







6.4 Nanite
本章将阐述UE5的Nanite虚拟微多边形的预处理、渲染、优化技术。
在UE5 EA源码工程搜索“Nanite”字眼,发现了195个文件供3026处匹配:

由于涉及面太广,当然不可能每个细节都阐述,笔者经过筛查,将集中精力剖析以下模块的Nanite源码:
- Editor的Nanite Mesh构建过程。
- Engine模块关于Nanite资源的管理、加载、组装等。
- Renderer模块关于Nanite的渲染过程、优化技术。
- Shader中Nanite的渲染步骤、算法。
6.4.1 Nanite基础
本节主要阐述Nanite相关的基本概念、类型和基础知识。
6.4.1.1 FMeshNaniteSettings
// Engine\Source\Runtime\Engine\Classes\Engine\EngineTypes.h
// 阴影图方法.
namespace EShadowMapMethod
{
enum Type
{
// 传统的阴影图. 逐组件裁剪, 在高多边形场景造成较差的性能.
ShadowMaps UMETA(DisplayName = "Shadow Maps"),
// 为阴影渲染几何体到虚拟深度图, 用简单设置便可提供高质量的次世代投影. 与Nanite配合使用时,可实现高效裁剪.
VirtualShadowMaps UMETA(DisplayName = "Virtual Shadow Maps (Beta)")
};
}
// 应用于Nanite数据构建时的配置.
struct FMeshNaniteSettings
{
// 是否启用Nanite网格.
uint8 bEnabled : 1;
// 位置精度. 步长为2^(-PositionPrecision) cm. MIN_int32表示自动设置.
int32 PositionPrecision;
// 从LOD0的三角形百分比. 1.0表示没有任何减面, 0.0表示没有三角形.
float PercentTriangles;
FMeshNaniteSettings(): bEnabled(false), PositionPrecision(MIN_int32), PercentTriangles(0.0f){}
FMeshNaniteSettings(const FMeshNaniteSettings& Other);
bool operator==(const FMeshNaniteSettings& Other) const;
bool operator!=(const FMeshNaniteSettings& Other) const;
};
6.4.1.2 StaticMesh
// Engine\Source\Runtime\Engine\Classes\Engine\StaticMesh.h
class UStaticMesh : public UStreamableRenderAsset, (......)
{
(......)
public:
// 静态网格的Nanite配置数据.
FMeshNaniteSettings NaniteSettings;
// 如果网格存在有效的Nanite渲染数据则返回true.
bool HasValidNaniteData() const
{
if (const FStaticMeshRenderData* SMRenderData = GetRenderData())
{
return SMRenderData->NaniteResources.PageStreamingStates.Num() > 0;
}
return false;
}
(......)
// 超高分辨率的源模型相关的接口.
FStaticMeshSourceModel& GetHiResSourceModel();
const FStaticMeshSourceModel& GetHiResSourceModel() const;
FStaticMeshSourceModel&& MoveHiResSourceModel();
void SetHiResSourceModel(FStaticMeshSourceModel&& SourceModel);
bool LoadHiResMeshDescription(FMeshDescription& OutMeshDescription) const;
bool CloneHiResMeshDescription(FMeshDescription& OutMeshDescription) const;
FMeshDescription* CreateHiResMeshDescription();
FMeshDescription* CreateHiResMeshDescription(FMeshDescription MeshDescription);
FMeshDescription* GetHiResMeshDescription() const;
bool IsHiResMeshDescriptionValid() const;
void CommitHiResMeshDescription(const FCommitMeshDescriptionParams& Params);
void ClearHiResMeshDescription();
(......)
private:
// 超高分辨率的源模型.
FStaticMeshSourceModel HiResSourceModel;
(......)
};
// Engine\Source\Runtime\Engine\Public\StaticMeshResources.h
// 静态网格所需的渲染数据.
class FStaticMeshRenderData
{
public:
(......)
// Nanite渲染资源.
Nanite::FResources NaniteResources;
(......)
};
6.4.1.3 NaniteResource
// Engine\Source\Runtime\Engine\Public\Rendering\NaniteResources.h
// 最大数量的常量.
#define MAX_STREAMING_REQUESTS ( 128u * 1024u )
#define MAX_CLUSTER_TRIANGLES 128
#define MAX_CLUSTER_VERTICES 256
#define MAX_CLUSTER_INDICES ( MAX_CLUSTER_TRIANGLES * 3 )
#define MAX_NANITE_UVS 4
#define NUM_ROOT_PAGES 1u
// 是否使用三角形带索引.
#define USE_STRIP_INDICES 1
// CLUSTER常量.
#define CLUSTER_PAGE_GPU_SIZE_BITS 17
#define CLUSTER_PAGE_GPU_SIZE ( 1 << CLUSTER_PAGE_GPU_SIZE_BITS )
#define CLUSTER_PAGE_DISK_SIZE ( CLUSTER_PAGE_GPU_SIZE * 2 )
#define MAX_CLUSTERS_PER_PAGE_BITS 10
#define MAX_CLUSTERS_PER_PAGE_MASK ( ( 1 << MAX_CLUSTERS_PER_PAGE_BITS ) - 1 )
#define MAX_CLUSTERS_PER_PAGE ( 1 << MAX_CLUSTERS_PER_PAGE_BITS )
#define MAX_CLUSTERS_PER_GROUP_BITS 9
#define MAX_CLUSTERS_PER_GROUP_MASK ( ( 1 << MAX_CLUSTERS_PER_GROUP_BITS ) - 1 )
#define MAX_CLUSTERS_PER_GROUP ( ( 1 << MAX_CLUSTERS_PER_GROUP_BITS ) - 1 )
#define MAX_CLUSTERS_PER_GROUP_TARGET 128
// 层级, GPU页, 实例化, 组等的常量.
#define MAX_HIERACHY_CHILDREN_BITS 6
#define MAX_HIERACHY_CHILDREN ( 1 << MAX_HIERACHY_CHILDREN_BITS )
#define MAX_GPU_PAGES_BITS 14
#define MAX_GPU_PAGES ( 1 << MAX_GPU_PAGES_BITS )
#define MAX_INSTANCES_BITS 24
#define MAX_INSTANCES ( 1 << MAX_INSTANCES_BITS )
#define MAX_NODES_PER_PRIMITIVE_BITS 16
#define MAX_RESOURCE_PAGES_BITS 20
#define MAX_RESOURCE_PAGES (1 << MAX_RESOURCE_PAGES_BITS)
#define MAX_GROUP_PARTS_BITS 3
#define MAX_GROUP_PARTS_MASK ((1 << MAX_GROUP_PARTS_BITS) - 1)
#define MAX_GROUP_PARTS (1 << MAX_GROUP_PARTS_BITS)
#define PERSISTENT_CLUSTER_CULLING_GROUP_SIZE 64
// BVH
#define MAX_BVH_NODE_FANOUT_BITS 3
#define MAX_BVH_NODE_FANOUT (1 << MAX_BVH_NODE_FANOUT_BITS)
#define MAX_BVH_NODES_PER_GROUP (PERSISTENT_CLUSTER_CULLING_GROUP_SIZE / MAX_BVH_NODE_FANOUT)
#define NUM_CULLING_FLAG_BITS 3
#define NUM_PACKED_CLUSTER_FLOAT4S 8
#define MAX_POSITION_QUANTIZATION_BITS 21 // (21*3 = 63) < 64
#define NORMAL_QUANTIZATION_BITS 9
#define MAX_TEXCOORD_QUANTIZATION_BITS 15
#define MAX_COLOR_QUANTIZATION_BITS 8
#define NUM_STREAMING_PRIORITY_CATEGORY_BITS 2
#define STREAMING_PRIORITY_CATEGORY_MASK ((1u << NUM_STREAMING_PRIORITY_CATEGORY_BITS) - 1u)
#define VIEW_FLAG_HZBTEST 0x1
#define MAX_TRANSCODE_GROUPS_PER_PAGE 128
#define VERTEX_COLOR_MODE_WHITE 0
#define VERTEX_COLOR_MODE_CONSTANT 1
#define VERTEX_COLOR_MODE_VARIABLE 2
#define NANITE_USE_SCRATCH_BUFFERS 1
#define NANITE_CLUSTER_FLAG_LEAF 0x1
namespace Nanite
{
// 整形向量.
