







 本文介绍了多模态预训练模型的基本架构,包括two-stream和one-stream两大类,并列举了代表性的模型如ViLBERT、LXMERT等。同时,还详细说明了常用的预训练数据集,如MS-COCO、VisualGenome等。
本文介绍了多模态预训练模型的基本架构,包括two-stream和one-stream两大类,并列举了代表性的模型如ViLBERT、LXMERT等。同时,还详细说明了常用的预训练数据集,如MS-COCO、VisualGenome等。
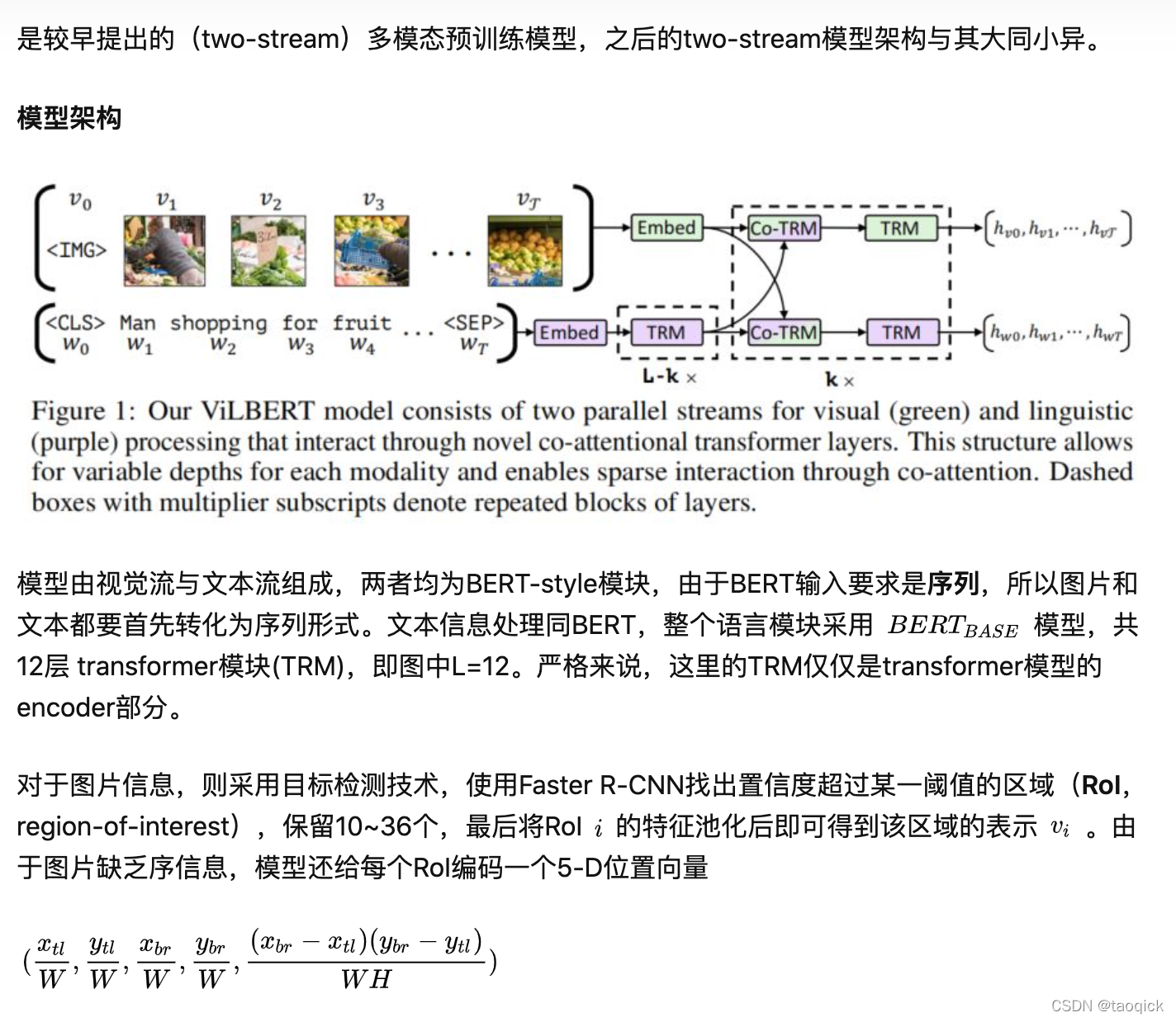
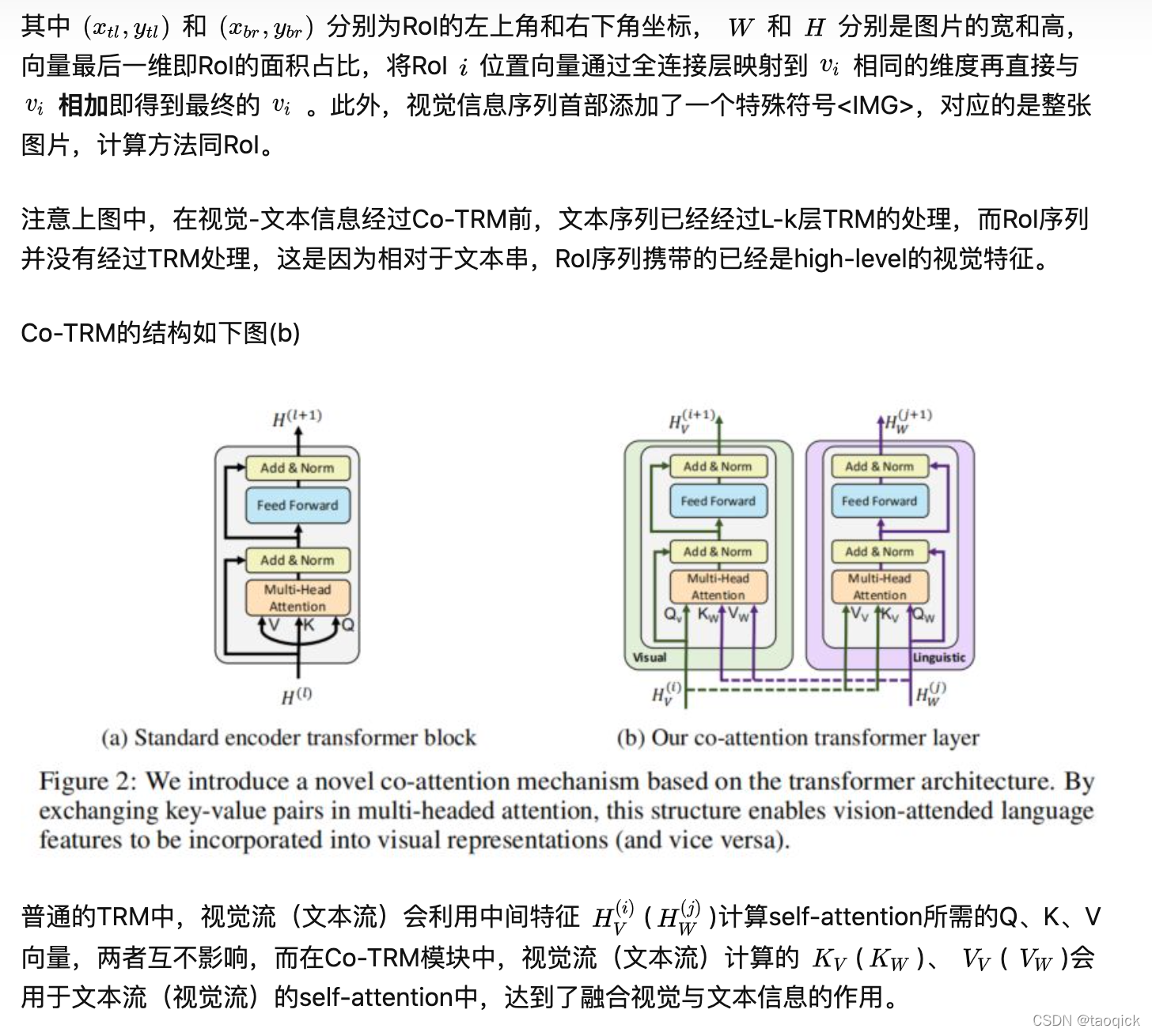
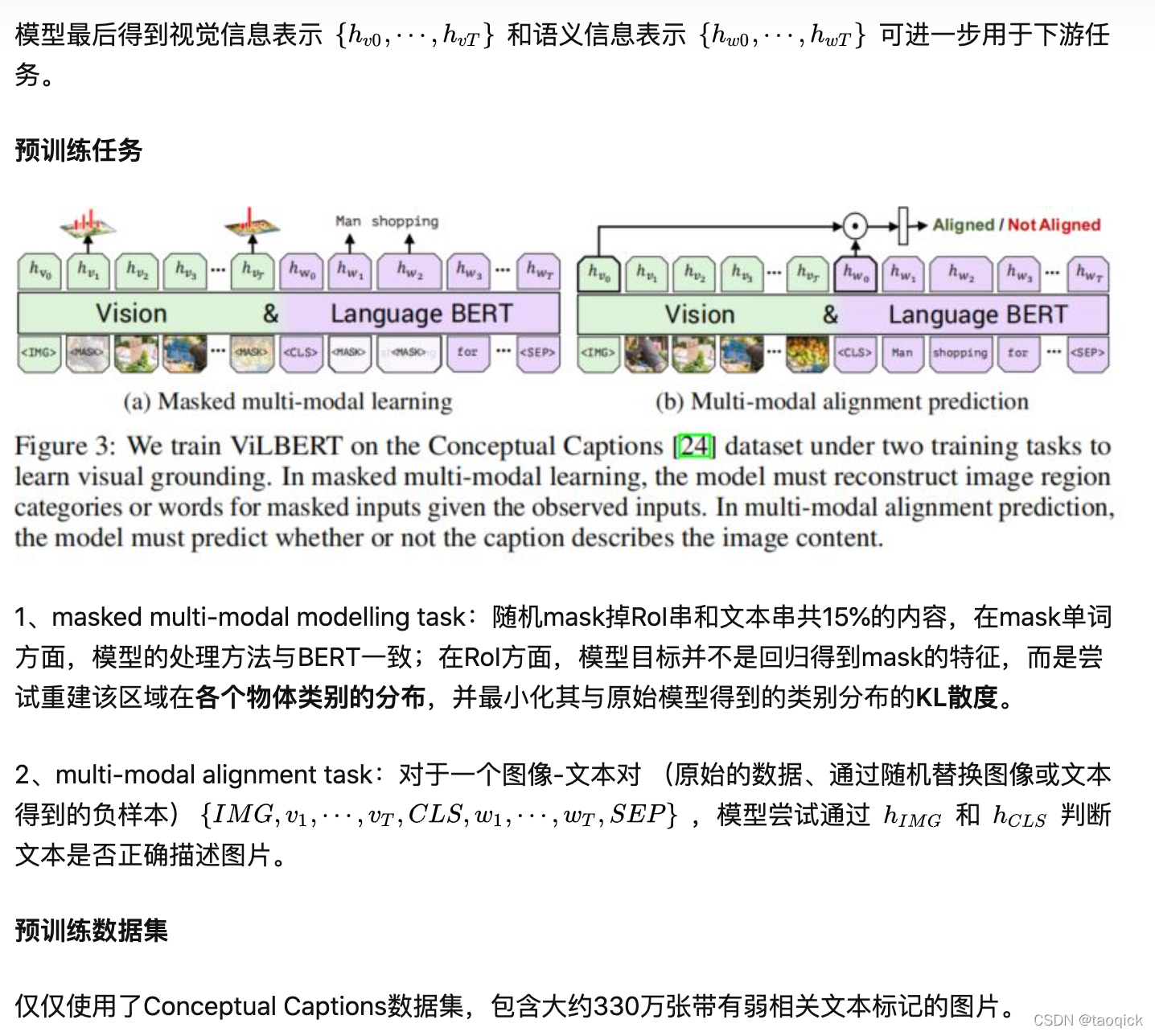
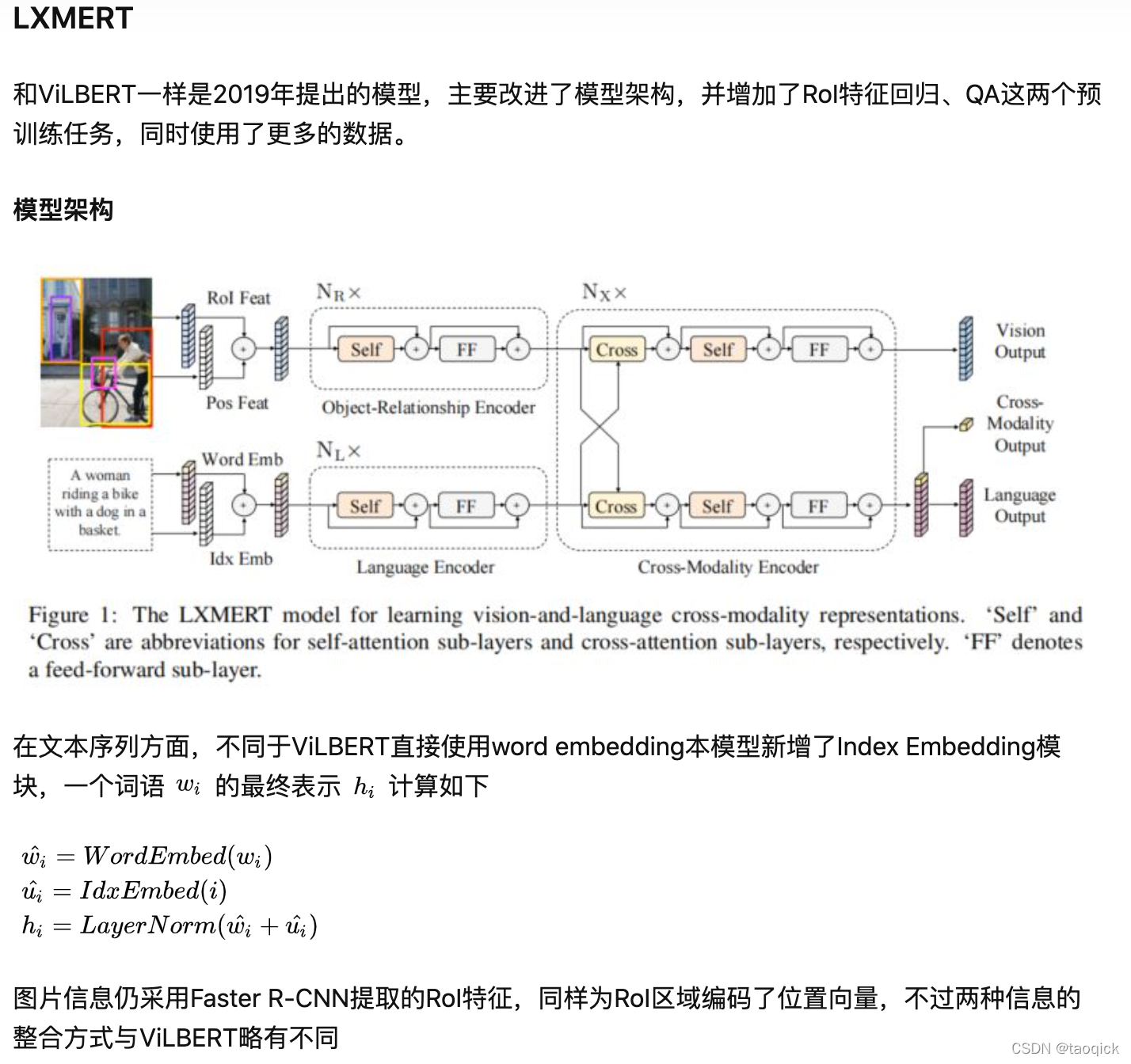
