







main_vo_sf_imageseq.cpp文件中
这个就是读取文件的路径
图片路径需要修改
std::string dir = ".../data/sequence people moving/";
这个函数用来读取图片的。
cf.loadImageFromSequence(dir, im_count, res_factor);
在solver.cpp中有loadImageFromSequence函数的定义。
传入进来的index=1;构建图片名aux
sprintf(aux, "i%d.png", index);//构建aux="i1.png"
构建图片路径
string name = files_dir + aux;
读取RGB彩色图片
cv::Mat color = cv::imread(name.c_str(), CV_LOAD_IMAGE_COLOR);
同样的构建图片读取路径
sprintf(aux, "d%d.png", index);
name = files_dir + aux;
读取深度图。
cv::Mat depth = cv::imread(name, -1);
ok!读取图片任务完成。
因为数据集需要有以下改动,
1.图片路径需要修改
2.图片路径下存放的图片命名应该为,ixx(rgb图片),dxx(深度图)。
3.运行方式:./VO-SF-ImageSeq,因为我没有编译过,所以不知道生成的具体的可执行文件是什么样的。
4.运行了之后可能还有输入提示,
n:加载图片并运行
s:继续or停止
e:关闭程序
readme中也有关于数据集的介绍。
kmeans.cpp
void VO_SF::kMeans3DCoord()函数中
const float distance_to_last_label = (centers_a.col(last_label) - p).squaredNorm();
MatrixXf centers_a(3,NUM_LABELS)
const Vector3f p(depth_ref(v,u), xx_ref(v,u), yy_ref(v,u));
//Refs
const MatrixXf &depth_ref = depth_old[lower_level];
const MatrixXf &xx_ref = xx_old[lower_level];
const MatrixXf &yy_ref = yy_old[lower_level];
在void VO_SF::createImagePyramid()函数中,
//Push the frames back
intensity_old.swap(intensity);
depth_old.swap(depth);
xx_old.swap(xx);
yy_old.swap(yy);
0.intensity_wf,depth_wf初始化了。
1.intensity,depth没有初始化。。。。
2.xx,yy就是等比例变换的坐标,
3.实际上是在createImagePyramid()函数里进行初始化的。。。。
4.本质上聚类还是使用的深度信息和图像坐标进行聚类的。。。。,没有使用到灰度信息聚类。
5.使用了图像金字塔,因此聚类是在图像金字塔的图像中聚类的。
=》6.先实现图像金字塔聚类结果显示。。。。。
loadImagePairFromFiles函数中初始化了这些变量
main_vo_sf_imagepair.cpp中调用了该函数
3) VO SF ImagePair:**这是一个简单的应用程序,用于测试单个RGB-D图像对的算法(主要用于查看估计场景流的准确性)。设置主文件中包含图像的文件夹。图像文件应具有以下名称:“depth0.png”、“color0.png“、“depth1.png”和“color1.png“。
场景流以米为单位存储(坐标:x-左/右,y-上/下,z-深度)。
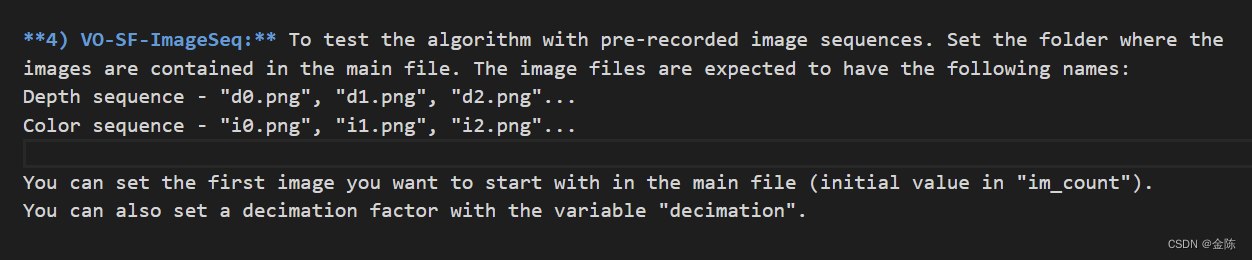
**4) VO SF ImageSeq:**使用预先记录的图像序列测试算法。设置主文件中包含图像的文件夹。图像文件应具有以下名称:
深度序列-“d0.png”、“d1.png”、“d2.png”。。。
颜色序列-“i0.png”、“i1.png”和“i2.png”。。。
您可以在主文件中设置要开始的第一个图像(“im_count”中的初始值)。
您还可以使用变量“抽取”设置抽取因子。
聚类函数测试
实际上是判断单张图片能否聚类成功,以及耗时方面的计算。
1.图像尺寸需要更改,图片名称,导入深度图和rgb图片进行测试
代码完成之后进行调试
kmeans-11-27带有金字塔的图像聚类,运行成功。。。。
kmeans-11-28
Q1.去除图像金字塔,直接按原图像比例进行聚类。
2.图像金字塔是需要的,因为需要使用最小分辨率的图像金字塔来实现聚类中心的初始化,同时节省时间。
3.最后也只在320×240的最大分辨率的图像上进行聚类的。
4.聚类完成后需要完成可视化相关程序。
程序完成。但是实验效果并不好,还有,如何使用???最后的图像为缩小后的图像。。。个人觉得不好。
使用深度图进行聚类不如直接使用rgb图像进行聚类。理论部分需要更改。
扭曲图像计算残差
orbslam里面用于剔除异常点的方法就是计算的重投影误差。。。。。
先试试orbslam运行tum rgbd数据集看看结果。
















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