struct FUIntVector
{
uint32 X, Y, Z;
bool operator==(const FUIntVector& V) const;
FORCEINLINE friend FArchive& operator<<(FArchive& Ar, FUIntVector& V);
};
// 打包的层级节点.
struct FPackedHierarchyNode
{
FSphere LODBounds[MAX_BVH_NODE_FANOUT]; // 用球体做LOD包围盒.
struct
{
FVector BoxBoundsCenter;
uint32 MinLODError_MaxParentLODError;
} Misc0[MAX_BVH_NODE_FANOUT];
struct
{
FVector BoxBoundsExtent;
uint32 ChildStartReference;
} Misc1[MAX_BVH_NODE_FANOUT];
struct
{
uint32 ResourcePageIndex_NumPages_GroupPartSize;
} Misc2[MAX_BVH_NODE_FANOUT];
};
// 材质三角形.
struct FMaterialTriangle
{
uint32 Index0;
uint32 Index1;
uint32 Index2;
uint32 MaterialIndex;
uint32 RangeCount;
};
// 从Value中获取指定位数和偏移的值.
uint32 GetBits(uint32 Value, uint32 NumBits, uint32 Offset)
{
uint32 Mask = (1u << NumBits) - 1u;
return (Value >> Offset) & Mask;
}
// 将指定位数和偏移的值合并到Value中.
void SetBits(uint32& Value, uint32 Bits, uint32 NumBits, uint32 Offset)
{
uint32 Mask = (1u << NumBits) - 1u;
Mask <<= Offset;
Value = (Value & ~Mask) | (Bits << Offset);
}
// 被GPU使用的打包的Cluster.
struct FPackedCluster
{
// 光栅化所需的数据成员.
FIntVector QuantizedPosStart;
uint32 NumVerts_PositionOffset; // NumVerts:9, PositionOffset:23
FVector MeshBoundsMin;
uint32 NumTris_IndexOffset; // NumTris:8, IndexOffset: 24
FVector MeshBoundsDelta;
uint32 BitsPerIndex_QuantizedPosShift_PosBits; // BitsPerIndex:4, QuantizedPosShift:6, QuantizedPosBits:5.5.5
// 裁剪所需的数据成员.
FSphere LODBounds;
FVector BoxBoundsCenter;
uint32 LODErrorAndEdgeLength;
FVector BoxBoundsExtent;
uint32 Flags;
// 材质所需的数据成员.
uint32 AttributeOffset_BitsPerAttribute; // AttributeOffset: 22, BitsPerAttribute: 10
uint32 DecodeInfoOffset_NumUVs_ColorMode; // DecodeInfoOffset: 22, NumUVs: 3, ColorMode: 2
uint32 UV_Prec; // U0:4, V0:4, U1:4, V1:4, U2:4, V2:4, U3:4, V3:4
uint32 PackedMaterialInfo;
uint32 ColorMin;
uint32 ColorBits; // R:4, G:4, B:4, A:4
uint32 GroupIndex; // Debug only
uint32 Pad0;
uint32 GetNumVerts() const { return GetBits(NumVerts_PositionOffset, 9, 0); }
uint32 GetPositionOffset() const { return GetBits(NumVerts_PositionOffset, 23, 9); }
uint32 GetNumTris() const { return GetBits(NumTris_IndexOffset, 8, 0); }
uint32 GetIndexOffset() const { return GetBits(NumTris_IndexOffset, 24, 8); }
uint32 GetBitsPerIndex() const { return GetBits(BitsPerIndex_QuantizedPosShift_PosBits, 4, 0); }
uint32 GetQuantizedPosShift() const { return GetBits(BitsPerIndex_QuantizedPosShift_PosBits, 6, 4); }
uint32 GetPosBitsX() const { return GetBits(BitsPerIndex_QuantizedPosShift_PosBits, 5, 10); }
uint32 GetPosBitsY() const { return GetBits(BitsPerIndex_QuantizedPosShift_PosBits, 5, 15); }
uint32 GetPosBitsZ() const { return GetBits(BitsPerIndex_QuantizedPosShift_PosBits, 5, 20); }
uint32 GetAttributeOffset() const { return GetBits(AttributeOffset_BitsPerAttribute, 22, 0); }
uint32 GetBitsPerAttribute() const { return GetBits(AttributeOffset_BitsPerAttribute, 10, 22); }
void SetNumVerts(uint32 NumVerts) { SetBits(NumVerts_PositionOffset, NumVerts, 9, 0); }
void SetPositionOffset(uint32 Offset) { SetBits(NumVerts_PositionOffset, Offset, 23, 9); }
void SetNumTris(uint32 NumTris) { SetBits(NumTris_IndexOffset, NumTris, 8, 0); }
void SetIndexOffset(uint32 Offset) { SetBits(NumTris_IndexOffset, Offset, 24, 8); }
void SetBitsPerIndex(uint32 BitsPerIndex) { SetBits(BitsPerIndex_QuantizedPosShift_PosBits, BitsPerIndex, 4, 0); }
void SetQuantizedPosShift(uint32 PosShift) { SetBits(BitsPerIndex_QuantizedPosShift_PosBits, PosShift, 6, 4); }
void SetPosBitsX(uint32 NumBits) { SetBits(BitsPerIndex_QuantizedPosShift_PosBits, NumBits, 5, 10); }
void SetPosBitsY(uint32 NumBits) { SetBits(BitsPerIndex_QuantizedPosShift_PosBits, NumBits, 5, 15); }
void SetPosBitsZ(uint32 NumBits) { SetBits(BitsPerIndex_QuantizedPosShift_PosBits, NumBits, 5, 20); }
void SetAttributeOffset(uint32 Offset) { SetBits(AttributeOffset_BitsPerAttribute, Offset, 22, 0); }
void SetBitsPerAttribute(uint32 Bits) { SetBits(AttributeOffset_BitsPerAttribute, Bits, 10, 22); }
void SetDecodeInfoOffset(uint32 Offset) { SetBits(DecodeInfoOffset_NumUVs_ColorMode, Offset, 22, 0); }
void SetNumUVs(uint32 Num) { SetBits(DecodeInfoOffset_NumUVs_ColorMode, Num, 3, 22); }
void SetColorMode(uint32 Mode) { SetBits(DecodeInfoOffset_NumUVs_ColorMode, Mode, 2, 22+3); }
};
// 页面流状态.
struct FPageStreamingState
{
uint32 BulkOffset;
uint32 BulkSize;
uint32 PageUncompressedSize;
uint32 DependenciesStart;
uint32 DependenciesNum;
};
// 层级修正.
