









TensorFlow的图对应的shape可以先用print出来debug,拿ptb model里面的build_rnn_graph_lstm代码为例:
import numpy as np
import tensorflow as tf
class SmallConfig(object):
"""Small config."""
init_scale = 0.1
learning_rate = 1.0
max_grad_norm = 5
num_layers = 2
num_steps = 2
hidden_size = 200
max_epoch = 4
max_max_epoch = 13
keep_prob = 1.0
lr_decay = 0.5
batch_size = 3
vocab_size = 10000
def get_lstm_cell(config, is_training):
return tf.contrib.rnn.BasicLSTMCell(config.hidden_size, forget_bias=0.0, state_is_tuple=True, reuse=not is_training)
def build_rnn_graph_lstm(inputs, config, is_training):
"""Build the inference graph using canonical LSTM cells."""
# Slightly better results can be obtained with forget gate biases
# initialized to 1 but the hyperparameters of the model would need to be
# different than reported in the paper.
def make_cell():
cell = get_lstm_cell(config, is_training)
if is_training and config.keep_prob < 1:
cell = tf.contrib.rnn.DropoutWrapper(
cell, output_keep_prob=config.keep_prob)
return cell
cell = tf.contrib.rnn.MultiRNNCell(
[make_cell() for _ in range(config.num_layers)], state_is_tuple=True)
initial_state = cell.zero_state(config.batch_size, tf.float32)
state = initial_state
# Simplified version of tf.nn.static_rnn().
# This builds an unrolled LSTM for tutorial purposes only.
# In general, use tf.nn.static_rnn() or tf.nn.static_state_saving_rnn().
#
# The alternative version of the code below is:
#
# inputs = tf.unstack(inputs, num=config.num_steps, axis=1)
# outputs, state = tf.nn.static_rnn(cell, inputs,
# initial_state=initial_state)
outputs = []
with tf.variable_scope("RNN"):
for time_step in range(config.num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
print("cell_output = ", cell_output)
print("cell_state = ", state)
outputs.append(cell_output)
outputs = tf.reshape(tf.concat(outputs, 1), [-1, config.hidden_size])
return outputs, state
config = SmallConfig()
#inputs = tf.get_variable("inputs", initializer=[[[1.],[2.]], [[3.],[4.]], [[5.],[6.]]])
inputs = tf.placeholder(dtype = tf.float32, shape = [3, 2, 1])
print(inputs)
output, state = build_rnn_graph_lstm(inputs = inputs, config=config, is_training = True)
print("output =", output)
print("state =", state)对应的输出为:
Tensor("Placeholder:0", shape=(3, 2, 1), dtype=float32)
cell_output = Tensor("RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_2:0", shape=(3, 200), dtype=float32)
cell_state = (LSTMStateTuple(c=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/add_1:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/mul_2:0' shape=(3, 200) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/add_1:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_2:0' shape=(3, 200) dtype=float32>))
cell_output = Tensor("RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_5:0", shape=(3, 200), dtype=float32)
cell_state = (LSTMStateTuple(c=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/add_3:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/add_3:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>))
output = Tensor("Reshape:0", shape=(6, 200), dtype=float32)
state = (LSTMStateTuple(c=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/add_3:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/add_3:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'RNN/RNN/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>))
但如果用注释中的代码:
import numpy as np
import tensorflow as tf
class SmallConfig(object):
"""Small config."""
init_scale = 0.1
learning_rate = 1.0
max_grad_norm = 5
num_layers = 2
num_steps = 2
hidden_size = 200
max_epoch = 4
max_max_epoch = 13
keep_prob = 1.0
lr_decay = 0.5
batch_size = 3
vocab_size = 10000
def get_lstm_cell(config, is_training):
return tf.contrib.rnn.BasicLSTMCell(config.hidden_size, forget_bias=0.0, state_is_tuple=True, reuse=not is_training)
def build_rnn_graph_lstm(inputs, config, is_training):
"""Build the inference graph using canonical LSTM cells."""
# Slightly better results can be obtained with forget gate biases
# initialized to 1 but the hyperparameters of the model would need to be
# different than reported in the paper.
def make_cell():
cell = get_lstm_cell(config, is_training)
if is_training and config.keep_prob < 1:
cell = tf.contrib.rnn.DropoutWrapper(
cell, output_keep_prob=config.keep_prob)
return cell
cell = tf.contrib.rnn.MultiRNNCell(
[make_cell() for _ in range(config.num_layers)], state_is_tuple=True)
initial_state = cell.zero_state(config.batch_size, tf.float32)
state = initial_state
# Simplified version of tf.nn.static_rnn().
# This builds an unrolled LSTM for tutorial purposes only.
# In general, use tf.nn.static_rnn() or tf.nn.static_state_saving_rnn().
#
# The alternative version of the code below is:
#
inputs = tf.unstack(inputs, num=config.num_steps, axis=1)
outputs, state = tf.nn.static_rnn(cell, inputs,
initial_state=initial_state)
# outputs = []
# with tf.variable_scope("RNN"):
# for time_step in range(config.num_steps):
# if time_step > 0: tf.get_variable_scope().reuse_variables()
# (cell_output, state) = cell(inputs[:, time_step, :], state)
# print("cell_output = ", cell_output)
# print("cell_state = ", state)
# outputs.append(cell_output)
# outputs = tf.reshape(tf.concat(outputs, 1), [-1, config.hidden_size])
return outputs, state
config = SmallConfig()
#inputs = tf.get_variable("inputs", initializer=[[[1.],[2.]], [[3.],[4.]], [[5.],[6.]]])
