







 本文介绍三种不同的CNN加速器设计方案:基于软硬件协同优化的方法提高性能;SmartExchange通过压缩技术实现成本效益;unzipFPGA利用权重实时生成降低存储需求。
本文介绍三种不同的CNN加速器设计方案:基于软硬件协同优化的方法提高性能;SmartExchange通过压缩技术实现成本效益;unzipFPGA利用权重实时生成降低存储需求。
- 题目:High Performance CNN Accelerators Based on Hardware and Algorithm Co-Optimization
- 时间:2020
- 期刊:TCAS-1
- 研究机构:南大
1 introduction
本篇论文的主要贡献:软硬件协同优化
- 网络压缩:将网络层分成两种:不剪枝的层与剪枝的层,剪枝的层网络压缩率较高,不剪枝的层取数比较规则
- 剪枝的层:量化成2的指数,只用移位加法
- 不剪枝的层:基于FIR滤波器计算卷积

前面几层权重规模小,且更敏感,最好不剪枝;后面几层权重规模很大,更容易冗余,适合剪枝。
2 硬件架构
基于FIR的卷积结构,计算非剪枝层
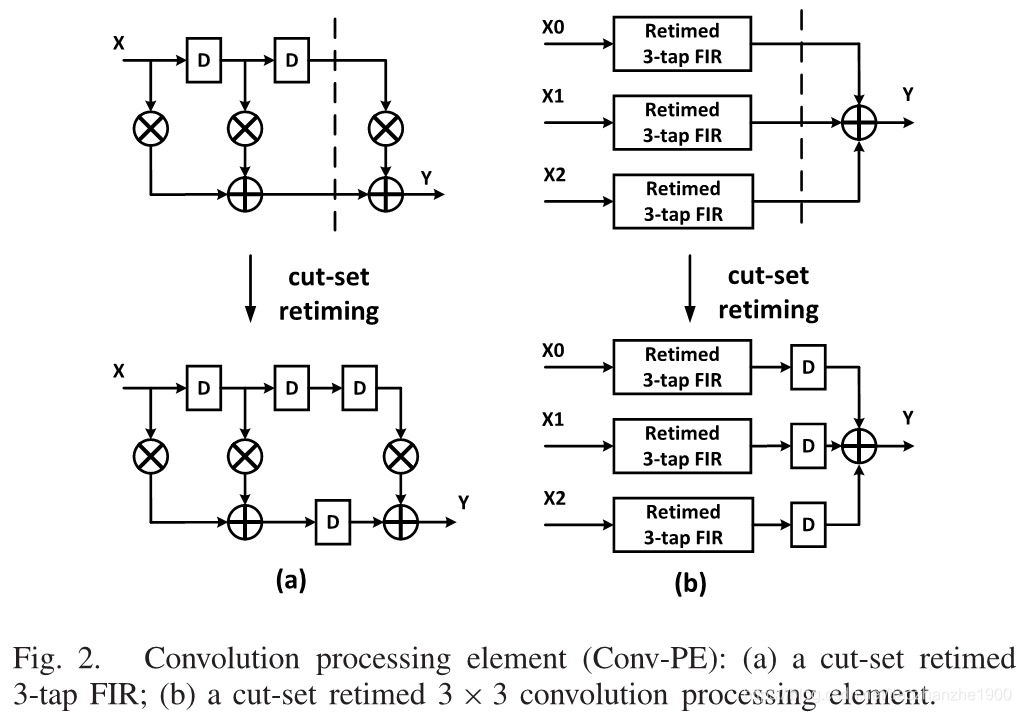
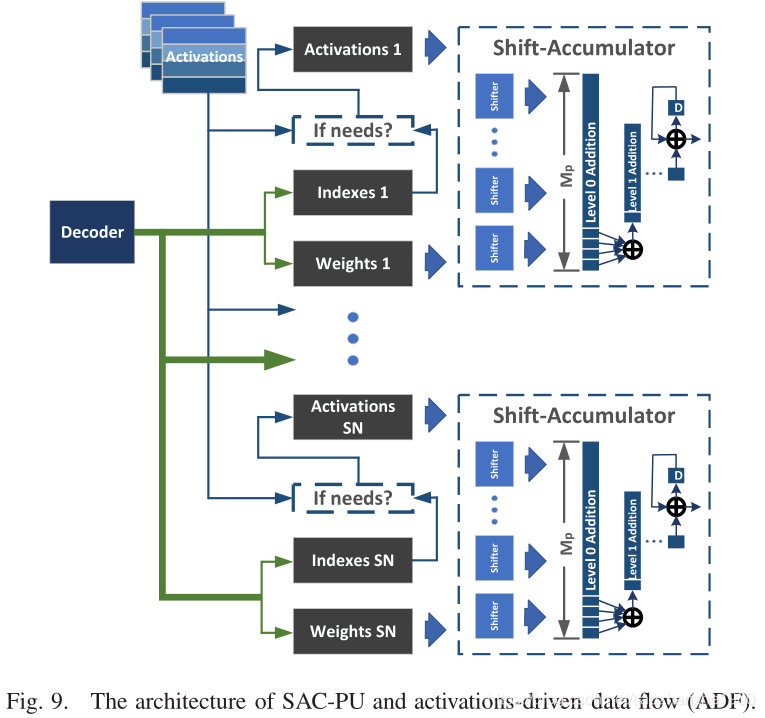
对于剪枝的层,需要decode + 移位器 + 加法术
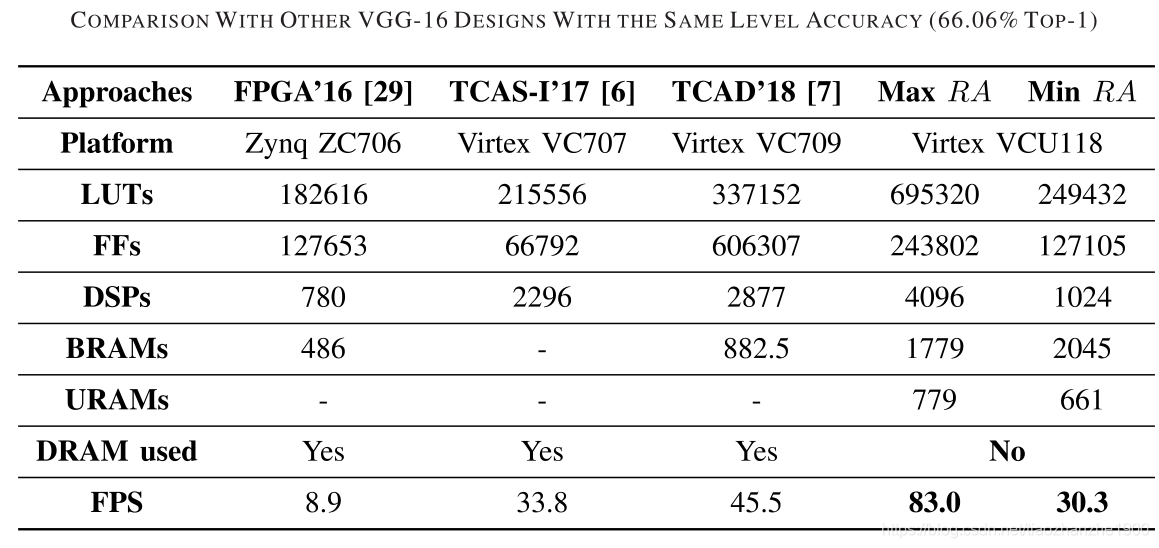
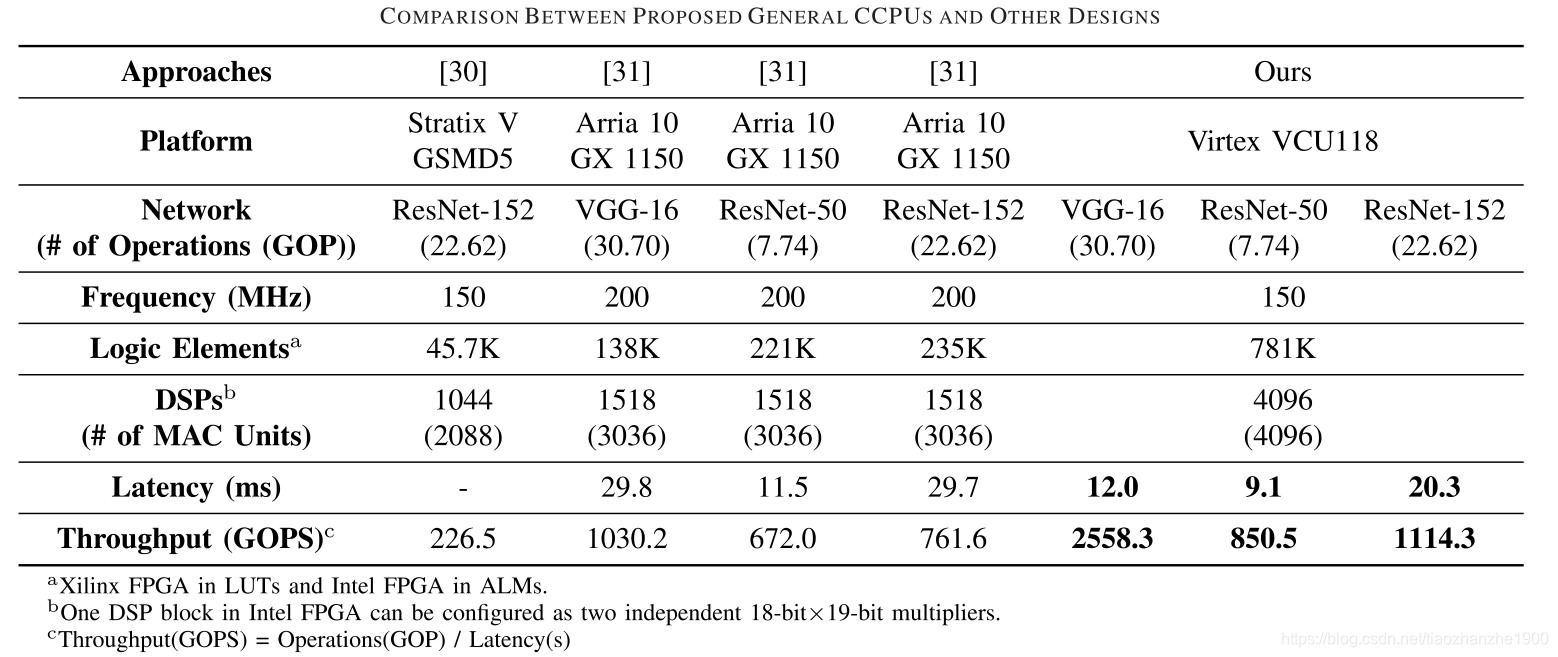
