






引言
笔者在另一篇文章(从一个简单的计算问题,看国内几个大语言模型推理逻辑能力)中比较了百度文心一言、月之暗面、深度求索、通义千问、讯飞星火、chatgpt对同一个简单的计算问题的回答结果,比较了他们的现有逻辑推理能力。国内还有的两个大公司的大模型还没有测试,说实话,笔者也是第一次用这两模型,就补了这篇文章。
同样的问题
123456*987654等于多少,给出你计算的过程。
看结果
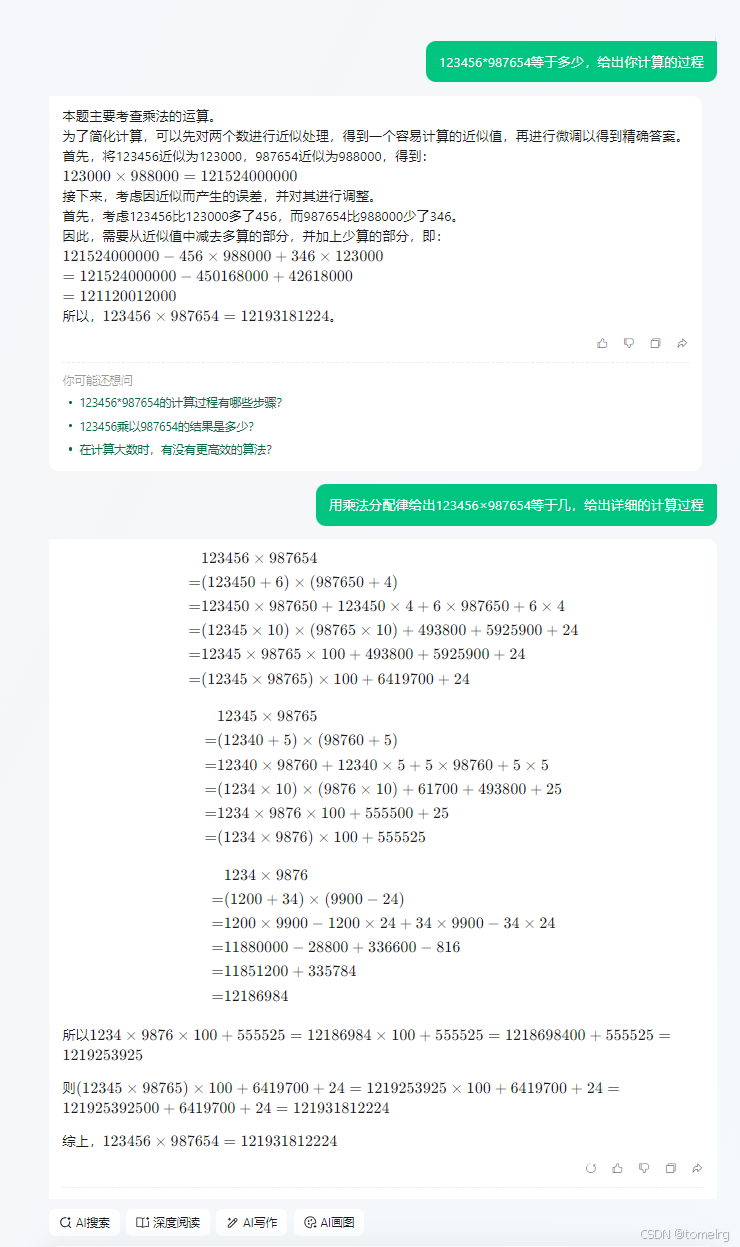
抖音豆包
好家伙,上去就来乘法分配律,奈何结果错误,这基本的计算看来模型都不理解。这个模型与百度文心一言4.0一样,上来就是乘法分配律。

腾讯元宝
说实话,有惊到我,这解答果然不走寻常路,但逻辑思想也基本上是基于乘法分配律,逻辑推理还是欠缺些,中间的计算过程不正确,结果也不正确。第二次的回答,结果正确,中间过程诸君自行分析吧。

















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









