







来源:MIND at NJUPT
本文共4700字,建议阅读9分钟
本文旨在为小规模LLM提供稳定的检索能力和高效的推理能力。journal: AAAI
year: 2025
address: https://arxiv.org/abs/2504.03137
Introduction
随着更多大语言模型(LLM)的出现,其持续提升的性能为自然语言处理(NLP)领域带来了重大创新。在庞大数据量和海量参数下展现的"突现能力",使LLM在复杂零样本任务中表现卓越。尽管效果显著,LLM在知识密集型任务中仍面临挑战:由于缺乏任务特定的先验知识和理解能力,以及模型训练的高成本耗时性,导致知识库持续更新困难。
为解决这些问题,研究者提出通过知识图谱(KG)为LLM提供可靠且持续更新的知识库,以支持更精准可解释的推理。KGQA作为典型的知识密集型任务,现有工作探索了多种LLM与KG协同推理方法。当前主流方法主要通过从KG检索信息并融入提示词(prompt),借助LLM的推理能力解决问题。
尽管LLM在KG上的推理前景广阔,但仍面临若干挑战:首先,KG的内容常被直接表示为冗长的文本内容,这无法有效传递图谱结构中富含的逻辑关系(这对推理至关重要)。
先前工作中,KG内容以多维列表或自然语言形式呈现在输入提示中,难以清晰表达其复杂的关联关系和层次结构。其次,KG的检索推理需要大量LLM调用和强大推理能力。先前工作采用从问题实体开始的迭代方法逐步获取推理信息,这增加了LLM调用次数,牺牲了推理效率并降低了可行性。描述KG的文本内容体量庞大,不仅需要更大的上下文窗口,还需要更强大的LLM来确保信息不漏检,同时避免在冗余上下文中生成错误答案。
针对上述挑战,作者提出了面向大语言模型(LLMs)的 "检索-嵌入-推理"(Retrieve-Embed-Reason)框架 —— LightPROF。该框架旨在为小规模LLM提供稳定的检索能力和高效的推理能力,其核心由三个模块构成:
1、检索模块(Retrieval)