class FHierarchyFixup
{
public:
FHierarchyFixup() {}
FHierarchyFixup( uint32 InPageIndex, uint32 NodeIndex, uint32 ChildIndex, uint32 InClusterGroupPartStartIndex, uint32 PageDependencyStart, uint32 PageDependencyNum )
{
PageIndex = InPageIndex;
HierarchyNodeAndChildIndex = ( NodeIndex << MAX_HIERACHY_CHILDREN_BITS ) | ChildIndex;
ClusterGroupPartStartIndex = InClusterGroupPartStartIndex;
PageDependencyStartAndNum = (PageDependencyStart << MAX_GROUP_PARTS_BITS) | PageDependencyNum;
}
uint32 GetPageIndex() const { return PageIndex; }
uint32 GetNodeIndex() const { return HierarchyNodeAndChildIndex >> MAX_HIERACHY_CHILDREN_BITS; }
uint32 GetChildIndex() const { return HierarchyNodeAndChildIndex & ( MAX_HIERACHY_CHILDREN - 1 ); }
uint32 GetClusterGroupPartStartIndex() const { return ClusterGroupPartStartIndex; }
uint32 GetPageDependencyStart() const { return PageDependencyStartAndNum >> MAX_GROUP_PARTS_BITS; }
uint32 GetPageDependencyNum() const { return PageDependencyStartAndNum & MAX_GROUP_PARTS_MASK; }
uint32 PageIndex;
uint32 HierarchyNodeAndChildIndex;
uint32 ClusterGroupPartStartIndex;
uint32 PageDependencyStartAndNum;
};
// Cluster修正.
class FClusterFixup
{
public:
FClusterFixup() {}
FClusterFixup( uint32 PageIndex, uint32 ClusterIndex, uint32 PageDependencyStart, uint32 PageDependencyNum )
{
PageAndClusterIndex = ( PageIndex << MAX_CLUSTERS_PER_PAGE_BITS ) | ClusterIndex;
PageDependencyStartAndNum = (PageDependencyStart << MAX_GROUP_PARTS_BITS) | PageDependencyNum;
}
uint32 GetPageIndex() const { return PageAndClusterIndex >> MAX_CLUSTERS_PER_PAGE_BITS; }
uint32 GetClusterIndex() const { return PageAndClusterIndex & (MAX_CLUSTERS_PER_PAGE - 1u); }
uint32 GetPageDependencyStart() const { return PageDependencyStartAndNum >> MAX_GROUP_PARTS_BITS; }
uint32 GetPageDependencyNum() const { return PageDependencyStartAndNum & MAX_GROUP_PARTS_MASK; }
uint32 PageAndClusterIndex;
uint32 PageDependencyStartAndNum;
};
// 页面磁盘头.
struct FPageDiskHeader
{
uint32 GpuSize;
uint32 NumClusters;
uint32 NumRawFloat4s;
uint32 NumTexCoords;
uint32 DecodeInfoOffset;
uint32 StripBitmaskOffset;
uint32 VertexRefBitmaskOffset;
};
// Cluster磁盘头.
struct FClusterDiskHeader
{
uint32 IndexDataOffset;
uint32 VertexRefDataOffset;
uint32 PositionDataOffset;
uint32 AttributeDataOffset;
uint32 NumPrevRefVerticesBeforeDwords;
uint32 NumPrevNewVerticesBeforeDwords;
};
// Chunk修正.
class FFixupChunk //TODO: rename to something else
{
public:
struct FHeader
{
uint16 NumClusters = 0;
uint16 NumHierachyFixups = 0;
uint16 NumClusterFixups = 0;
uint16 Pad = 0;
} Header;
uint8 Data[ sizeof(FHierarchyFixup) * MAX_CLUSTERS_PER_PAGE + sizeof( FClusterFixup ) * MAX_CLUSTERS_PER_PAGE ];
FClusterFixup& GetClusterFixup( uint32 Index ) const { check( Index < Header.NumClusterFixups ); return ( (FClusterFixup*)( Data + Header.NumHierachyFixups * sizeof( FHierarchyFixup ) ) )[ Index ]; }
FHierarchyFixup& GetHierarchyFixup( uint32 Index ) const { check( Index < Header.NumHierachyFixups ); return ((FHierarchyFixup*)Data)[ Index ]; }
uint32 GetSize() const { return sizeof( Header ) + Header.NumHierachyFixups * sizeof( FHierarchyFixup ) + Header.NumClusterFixups * sizeof( FClusterFixup ); }
};
// 实例绘制参数.
struct FInstanceDraw
{
uint32 InstanceId;
uint32 ViewId;
};
// Nanite渲染资源.
struct FResources
{
// 持久状态.
TArray< uint8 > RootClusterPage; // Root page is loaded on resource load, so we always have something to draw.
FByteBulkData StreamableClusterPages; // Remaining pages are streamed on demand.
TArray< uint16 > ImposterAtlas;
TArray< FPackedHierarchyNode > HierarchyNodes;
TArray< uint32 > HierarchyRootOffsets;
TArray< FPageStreamingState > PageStreamingStates;
TArray< uint32 > PageDependencies;
int32 PositionPrecision = 0;
bool bLZCompressed = false;
// 运行时状态.
uint32 RuntimeResourceID = 0xFFFFFFFFu;
int32 HierarchyOffset = INDEX_NONE;
int32 RootPageIndex = INDEX_NONE;
uint32 NumHierarchyNodes = 0;
(......)
ENGINE_API void InitResources();
ENGINE_API bool ReleaseResources();
ENGINE_API void Serialize(FArchive& Ar, UObject* Owner);
};
// GPU端Buffer, 包含了Nanite资源数据.
class FGlobalResources : public FRenderResource
{
public:
struct PassBuffers
{
// 候选的(即未裁剪的)节点和Cluster缓冲区.
TRefCountPtr<FRDGPooledBuffer> CandidateNodesAndClustersBuffer;
TRefCountPtr<FRDGPooledBuffer> StatsRasterizeArgsSWHWBuffer;
};
uint32 StatsRenderFlags = 0;
uint32 StatsDebugFlags = 0;
public:
virtual void InitRHI() override;
virtual void ReleaseRHI() override;
ENGINE_API void Update(FRDGBuilder& GraphBuilder); // Called once per frame before any Nanite rendering has occurred.
ENGINE_API static uint32 GetMaxCandidateClusters();
ENGINE_API static uint32 GetMaxVisibleClusters();
ENGINE_API static uint32 GetMaxNodes();
(......)
private:
PassBuffers MainPassBuffers;
PassBuffers PostPassBuffers;
class FVertexFactory* VertexFactory = nullptr;
TRefCountPtr<FRDGPooledBuffer> StatsBuffer;
// Dummy structured buffer with stride8
TRefCountPtr<FRDGPooledBuffer> StructureBufferStride8;
#if NANITE_USE_SCRATCH_BUFFERS
TRefCountPtr<FRDGPooledBuffer> PrimaryVisibleClustersBuffer;
// Used for scratch memory (transient only)
TRefCountPtr<FRDGPooledBuffer> ScratchVisibleClustersBuffer;
TRefCountPtr<FRDGPooledBuffer> ScratchOccludedInstancesBuffer;
#endif
};
extern ENGINE_API TGlobalResource< FGlobalResources > GGlobalResources;
} // namespace Nanite
6.4.1.4 Cluster, ClusterGroup, Page
由于构建Nanite数据时涉及的概念众多,这里集中阐述一下。
Nanite涉及到最核心最基础的概念便是Cluster,一个Cluster是一组相邻三角形的集合:

上:正常渲染;中:三角形可视化;下:Cluster可视化。
Cluster可以和相邻的Cluster或者相邻LOD的Cluster动态合批,使得画面不违和,不产生明显的跳变,具体此视频:
Cluster技术并非UE独创,而在早前已被育碧和寒霜引擎使用,具体可参见论文:GPU-Driven Rendering Pipeline和Optimizing the Graphics Pipeline with Compute。
下面是Cluster及其它基础类型的定义:
// Engine\Source\Developer\NaniteBuilder\Private\Cluster.h
// 网格簇, 将模型划分为若干个簇.
class FCluster
{
public:
FCluster();
FCluster( FCluster& SrcCluster, uint32 TriBegin, uint32 TriEnd, const TArray< uint32 >& TriIndexes );
FCluster( const TArray< const FCluster*, TInlineAllocator<16> >& MergeList );
FCluster(const TArray< FStaticMeshBuildVertex >& InVerts,const TArrayView< const uint32 >& InIndexes,
const TArrayView< const int32 >& InMaterialIndexes,const TBitArray<>& InBoundaryEdges,uint32 TriBegin, uint32 TriEnd, const TArray< uint32 >& TriIndexes, uint32 NumTexCoords, bool bHasColors );
// 简化Cluster, 可以指定期望的三角形数量.
float Simplify( uint32 NumTris );
// 拆分Cluster.
void Split( FGraphPartitioner& Partitioner ) const;
(......)
static const uint32 ClusterSize = 128;
// 计数器.
uint32 NumVerts = 0;
uint32 NumTris = 0;
uint32 NumTexCoords = 0;
bool bHasColors = false;
// 网格数据.