inputs = tf.placeholder(dtype = tf.float32, shape = [3, 2, 1])
print(inputs)
output, state = build_rnn_graph_lstm(inputs = inputs, config=config, is_training = True)
print("output =", output)
print("state =", state)对应的输出为:
Tensor("Placeholder:0", shape=(3, 2, 1), dtype=float32)
output = [<tf.Tensor 'rnn/rnn/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_2:0' shape=(3, 200) dtype=float32>, <tf.Tensor 'rnn/rnn/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>]
state = (LSTMStateTuple(c=<tf.Tensor 'rnn/rnn/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/add_3:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'rnn/rnn/multi_rnn_cell/cell_0/cell_0/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>), LSTMStateTuple(c=<tf.Tensor 'rnn/rnn/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/add_3:0' shape=(3, 200) dtype=float32>, h=<tf.Tensor 'rnn/rnn/multi_rnn_cell/cell_1/cell_1/basic_lstm_cell/mul_5:0' shape=(3, 200) dtype=float32>))
所以总结一下,PTB LSTM的输入每次都是一批单词,大小为batch_size, 例如以下官网上的例子,其中每一个time_steps都会投一批词进去,这就是inputs的shape为[batch_size, time_steps, embedding_size],至于第三维参数,取决于Embedding的方法。
t=0 t=1 t=2 t=3 t=4
[The, brown, fox, is, quick]
[The, red, fox, jumped, high]
words_in_dataset[0] = [The, The]
words_in_dataset[1] = [brown, red]
words_in_dataset[2] = [fox, fox]
words_in_dataset[3] = [is, jumped]
words_in_dataset[4] = [quick, high]
batch_size = 2, time_steps = 5用一张图来展示多层LSTM状态的变化:
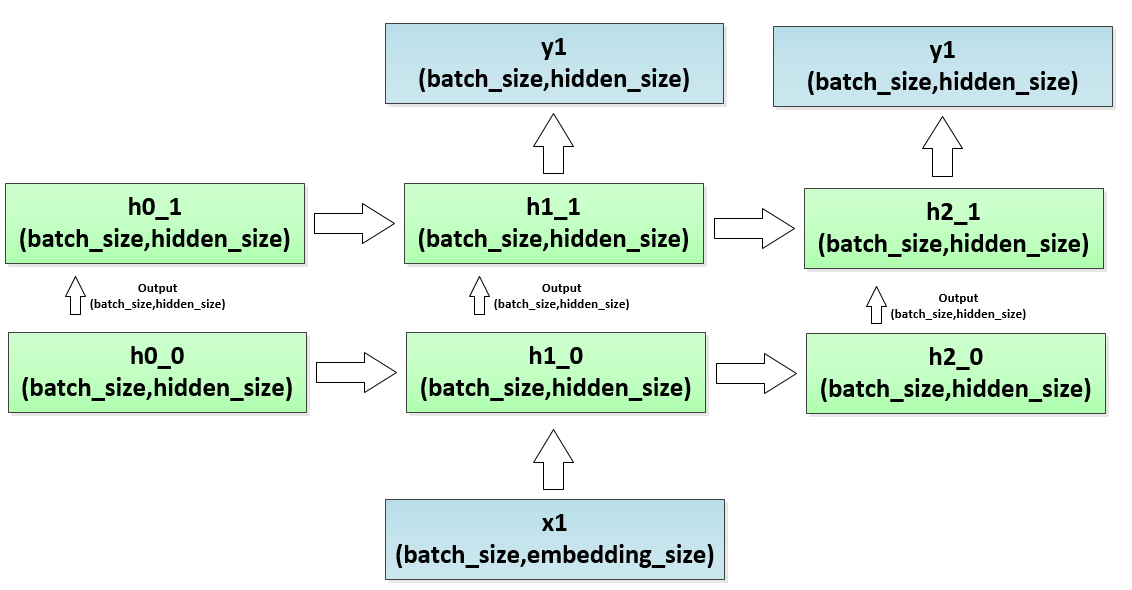
这正和http://blog.csdn.net/taoqick/article/details/79475350 一文中最后一图成对应的关系。















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