以关系为基本检索单元:从知识图谱(KG)中基于问题语义限定检索范围,精准获取推理所需的子图(Reasoning Graph)。
优势:通过语义约束缩小搜索空间,减少LLM的频繁调用,提升检索准确性和稳定性。
2、嵌入模块(Embedding)
同时编码文本内容(如实体、关系描述)和图结构(如路径依赖、层级关系)。
通过轻量级映射层(Projector)将知识嵌入对齐到LLM的词元空间,生成知识软提示(Knowledge Soft Prompt)。
基于Transformer的知识适配器(Knowledge Adapter):从推理子图中提取并融合文本和结构信息,生成适合LLM的嵌入表示。
创新点:
优势:减少输入token数量,缓解信息冗余和歧义,降低LLM的上下文窗口压力。
3、推理模块(Reasoning)
混合提示机制:将知识软提示与人工设计的自然语言硬提示结合,引导LLM生成最终答案。
关键设计:冻结LLM参数,仅训练知识适配器,实现参数高效(Parameter-Efficient)的推理。
Methodology
本文设计了 LightPROF 框架,通过精准检索和细粒度结构化数据处理能力,在小规模大语言模型(LLM)下实现高效的复杂知识图谱(KG)问题推理。如图1所示,作者提出的 "检索-嵌入-推理"(Retrieve-Embed-Reason)框架 包含三个阶段:推理图检索、知识嵌入 和 知识提示混合推理。
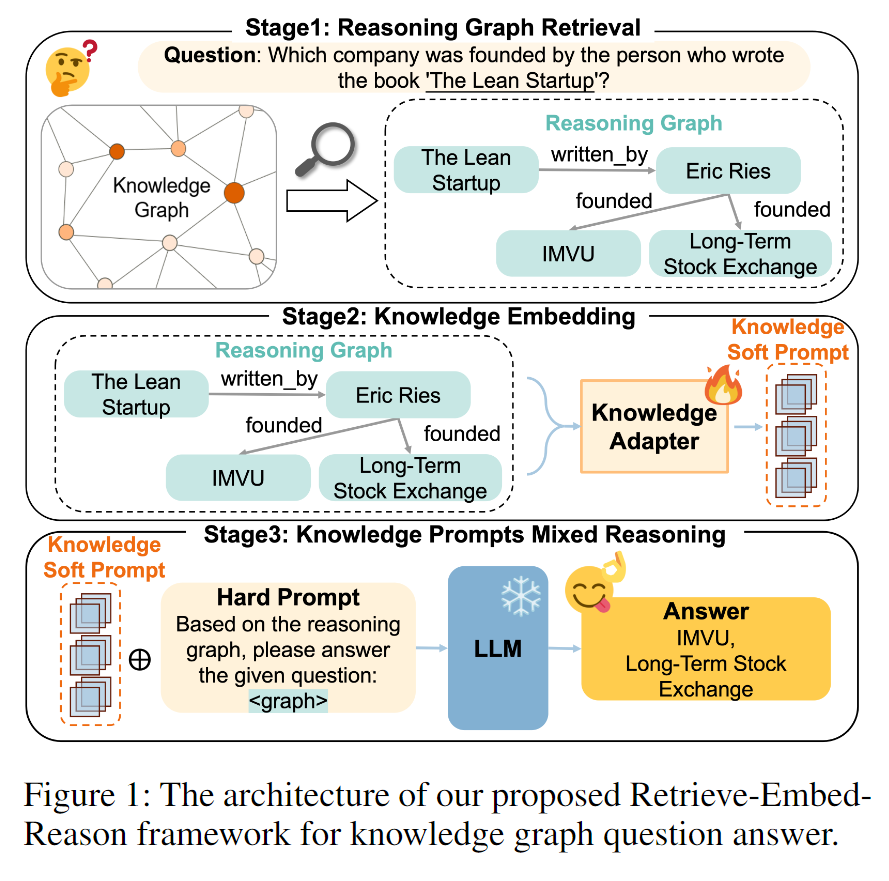
Stage1: Reasoning Graph Retrieval
针对复杂多跳知识图谱问答(KGQA)任务,如何基于问题高效、精准、稳定地从知识图谱中检索信息是关键挑战。为此,作者将检索模块分解为三个步骤(如图2所示):
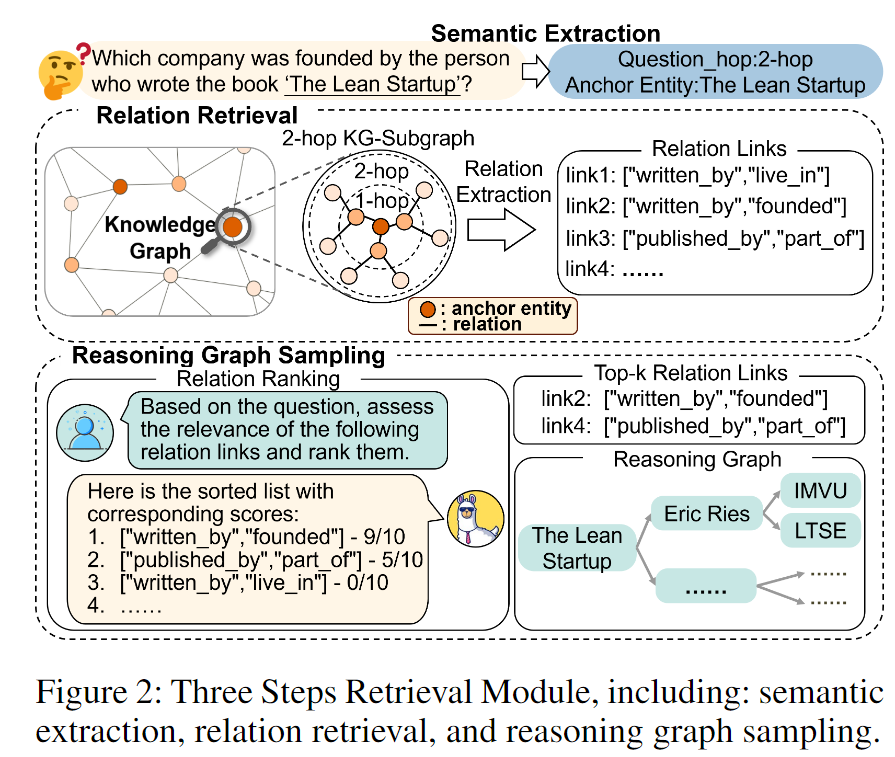
Semantic Extraction