TArray< float > Verts; // 顶点
TArray< uint32 > Indexes; // 索引
TArray< int32 > MaterialIndexes; // 材质索引.
TBitArray<> BoundaryEdges; // 边界边.
TBitArray<> ExternalEdges; // 扩展边.
uint32 NumExternalEdges; // 扩展边数量.
TMap< uint32, uint32 > AdjacentClusters; // 相邻的Cluster.
// 包围盒数据.
FBounds Bounds; // 包围盒.
FSphere SphereBounds;
FSphere LODBounds;
FVector MeshBoundsMin; //网格包围盒.
FVector MeshBoundsDelta;
float SurfaceArea = 0.0f;
uint32 GUID = 0;
int32 MipLevel = 0;
// 量化位置的数据.
TArray<FIntVector> QuantizedPositions;
FIntVector QuantizedPosStart = { 0u, 0u, 0u };
uint32 QuantizedPosShift = 0u;
FIntVector QuantizedPosBits = {};
float EdgeLength = 0.0f;
float LODError = 0.0f;
// 所在的Group数据.
uint32 GroupIndex = MAX_uint32;
uint32 GroupPartIndex = MAX_uint32;
uint32 GeneratingGroupIndex= MAX_uint32;
// 材质范围.
TArray<FMaterialRange, TInlineAllocator<4>> MaterialRanges;
// 带状索引数据.
FStripDesc StripDesc;
TArray<uint8> StripIndexData;
};
// Engine\Source\Developer\NaniteBuilder\Private\ClusterDAG.h
// 簇组, 集合了若干个Cluster.
struct FClusterGroup
{
// 包围盒.
FSphere Bounds;
FSphere LODBounds;
// 误差.
float MinLODError;
float MaxParentLODError;
// 层级和网格索引.
int32 MipLevel;
uint32 MeshIndex;
// 页表索引.
uint32 PageIndexStart;
uint32 PageIndexNum;
// 子节点索引.
TArray< uint32 > Children;
friend FArchive& operator<<(FArchive& Ar, FClusterGroup& Group);
};
// Engine\Source\Developer\NaniteBuilder\Private\NaniteEncode.cpp
// FClusterGroup分拆后的全部或一部分.
struct FClusterGroupPart
{
TArray<uint32> Clusters; // 在页面分配期间可能重新排序,因此需要在这里存储一个列表。
FBounds Bounds; // 包围盒.
uint32 PageIndex; // 页表索引.
uint32 GroupIndex; // 所在的Group索引.
uint32 HierarchyNodeIndex; // 层次结构节点索引.
uint32 HierarchyChildIndex; // 层次结构子节点索引.
uint32 PageClusterOffset; // 页表Cluster列表偏移.
};
// 页表的一部分.
struct FPageSections
{
uint32 Cluster = 0;
uint32 MaterialTable = 0;
uint32 DecodeInfo = 0;
uint32 Index = 0;
uint32 Position = 0;
uint32 Attribute = 0;
uint32 GetMaterialTableSize() const { return Align(MaterialTable, 16); }
uint32 GetClusterOffset() const { return 0; }
uint32 GetMaterialTableOffset() const { return Cluster; }
uint32 GetDecodeInfoOffset() const { return Cluster + GetMaterialTableSize(); }
uint32 GetIndexOffset() const { return Cluster + GetMaterialTableSize() + DecodeInfo; }
uint32 GetPositionOffset() const { return Cluster + GetMaterialTableSize() + DecodeInfo + Index; }
uint32 GetAttributeOffset() const { return Cluster + GetMaterialTableSize() + DecodeInfo + Index + Position; }
uint32 GetTotal() const { return Cluster + GetMaterialTableSize() + DecodeInfo + Index + Position + Attribute; }
FPageSections GetOffsets() const
{
return FPageSections{ GetClusterOffset(), GetMaterialTableOffset(), GetDecodeInfoOffset(), GetIndexOffset(), GetPositionOffset(), GetAttributeOffset() };
}
void operator+=(const FPageSections& Other)
{
Cluster += Other.Cluster;
MaterialTable += Other.MaterialTable;
DecodeInfo += Other.DecodeInfo;
Index += Other.Index;
Position += Other.Position;
Attribute += Other.Attribute;
}
};
// Clsuter页表.
struct FPage
{
uint32 PartsStartIndex = 0; // FClusterGroupPart起始索引.
uint32 PartsNum = 0; // FClusterGroupPart数量.
uint32 NumClusters = 0; // Cluster数量.
FPageSections GpuSizes; // GPU尺寸.
};
// 编码信息.
struct FEncodingInfo
{
uint32 BitsPerIndex; // 每个索引的位数.
uint32 BitsPerAttribute; // 每个属性的位数.
uint32 UVPrec; // UV精度.
uint32 ColorMode; // 颜色模式.
FIntVector4 ColorMin; // 最小颜色.
FIntVector4 ColorBits; // 颜色位数.
FPageSections GpuSizes; // GPU尺寸.
// UV编码信息.
FGeometryEncodingUVInfo UVInfos[MAX_NANITE_UVS];
};
// Cluster Hierarchy的中间节点, 用于构建Hierarchy.
struct FIntermediateNode
{
uint32 PartIndex = MAX_uint32; // FClusterGroupPart索引.
uint32 MipLevel = MAX_int32; // Mip层级.
bool bLeaf = false; // 是否叶子节点.
FBounds Bound; // 包围盒.
TArray< uint32 > Children; // 子节点列表.
};
// Engine\Source\Developer\NaniteBuilder\Private\ImposterAtlas.h
// Cluster光栅化进的图集.
class FImposterAtlas
{
public:
static constexpr uint32 AtlasSize = 12;
static constexpr uint32 TileSize = 12;
FImposterAtlas( TArray< uint16 >& InPixels, const FBounds& MeshBounds );
// 光栅化指定Cluster的所有三角形到此FImposterAtlas.
void Rasterize( const FIntPoint& TilePos, const FCluster& Cluster, uint32 ClusterIndex );
private:
TArray< uint16 >& Pixels;
FVector BoundsCenter;
FVector BoundsExtent;
FMatrix GetLocalToImposter( const FIntPoint& TilePos ) const;
};
6.4.2 Nanite数据构建
本小节主要阐述Nanite在渲染前执行的预处理,包含Nanite静态数据的构建、调用过程等。
6.4.2.1 BuildNaniteFromHiResSourceModel
Nanite通过BuildNaniteFromHiResSourceModel接口从最高分辨率的模型构建需要的数据,类似于FStaticMeshBuilder::Build()接口,但会忽略减面过程,这个过程被称作Nanite切分(Nanite-fractional-cut),具体过程如下:
// Engine\Source\Developer\MeshBuilder\Private\StaticMeshBuilder.cpp
static bool BuildNaniteFromHiResSourceModel(
UStaticMesh* StaticMesh,
const FMeshNaniteSettings NaniteSettings,
FBoxSphereBounds& HiResBoundsOut,
Nanite::FResources& NaniteResourcesOut)
{
// 忽略没有高分辨率的静态网格.
if (ensure(StaticMesh->IsHiResMeshDescriptionValid()) == false)
{
return false;
}
TRACE_CPUPROFILER_EVENT_SCOPE(FStaticMeshBuilder::BuildNaniteFromHiResSourceModel);
// 获取模型数据
FMeshDescription HiResMeshDescription = *StaticMesh->GetHiResMeshDescription();
FStaticMeshSourceModel& HiResSrcModel = StaticMesh->GetHiResSourceModel();
FMeshBuildSettings& HiResBuildSettings = HiResSrcModel.BuildSettings;
// 计算切线, 光照图UV等等.
