






在之前的文章机器学习详解(5):MLP代码详解之MNIST手写数字识别中,我们使用了多层感知机(MLP)对MNIST手语数据集进行了分类。虽然MLP能够在训练数据上取得较高的准确率,但其对验证数据的泛化性能较差,容易出现过拟合问题。此外,MLP无法充分利用图像数据的空间信息,仅将图像像素作为一维输入处理,这限制了其对图像特征的提取能力。
为了解决这些问题,我们引入卷积神经网络(CNN),一种专为处理图像数据设计的模型。CNN通过卷积和池化层有效提取图像的局部特征,同时减少参数量,提高模型的泛化能力,非常适合用于图像分类任务。本节课通过识别American Sign Language(美国手语,ASL)来学习一下CNN。
1 加载和准备数据
1.1 ASL数据集
美国手语(ASL)字母表包含26个字母。其中有两个字母(J和Z)需要通过手势的移动来表示,因此它们没有包含在训练数据集中。
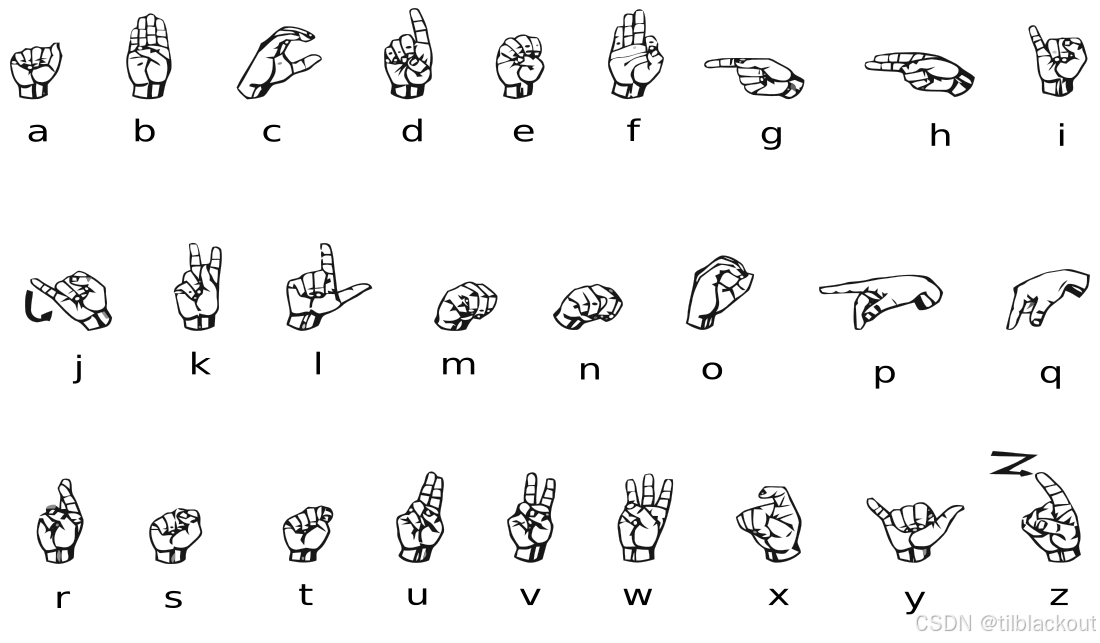
- 这个数据集可以从Kaggle网站获取。
1.2 数据加载
这个数据集不像MNIST那样可以通过TorchVision直接获取,因此我们需要学习如何加载自定义数据。在这一部分结束时,我们将得到四个变量:x_train、y_train、x_valid和y_valid。
1.2.1 数据读取
手语数据集以CSV(逗号分隔值)格式存储,这是一种与Microsoft Excel和Google Sheets相同的数据结构。它是一个带有顶部标签的行列网格,数据在训练集和验证集文件中(加载可能需要一些时间)。
为了加载和处理这些数据,我们使用Pandas的read_csv方法可以读取CSV文件,并返回一个DataFrame对象。
train_df = pd.read_csv("/content/sign_mnist_train.csv")
valid_df = pd.read_csv("/content/sign_mnist_valid.csv")
让我们看一下数据内容。可以使用head方法打印DataFrame的前几行。每一行代表一张图片,其中包含一个标签列和784个像素值(每个值代表图片的一个像素),这与MNIST数据集的结构类似。需要注意的是,这些标签目前是数字,而不是字母。
train_df.head()
输出如下:

1.2.2 提取标签和图片
我们将训练和验证标签分别存储在变量 y_train 和 y_valid 中。可以使用 pop 方法从 DataFrame 中移除某一列,并将移除的值分配给一个变量。
y_train = train_df.pop('label')
y_valid = valid_df.pop('label')
y_train
输出:
label
0 3
1 6
2 2
3 2
4 12
... ...