对于给定问题q,目标是从知识图谱(KG)中提取相关语义(即查询q所需的跳数hq和锚实体B),以此缩小检索范围,同时保留关键推理知识。该方法能够检索并构建高度相关且精确的推理图。具体而言,本文微调一个预训练语言模型,基于查询q的语义向量Vq来预测KG推理所需的跳数hq。假设数据集中最大跳数为H,这可以构建为分类任务:
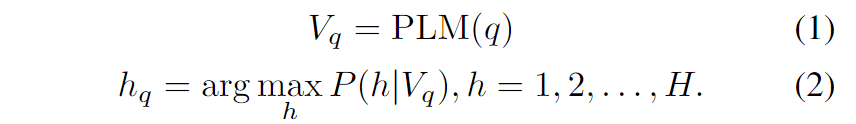
Relation Retrieval
知识图谱中的关系描述了两个实体之间的特定联系,为其交互提供了语义清晰度,并极大地丰富了知识图谱的信息内容。许多研究利用语义丰富的关系链接进行知识图谱推理任务。
更重要的是,与不断变化且复杂的实体相比,知识图谱中的关系表现出更强的稳定性和直观性。为了尽可能收集相关知识,基于锚实体集合 B 和预测的跳数 hq,在知识图谱中搜索关系链接。具体而言,模型首先选择一个锚实体,然后进行深度限制为 hq 的受限广度优先搜索(BFS),以收集从锚实体 B 出发、长度不超过 hq 的所有关系链接。
Reasoning Graph Sampling
将检索到的关系链接输入大型语言模型(LLM)。LLM 根据这些链接与问题 q 的语义相关性计算分数并排序,然后选择排名前 k 的相关链接。最后,基于选定的关系链接在知识图谱中采样,提取多条推理路径 {R₁, R₂, ..., Rₙ},构建一个精炼的推理图 Gᴿ。
Stage2: Knowledge Embedding
知识图谱通常包含丰富的复杂结构信息,例如子图结构、关系模式以及实体间的关联关系。这类结构信息对于大型语言模型(LLMs)深入理解知识图谱至关重要。然而,知识图谱结构信息的自然语言表达存在冗余和语义混淆问题,无法直接揭示其本质特性,从而阻碍了LLM对此类信息的有效利用。
为解决上述挑战,受启发于,作者提出一种精细且紧凑的知识适配器,能够在推理图中编码文本信息并提取其结构信息(如下图3所示)。通过细粒度融合文本信息与结构特征,知识适配器帮助LLM更精准地理解推理图知识,从而实现更精确的推理。
