






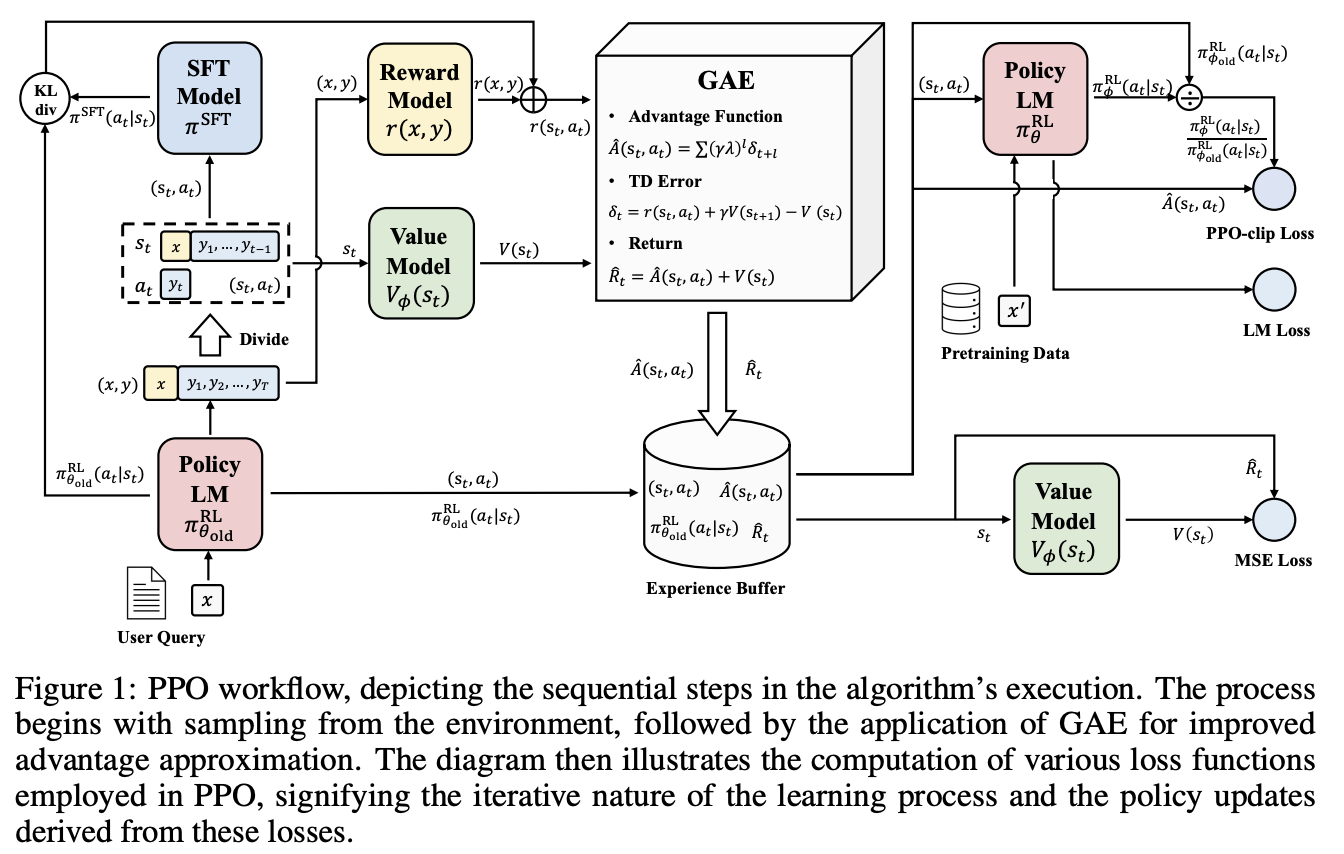
仔细看了看TRL的code(https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py),step大致流程为先batched_forward_pass,再过minibatch:

先写一写自己的理解
PPO的loss由以下几部分相加得到:
- actor的loss,代码里叫pg_loss,pg_loss是由-advantage值*exp(logprobs - old_logprobs)的得到的(刚好就是除的形式),至于advantage就是PPO里TD误差的加权和。这里值得注意的是PPO中的核心改进就是上面exp(logprobs - old_logprobs)控制在[1-\epi和1+\epi]之间做了CLIP。另外需要注意的是advantage是由rewards来得到的,rewards里增加了kl_penalty
- critic的loss,代码里叫vf_loss(value function loss),我们都有一个由Critic预测出的预期回报值V,以及一个真实的回报值G(returns),这俩MSE就是critic的loss。值得注意的是由大batch得到的values和小batch得到的vpreds也做了clip,values就是由critic模型输出的那个values。values和logits都是由LLM输出,代码中会给LLM加一个PreTrainedModelWrapper
- (optional) LM的loss,这个在TRL库里没有
- (optional) actor里可能会加一个entropy loss来让每一步动作更加均匀,但是在TRL的实现中并没有找到这个。
PPO训练中loss下降不能代表全部问题,以下几个指标也经常关注:
- reward系列: 希望reward可以平稳上升,reward->advantage->pg_loss
- kl系列:期望和ref模型距离不要太远
- PPL(perplexity系列):语言模型
PPO过程中有4个模型,这4个都可以放一个大语言模型,导致显存要占4倍,也可以做一些优化:
- SFT Model: 一般会把LM做一遍SFT,保证Policy Model距离语言模型不要太远
- Policy Model: 最终得到的LM
- Reward Model(RM):怎么评估rewards,例如计算器简单来说就是结果对不对,对得1分,不对得0分;对于toxic来说就是有没有毒
- Value Model:也可以叫Critic Model,评估当前状态下的期望收益。这个可以给Policy Model加一个Linear,省一些模型空间
下图来自论文Secrets of RLHF in Large Language Models Part I: PPO:
一图拆解RLHF中的PPO
以下转载自:强化学习从零到RLHF(八)一图拆解RLHF中的PPO


