







U-Net是医疗领域进行语义分割的利器,随着AIGC的爆火,U-Net已成为Diffusion Model的backbone,有必要详细记录下。
原理

U-Net包含了编码器和解码器部分:
- 编码器:通过下采样,实现了特征的层次提取。该过程类似于人类视觉系统,先关注局部细节,然后逐步构建出整体的语义信息
- 解码器:通过反卷积和跳跃连接,将编码器中相应尺寸的特征图与解码器中的特征图拼接,从而实现特征的层次恢复。该过程有助于网络在解码过程中更好地利用上下文信息,提高分割的准确性
实践
原论文的输入维度对于上下采样时的大小变换不友好,因此出现了维度裁剪的情况。这里以实现下述结构的U-Net为例:
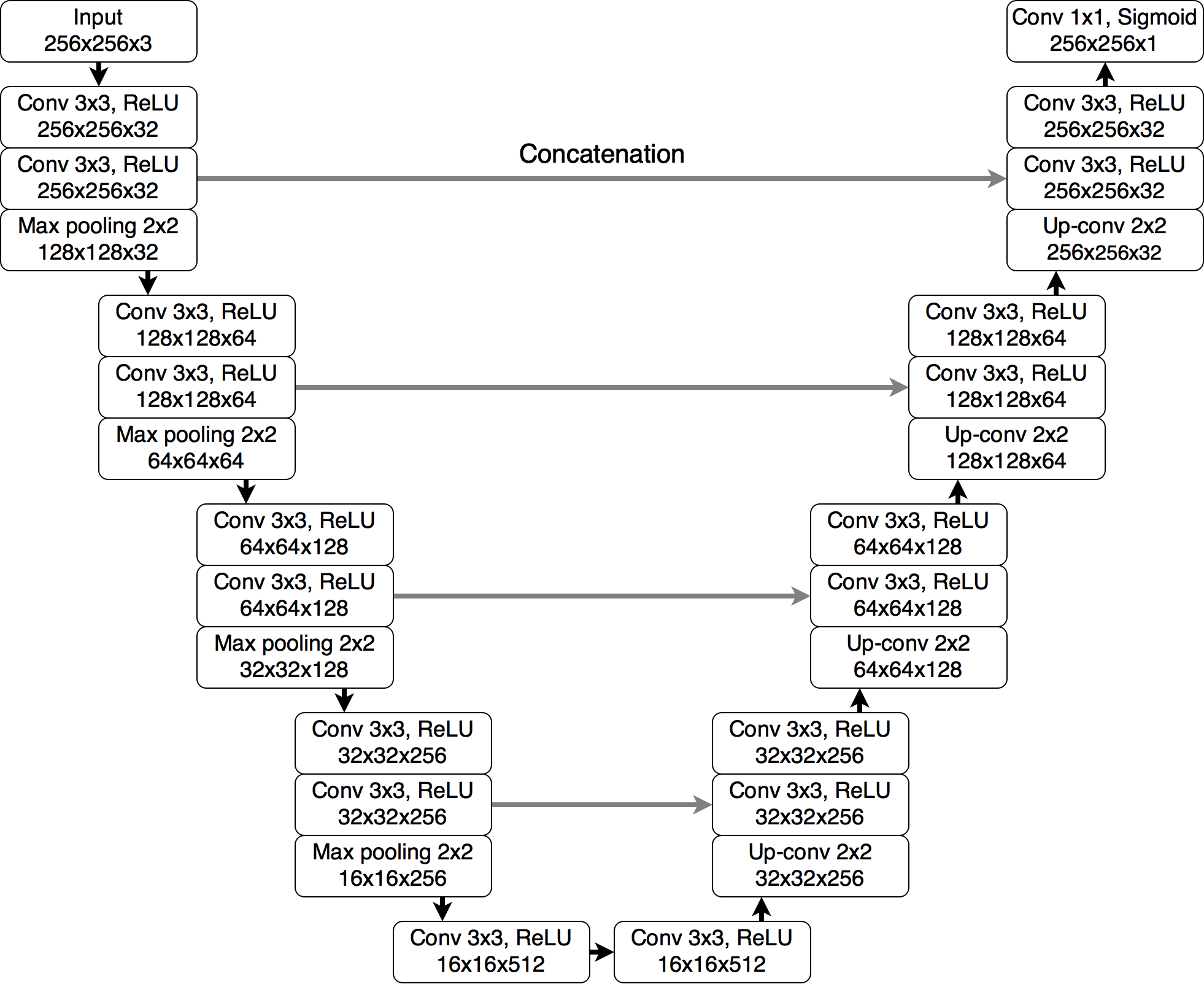
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(UNet, self).__init__()
# 下采样
def down_conv_block(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
# 上采样
def up_conv_block(in_channels, out_channels):
return nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)
self.pool = nn.MaxPool2d(kernel_size=2)
self.encoder1 = down_conv_block(in_channels, 32)
self.encoder2 = down_conv_block(32, 64)
self.encoder3 = down_conv_block(64, 128)
self.encoder4 = down_conv_block(128, 256)
self.bottleneck = down_conv_block(256, 512)
self.upconv4 = up_conv_block(512, 256)
self.decoder4 = down_conv_block(512, 256)
self.upconv3 = up_conv_block(256, 128)
self.decoder3 = down_conv_block(256, 128)
self.upconv2 = up_conv_block(128, 64)
self.decoder2 = down_conv_block(128, 64)
self.upconv1 = up_conv_block(64, 32)
self.decoder1 = down_conv_block(64, 32)
self.output = nn.Conv2d(32, out_channels, kernel_size=1)
def forward(self, x):
# Encoding path
# 1, 32, 256, 256
enc1 = self.encoder1(x)
# 1, 64, 128, 128
enc2 = self.encoder2(self.pool(enc1))
# 1, 128, 64, 64
enc3 = self.encoder3(self.pool(enc2))
# 1, 256, 32, 32
enc4 = self.encoder4(self.pool(enc3))
# Bottleneck
# 1, 512, 16, 16
bottleneck = self.bottleneck(self.pool(enc4))
# Decoding path
# 1, 256, 32, 32
dec4 = self.upconv4(bottleneck)
# 1, 512, 32, 32
dec4 = torch.cat((dec4, enc4), dim=1)
# 1, 256, 32, 32
dec4 = self.decoder4(dec4)
# 1, 128, 64, 64
dec3 = self.upconv3(dec4)
# 1, 256, 64, 64
dec3 = torch.cat((dec3, enc3), dim=1)
# 1, 128, 64, 64
dec3 = self.decoder3(dec3)
# 1, 64, 128, 128
dec2 = self.upconv2(dec3)
# 1, 128, 128, 128
dec2 = torch.cat((dec2, enc2), dim=1)
# 1, 64, 128, 128
dec2 = self.decoder2(dec2)
# 1, 32, 256, 256
dec1 = self.upconv1(dec2)
# 1, 64, 256, 256
dec1 = torch.cat((dec1, enc1), dim=1)
# 1, 32, 256, 256
dec1 = self.decoder1(dec1)
return self.output(dec1)
model = UNet(in_channels=3, out_channels=1)
input_tensor = torch.randn(1, 3, 256, 256) # Batch size 1, 1 channel, 572x572 image size
output_tensor = model(input_tensor)
print(output_tensor.shape)














 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