3 实验结果
- 网络层: VGG16
- FPGA: VCU118
- 题目:SmartExchange: Trading Higher-cost Memory Storage/Access for Lower-cost Computation
- 时间:2020
- 会议:ISCA
- 研究机构:莱斯大学
1 introduction
本篇论文的主要贡献:
- 融合了剪枝、量化、张量分解,提出了一个压缩方法SmartExchange,本质为通过基向量乘一个较大的稀疏矩阵,得到不同层的权重
- 软硬件协同优化,软件上压缩+硬件加速器RTL设计
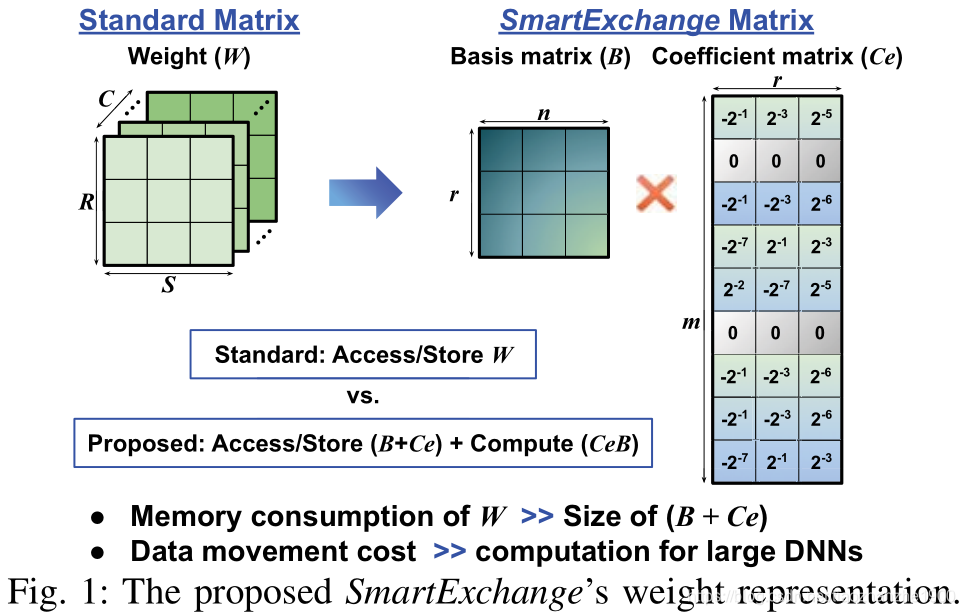