FMeshDescriptionHelper MeshDescriptionHelper(&HiResBuildSettings);
MeshDescriptionHelper.SetupRenderMeshDescription(StaticMesh, HiResMeshDescription);
// 构建临时的RenderData数据, 以便传递到后续的Nanite构建阶段.
FStaticMeshRenderData HiResTempRenderData;
HiResTempRenderData.AllocateLODResources(1);
// 注意获取的是索引为0的LOD数据(亦即最高分辨率的数据).
FStaticMeshLODResources& HiResStaticMeshLOD = HiResTempRenderData.LODResources[0];
HiResStaticMeshLOD.MaxDeviation = 0.0f;
// 准备PerSectionIndices数组, 以优化提供给GPU的索引缓冲.
TArray<TArray<uint32>> PerSectionIndices;
PerSectionIndices.AddDefaulted(HiResMeshDescription.PolygonGroups().Num());
HiResStaticMeshLOD.Sections.Empty(HiResMeshDescription.PolygonGroups().Num());
// 构建顶点和索引缓冲. 不需要WedgeMap或RemapVerts
TArray<int32> WedgeMap, RemapVerts;
TArray<FStaticMeshBuildVertex> StaticMeshBuildVertices;
BuildVertexBuffer(StaticMesh, HiResMeshDescription, HiResBuildSettings, WedgeMap, HiResStaticMeshLOD.Sections, PerSectionIndices, StaticMeshBuildVertices, MeshDescriptionHelper.GetOverlappingCorners(), RemapVerts);
WedgeMap.Empty();
const uint32 NumTextureCoord = HiResMeshDescription.VertexInstanceAttributes().GetAttributesRef<FVector2D>(MeshAttribute::VertexInstance::TextureCoordinate).GetNumChannels();
// 只有渲染数据和顶点数据需要被使用, 所以可以清理MeshDescription.
HiResMeshDescription.Empty();
// 连结逐section的索引缓冲.
TArray<uint32> CombinedIndices;
bool bNeeds32BitIndices = false;
BuildCombinedSectionIndices(PerSectionIndices, HiResStaticMeshLOD, CombinedIndices, bNeeds32BitIndices);
// 在Nanite构建之前从高分辨率网格计算包围盒, 因为它会修改StaticMeshBuildVertices.
ComputeBoundsFromVertexList(StaticMeshBuildVertices, HiResBoundsOut.Origin, HiResBoundsOut.BoxExtent, HiResBoundsOut.SphereRadius);
// Nanite构建要求section材质索引已经从SectionInfoMap中解析出来, 因为索引被烘焙进了FMaterialTriangles.
for (int32 SectionIndex = 0; SectionIndex < HiResStaticMeshLOD.Sections.Num(); SectionIndex++)
{
HiResStaticMeshLOD.Sections[SectionIndex].MaterialIndex = StaticMesh->GetSectionInfoMap().Get(0, SectionIndex).MaterialIndex;
}
// 运行Nanite构建.
{
TRACE_CPUPROFILER_EVENT_SCOPE(FStaticMeshBuilder::BuildNaniteFromHiResSourceModel::Nanite);
Nanite::IBuilderModule& NaniteBuilderModule = Nanite::IBuilderModule::Get();
if (!NaniteBuilderModule.Build(NaniteResourcesOut, StaticMeshBuildVertices, CombinedIndices, HiResStaticMeshLOD.Sections, NumTextureCoord, NaniteSettings))
{
UE_LOG(LogStaticMesh, Error, TEXT("Failed to build Nanite for HiRes static mesh. See previous line(s) for details."));
return false;
}
}
return true;
}
上面的代码涉及了几个重要接口,下面分析它们:
// Engine\Source\Runtime\Engine\Private\StaticMesh.cpp
// 是否存在有效的高分辨率网格.
bool UStaticMesh::IsHiResMeshDescriptionValid() const
{
const FStaticMeshSourceModel& SourceModel = GetHiResSourceModel();
return SourceModel.IsMeshDescriptionValid();
}
// Engine\Source\Developer\MeshBuilder\Private\MeshDescriptionHelper.cpp
void FMeshDescriptionHelper::SetupRenderMeshDescription(UObject* Owner, FMeshDescription& RenderMeshDescription)
{
TRACE_CPUPROFILER_EVENT_SCOPE(FMeshDescriptionHelper::GetRenderMeshDescription);
UStaticMesh* StaticMesh = Cast<UStaticMesh>(Owner);
const bool bNaniteBuildEnabled = StaticMesh->NaniteSettings.bEnabled;
float ComparisonThreshold = (BuildSettings->bRemoveDegenerates && !bNaniteBuildEnabled) ? THRESH_POINTS_ARE_SAME : 0.0f;
// 保证多边形法线,切线,副法线被计算, 也会从render mesh description删除的退化三件套.
FStaticMeshOperations::ComputeTriangleTangentsAndNormals(RenderMeshDescription, ComparisonThreshold);
FVertexInstanceArray& VertexInstanceArray = RenderMeshDescription.VertexInstances();
FStaticMeshAttributes Attributes(RenderMeshDescription);
TVertexInstanceAttributesRef<FVector> Normals = Attributes.GetVertexInstanceNormals();
TVertexInstanceAttributesRef<FVector> Tangents = Attributes.GetVertexInstanceTangents();
TVertexInstanceAttributesRef<float> BinormalSigns = Attributes.GetVertexInstanceBinormalSigns();
// 找到重叠的顶点,加速邻接。
FStaticMeshOperations::FindOverlappingCorners(OverlappingCorners, RenderMeshDescription, ComparisonThreshold);
// 静态网格总是混合重叠角的法线.
EComputeNTBsFlags ComputeNTBsOptions = EComputeNTBsFlags::BlendOverlappingNormals;
ComputeNTBsOptions |= BuildSettings->bComputeWeightedNormals ? EComputeNTBsFlags::WeightedNTBs : EComputeNTBsFlags::None;
ComputeNTBsOptions |= BuildSettings->bRecomputeNormals ? EComputeNTBsFlags::Normals : EComputeNTBsFlags::None;
ComputeNTBsOptions |= BuildSettings->bUseMikkTSpace ? EComputeNTBsFlags::UseMikkTSpace : EComputeNTBsFlags::None;
// Nanite网格不会计算切线数据.
if (!bNaniteBuildEnabled)
{
ComputeNTBsOptions |= BuildSettings->bRemoveDegenerates ? EComputeNTBsFlags::IgnoreDegenerateTriangles : EComputeNTBsFlags::None;
ComputeNTBsOptions |= BuildSettings->bRecomputeTangents ? EComputeNTBsFlags::Tangents : EComputeNTBsFlags::None;
}
// 计算任何丢失的法线或切线.