27450 12
27451 22
27452 17
27453 16
27454 22
27455 rows × 1 columns
接下来,我们将训练和验证图像存储到变量 x_train 和 x_valid 中。以下是创建这些变量的代码:
x_train = train_df.values
x_valid = valid_df.values
x_train
输出:
array([[107, 118, 127, ..., 204, 203, 202],
[155, 157, 156, ..., 103, 135, 149],
[187, 188, 188, ..., 195, 194, 195],
...,
[174, 174, 174, ..., 202, 200, 200],
[177, 181, 184, ..., 64, 87, 93],
[179, 180, 180, ..., 205, 209, 215]])
最后我们看一下最终的输出:
print('x_train.shape:', x_train.shape) # 输出 (27455, 784)
print('y_train.shape:', y_train.shape) # 输出 (27455,)
print('x_valid.shape:', x_valid.shape) # 输出 (7172, 784)
print('y_valid.shape:', y_valid.shape) # 输出 (7172,)
-
图像:
x_train包含 27,455 张图片,每张图片由 784 个像素组成,其形状为(27455, 784)。 -
标签:
y_train包含 27,455 个对应的标签,其形状为(27455,)。 -
图像:
x_valid包含 7,172 张图片,每张图片由 784 个像素组成,其形状为(7172, 784)。 -
标签:
y_valid包含 7,172 个对应的标签,其形状为(7172,)。
1.3 可视化数据
我们需要将当前形状为784像素的一维数据重塑为28x28像素的二维图像,以便更直观地理解图像。
import matplotlib.pyplot as plt
plt.figure(figsize=(40,40))
num_images = 20
for i in range(num_images):
row = x_train[i]
label = y_train[i]
image = row.reshape(28,28)
plt.subplot(1, num_images, i+1)
plt.title(label, fontsize=30)
plt.axis('off')
plt.imshow(image, cmap='gray')
输出大致如下:

1.4 归一化
归一化将像素值从0-255缩放到0-1范围的浮点值,能加快训练收敛速度并防止数值过大导致梯度爆炸。此外,归一化让数据分布更均匀,使模型更容易学习到特征,同时与激活函数更好地匹配,提升训练效果和泛化性能。
x_train.min() # 输出 0
x_train.max() # 输出 255
所以我们除以255就行了:
# x_train = x_train / 255 is also correct
x_train = train_df.values / 255
x_valid = valid_df.values / 255
1.5 模块化
我们将上面的内容整合在一个class里面:
IMG_HEIGHT = 28
IMG_WIDTH = 28
IMG_CHS = 1
# 自定义数据集类,继承自 PyTorch 的 Dataset 基类
class MyDataset(Dataset):
def __init__(self, base_df):
# 创建数据的副本,防止对原始 DataFrame 的操作影响其他代码
x_df = base_df.copy()
# 从数据中移除标签列,同时将标签存储到 y_df 中
y_df = x_df.pop('label')
# 将剩余像素值转换为 NumPy 数组,并进行归一化(从 0-255 缩放到 0-1)
x_df = x_df.values / 255
# 调整形状为 (样本数, 通道数, 宽度, 高度),以适应 CNN 输入格式
x_df = x_df.reshape(-1, IMG_CHS, IMG_WIDTH, IMG_HEIGHT)
# 将 NumPy 数组转换为 PyTorch 张量,并指定为浮点类型,同时移动到设备(CPU/GPU)
self.xs = torch.tensor(x_df).float().to(device)
# 将标签转换为 PyTorch 张量,并移动到设备(CPU/GPU)
self.ys = torch.tensor(y_df).to(device)
def __getitem__(self, idx):
x = self.xs[idx] # 根据索引返回对应的图像张量
y = self.ys[idx] # 根据索引返回对应的标签张量
return x, y # 返回图像和标签
def __len__(self):
return len(self.xs) # 返回数据集的总样本数
1.6 创建DataLoader
DataLoader 是 PyTorch 数据加载的核心工具,它通过分批加载、随机打乱、并行化等机制,使训练和验证过程更加高效和灵活。
BATCH_SIZE = 32
train_data = MyDataset(train_df)
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
train_N = len(train_loader.dataset)
valid_data = MyDataset(valid_df)
valid_loader = DataLoader(valid_data, batch_size=BATCH_SIZE)
valid_N = len(valid_loader.dataset)