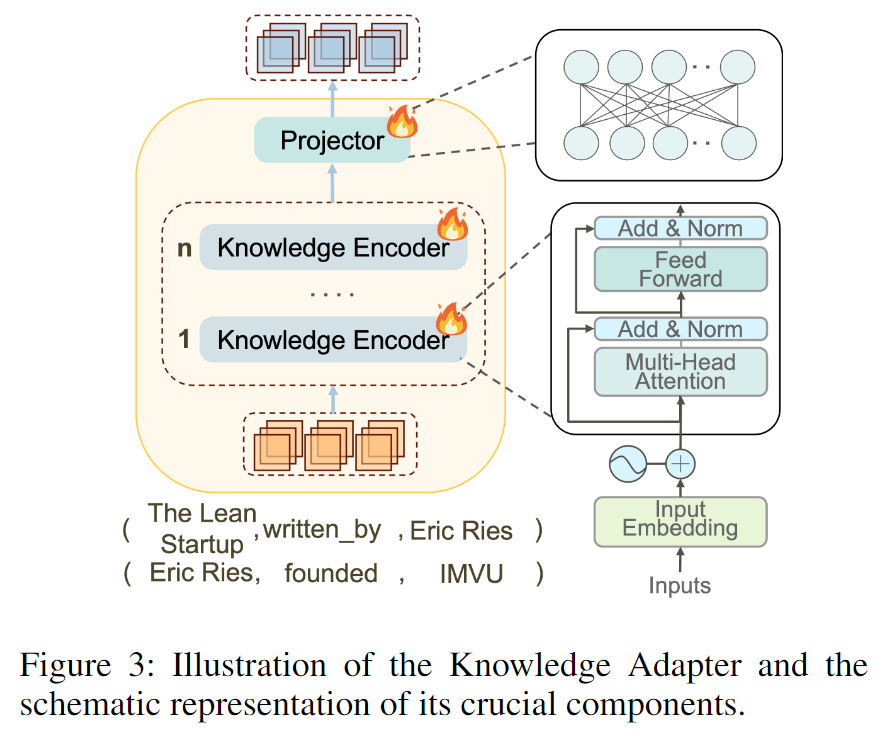
具体而言,假设推理图 = 由 N 条推理路径组成,每条路径 是三元组的集合。本文通过以下步骤处理:
1.嵌入获取:使用预训练模型(如BERT)生成关系 的关系嵌入 ,以及实体 的实体嵌入。
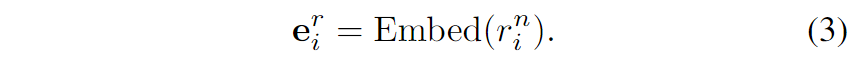
2.结构编码:
局部结构:通过结构编码器(StructEmb)捕获单个三元组内实体与关系的交互信息。
全局结构:通过线性层(Linear)聚合整条推理路径的全局信息。
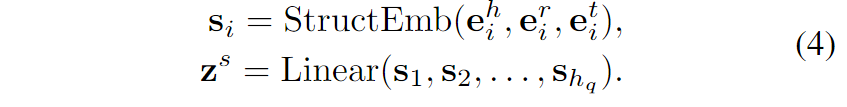
优势:保留图谱的拓扑特性(如路径依赖关系),避免传统文本化方法的信息丢失。
3.文本融合:此外,为了捕获推理路径 的文本信息,作者使用 Fusion(·) 来组合 中所有实体和关系的文本级信息。作者首先获得所有头部实体的组合文本表示
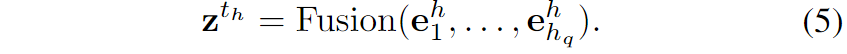
然后,关系 和尾部实体 的组合文本表示可以以相同的方式获得。之后,这些向量被合并到一个向量 中,以表示整个推理路径Rn的综合文本信息:
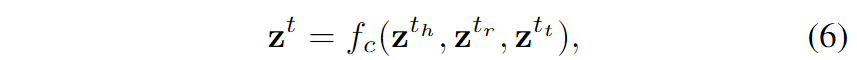
最后,作者使用KnowledgeEncoder(·)无缝集成得到的综合文本信息 和全局结构信息 ,得到推理路径的融合表示,如下图3所示:
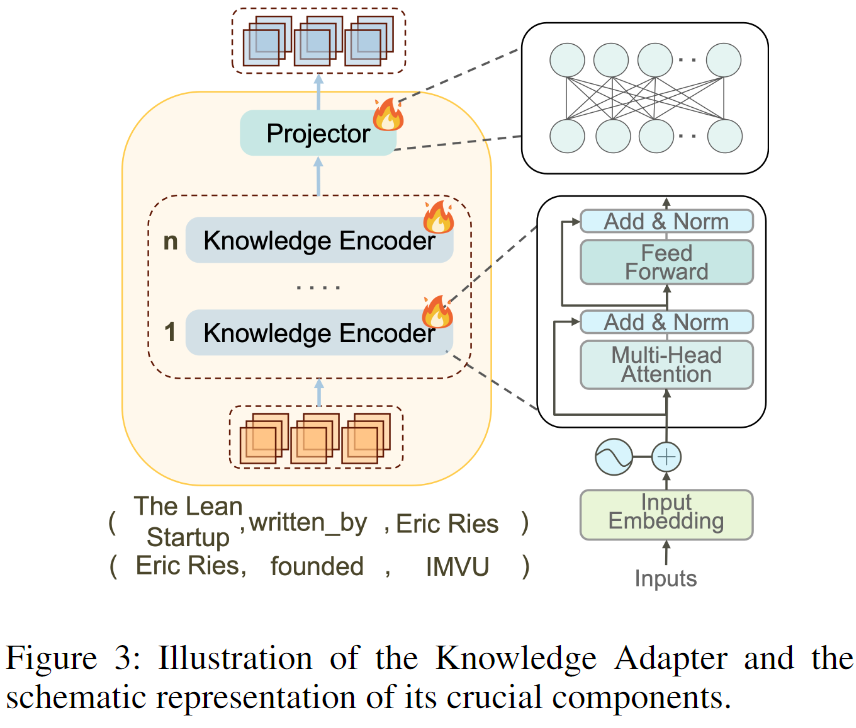
通过这种方式,知识编码器(Knowledge Encoder) 能够将推理图中的每条推理路径编码为单个标记(Token),显著提升大型语言模型(LLM)的标记利用效率,并增强推理路径的语义表征能力。在编码过程中,知识编码器不仅捕获推理图中的文本信息(如实体和关系的描述),还提取关键结构信息(如路径拓扑)。由于融合信息 同时包含文本和结构特征,模型在推理时能更全面地理解路径中隐含的逻辑含义。这种多维信息表征增强了模型对上下文的敏感性,支持更有效的深度语义分析与推理,从而更精准地捕捉语义与结构间的复杂交互,提升推理的准确性和深度。