FStaticMeshOperations::ComputeTangentsAndNormals(RenderMeshDescription, ComputeNTBsOptions);
// 生成光照图UV.
if (BuildSettings->bGenerateLightmapUVs && VertexInstanceArray.Num() > 0)
{
TVertexInstanceAttributesRef<FVector2D> VertexInstanceUVs = Attributes.GetVertexInstanceUVs();
int32 NumIndices = VertexInstanceUVs.GetNumChannels();
//Verify the src light map channel
if (BuildSettings->SrcLightmapIndex >= NumIndices)
{
BuildSettings->SrcLightmapIndex = 0;
}
//Verify the destination light map channel
if (BuildSettings->DstLightmapIndex >= NumIndices)
{
//Make sure we do not add illegal UV Channel index
if (BuildSettings->DstLightmapIndex >= MAX_MESH_TEXTURE_COORDS_MD)
{
BuildSettings->DstLightmapIndex = MAX_MESH_TEXTURE_COORDS_MD - 1;
}
//Add some unused UVChannel to the mesh description for the lightmapUVs
VertexInstanceUVs.SetNumChannels(BuildSettings->DstLightmapIndex + 1);
BuildSettings->DstLightmapIndex = NumIndices;
}
FStaticMeshOperations::CreateLightMapUVLayout(RenderMeshDescription,
BuildSettings->SrcLightmapIndex,
BuildSettings->DstLightmapIndex,
BuildSettings->MinLightmapResolution,
(ELightmapUVVersion)StaticMesh->GetLightmapUVVersion(),
OverlappingCorners);
}
}
// Engine\Source\Developer\MeshBuilder\Private\StaticMeshBuilder.cpp
// 构建顶点缓冲区.
void BuildVertexBuffer(
UStaticMesh *StaticMesh
, const FMeshDescription& MeshDescription
, const FMeshBuildSettings& BuildSettings
, TArray<int32>& OutWedgeMap
, FStaticMeshSectionArray& OutSections
, TArray<TArray<uint32> >& OutPerSectionIndices
, TArray< FStaticMeshBuildVertex >& StaticMeshBuildVertices
, const FOverlappingCorners& OverlappingCorners
, TArray<int32>& RemapVerts)
{
TRACE_CPUPROFILER_EVENT_SCOPE(BuildVertexBuffer);
TArray<int32> RemapVertexInstanceID;
// 设置顶点缓冲元素.
const int32 NumVertexInstances = MeshDescription.VertexInstances().GetArraySize();
StaticMeshBuildVertices.Reserve(NumVertexInstances);
FStaticMeshConstAttributes Attributes(MeshDescription);
TPolygonGroupAttributesConstRef<FName> PolygonGroupImportedMaterialSlotNames = Attributes.GetPolygonGroupMaterialSlotNames();
TVertexAttributesConstRef<FVector> VertexPositions = Attributes.GetVertexPositions();
TVertexInstanceAttributesConstRef<FVector> VertexInstanceNormals = Attributes.GetVertexInstanceNormals();
TVertexInstanceAttributesConstRef<FVector> VertexInstanceTangents = Attributes.GetVertexInstanceTangents();
TVertexInstanceAttributesConstRef<float> VertexInstanceBinormalSigns = Attributes.GetVertexInstanceBinormalSigns();
TVertexInstanceAttributesConstRef<FVector4> VertexInstanceColors = Attributes.GetVertexInstanceColors();
TVertexInstanceAttributesConstRef<FVector2D> VertexInstanceUVs = Attributes.GetVertexInstanceUVs();
const bool bHasColors = VertexInstanceColors.IsValid();
const bool bIgnoreTangents = StaticMesh->NaniteSettings.bEnabled;
const uint32 NumTextureCoord = VertexInstanceUVs.GetNumChannels();
const FMatrix ScaleMatrix = FScaleMatrix(BuildSettings.BuildScale3D).Inverse().GetTransposed();
TMap<FPolygonGroupID, int32> PolygonGroupToSectionIndex;
for (const FPolygonGroupID PolygonGroupID : MeshDescription.PolygonGroups().GetElementIDs())
{
int32& SectionIndex = PolygonGroupToSectionIndex.FindOrAdd(PolygonGroupID);
SectionIndex = OutSections.Add(FStaticMeshSection());
FStaticMeshSection& StaticMeshSection = OutSections[SectionIndex];
StaticMeshSection.MaterialIndex = StaticMesh->GetMaterialIndexFromImportedMaterialSlotName(PolygonGroupImportedMaterialSlotNames[PolygonGroupID]);
if (StaticMeshSection.MaterialIndex == INDEX_NONE)
{
StaticMeshSection.MaterialIndex = PolygonGroupID.GetValue();
}
}
int32 ReserveIndicesCount = MeshDescription.Triangles().Num() * 3;
// 填充重映射数组.
RemapVerts.AddZeroed(ReserveIndicesCount);
for (int32& RemapIndex : RemapVerts)
{
RemapIndex = INDEX_NONE;
}
// 初始化楔形表OutWedgeMap
OutWedgeMap.Reset();
OutWedgeMap.AddZeroed(ReserveIndicesCount);
float VertexComparisonThreshold = BuildSettings.bRemoveDegenerates ? THRESH_POINTS_ARE_SAME : 0.0f;
int32 WedgeIndex = 0;
for (const FTriangleID TriangleID : MeshDescription.Triangles().GetElementIDs())
{
const FPolygonGroupID PolygonGroupID = MeshDescription.GetTrianglePolygonGroup(TriangleID);
const int32 SectionIndex = PolygonGroupToSectionIndex[PolygonGroupID];
TArray<uint32>& SectionIndices = OutPerSectionIndices[SectionIndex];
TArrayView<const FVertexID> VertexIDs = MeshDescription.GetTriangleVertices(TriangleID);
FVector CornerPositions[3];
for (int32 TriVert = 0; TriVert < 3; ++TriVert)
{
CornerPositions[TriVert] = VertexPositions[VertexIDs[TriVert]];
}
FOverlappingThresholds OverlappingThresholds;
OverlappingThresholds.ThresholdPosition = VertexComparisonThreshold;
// 不处理已被合并的三角形.
if (PointsEqual(CornerPositions[0], CornerPositions[1], OverlappingThresholds)
|| PointsEqual(CornerPositions[0], CornerPositions[2], OverlappingThresholds)
|| PointsEqual(CornerPositions[1], CornerPositions[2], OverlappingThresholds))
{
WedgeIndex += 3;
continue;
}
TArrayView<const FVertexInstanceID> VertexInstanceIDs = MeshDescription.GetTriangleVertexInstances(TriangleID);
for (int32 TriVert = 0; TriVert < 3; ++TriVert, ++WedgeIndex)
{
const FVertexInstanceID VertexInstanceID = VertexInstanceIDs[TriVert];
const FVector& VertexPosition = CornerPositions[TriVert];
const FVector& VertexInstanceNormal = VertexInstanceNormals[VertexInstanceID];
const FVector& VertexInstanceTangent = VertexInstanceTangents[VertexInstanceID];
const float VertexInstanceBinormalSign = VertexInstanceBinormalSigns[VertexInstanceID];
FStaticMeshBuildVertex StaticMeshVertex;
StaticMeshVertex.Position = VertexPosition * BuildSettings.BuildScale3D;
// 如果是Nanite网格, 直接赋值固定的切线和副切线.