影响PPO算法性能的10个关键技巧
以下转载自:影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)


你会PPO算法吗?那这些问题你知道答案吗?
以下部分部分摘录自 你会PPO算法吗?那这些问题你知道答案吗?
PPO算法的全称是什么?
PPO算法的全称是Proximal Policy Optimization,中文可以翻译为近端策略优化。
PPO算法是为了解决什么问题而设计的?
PPO (Proximal Policy Optimization) 算法是为了解决深度强化学习中策略优化的问题而设计的。具体来说,它旨在解决以下几个关键问题:
- 样本效率:在深度强化学习中,高样本效率是非常重要的。PPO通过使用一种特殊的目标函数,尽量减少所需的样本数量,从而提高样本效率。
- 稳定性和健壮性:在强化学习中,训练过程往往容易受到不稳定和崩溃的影响。PPO通过限制策略更新的步长,以确保训练过程的稳定性,并避免由于过大的策略更新而导致的性能下降。
- 简单和通用性:PPO试图在简单和通用性之间找到平衡。它的设计目标是在不同的任务和环境中都能表现良好,且实现简单,容易理解和使用。
- 解决信任区域优化的问题:传统的信任区域方法(例如TRPO)往往在求解优化问题时需要更多的计算资源和时间。PPO通过引入一种简化的目标函数来避免这些复杂的计算,同时仍然保持了信任区域的思想,即在更新策略时不偏离当前策略太远。
PPO通过其特定的目标函数和优化技术,能够在许多不同的任务和环境中实现高效、稳定的学习,使其成为当前强化学习领域中非常流行和广泛应用的算法之一。
PPO算法相较于其他强化学习算法如DQN或TRPO有什么优势?
PPO (Proximal Policy Optimization) 算法相较于其他强化学习算法如DQN (Deep Q-Network) 或 TRPO (Trust Region Policy Optimization) 有几方面的优势:
- 稳定性和样本效率:PPO通过限制策略更新的大小,提供了一种稳定的训练过程,避免了大的策略更新可能导致的训练不稳定。相比之下,DQN可能会在某些情况下表现出不稳定的训练行为。PPO还通过使用旧的策略样本来提高样本效率,而DQN通常需要更多的样本来实现良好的性能。
- 处理连续动作空间: PPO能够很好地处理连续的动作空间,这使得它在诸如机器人控制和自动驾驶等连续控制任务中特别有用。而DQN更适合于离散动作空间的任务。
- 简化和实用性:PPO的实现相对简单,容易理解,而且它不需要复杂的调参就能在许多任务中表现良好。相比之下,DQN和TRPO可能需要更多的调参和技巧来获得良好的性能。
- 算法效率:PPO通过近似解决TRPO中的优化问题,大大减少了计算要求,同时保持了TRPO的核心思想。这使得PPO在计算效率上具有优势,特别是与TRPO比较。
- 通用性:PPO被设计为一种通用的算法,能够在多种不同的任务和环境中表现良好。它的目标是在简单性和性能之间找到一个好的平衡,使其成为一种非常实用和广泛应用的算法。
- 超参数敏感性:PPO通常被认为是相对不太敏感于超参数选择的,这意味着它在不同的任务和环境中可能不需要太多的超参数调整。而DQN和TRPO可能会更敏感于超参数的选择。
通过这些优势,PPO为强化学习社区和实际应用提供了一个高效、稳定和通用的算法选择。
PPO中的clip函数有什么作用?
在PPO(Proximal Policy Optimization,近端策略优化)算法中,clip函数起着至关重要的作用。它是用来确保策略更新保持在一个合理的范围内,以保证训练的稳定性和避免过大的策略变化。以下是clip函数在PPO中的主要作用:
限制策略更新:Clip函数通过限制目标函数的值,从而限制了策略更新的大小。这确保了新策略不会偏离旧策略太远,有助于保持训练过程的稳定性。
避免过优化:在传统的策略梯度方法中,如果单步更新太大,可能会导致过优化和性能下降。Clip函数通过限制单步更新的大小,有助于避免过优化的问题。
增加样本效率:Clip函数通过限制策略的变化,使得旧的样本仍然保持有用。这样,算法可以在多个更新中重复使用同一批样本,从而提高样本效率。
保持稳定和高效的学习:通过控制策略更新的大小,Clip函数帮助保持了学习过程的稳定性和高效性,使得PPO能够在多种不同的任务和环境中取得良好的性能。
具体实现中,PPO的clip函数是通过在目标函数中加入一个clip操作来实现的。该函数将比率(新策略与旧策略的比值)限制在一个预定义的范围内,例如[1-
ϵ
\epsilon
ϵ,1+
ϵ
\epsilon
ϵ],其中
ϵ
\epsilon
ϵ是一个小的正数(如0.2)。通过这种方式,PPO确保了策略更新的大小在一个合理的范围内,避免了过大的策略变化和可能的不稳定性,从而实现了稳定和高效的学习。
PPO算法中如何保证数据效率?
在PPO(Proximal Policy Optimization)算法中,数据效率是通过多种方式来保证的,以确保在有限的数据样本上实现有效的学习。以下是PPO算法保证数据效率的主要方式:
- 多次更新: PPO算法通常会对每个数据批次进行多次更新,而不是在每个数据批次上仅执行一次更新。这种方法使得算法能够更好地利用每个数据样本,提高数据效率。
- 使用旧的策略样本: 在传统的强化学习算法中,通常在每次更新策略后丢弃旧的样本。而PPO利用旧的策略样本来进行多次更新,以此来提高样本的利用率和数据效率。
- Clip目标函数: 通过引入clip函数,PPO限制了策略更新的大小,确保新策略不会偏离旧策略太远。这种方法允许算法在多个更新中重复使用相同的数据样本,从而提高数据效率。
- 广义优势估计(GAE): PPO通常与广义优势估计(GAE)结合使用,以减少估计方差并提高样本效率。GAE能够更准确地估计每个状态和动作的优势,从而提高学习效率。
稳定的学习过程: 通过保持学习过程的稳定性,PPO能够避免需要额外的数据来修正不稳定的策略更新。稳定的学习过程可以帮助提高数据效率。 - 效率的优化算法: PPO通过使用效率较高的优化算法,如Adam或TRPO,来确保在有限的数据上实现有效的学习。效率较高的优化算法可以帮助提高数据效率和学习速度。
- 迷你批次学习: PPO通常使用小批量(mini-batch)学习,它允许算法在收集完一小批数据后立即进行更新,而不是等待整个数据集。这种方法可以加速学习过程,提高数据效率。
通过这些设计和技巧,PPO算法能够在有限的数据上实现有效和稳定的学习,使其成为一个数据效率较高的强化学习算法。
PPO中的值函数和优势函数有什么区别?
简单来说就是优势函数是由rewards函数和值函数计算出来的,参考公式(4)