MyDataset类可以作为DataLoader的第一个参数,是因为它继承自torch.utils.data.Dataset类,而DataLoader的设计就是为了与Dataset类型对象配合使用的。
现在我们从DataLoader获取一个批处理以确保正常工作:
batch = next(iter(train_loader))
batch
输出
[tensor([[[[0.1490, 0.1529, 0.0235, ..., 0.4706, 0.4824, 0.4863],
[0.1686, 0.1529, 0.0314, ..., 0.4784, 0.4824, 0.4863],
[0.1843, 0.1490, 0.0392, ..., 0.5020, 0.4863, 0.4941],
...,
[0.4078, 0.3216, 0.0000, ..., 0.6118, 0.6157, 0.6235],
[0.4275, 0.2784, 0.0000, ..., 0.6196, 0.6235, 0.6275],
[0.4549, 0.2431, 0.0000, ..., 0.6196, 0.6235, 0.6314]]],
[[[0.6824, 0.7059, 0.7176, ..., 0.7647, 0.7569, 0.7529],
[0.6784, 0.7020, 0.7255, ..., 0.7725, 0.7686, 0.7608],
[0.6863, 0.7098, 0.7294, ..., 0.7725, 0.7725, 0.7647],
...,
[0.5647, 0.5608, 0.5569, ..., 0.8275, 0.7765, 0.6039],
[0.5725, 0.5725, 0.5647, ..., 0.8471, 0.7804, 0.5961],
[0.5686, 0.5725, 0.5647, ..., 0.7725, 0.8863, 0.6471]]],
[[[0.4118, 0.4275, 0.4353, ..., 0.5608, 0.5608, 0.5647],
[0.4157, 0.4314, 0.4392, ..., 0.5647, 0.5647, 0.5647],
[0.4235, 0.4353, 0.4510, ..., 0.5647, 0.5647, 0.5647],
...,
[0.4863, 0.4745, 0.6196, ..., 0.6392, 0.6392, 0.6392],
[0.4667, 0.5451, 0.7216, ..., 0.6431, 0.6392, 0.6353],
[0.4588, 0.5961, 0.7216, ..., 0.6392, 0.6392, 0.6392]]],
...,
[[[0.6706, 0.6706, 0.6745, ..., 0.6510, 0.6471, 0.6471],
[0.6784, 0.6784, 0.6824, ..., 0.6627, 0.6549, 0.6549],
[0.6784, 0.6824, 0.6863, ..., 0.6667, 0.6588, 0.6588],
...,
[0.1333, 0.0941, 0.0745, ..., 0.2196, 0.2431, 0.2314],
[0.1098, 0.0471, 0.1451, ..., 0.2039, 0.2314, 0.2392],
[0.0824, 0.0471, 0.2471, ..., 0.2078, 0.2157, 0.2353]]],
[[[0.4667, 0.4784, 0.4941, ..., 0.5961, 0.5922, 0.5922],
[0.4784, 0.4863, 0.5020, ..., 0.6000, 0.5961, 0.5961],
[0.4941, 0.5020, 0.5176, ..., 0.6078, 0.6039, 0.6039],
...,
[0.7216, 0.7333, 0.7451, ..., 0.8196, 0.8196, 0.8157],
[0.7216, 0.7333, 0.7490, ..., 0.8314, 0.8275, 0.8196],
[0.7255, 0.7373, 0.7529, ..., 0.8353, 0.8314, 0.8275]]],
[[[0.7333, 0.7490, 0.7608, ..., 0.7490, 0.7412, 0.7333],
[0.7412, 0.7529, 0.7647, ..., 0.7569, 0.7490, 0.7412],
[0.7490, 0.7608, 0.7725, ..., 0.7647, 0.7569, 0.7529],
...,
[0.5451, 0.5569, 0.5647, ..., 0.4078, 0.4392, 0.3137],
[0.5529, 0.5647, 0.5569, ..., 0.3451, 0.4314, 0.3765],
[0.5725, 0.5686, 0.5686, ..., 0.2902, 0.3804, 0.4039]]]]),
tensor([21, 19, 5, 4, 6, 11, 3, 3, 2, 4, 20, 12, 20, 21, 2, 16, 12, 18,
5, 2, 8, 8, 2, 18, 16, 16, 21, 6, 3, 6, 16, 16])]
-
iter(train_loader)将train_loader转换为一个 迭代器。 -
next(iterator):从迭代器中获取下一个批次的数据。- 从
train_loader中获取一个小批次的(x_batch, y_batch)。其中x_batch是当前批次的图像张量,y_batch是当前批次的标签张量。
- 从
再来输出一下单个batch的形状:
batch[0].shape # 输出torch.Size([32, 1, 28, 28])
batch[1].shape # 输出torch.Size([32])
batch[0]:形状为[32, 1, 28, 28],表示批次中的图像数据。batch[1]:形状为[32],表示批次中图像对应的标签。
