中,虽然预测时间步的真实值最终会以延迟的方式获得,但它们是可访问的。例如,在预测未来30天的电力消耗时,我们会在30天后知道实际的电力消耗量。有趣的是,如图1(b)所示,时间序列的序列性质使得在获得全部真实值之前,真实值部分是可观测的。在上述例子中,前7天的部分真实值只能在一周后获得。利用这种部分可观测的真实值为我们在全部真实值到来之前提前执行 TSF-TTA 提供了宝贵的机会。此外,由于时间序列中存在时间依赖性,TSF-TTA 违反了第二个假设。这需要采用一种技术来解决时间序列在局部(窗口内)和全局(整个测试时间)层面上的非独立同分布(non-IID)问题。
考虑到时间序列特性所带来的这些挑战和机遇,研究者提出了一种针对非平稳时间序列的测试时自适应预测框架——TAFAS,该框架可扩展至各种时间序列预测架构。
论文方法
TAFAS 框架由周期感知自适应调度(PAAS)和门控校准模块(GCM)组成。
PAAS 自适应地获取足够长度的部分可观测真实值,以表示具有语义意义的周期模式。利用快速傅里叶变换来识别数据中的主导频率,并据此计算出 POGT 的长度,以确保 POGT 包含足够的语义信息,同时减少适应延迟。
之后,模型无关的GCM被调整以校准测试时间输入,使其符合源预测模型有效处理的分布。GCM 中的门控机制通过考虑全局分布变化来控制校准结果的使用程度。PAAS 和 GCM 共同作用,使源预测模型能够主动适应非平稳的测试时间输入。
在整个自适应过程中,源预测模型保持冻结状态,以保留其从大量历史数据中学习到的核心语义。通过主动适应的预测模型,TAFAS 调整了原始预测的后半部分(即尚未观察到真实值的部分),使自适应后的预测反映分布变化。

图2:TAFAS框架图
实验分析
TAFAS 在不同 TSF 架构上的表现
表1展示了在不同源TSF架构和多个预测窗口下,应用 TAFAS 与否的均方误差(MSE)。TAFAS 在测试时一致降低了预测误差,有效处理了时间序列的测试时非平稳性。特别是在长期预测场景中,分布偏移更为明显时,TAFAS 的性能提升更为显著。
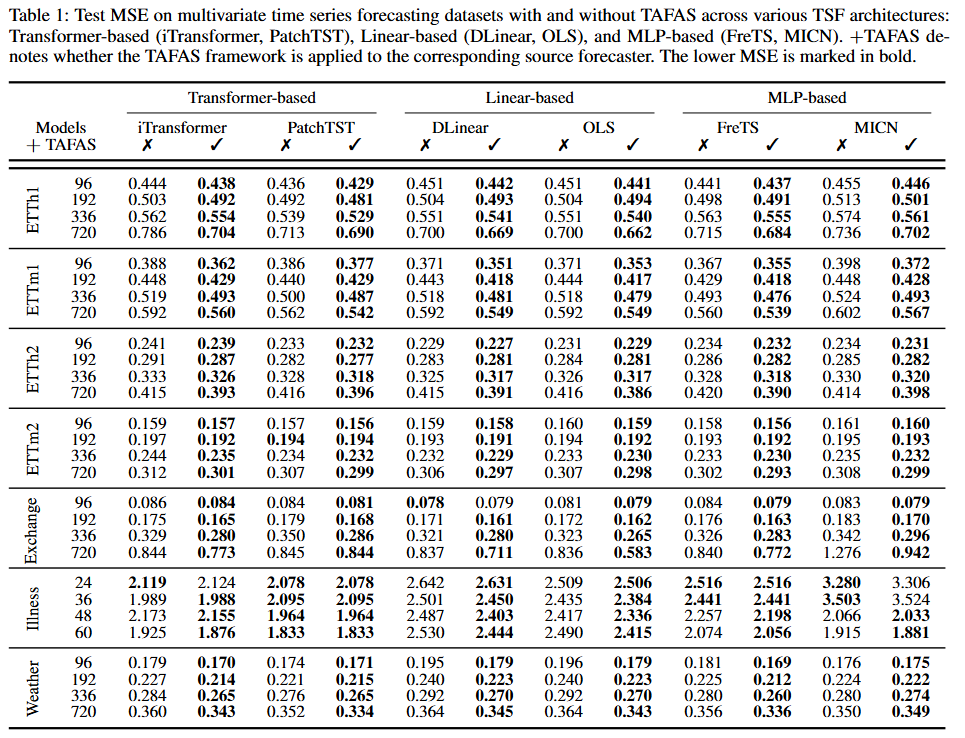
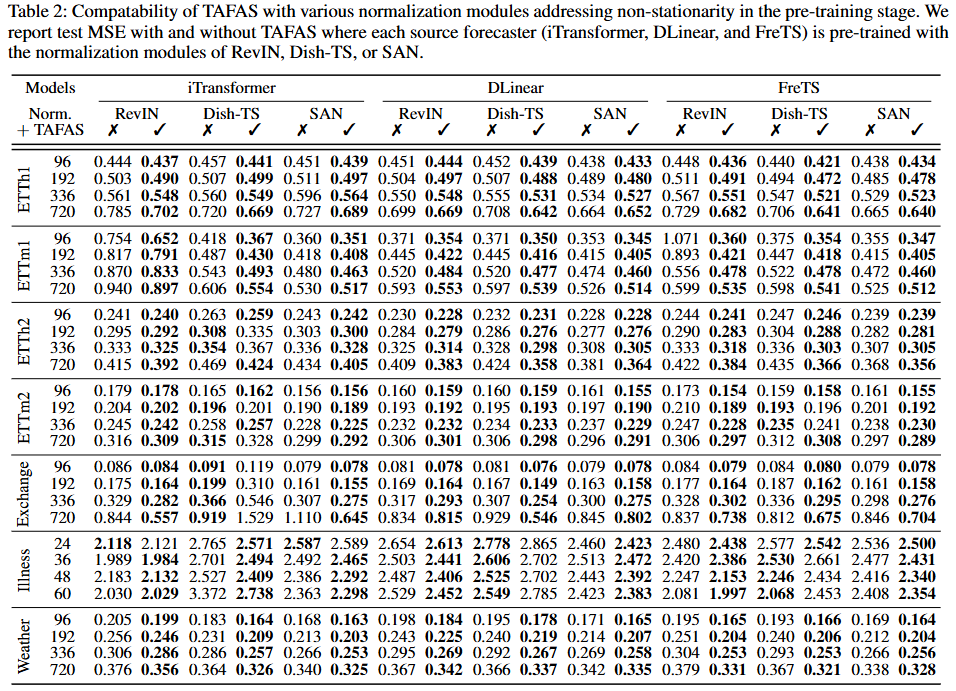
与预训练阶段非平稳性处理方法的兼容性
