







随机森林是一种常用的监督学习算法,适用于回归和分类任务。它通过集成多个决策树模型,提高预测的准确性和稳定性,是应对单棵决策树易过拟合、对数据敏感等缺点的有效改进方式。作为一种集成方法,随机森林利用有标签的数据进行训练,并结合多个树的预测结果做出最终判断。
1 介绍
1.1 原理
随机森林通过组合多棵决策树来进行预测。森林中的每棵树都在数据的一个随机子样本上进行训练,并在每次划分节点时只考虑部分随机选取的特征。每棵树就像一个“专家”,独立做出分类判断。最终结果通过多数投票决定哪一类为最终预测(如果是回归任务,则取所有树预测值的平均)。
如下图所示,有一组由n棵树组成的森林,我们看前5棵,其中4棵判断为“猫”,1棵判断为“狗”,那最终结果就是“猫”。每棵树走的判断路径可能不同,因此预测也各有差异。
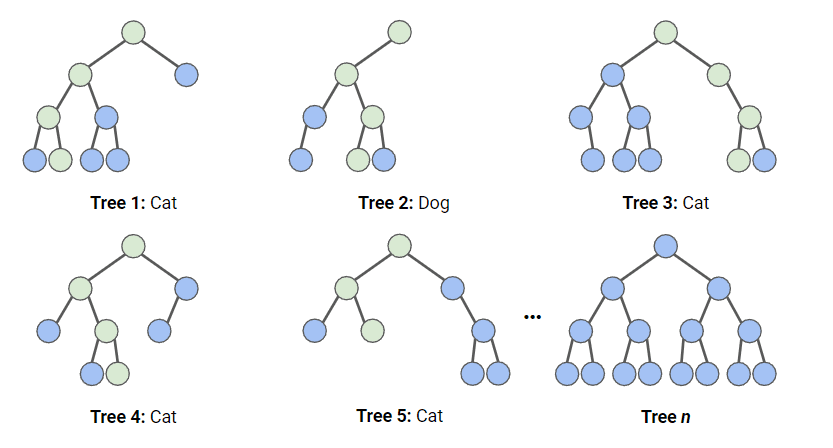
随机森林的工作流程如下:
- Bootstrap抽样:每棵树都会获得一个独立的训练子集,该子集是通过对原始数据进行有放回的随机抽样生成的。这意味着某些数据点可能重复出现,而另一些则未被使用。
- 目的是让每棵树看到的数据不同,模型更有多样性,防止所有树都长得一样
- 随机特征选择:在进行节点划分时,每棵树只考虑所有特征中的一个随机子集(通常是总特征数的平方根)。
- 构建树模型:每棵树仅基于自己的Bootstrap样本和随机选择的特征集不断分裂节点,直到满足停止条件(如节点纯度或最小样本数)。
- 最终预测:所有决策树共同参与最终预测。对于分类任务,采用多数投票结果作为输出;对于回归任务,计算所有树预测值的平均作为最终结果。
1.2 例子
这里用一个实例解释一下Bootstrap抽样和随机特征选择:
假设你有一个小型的图像分类数据集,总共有 10张图片,每张图像已经贴好标签(猫或狗):
| 图片编号 | 标签 |
|---|---|
| 1 | 猫 |
| 2 | 狗 |
| 3 | 猫 |
| 4 | 狗 |
| 5 | 猫 |
| 6 | 狗 |
| 7 | 猫 |
| 8 | 狗 |
| 9 | 猫 |
| 10 | 狗 |
我们从这10张图中,随机地、有放回地抽取10张样本,可能得到如下这个“子训练集”:
| 抽样顺序 | 选中的图片编号 | 标签 |
|---|---|---|
| 1 | 2 | 狗 |
| 2 | 5 | 猫 |
| 3 | 2 | 狗 |
| 4 | 7 | 猫 |
| 5 | 9 | 猫 |
| 6 | 1 | 猫 |
| 7 | 4 | 狗 |
| 8 | 2 | 狗 |
| 9 | 10 | 狗 |
| 10 | 3 | 猫 |
你会发现:
- 图片2出现了 3次
- 图片6、8 没有出现
- 这就是这棵树的训练集,具有随机性和重复性
除了样本不同,每棵树在分裂每个节点时,还只考虑部分特征,这就是“随机特征选择”。假设我们对每张图像提取了如下特征:
| 特征编号 | 特征名 | 含义说明 |
|---|---|---|
| F1 | 耳朵高度 | 猫高、狗低 |
| F2 | 毛发密度 | 猫密、狗疏 |
| F3 | 眼睛间距 | 猫眼近、狗眼远 |
| F4 | 嘴巴宽度 | 狗嘴宽、猫嘴窄 |
| F5 | 尾巴弯曲度 | 猫尾巴更弯 |
| F6 | 身体长度 | 狗身体更长 |
在每次节点分裂时,并不会考虑全部6个特征,而是随机选取其中一部分(比如2个)。
例如某次分裂只选中了 [F2, F4],那本节点只能在这两个中选择“最佳分裂特征”。这会导致每棵树的结构更加不一样,进一步增强多样性。
1.3. OOB(Out-of-Bag)
由于 Bootstrap 是有放回抽样,大约有36.8%的样本不会被采样到某棵树中,这些样本就叫作袋外样本(Out-of-Bag)。这些袋外样本可以被用来评估该棵树的性能,相当于内置了“交叉验证”的效果。
在随机森林中,每个样本通常不会出现在所有树的训练集中。由于采用了 Bootstrap 抽样,有些样本在某棵树中被选中用于训练,而在其他树中则未被使用。对于这些“未见过该样本”的树,我们可以利用它们对该样本进行预测,并将预测结果与真实标签进行对比,计算预测的准确率或误差。最后,对所有样本在其对应“未见过的树”上的预测误差取平均,就得到了随机森林的OOB(Out-of-Bag)估计误差。
这种方法的最大优势在于,它不需要额外划分验证集,就可以获得模型在未见数据上的泛化能力评估。在数据集较小的场景中尤其有用,不会浪费宝贵的训练数据,同时还能提供稳定、有效的模型性能参考。
2 代码实例
现在我们通过使用 sklearn 中的 RandomForestClassifier,对 possum.csv 数据集进行性别分类预测。
possum.csv 是一个关于袋貂(possum)的生物测量数据集,包含多个物理特征(如体长、尾长、耳长等),目标是预测袋貂的性别(male / female)。