2 创建卷积模型
2.1 CNN层设计
在设计卷积神经网络(CNN)时,通常会参考现有的经典模型架构,如LeNet、AlexNet、ResNet等。这些模型在各种任务中表现出色,其设计理念和结构为新模型的开发提供了宝贵的指导。通过借鉴这些成熟模型的设计,可以更有效地构建适用于特定任务的网络结构。
大多数情况下,我们会利用现有的模型来加速开发。只要问题不是完全独特的,通常可以在像 TensorFlow Hub或 NGC Catalog 这样的在线资源库中找到性能良好的模型。对于我们的任务,我们将使用一个现有的模型来实现解决方案。
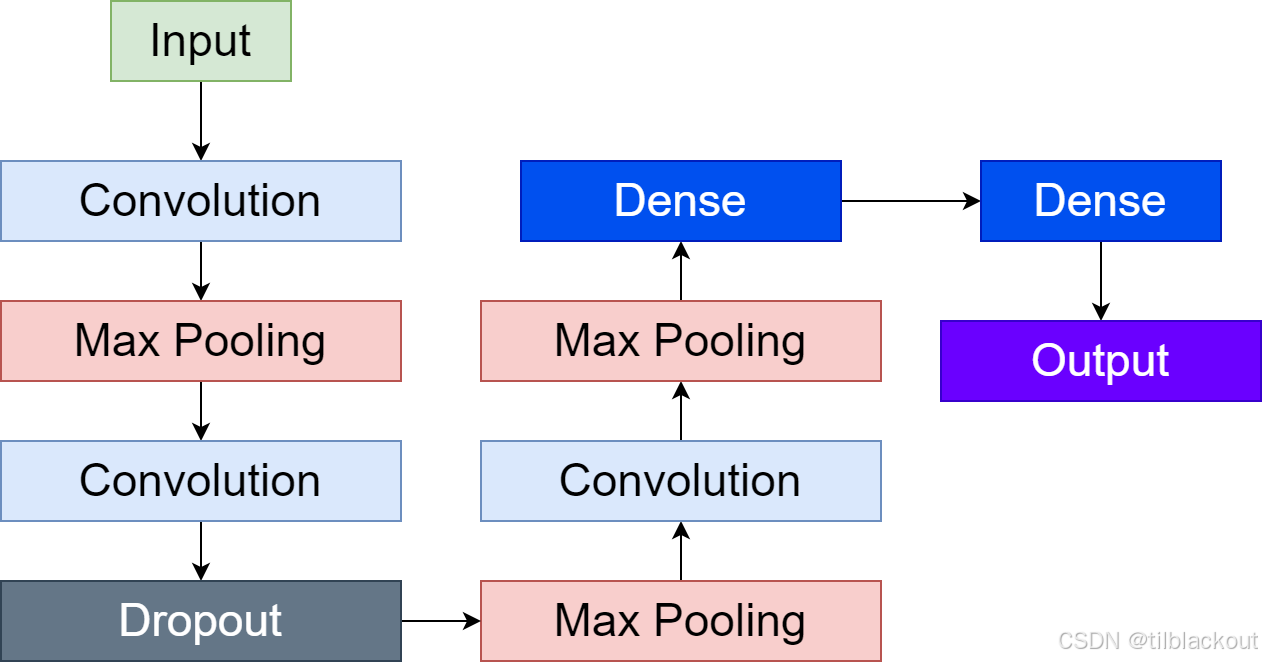
1. 为什么选择三层卷积层
(1) 提取多层次特征
卷积层的主要作用是从输入数据中提取特征。每一层卷积都会提取不同层次的特征:
- 第一层卷积:捕获低级特征,如边缘、线条。
- 第二层卷积:捕获中级特征,如角点、形状。
- 第三层卷积:捕获高级特征,如模式、局部纹理。
在任务中,手语字母的图像包含丰富的细节(如手指形状),三层卷积可以逐步从低层次到高层次提取信息。
(2) 控制模型复杂度
- 如果卷积层太少,模型可能无法捕获足够的特征,从而导致低精度。
- 如果卷积层过多,网络可能过于复杂,导致过拟合或训练困难。
- 三层卷积是对任务复杂性(28x28 手语图像)的一种平衡选择。
2. 为什么在第二个卷积层和池化层之间添加 Dropout
(1) Dropout 的作用
- Dropout 在训练时随机丢弃一定比例的神经元(如这里的 20%),防止模型过拟合,提高泛化能力。
- Dropout 的主要作用是正则化,确保模型在训练数据有限的情况下不会记忆数据而是学习特征。
(2) 为什么选择在第二层卷积后
- 防止中级特征过拟合。
- 第二层卷积已经提取了中级特征(如形状、角点)。如果不加正则化,模型可能会过度依赖这些特征,导致对训练数据拟合过度。
- 通过 Dropout 随机丢弃一部分神经元,可以强迫模型在第三层卷积时学习更多冗余特征。
- 模型对高层特征更敏感。
- Dropout 放在更高层(如第三层卷积后)可能会影响高级特征的学习效果。
- 因此在第二层卷积后加入 Dropout 是一个合理的选择,可以对中间特征进行正则化,而不干扰低级或高级特征的学习。
3. 为什么要两个全连接层
(1) 全连接层的作用
- 全连接层的主要作用是将卷积层提取的特征向量映射到分类结果。
- 在展平后的特征向量中(
75 x 3 x 3 = 675),可能包含冗余信息。通过两层全连接,逐步提取最重要的特征,提高分类性能。
(2) 为什么不是一层全连接
- 第一层全连接
- 将 675 个特征映射到 512 个隐藏单元,降低维度,同时压缩特征,使网络对冗余特征的依赖减少。
- ReLU 激活函数增加了非线性,使模型能够学习更复杂的关系。
- 第二层全连接:从 512 个隐藏单元映射到最终的 24 个输出类别,完成分类任务。
(3) 多层全连接的好处
- 提高模型的学习能力:两层全连接能更好地拟合特征与类别之间的复杂映射关系。
- 增强非线性能力:多层全连接配合 ReLU,使模型能够学习更复杂的非线性决策边界。
- 降低过拟合风险:在第一层全连接后加入 Dropout(30%)进一步防止过拟合。
2.2 代码分析
2.2.1 回顾与深入
在上一篇文章中,我们简单了介绍了Dropout和归一化,这里再更深地讨论一下。
2.2.1.1 Dropout
Dropout 是一种防止过拟合的技术。Dropout 随机选择一部分神经元,将它们关闭,使它们在特定的前向传播或反向传播过程中不参与计算。这有助于确保网络具有鲁棒性和冗余性,并且不依赖于某一个部分来给出答案。
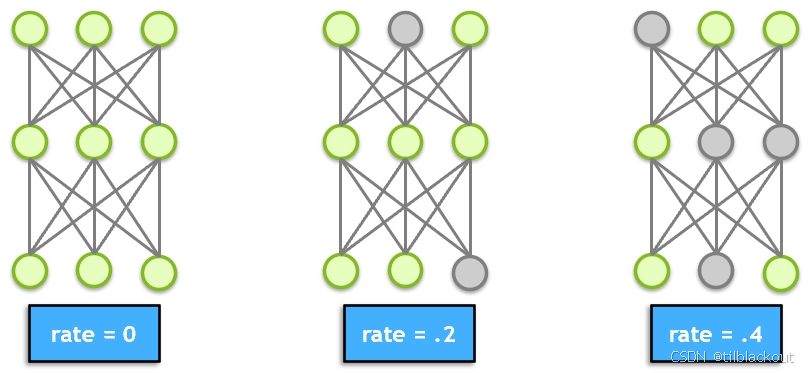
Dropout 是一种随机操作,每个神经元都有一定的概率被屏蔽。如果 Dropout 率是 20%,意味着每个神经元有 20% 的概率被屏蔽,80% 的概率被保留。不是说上面有9个就有2(1.8四舍五入为2)个神经元被屏蔽,而是每个神经元根据这个概率分别计算是否被屏蔽。
对于神经元来说,在训练阶段和测试阶段的目的不同:
训练阶段:
- Dropout 随机丢弃一定比例的神经元(如 20%)。
- 被丢弃的神经元在当前前向传播和反向传播中不参与计算(输出为 0,梯度也不更新)。
- 这样可以强迫网络依赖更多不同的神经元,而不是仅仅依赖部分特定神经元,达到正则化效果。
推理(测试)阶段:
- 所有神经元都会参与计算(没有神经元被丢弃)。
- 为了与训练阶段保持一致性,Dropout 会自动对神经元的输出值乘以一个系数(通常是训练阶段保留神经元的比例,如
0.8),相当于对权重进行缩放。
2.2.1.2 Batch Normalization
像对输入进行标准化一样,批量归一化(Batch Normalization, BN)通过缩放隐藏层中的值来提升训练效果。可以参考这篇文章Intro to Optimization in Deep Learning: Busting the Myth About Batch Normalization来详细理解一下批量归一化是如何起作用的。
这篇文章中的内部协变量转移(Internal Covariate Shift, ICS)是指神经网络训练中,层与层之间输入分布随训练动态变化的问题,可能导致模型收敛缓慢甚至不稳定。尽管 BN 并未真正解决 ICS,但通过平滑损失表面、控制激活统计特性、提供正则化效果以及减少层间权重更新的干扰,它显著加速了训练并提升了模型性能。BN的作用大致如下:
- 加速训练:BN使得网络对学习率的选择更加宽容,支持更高的学习率,从而缩短训练时间。
- 稳定收敛:在深层网络中,BN避免了因梯度爆炸或消失导致的不稳定收敛问题。
- 减少超参数调优的复杂性:BN减少了对初始权重和学习率的依赖,使模型更容易训练。
2.2.1.3 Dropout和Batch Normalization的顺序问题