表2展示了 TAFAS 在配备 RevIN、Dish-TS 或 SAN 归一化模块的源预测器上的应用结果。TAFAS 在所有数据集和架构上进一步提升了这些先进源预测器的预测能力,尤其是在长期时间序列预测中。
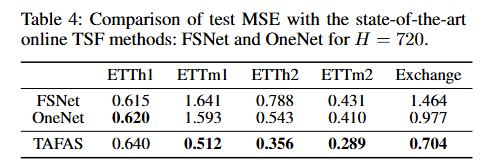
与在线 TSF 方法的比较
表4比较了 TAFAS 与在线 TSF 方法 FSNet 和 OneNet 在长期预测场景(H=720)下的测试 MSE。在大多数实验设置中,TAFAS 显著优于在线 TSF 方法。TAFAS 的优势归因于其主动适应预测器的能力、及时调整预测以反映相邻分布偏移的能力,以及通过使用辅助的非平稳性感知 GCM 模块保留源预测器的知识。
TAFAS的技术组件分析
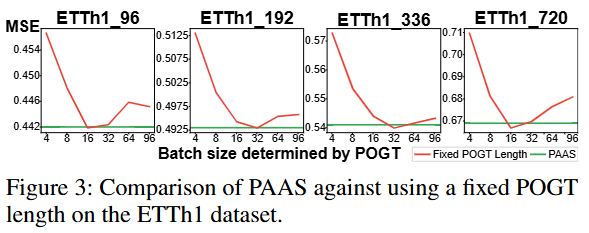
PAAS 与固定 POGT 长度的比较:图3展示了在 ETTh1 数据集上,使用 PAAS 动态调整 POGT 长度与使用固定 POGT 长度的比较。结果显示,PAAS 能够根据数据集的特性动态调整 POGT 长度,从而更好地适应数据的非平稳性。
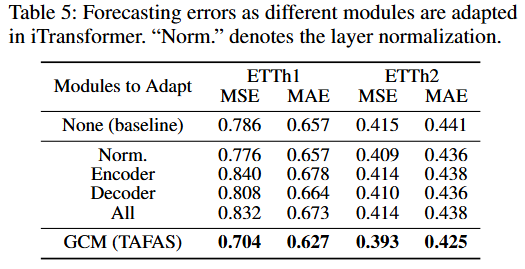
GCM 的有效性:表5展示了在 iTransformer 中适应不同模块的预测误差。结果显示,仅适应 GCM(TAFAS)时,预测性能得到了显著提升,而适应其他内部模块则可能导致性能下降,甚至低于基线,这表明 TAFAS 在保留源预测器核心语义的同时,有效地适应了测试时的分布偏移。
总结
为了解决非平稳时间序列中分布不断变化的问题,研究者提出了 TAFAS,这是一种开创性的时间序列预测测试时自适应(TSF-TTA)框架。该框架在测试时能够动态调整源预测器的参数,同时保留源预测器的知识。通过使用部分自适应自监督(PAAS)方法,可以获取具有语义意义模式的部分观测真实值,从而实现主动自适应。然后,采用全局与局部一致性匹配(GCM)方法来应对分布的变化,该方法同时考虑了局部和全局的时间分布偏移。TAFAS 是一个与数据集和模型无关的框架,这一点已通过全面的实验结果和分析得到验证。文中开创的 TSF-TTA 框架为最先进的时间序列预测器的可持续部署开辟了一条新途径。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