- 题目:unzipFPGA: Enhancing FPGA-based CNN Engines with On-the-Fly Weights Generation
- 时间:2021
- 会议:FCCM
- 研究机构:三星/牛津
1 introduction
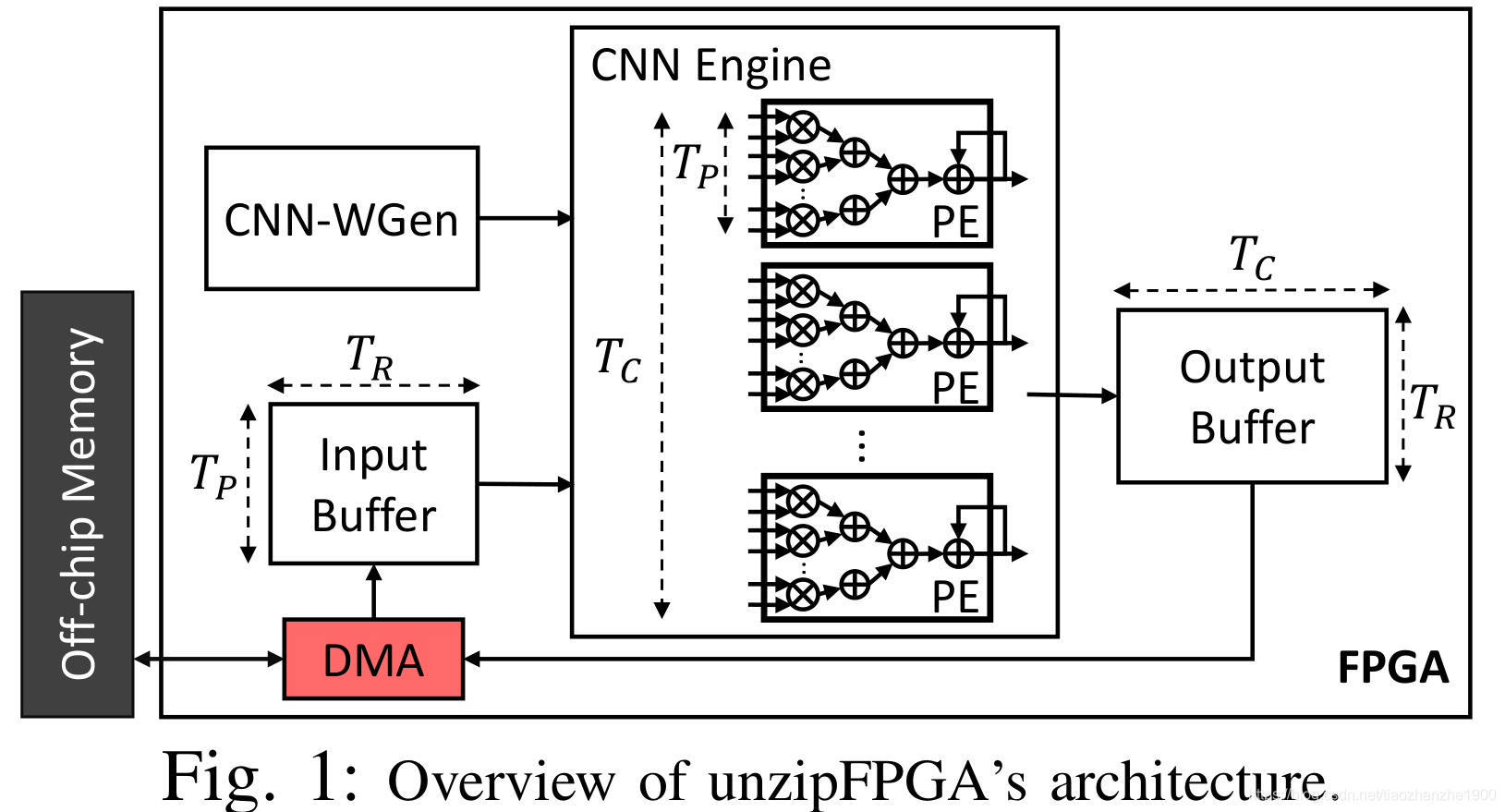
思路就是不直接存权重,而是在需要的时候计算生成,节省权重存储的开销,其实就是计算换存储,减少片外访存次数。
本次实验是用OVSF编码压缩权重的


















 7484
7484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