批量归一化(Batch Normalization, BN)和 Dropout 时,它们之间的顺序可能会影响模型的训练和测试表现。关于批量归一化层的最佳位置存在争议。可以参考一下这篇文章Ordering of batch normalization and dropout。基于帖子中的回答,我总结了如下内容:
推荐顺序:优先采用 BN → 激活函数(如 ReLU)→ Dropout,这样可以避免 Dropout 干扰 BN 的参数估计,确保训练和测试阶段分布一致。如果发现问题,可以考虑完全去掉 Dropout。
是否使用 Dropout:
- 深度网络(如 ResNet、DenseNet):通常只使用 BN,省略 Dropout。
- 小数据集或易过拟合任务:可以保留 Dropout,确保其顺序与 BN 配置合理。
2.2.2 代码详解
首先定义一下我们后面需要用到的变量:
n_classes = 24
kernel_size = 3
flattened_img_size = 75 * 3 * 3
n_classes = 24: 输出类别的数量(例如,手语字母 A 到 Z,排除 J 和 Z)。kernel_size = 3: 卷积核大小为 3x3。flattened_img_size = 75 * 3 * 3: 经过所有卷积层和池化层后,特征图展平的总大小。
以下就是我们整个层的代码:
model = nn.Sequential(
# 第一组卷积
nn.Conv2d(IMG_CHS, 25, kernel_size, stride=1, padding=1), # 25 x 28 x 28
nn.BatchNorm2d(25),
nn.ReLU(),
nn.MaxPool2d(2, stride=2), # 25 x 14 x 14
# 第二组卷积
nn.Conv2d(25, 50, kernel_size, stride=1, padding=1), # 50 x 14 x 14
nn.BatchNorm2d(50),
nn.ReLU(),
nn.Dropout(.2),
nn.MaxPool2d(2, stride=2), # 50 x 7 x 7
# 第三组卷积
nn.Conv2d(50, 75, kernel_size, stride=1, padding=1), # 75 x 7 x 7
nn.BatchNorm2d(75),
nn.ReLU(),
nn.MaxPool2d(2, stride=2), # 75 x 3 x 3
# 展平到全连接层
nn.Flatten(),
nn.Linear(flattened_img_size, 512),
nn.Dropout(.3),
nn.ReLU(),
nn.Linear(512, n_classes)
)
下面一段段来分析一下上面的代码。
2.2.2.1 卷积层
第一部分:第一组卷积和池化
nn.Conv2d(IMG_CHS, 25, kernel_size, stride=1, padding=1), # 25 x 28 x 28
nn.BatchNorm2d(25),
nn.ReLU(),
nn.MaxPool2d(2, stride=2), # 25 x 14 x 14
-
nn.Conv2d(IMG_CHS, 25, kernel_size, stride=1, padding=1):- 卷积层,输入通道数为
IMG_CHS(灰度图为 1),输出 25 个通道,意味着卷积层会有 25 个不同的 3x3 卷积核(滤波器),每个卷积核提取输入图像的不同特征。 - 卷积核大小为 3x3,步幅为 1,填充确保输出大小与输入相同。
- 卷积层,输入通道数为
-
nn.BatchNorm2d(25): 对 25 个特征图进行归一化,提升训练稳定性。这个25和卷积层的输出特征个数对应。 -
nn.ReLU(): 引入非线性,提高模型的特征表达能力。 -
nn.MaxPool2d(2, stride=2): 最大池化层,将特征图尺寸从 28x28 减小到 14x14。kernel_size=2:定义池化窗口的大小,取每个 2x2 区域的最大值。stride=2:定义窗口滑动的步幅,每次滑动 2 个像素,导致特征图的尺寸减半。
第二部分:第二组卷积和池化
nn.Conv2d(25, 50, kernel_size, stride=1, padding=1), # 50 x 14 x 14
nn.BatchNorm2d(50),
nn.ReLU(),
nn.Dropout(.2),
nn.MaxPool2d(2, stride=2), # 50 x 7 x 7
-
nn.Conv2d(25, 50, kernel_size, stride=1, padding=1):- 卷积层,输入 25 个通道,输出 50 个通道,同时保持空间大小。
-
nn.BatchNorm2d(50): 对 50 个特征图进行归一化。 -
nn.ReLU(): 引入非线性。 -
nn.Dropout(.2): 随机丢弃 20% 的神经元,减少过拟合。 -
nn.MaxPool2d(2, stride=2): 最大池化层,将特征图尺寸从 14x14 减小到 7x7。
第三部分:第三组卷积和池化
nn.Conv2d(50, 75, kernel_size, stride=1, padding=1), # 75 x 7 x 7
nn.BatchNorm2d(75),
nn.ReLU(),
nn.MaxPool2d(2, stride=2), # 75 x 3 x 3
-
nn.Conv2d(50, 75, kernel_size, stride=1, padding=1):- 卷积层,输入 50 个通道,输出 75 个通道。
-
nn.BatchNorm2d(75): 对 75 个特征图进行归一化。 -
nn.ReLU(): 引入非线性。 -
nn.MaxPool2d(2, stride=2): 最大池化层,将特征图尺寸从 7x7 减小到 3x3。
2.2.2.1.1 卷积层Q&A
我们发现,每经过一层卷积层,特征图的尺寸越来越小,而特征图的数量却越来越多,接着来探讨一下下面三个问题:
1. 为什么特征图尺寸逐步减小?