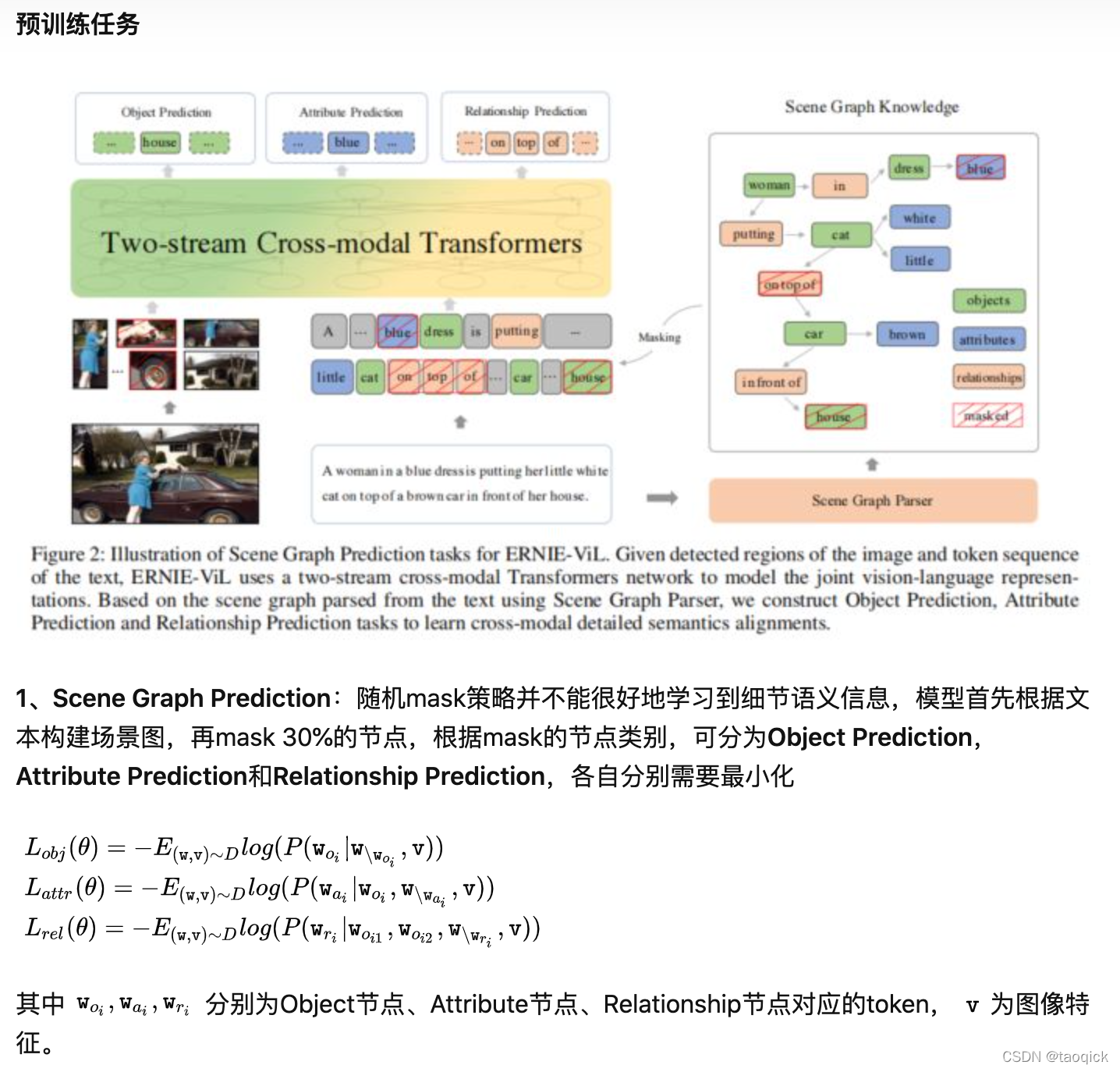
我们通常从三个方面学习了解一个多模态预训练模型:模型架构、预训练任务、预训练数据集,目前层出不穷的各种模型也是针对其中某个或某几个方面做文章。根据模型架构,多模态预训练模型可以分为two-stream和one-stream两大类,前者首先利用两个独立的模型分别处理图片和文本两种单模态信息,然后通过co-attention transformer layers融合两种模态信息;后者首先将两种模态的信息融合,然后直接输入到同一个模型中处理。目前one-stream有ViLBERT[1]、LXMERT[2]、ERNIE-ViL[3]三种two-stream多模态模型做简单介绍;two-stream有CBT(双流提取视频(S3D)和语音文本(ASR+BERT)特征后对比学习)、CLIP(SimCLR框架的对比学习)、WenLan(中文对比学习的MoCo)
ViLBERT

预训练数据集
MS-COCO,Visual Genome以及VQA v2.0、 GQA balanced version、VG-QA三个VQA数据集的train&dev部分,最终一共约有918万个图像-文本对。



















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