数据准备
import pandas as pd
df = pd.read_csv("possum.csv")
df.sample(5, random_state=44)
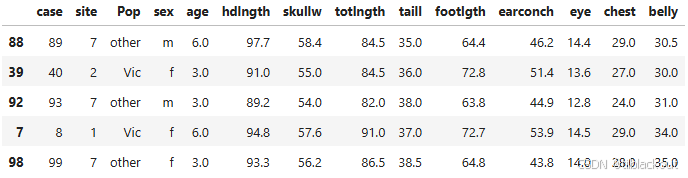
为了避免训练时出错,我们先去除包含缺失值的样本行。
df = df.dropna()
删除那些不必要的列,然后将特征数据和标签数据分别存储在不同的变量中:
X = df.drop(["case", "site", "Pop", "sex"], axis=1)
y = df["sex"]
case:这是每只袋貂的编号,相当于一个唯一标识符。它对分类任务没有实际意义,反而可能引入噪声。site:表示采样地点编号,是一个离散数字(如 1、2、3),它本质上是一个“类别”变量,而不是袋貂本身的生理特征。Pop:代表袋貂所属的族群(例如“Vic”或“other”),它可能与性别有一定相关性,但本身是类别型变量,我们当前主要关注数值型特征作为输入。
训练模型
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=44)
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(n_estimators=50, random_state=44)
rf_model.fit(X_train, y_train)
首先划分数据集,将 70% 的数据用于训练,30% 用于测试。接着使用 50 棵树构建森林;设置随机种子保证实验可重复,最后使用 .fit() 方法训练模型。
预测测试集结果
predictions = rf_model.predict(X_test)
predictions
输出:
预测概率输出
返回的是每个样本属于每个类别(例如 male/female)的概率值,适用于需要概率输出的场景(比如做阈值判断)。
rf_model.predict_proba(X_test)
输出:
特征重要性分析
我们来查看一下每个特征在决策过程中起到的重要程度,返回一个与特征顺序对应的数组。
importances = rf_model.feature_importances_
columns = X.columns
i = 0
while i < len(columns):
print(f"The importance of feature '{columns[i]}' is {round(importances[i] * 100, 2)}%.")
i += 1
输出:

模型表现
from sklearn.metrics import accuracy_score, classification_report
predictions = rf_model.predict(X_test)
print("accuracy:", accuracy_score(y_test, predictions))
print(classification_report(y_test, predictions))
输出:
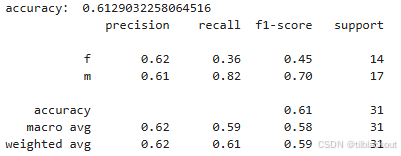
可以看出模型的表现并不理想:
- 模型倾向预测为男性:召回率高达 0.82,说明模型更擅长找出男性;
- 对于女性识别能力差:召回率仅 0.36,表示很多实际是女性的样本被错分成了男性;
- 不平衡预测倾向:虽然样本数还算均衡(f:14, m:17),但模型判断偏向一方,说明可能受到某些特征主导影响。
改进
由于这里只是简单介绍一下随机森林的例子,就不进一步优化模型了,以下是一些可能得改进模型的方法:
- 增加树数量:试试
n_estimators=100或更多,让模型更稳定。 - 特征工程:检查是否某些特征对性别没有帮助,或可以做归一化、组合、去除异常值等操作。
- 样本增强:如果数据量较小,可以考虑扩充样本,或使用 SMOTE 等方法增强少数类。
- 调参优化:尝试调整 max_depth、min_samples_leaf、class_weight 等参数。
- 尝试其他模型:对比逻辑回归、SVM 等看看是否能更好捕捉模式。
3 总结
随机森林是一种基于决策树的集成学习算法,通过引入样本和特征的双重随机性,构建多棵彼此独立的树模型,并以投票或平均的方式输出最终结果。这种方法不仅提升了模型的泛化能力,还有效减少了过拟合风险。它在处理高维数据、评估特征重要性以及应对复杂非线性关系方面具有明显优势。尽管在小数据集上可能表现受限,但通过合理调参与特征工程,随机森林依然是一种强大且易用的机器学习工具。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