通过聚合所有推理路径 ,作者得到推理图 的表示序列 。在将其输入LLM前,需进行维度转换。由于知识编码器的嵌入空间与LLM的输入空间存在差异,直接使用这些标记是低效的。为此,作者设计了一个可训练的投影器(Projector),将这些标记映射到LLM的标记嵌入空间中,生成适配LLM的输入序列(称为知识软提示)。
Stage3: Knowledge Prompts Mixed Reasoning
大型语言模型(LLMs)通过海量语料库的广泛训练已掌握丰富知识,但其在处理专业知识、复杂长逻辑链及多跳知识推理时仍存在显著缺陷,主要源于预训练数据的局限性。尽管可通过重新训练扩展LLM的知识库,但这种方法成本高昂且耗时,更严重的是可能导致已有知识遗忘。为解决这一挑战,LightPROF在训练中冻结LLM参数,通过硬提示(Hard Prompt)与软提示(Soft Prompt)的组合引导模型精准高效地回答问题。
具体实现:
1、输入组织:
硬提示:通过精心设计的文本模板,将指令与问题结构化(如 [问题]:爱因斯坦的导师是谁?[要求]:基于推理图回答)。
软提示:将编码后的推理图知识(如路径向量 z^f)插入硬提示的特定位置(如模板中的 [推理图]:{知识软提示})。
2、推理流程:
编码阶段:LLM接收硬提示文本和软提示向量,生成融合知识的输入序列。
解码阶段:基于输入序列自回归生成答案,无需更新模型参数。
Experiments
在本实验中,作者主要讨论以下问题:
Q1:LightPROF能在多大程度上提高LLM在KGQA任务中的表现。
Q2: LightPROF能否与不同LLM主干集成以提高性能。
Q3: LightPROF能否用小规模LLM实现高效的输入和稳定的输出?
