







 本文探讨了大语言模型在研究领域的应用,重点介绍了基于子图检索和查询交互的方法来利用知识图谱。子图检索通过筛选重要节点构成知识子图,而查询交互则通过多轮交互获取所需信息。总结中提出应用建议,如根据任务需求选择合适策略,并指出未来研究方向,包括知识整合、冲突消解和模型准确性提升。
本文探讨了大语言模型在研究领域的应用,重点介绍了基于子图检索和查询交互的方法来利用知识图谱。子图检索通过筛选重要节点构成知识子图,而查询交互则通过多轮交互获取所需信息。总结中提出应用建议,如根据任务需求选择合适策略,并指出未来研究方向,包括知识整合、冲突消解和模型准确性提升。
尽管大语言模型具有出色的自然语言生成能力,但在知识密集型任务中常常面临一些挑战,例如可能生成幻象或事实错误内容。因此,在一些特定场景中,需要向大语言模型补充外部的知识信息。知识图谱(Knowledge Graph, KG)存储了大量的结构化知识信息,常用于知识密集型的任务场景,也广泛被用于补充大语言模型的知识信息。本部分将从两个方面讨论如何使用知识图谱增强大模型,包括基于子图检索的方法和基于查询交互的方法。
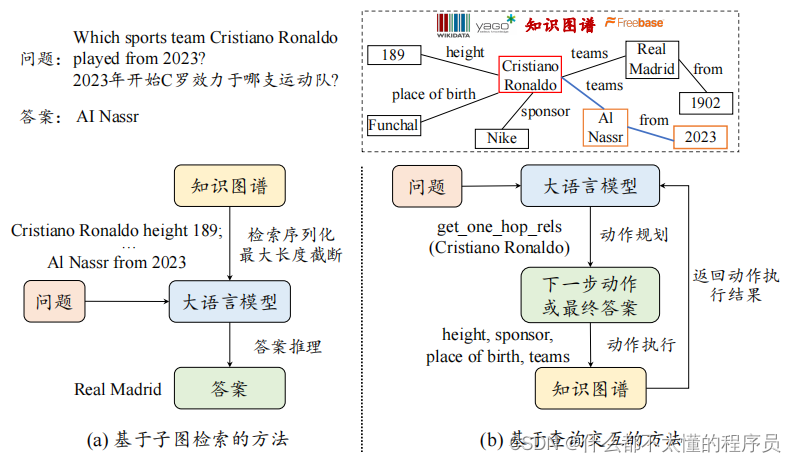
基于子图检索的方法
基于检索增强的方法通常首先从知识图谱中检索一个相对较小的子图(知识检索),然后将该子图序列化并作为提示的一部分,输入给大语言模型以丰富其相关背景知识(知识利用)。对于知识检索,可以使用启发式方法过滤掉知识图谱上不重要的节点。这类方法通常使用 PageRank 等图节点排序算法来计算知识图谱上每个节点的重要性,并按照预先设定的阈值筛选出重要的节点以构成规模相对较小的子图。然而,这种方法仅利用了知识图谱的结构特征,没有考虑节点与输入文本在语义信息上的相关性。另一类有效的方法是训练语义匹配模型(例如预训练语言模型),专门用于筛选与问题相关的事实三元组。由于知识图谱中三元组规模庞大,可以基于输入文本中包含的实体,对与其相邻的若干跳以内的三元组进行筛选。对于知识利用,通常是将检索到的子图序列化,并设计特定的提示将其作为大语言模型的输入。具体来说,给定上述的检索子图,可以从起点开始按照图结构进行广度优先遍历,得到子图上三元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