- 逐步聚焦局部特征到全局特征:
- 初始层的特征图尺寸较大,可以捕捉输入图像的低级特征(如边缘、线条)。
- 随着网络的加深,池化层和卷积层逐步缩小特征图尺寸,使模型从更大的感受野(receptive field)中学习特征。
- 最终的高层特征图(小尺寸)表示图像的全局特征。
- 减少计算复杂度:每个卷积层的计算复杂度与特征图的尺寸成正比。随着层数增加,缩小特征图的尺寸可以显著降低计算量,尤其是在深层网络中。
- 防止过拟合:减少特征图尺寸,相当于降低数据表示的维度,可以减少冗余特征,降低过拟合的风险。
2. 为什么特征图数量逐步增加?
- 提取更多的特征:
- 初始卷积层提取的是简单特征(如边缘、角点)。
- 随着网络加深,模型需要学到更复杂的中级和高级特征(如形状、纹理、模式)。
- 增加特征图数量(通道数)意味着引入更多的卷积核,让模型能捕获更多种类的特征。
- 特征表达能力增强:特征图数量增加相当于增加了网络的表达能力。更高的通道数让模型对图像内容的细节和模式有更强的区分能力。
- 为全连接层提供丰富输入:在 Flatten 后,模型需要将所有特征图展平为向量输入全连接层。如果通道数太少,可能会导致全连接层输入信息不足,降低分类性能。
3. 这样设计是否必要?
不一定,以下是不同情况的分析:
- 优点:逐渐减小特征图尺寸可以减少计算量,同时聚焦更重要的特征。逐渐增加通道数可以提升特征表达能力,支持更复杂的分类任务。
- 缺点:
- 如果特征图尺寸始终保持大:计算复杂度会急剧上升。模型可能捕获太多细节,但对全局特征的学习不足。
- 如果特征图数量始终保持少:表达能力不足,无法捕捉复杂的特征模式,降低分类性能。
- 根据任务调整:
- 对于简单任务(如 MNIST 手写数字识别),可以减少层数或特征图数量,避免过度设计。
- 对于复杂任务(如图像分割、目标检测),缩小尺寸、增加通道非常重要。
2.2.2.2 全连接层
nn.Flatten(),
nn.Linear(flattened_img_size, 512),
nn.Dropout(.3),
nn.ReLU(),
nn.Linear(512, n_classes)
-
nn.Flatten(): 将 3D 特征图(75, 3, 3)展平为一维向量,大小为 675。 -
nn.Linear(flattened_img_size, 512): 全连接层,将 675 个输入特征映射到 512 个输出特征。 -
nn.Dropout(.3): 随机丢弃 30% 的神经元,减少过拟合。 -
nn.ReLU(): 引入非线性。 -
nn.Linear(512, n_classes): 最后一层全连接层,将特征映射到 24 个类别的输出。
2.2.2.3 损失函数和优化器
1. 损失函数(Loss Function):
- 使用了
nn.CrossEntropyLoss(),这是用于分类任务的常见损失函数。 - 该函数结合了 softmax 和 负对数似然损失(Negative Log Likelihood Loss),适合多分类问题。
2. 优化器(Optimizer):
- 使用了
Adam优化器(torch.optim.Adam),结合了动量和自适应学习率方法,能快速收敛且在实践中效果较好。 - 在 ASL 手语图像分类任务中,不同手势的特征可能高度稀疏(比如某些手势只影响部分像素区域),Adam 对稀疏梯度的处理能力较强。
代码如下:
loss_function = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters())
2.2.2.4 准确率计算函数
计算一个批次数据的分类准确率:
def get_batch_accuracy(output, y, N):
# 取预测结果中得分最高的类别索引,保持结果维度
pred = output.argmax(dim=1, keepdim=True)
# 将真实标签的形状调整为与预测结果一致,并计算预测正确的数量
correct = pred.eq(y.view_as(pred)).sum().item()
# 返回准确率,正确数量 / 总样本数
return correct / N
参数:
- output: 模型的输出张量,形状为 (
batch_size,num_classes),每行是每个样本对各类别的预测得分。 - y: 真实标签张量,形状为 (
batch_size,),每个元素是样本的真实类别。 - N: 当前批次的样本数量(即
batch_size)。
2.2.3 训练模型
2.2.3.1 编译模型
torch.compile 是 PyTorch2.0 引入的新特性,用于加速模型的训练和推理。
model = torch.compile(model.to(device))
model
输出:
OptimizedModule(
(_orig_mod): Sequential(
(0): Conv2d(1, 25, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(25, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(25, 50, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU()
(7): Dropout(p=0.2, inplace=False)
(8): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(9): Conv2d(50, 75, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): BatchNorm2d(75, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU()
(12): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(13): Flatten(start_dim=1, end_dim=-1)