Datasets
本文基于 Freebase 知识图:WebQuestionsSP(WebQSP)和 ComplexWebQuestions(CWQ)在两个公共数据集上训练和评估 LightPROF 的多跳推理能力。基于之前的工作,作者利用匹配准确度 (Hits@1) 来评估模型的 top-1 答案是否正确。
WebQSP 是一个问题较少但知识图谱较大的基准,由 4,737 个问题组成。每个问题都包含一个主题实体、推理链和一个 SPARQL 查询来查找答案。答案实体需要对 Freebase 进行 2 跳推理。
CWQ 是一个专门为复杂知识图谱问答研究设计的基准。它包括 34,689 个问答对,建立在 WebQSP 数据集上。它涉及自动创建更复杂的 SPARQL 查询并生成相应的自然语言问题,从而创建广泛多样的问题类型。这些问题需要在 Freebase 上最多 4 跳推理。
Baselines
作者主要考虑三种类型的基线方法:完全微调方法、普通 LLM 方法和 LLM+KG 方法。完整的微调方法包括KV-Mem、EmbedKGQA 、TransferNet 、NSM、KGT5 、GraftNet 、PullNet、UniKGQA 。
LLM+KG方法包括StructGPT、ToG 、KnowledgeNavigator 、AgentBench
值得注意的是,为了确保公平的比较,作者选择的LLM+KGs方法不涉及微调LLM,即它们都是zeroshot方法,没有任何LLM的训练。
Q1: Performance Comparison
作者在三类基线方法上对LightPROF进行评估:完全微调方法、原生LLM方法、LLM+知识图谱方法。如下表1所示,LightPROF不仅在简单问题上表现优异,在需要深度推理和复杂查询处理的场景中也展现出高性能。
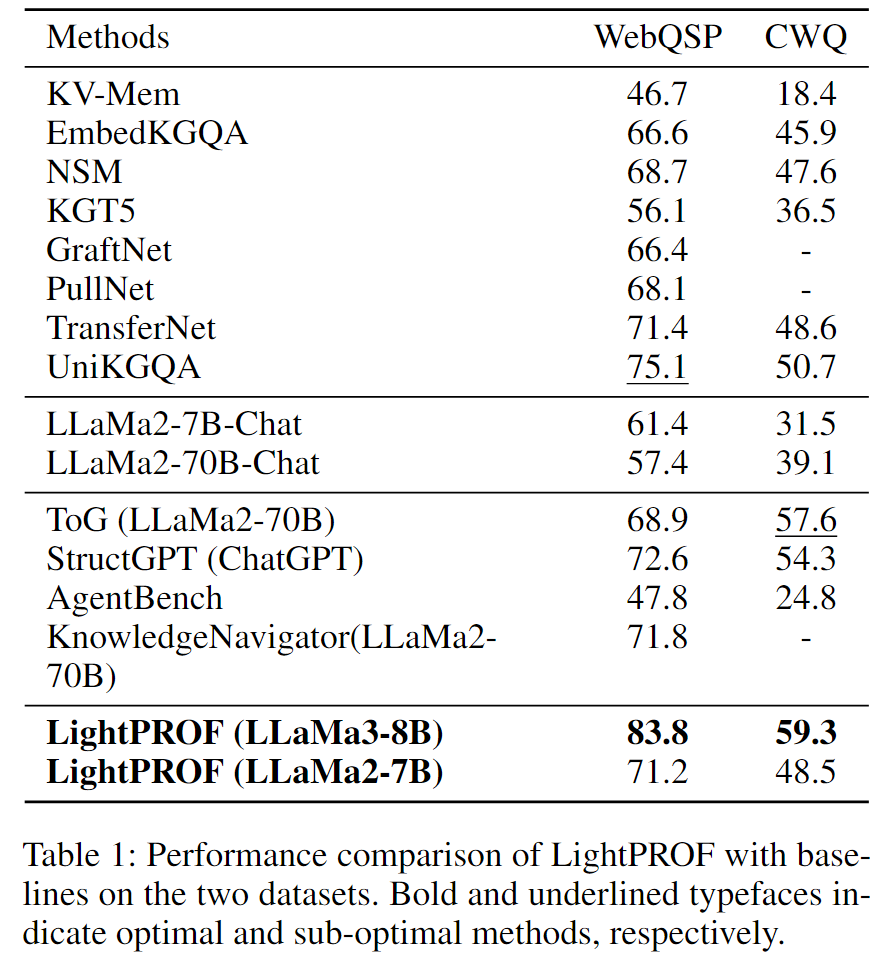
具体而言,LightPROF在WebQSP数据集上显著超越当前最先进模型(83.8% vs 75.1%),在更复杂的CWQ数据集上也表现出色(59.3% vs 57.6%)。这些结果验证了作者框架在处理知识图谱问答(KGQA)任务中的卓越能力,凸显了LightPROF在处理多跳和复杂挑战方面的有效性。与使用纯文本提示的原生LLM和LLM+KG方法相比,LightPROF的显著改进表明,知识适配器生成的软提示能够比离散文本更有效地封装复杂的结构化知识——简洁、信息丰富且表达力强,从而增强LLM对知识图谱信息的理解。
值得注意的是,本文的框架在所有实验条件下均优于其他大规模模型。例如,与使用LLaMa2-70B-Chat的ToG和使用ChatGPT的StructGPT相比,LightPROF在复杂问题推理中表现更优。此外,即使采用较小的LLaMa2-7B版本,框架仍能与其他大规模模型有效竞争,突显了框架设计和优化的高效性。
Q2: Plug-and-Play