PPO算法中的探索策略是如何实现的?

PPO如何处理连续动作空间的问题?
在处理连续动作空间的问题时,PPO (Proximal Policy Optimization) 采用一种参数化的策略表示,并通过优化算法来更新策略参数,以此来学习一个高效的策略。以下是PPO处理连续动作空间问题的主要方式:
- 参数化的策略表示: 在连续动作空间中,PPO通常使用参数化的高斯策略来表示策略。每个动作由一个高斯分布生成,该分布的均值和方差由神经网络参数化,这个神经网络以状态为输入,并输出动作的均值和方差。
- 学习均值和方差: PPO的目标是学习一个参数化策略的参数,以便在给定状态下生成高效的动作。通过优化算法,PPO能够学习神经网络的参数,从而学习动作的均值和方差,使得生成的动作能够最大化预期的总回报。
- 稳定的优化: 为了保持训练的稳定性,PPO使用了clip目标函数和熵正则化等技术。clip目标函数通过限制策略更新的大小来保持稳定性,而熵正则化通过增加策略的熵来鼓励探索,这两者都有助于在连续动作空间中实现稳定和高效的学习。
- 优势函数: 优势函数评估了在给定状态下采取不同动作的相对优势。通过优势函数,PPO能够识别出哪些动作比平均水平更好,从而指导策略的更新和优化。
- 高效的优化算法: PPO通常使用高效的优化算法,如Adam,来更新策略参数。高效的优化算法能够加速学习过程,并帮助PPO在连续动作空间中找到高效的策略。
- 重复利用样本: PPO通过重复利用同一批数据进行多次更新,以提高数据效率。这种方法允许PPO在收集新数据之前,充分利用已有数据来更新和优化策略。
通过以上几种方法和技术,PPO能够有效地处理连续动作空间的问题,学习一个能够生成高效动作的参数化策略,从而在各种连续控制任务中实现高效和稳定的学习。

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