if( bIgnoreTangents )
{
StaticMeshVertex.TangentX = FVector( 1.0f, 0.0f, 0.0f );
StaticMeshVertex.TangentY = FVector( 0.0f, 1.0f, 0.0f );
}
else
{
StaticMeshVertex.TangentX = ScaleMatrix.TransformVector(VertexInstanceTangent).GetSafeNormal();
StaticMeshVertex.TangentY = ScaleMatrix.TransformVector(FVector::CrossProduct(VertexInstanceNormal, VertexInstanceTangent) * VertexInstanceBinormalSign).GetSafeNormal();
}
StaticMeshVertex.TangentZ = ScaleMatrix.TransformVector(VertexInstanceNormal).GetSafeNormal();
if (bHasColors)
{
const FVector4& VertexInstanceColor = VertexInstanceColors[VertexInstanceID];
const FLinearColor LinearColor(VertexInstanceColor);
StaticMeshVertex.Color = LinearColor.ToFColor(true);
}
else
{
StaticMeshVertex.Color = FColor::White;
}
const uint32 MaxNumTexCoords = FMath::Min<int32>(MAX_MESH_TEXTURE_COORDS_MD, MAX_STATIC_TEXCOORDS);
for (uint32 UVIndex = 0; UVIndex < MaxNumTexCoords; ++UVIndex)
{
if(UVIndex < NumTextureCoord)
{
StaticMeshVertex.UVs[UVIndex] = VertexInstanceUVs.Get(VertexInstanceID, UVIndex);
}
else
{
StaticMeshVertex.UVs[UVIndex] = FVector2D(0.0f, 0.0f);
}
}
// 不会增加重复的顶点实例. 使用已被构建的WedgeIndex
const TArray<int32>& DupVerts = OverlappingCorners.FindIfOverlapping(WedgeIndex);
int32 Index = INDEX_NONE;
for (int32 k = 0; k < DupVerts.Num(); k++)
{
if (DupVerts[k] >= WedgeIndex)
{
break;
}
int32 Location = RemapVerts.IsValidIndex(DupVerts[k]) ? RemapVerts[DupVerts[k]] : INDEX_NONE;
if (Location != INDEX_NONE && AreVerticesEqual(StaticMeshVertex, StaticMeshBuildVertices[Location], VertexComparisonThreshold))
{
Index = Location;
break;
}
}
if (Index == INDEX_NONE)
{
Index = StaticMeshBuildVertices.Add(StaticMeshVertex);
}
RemapVerts[WedgeIndex] = Index;
OutWedgeMap[WedgeIndex] = Index;
SectionIndices.Add( Index );
}
}
// 设置缓冲区前先优化.
if (NumVertexInstances < 100000 * 3)
{
BuildOptimizationHelper::CacheOptimizeVertexAndIndexBuffer(StaticMeshBuildVertices, OutPerSectionIndices, OutWedgeMap);
}
}
// 构建组合的Section索引.
static void BuildCombinedSectionIndices(
const TArray<TArray<uint32>>& PerSectionIndices,
FStaticMeshLODResources& StaticMeshLODInOut,
TArray<uint32>& CombinedIndicesOut,
bool& bNeeds32BitIndicesOut )
{
bNeeds32BitIndicesOut = false;
for (int32 SectionIndex = 0; SectionIndex < StaticMeshLODInOut.Sections.Num(); SectionIndex++)
{
FStaticMeshSection& Section = StaticMeshLODInOut.Sections[SectionIndex];
const TArray<uint32>& SectionIndices = PerSectionIndices[SectionIndex];
Section.FirstIndex = 0;
Section.NumTriangles = 0;
Section.MinVertexIndex = 0;
Section.MaxVertexIndex = 0;
if (SectionIndices.Num())
{
Section.FirstIndex = CombinedIndicesOut.Num();
Section.NumTriangles = SectionIndices.Num() / 3;
CombinedIndicesOut.AddUninitialized(SectionIndices.Num());
uint32* DestPtr = &CombinedIndicesOut[Section.FirstIndex];
uint32 const* SrcPtr = SectionIndices.GetData();
Section.MinVertexIndex = *SrcPtr;
Section.MaxVertexIndex = *SrcPtr;
for (int32 Index = 0; Index < SectionIndices.Num(); Index++)
{
uint32 VertIndex = *SrcPtr++;
bNeeds32BitIndicesOut |= (VertIndex > MAX_uint16);
Section.MinVertexIndex = FMath::Min<uint32>(VertIndex, Section.MinVertexIndex);
Section.MaxVertexIndex = FMath::Max<uint32>(VertIndex, Section.MaxVertexIndex);
*DestPtr++ = VertIndex;
}
}
}
}
// 根据顶点计算包围盒和球体
static void ComputeBoundsFromVertexList(const TArray<FStaticMeshBuildVertex>& Vertices, FVector& OriginOut, FVector& ExtentOut, float& RadiusOut)
{
// 计算包围盒
FBox BoundingBox(ForceInit);
for (int32 VertexIndex = 0; VertexIndex < Vertices.Num(); VertexIndex++)
{
BoundingBox += Vertices[VertexIndex].Position;
}
BoundingBox.GetCenterAndExtents(OriginOut, ExtentOut);
// 计算球体, 利用包围盒的中心作为球体中心.
RadiusOut = 0.0f;
for (int32 VertexIndex = 0; VertexIndex < Vertices.Num(); VertexIndex++)
{
RadiusOut = FMath::Max((Vertices[VertexIndex].Position-OriginOut).Size(), RadiusOut);
}
}
以上的很多逻辑和普通的静态网格类似,但也存在以下几点不同:
- Nanite的源模型来自超高分辨率模型HiResSourceModel。
- Nanite网格会忽略切线、副切线的计算以及减面过程。
- 最后会调用Nanite::IBuilderModule::Build真正地构建Nanite网格数据。具体见下一小节分析。
6.4.2.2 BuildNaniteData
本小节将阐述Nanite网格的构建过程。
// Engine\Source\Developer\NaniteBuilder\Private\NaniteBuilder.cpp
bool FBuilderModule::Build(
FResources& Resources,
TArray< FStaticMeshBuildVertex>& Vertices,
TArray< uint32 >& TriangleIndices,
TArray< FStaticMeshSection, TInlineAllocator<1>>& Sections,
uint32 NumTexCoords,
const FMeshNaniteSettings& Settings)
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build);
check(Sections.Num() > 0 && Sections.Num() <= 64);
// 构建三角形索引和材质索引的关联数组。
TArray<int32> MaterialIndices;
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::BuildSections);
// 材质索引的数量和三角形数量一致.
MaterialIndices.Reserve(TriangleIndices.Num() / 3);
for (int32 SectionIndex = 0; SectionIndex < Sections.Num(); SectionIndex++)
{
FStaticMeshSection& Section = Sections[SectionIndex];
check(Section.MaterialIndex != INDEX_NONE);
for (uint32 i = 0; i < Section.NumTriangles; ++i)
{
MaterialIndices.Add(Section.MaterialIndex);
}
}
}
TArray<uint32> MeshTriangleCounts;
MeshTriangleCounts.Add(TriangleIndices.Num() / 3);
// 保证每个三角形有一个材质索引.
check(MaterialIndices.Num() * 3 == TriangleIndices.Num());
// 构建Nanite数据.
return BuildNaniteData(
Resources,
Vertices,
TriangleIndices,
MaterialIndices,
MeshTriangleCounts,
Sections,
NumTexCoords,
Settings
);
}
// 构建Nanite数据.
static bool BuildNaniteData(
FResources& Resources,
TArray< FStaticMeshBuildVertex >& Verts, // TODO: Do not require this vertex type for all users of Nanite
TArray< uint32 >& Indexes,
TArray< int32 >& MaterialIndexes,
TArray<uint32>& MeshTriangleCounts,
TArray< FStaticMeshSection, TInlineAllocator<1> >& Sections,
uint32 NumTexCoords,
const FMeshNaniteSettings& Settings
)
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::BuildData);
if (NumTexCoords > MAX_NANITE_UVS) NumTexCoords = MAX_NANITE_UVS;
FBounds VertexBounds;
uint32 Channel = 255; // 用来检测是否拥有有效的顶点数据.
for( auto& Vert : Verts )
{
VertexBounds += Vert.Position;
Channel &= Vert.Color.R;
Channel &= Vert.Color.G;
Channel &= Vert.Color.B;
Channel &= Vert.Color.A;
}
const uint32 NumMeshes = MeshTriangleCounts.Num();
// 只有非全白时才拥有颜色数据.
bool bHasColors = Channel != 255;
TArray< uint32 > ClusterCountPerMesh;
TArray< FCluster > Clusters;
{
uint32 BaseTriangle = 0;
// 遍历所有Section, 给每个Section构建一个或多个Cluster.
for (uint32 NumTriangles : MeshTriangleCounts)
{
uint32 NumClustersBefore = Clusters.Num();
if (NumTriangles)
{
// 为每个Section构建1或多个Cluster. 使用了TArrayView构建复用数据的数组.