对于作者的框架,任何能够接受标记嵌入输入的开源大型语言模型(LLM)均适用。本节中,本文评估了LightPROF集成不同LLM的有效性。如表5所示,结果表明LightPROF框架显著增强了所集成LLM的性能,且不受原始模型基线性能的影响。LightPROF通过结构化数据的高效集成与优化,提升了模型处理复杂知识图谱问题的能力。这种即插即用的集成策略无需对LLM进行高成本微调,尤其适合快速提升现有模型在知识图谱问答(KGQA)任务上的表现。
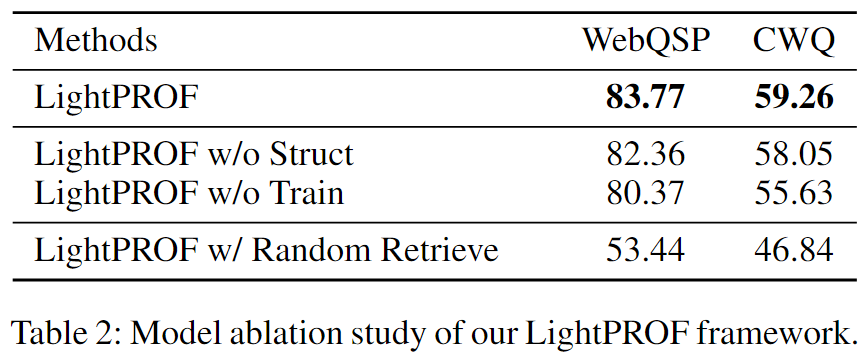

Q3: Efficient Input and Stable Output
Efficiency Results
本文进行了一系列效率测试,对比LightPROF与StructGPT在处理WebQSP数据集时的性能表现。具体测量了模型的运行时间、输入令牌总数及平均每请求令牌数(NPR),结果如表6所示。数据显示,LightPROF在处理相同数据集时更省时,时间成本降低30%(1小时11分49秒 vs. 1小时42分12秒)。

在输入令牌总数上,LightPROF与StructGPT差异显著,表明LightPROF在输入处理上更经济,令牌使用量减少约98%。此外,LightPROF的NPR值为224,远低于StructGPT的6400。这一对比进一步凸显了LightPROF在每请求所需令牌数上的优势,验证其更精准、资源效率更高的请求处理能力,证明了LightPROF在集成小规模LLM时的有效性。
Case Study
如下表4所示,作者通过对比LightPROF与StructGPT回答关于林赛·罗韩吸毒问题的复杂查询,验证了LightPROF在使用小规模LLM时的高效输入与稳定输出能力。

结果表明,LightPROF不仅能准确识别并全面回答查询,还展现出更深的推理路径和更高的综合评分。相比之下,尽管StructGPT处理了相关问题,但未能完全捕获所有相关答案。有趣的是,作者发现LightPROF能始终生成仅包含答案的输出,且使用更少的输入令牌和更短的推理时间。这表明LightPROF能有效整合并精准输出知识图谱中的复杂信息,验证了其在高效、准确处理复杂KGQA任务上的可靠性与实用性。
Conclusion
在本文中,作者提出了LightPROF框架,其通过精准检索与高效编码知识图谱(KG)来增强大型语言模型(LLM)的推理能力。为实现检索范围的精准约束,LightPROF以稳定关系为单位对知识图谱进行增量式采样。为实现小规模LLM的高效推理,设计了精细的知识适配器,能够有效解析图结构并进行细粒度信息整合,从而将推理图压缩为更少的标记(Token),并通过投影器(Projector)实现与LLM输入空间的全面对齐。
实验结果表明,本文的框架优于其他基线方法,尤其是涉及大规模语言模型的方法。与仅依赖文本的方法相比,知识软提示整合了更全面的结构与文本信息,使其更易于LLM理解。
编辑:于腾凯
校对:李享沣
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