(14): Linear(in_features=675, out_features=512, bias=True)
(15): Dropout(p=0.3, inplace=False)
(16): ReLU()
(17): Linear(in_features=512, out_features=24, bias=True)
)
)
torch.compile 将模型包装为一个经过优化的模型对象,具体执行过程如下:
- 捕获计算图:
- 在模型的前向传播中,PyTorch 会捕获模型的计算图。
- 计算图表示张量操作的顺序和依赖关系。
- 编译优化:
- PyTorch 使用后台优化工具(如 TorchDynamo 和 AOTAutograd)对计算图进行优化,包括:
- 操作融合:将多个小的操作合并为一个大操作。
- 内存优化:减少内存分配和回收的频率。
- 内核优化:生成更高效的 GPU/CPU 内核代码。
- PyTorch 使用后台优化工具(如 TorchDynamo 和 AOTAutograd)对计算图进行优化,包括:
- 执行编译后的计算图:
- 在模型训练或推理时,运行优化后的计算图,从而提升执行效率。
2.2.3.2 训练函数
在循环遍历 DataLoader 之前,需要将模型设置为训练模式(model.train),以确保模型参数可以被更新。为方便追踪训练进度,会记录训练的总损失和准确率。
def train():
loss = 0
accuracy = 0
model.train()
for x, y in train_loader:
output = model(x)
optimizer.zero_grad()
batch_loss = loss_function(output, y)
batch_loss.backward()
optimizer.step()
loss += batch_loss.item()
accuracy += get_batch_accuracy(output, y, train_N)
print('Train - Loss: {:.4f} Accuracy: {:.4f}'.format(loss, accuracy))
执行步骤如下:
- 将模型切换到训练模式(
model.train)。 - 对于每个批次数据(
train_loader):- 使用模型计算输出预测(
model(x))。 - 使用优化器清零梯度(
optimizer.zero_grad())。 - 根据损失函数计算当前批次的损失(
loss_function(output, y))。 - 通过
backward()计算损失的梯度。 - 通过
optimizer.step()更新模型的参数。 - 更新当前批次的损失和准确率。
- 使用模型计算输出预测(
- 输出整个训练阶段的损失和准确率。
2.2.3.3 验证函数
在验证过程中,模型不会进行学习,因此 validate 函数比前面的训练函数更简单。不一样的是,我们会通过 model.eval() 将模型设置为评估模式,这会阻止模型更新任何参数。
def validate():
loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for x, y in valid_loader:
output = model(x)
# 累加每个批次的 Loss 和 Accuracy
loss += loss_function(output, y).item()
accuracy += get_batch_accuracy(output, y, valid_N)
print('Valid - Loss: {:.4f} Accuracy: {:.4f}'.format(loss, accuracy))
-
model.eval():将模型切换到评估模式。-
禁用一些在训练时启用的功能,例如 Dropout 和 Batch Normalization 的动态行为。
-
确保模型在验证和推理时的行为是确定的,避免因随机性导致的不一致。
-
-
with torch.no_grad()::禁用梯度计算。- 在验证或推理阶段,不需要计算梯度,因此通过
torch.no_grad()禁用梯度,可以减少内存占用,加速计算。
- 在验证或推理阶段,不需要计算梯度,因此通过
2.2.3.4 主函数
epochs = 20
for epoch in range(epochs):
print('Epoch: {}'.format(epoch))
train()
validate()
输出如下:
Epoch: 0
No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
Train - Loss: 270.8916 Accuracy: 0.9052
Valid - Loss: 39.3250 Accuracy: 0.9483
Epoch: 1
Train - Loss: 12.8304 Accuracy: 0.9962
Valid - Loss: 39.4521 Accuracy: 0.9548
Epoch: 2
Train - Loss: 19.7593 Accuracy: 0.9930
Valid - Loss: 16.7592 Accuracy: 0.9752
Epoch: 3
Train - Loss: 5.6578 Accuracy: 0.9984
Valid - Loss: 28.4354 Accuracy: 0.9610
Epoch: 4
Train - Loss: 10.2799 Accuracy: 0.9964
Valid - Loss: 17.8178 Accuracy: 0.9718
Epoch: 5
Train - Loss: 1.5353 Accuracy: 0.9998
Valid - Loss: 9.9329 Accuracy: 0.9830
Epoch: 6
Train - Loss: 15.7924 Accuracy: 0.9950
Valid - Loss: 50.1468 Accuracy: 0.9290
Epoch: 7
Train - Loss: 4.9860 Accuracy: 0.9987
Valid - Loss: 83.7952 Accuracy: 0.9166
Epoch: 8
Train - Loss: 7.5209 Accuracy: 0.9972
Valid - Loss: 77.5145 Accuracy: 0.9002
Epoch: 9
Train - Loss: 2.1849 Accuracy: 0.9995
Valid - Loss: 11.9405 Accuracy: 0.9831
Epoch: 10
Train - Loss: 3.8308 Accuracy: 0.9990
Valid - Loss: 30.6041 Accuracy: 0.9750
Epoch: 11
Train - Loss: 7.9603 Accuracy: 0.9974
Valid - Loss: 14.1832 Accuracy: 0.9770
Epoch: 12
Train - Loss: 0.8395 Accuracy: 0.9996
Valid - Loss: 27.9665 Accuracy: 0.9721
Epoch: 13
Train - Loss: 7.6596 Accuracy: 0.9975
Valid - Loss: 18.1145 Accuracy: 0.9755
Epoch: 14
Train - Loss: 1.0418 Accuracy: 0.9996
Valid - Loss: 24.0420 Accuracy: 0.9730
Epoch: 15
Train - Loss: 5.1391 Accuracy: 0.9986
Valid - Loss: 35.1601 Accuracy: 0.9605
Epoch: 16
Train - Loss: 4.2844 Accuracy: 0.9985
Valid - Loss: 37.6194 Accuracy: 0.9506
Epoch: 17
Train - Loss: 0.8023 Accuracy: 0.9998
Valid - Loss: 7.7987 Accuracy: 0.9862
Epoch: 18
Train - Loss: 4.7752 Accuracy: 0.9987
Valid - Loss: 10.4014 Accuracy: 0.9827
Epoch: 19
Train - Loss: 0.2259 Accuracy: 0.9999
Valid - Loss: 19.4253 Accuracy: 0.9757
2.3 结果分析
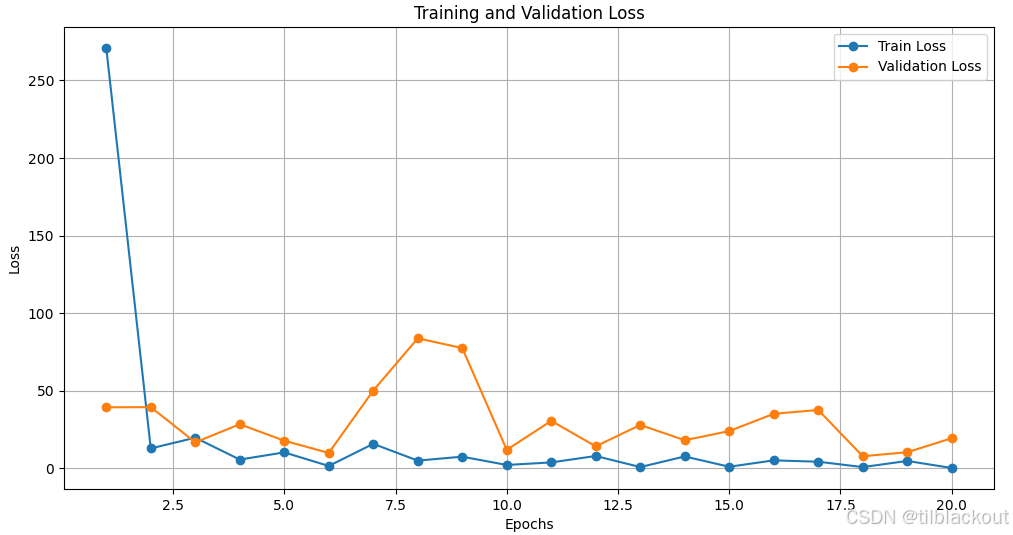
基于刚刚训练和验证的结果,我们可以得到训练和验证的损失图:
还有训练和验证的准确率图:
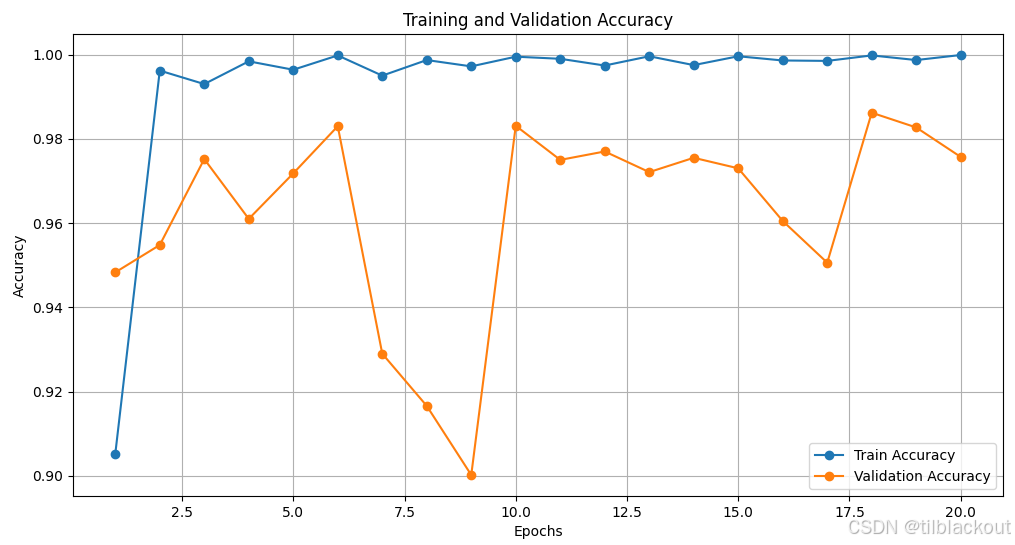
整体来看,模型在训练和验证阶段表现出较好的学习能力,尤其是在验证准确率上,多数 epoch 都达到了 90% 以上。然而,训练损失快速趋近于 0,准确率接近 100%,同时验证损失在第 7 和第 8 个 epoch 出现明显波动(例如第 7 个 epoch 验证损失高达 83.7952,准确率却只有 0.9166),这表明模型可能存在过拟合现象,对某些验证样本预测不够稳定。
可能的原因分析
- 学习率过高:
- 高学习率可能导致模型参数更新幅度过大,使得验证损失在部分 epoch 出现波动,甚至导致局部不稳定。
- 即使有 Batch Normalization,也无法完全抵消大幅度的参数更新对模型性能的负面影响。
- 数据分布差异:如果训练集和验证集的数据分布不一致(例如样本类别比例差异或样本特征存在偏差),模型在训练阶段可能拟合了特定的分布,导致验证阶段表现不稳定。
- 验证集的难度:验证集中可能包含一些复杂或边界样本(分类难度较高),导致模型在这些样本上的损失波动较大。
- 过拟合问题:尽管使用了 Dropout 和 Batch Normalization,但过拟合风险依然存在,尤其是当训练数据量相对较小时,模型可能过度拟合训练集的细节。
改进建议
- 调整学习率:采用学习率衰减策略(如 StepLR 或 Cosine Annealing),在训练后期逐步降低学习率,减少参数更新的幅度,改善验证损失波动问题。
- 增强数据预处理和扩增:
- 引入数据增强(如随机裁剪、旋转、翻转)以增加样本多样性,帮助模型学习更泛化的特征。
- 检查训练集和验证集的分布是否一致,确保验证集能代表训练数据的真实分布。
- 增加验证样本数量:如果验证集样本较少或样本分布不均,可以适当增加验证集的样本数量,以获得更稳定的验证损失和准确率。
- 使用 Early Stopping:通过验证损失监控训练过程,提早停止训练,避免模型在后期过拟合训练数据。
- 模型架构优化:检查模型是否过于复杂(例如参数过多),可以尝试简化网络架构,降低模型容量,以减少过拟合风险。
- 分析异常样本:对验证集中表现不佳的样本进行单独分析,观察模型错误分类的样本特性,判断是否需要进一步调整数据或模型。
3 总结
本文通过构建卷积神经网络(CNN)实现了对 ASL 手语字母的分类任务,从数据预处理到模型设计,再到训练和验证,完整地展示了深度学习在计算机视觉领域的强大能力。通过使用 Batch Normalization 和 Dropout 等技术,我们在一定程度上缓解了过拟合问题,同时采用了优化器和损失函数的合理搭配来提升模型性能。
然而,训练出一个完美的模型需要不断的调参、对数据和结果的深入分析,以及丰富的实践经验。正如在最后的结果分析中,我们发现验证损失的波动需要进一步优化。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