// 后面有分析ClusterTriangles的具体过程.
ClusterTriangles(Verts, TArrayView< const uint32 >( &Indexes[BaseTriangle * 3], NumTriangles * 3 ),
TArrayView< const int32 >( &MaterialIndexes[BaseTriangle], NumTriangles ),
Clusters, VertexBounds, NumTexCoords, bHasColors);
}
// 记录每个Section的Cluster数量.
ClusterCountPerMesh.Add(Clusters.Num() - NumClustersBefore);
BaseTriangle += NumTriangles;
}
}
const int32 OldTriangleCount = Indexes.Num() / 3;
const int32 MinTriCount = 2000;
// 用粗糙代表(coarse representation)代替原始的静态网格数据。
const bool bUseCoarseRepresentation = Settings.PercentTriangles < 1.0f && OldTriangleCount > MinTriCount;
// 如果不用粗糙代表(coarse representation)替换原始的顶点缓冲, 去掉旧的拷贝数据.
// 将它复制到cluster representation中, 在更长的DAG减少阶段之前执行,以减少峰值内存持续时间。
// 当并行构建多个巨大的Nanite网格时,这一点尤为重要。
if (bUseCoarseRepresentation)
{
check(MeshTriangleCounts.Num() == 1);
Verts.Empty();
Indexes.Empty();
MaterialIndexes.Empty();
}
uint32 Time0 = FPlatformTime::Cycles();
FBounds MeshBounds;
TArray<FClusterGroup> Groups; // Cluster组列表.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::DAG.Reduce);
uint32 ClusterStart = 0;
for (uint32 MeshIndex = 0; MeshIndex < NumMeshes; MeshIndex++)
{
uint32 NumClusters = ClusterCountPerMesh[MeshIndex];
// 构建DAG(Directed Acyclic Graph,有向非循环图),以减面减模, 并且附加Cluster和Group到对应数组中.
BuildDAG( Groups, Clusters, ClusterStart, NumClusters, MeshIndex, MeshBounds );
ClusterStart += NumClusters;
}
}
uint32 ReduceTime = FPlatformTime::Cycles();
UE_LOG(LogStaticMesh, Log, TEXT("Reduce [%.2fs]"), FPlatformTime::ToMilliseconds(ReduceTime - Time0) / 1000.0f);
// 使用粗糙代表.
if (bUseCoarseRepresentation)
{
const uint32 CoarseStartTime = FPlatformTime::Cycles();
int32 CoarseTriCount = FMath::Max(MinTriCount, int32((float(OldTriangleCount) * Settings.PercentTriangles)));
TArray<FStaticMeshSection, TInlineAllocator<1>> CoarseSections = Sections;
// 构建粗糙代表.
BuildCoarseRepresentation(Groups, Clusters, Verts, Indexes, CoarseSections, NumTexCoords, CoarseTriCount);
// 使用粗糙网格范围修正网格section信息, 同时遵守原始序号和保留材质.
// 它不会以任何指定的三角形结束(由于抽取过程)。
for (FStaticMeshSection& Section : Sections)
{
// 对于每个section的信息,尝试在粗略版本中找到一个匹配的条目。
const FStaticMeshSection* CoarseSection = CoarseSections.FindByPredicate(
[&Section](const FStaticMeshSection& CoarseSectionIter)
{
return CoarseSectionIter.MaterialIndex == Section.MaterialIndex;
});
// 找到匹配的条目
if (CoarseSection != nullptr)
{
Section.FirstIndex = CoarseSection->FirstIndex;
Section.NumTriangles = CoarseSection->NumTriangles;
Section.MinVertexIndex = CoarseSection->MinVertexIndex;
Section.MaxVertexIndex = CoarseSection->MaxVertexIndex;
}
// 未找到匹配的条目.
else
{
// 由于抽取而被移除的部分,设置占位符条目
Section.FirstIndex = 0;
Section.NumTriangles = 0;
Section.MinVertexIndex = 0;
Section.MaxVertexIndex = 0;
}
}
const uint32 CoarseEndTime = FPlatformTime::Cycles();
UE_LOG(LogStaticMesh, Log, TEXT("Coarse [%.2fs], original tris: %d, coarse tris: %d"), FPlatformTime::ToMilliseconds(CoarseEndTime - CoarseStartTime) / 1000.0f, OldTriangleCount, CoarseTriCount);
}
uint32 EncodeTime0 = FPlatformTime::Cycles();
// 编码Nanite网格.
Encode( Resources, Settings, Clusters, Groups, MeshBounds, NumMeshes, NumTexCoords, bHasColors );
uint32 EncodeTime1 = FPlatformTime::Cycles();
UE_LOG( LogStaticMesh, Log, TEXT("Encode [%.2fs]"), FPlatformTime::ToMilliseconds( EncodeTime1 - EncodeTime0 ) / 1000.0f );
// 只有一个网格时才生成Imposter.
const bool bGenerateImposter = (NumMeshes == 1);
if (bGenerateImposter)
{
uint32 ImposterStartTime = FPlatformTime::Cycles();
auto& RootChildren = Groups.Last().Children;
// Resources的ImposterAtlas.
FImposterAtlas ImposterAtlas( Resources.ImposterAtlas, MeshBounds );
// 并行生成Imposter.
ParallelFor(FMath::Square(FImposterAtlas::AtlasSize),
[&](int32 TileIndex)
{
FIntPoint TilePos(
TileIndex % FImposterAtlas::AtlasSize,
TileIndex / FImposterAtlas::AtlasSize);
// 遍历所有子Cluster, 光栅化到ImposterAtlas.
for (int32 ClusterIndex = 0; ClusterIndex < RootChildren.Num(); ClusterIndex++)
{
ImposterAtlas.Rasterize(TilePos, Clusters[RootChildren[ClusterIndex]], ClusterIndex);
}
});
UE_LOG(LogStaticMesh, Log, TEXT("Imposter [%.2fs]"), FPlatformTime::ToMilliseconds(FPlatformTime::Cycles() - ImposterStartTime ) / 1000.0f);
}
uint32 Time1 = FPlatformTime::Cycles();
UE_LOG( LogStaticMesh, Log, TEXT("Nanite build [%.2fs]\n"), FPlatformTime::ToMilliseconds( Time1 - Time0 ) / 1000.0f );
return true;
}
6.4.2.3 ClusterTriangles
// 为每个Section构建1或多个Cluster.
static void ClusterTriangles(
const TArray< FStaticMeshBuildVertex >& Verts,
const TArrayView< const uint32 >& Indexes,
const TArrayView< const int32 >& MaterialIndexes,
TArray< FCluster >& Clusters, // Append
const FBounds& MeshBounds,
uint32 NumTexCoords,
bool bHasColors )
{
uint32 Time0 = FPlatformTime::Cycles();
LOG_CRC( Verts );
LOG_CRC( Indexes );
uint32 NumTriangles = Indexes.Num() / 3;
// 共享边
TArray< uint32 > SharedEdges;
SharedEdges.AddUninitialized( Indexes.Num() );
// 边界边
TBitArray<> BoundaryEdges;
BoundaryEdges.Init( false, Indexes.Num() );
// 边哈希
FHashTable EdgeHash( 1 << FMath::FloorLog2( Indexes.Num() ), Indexes.Num() );
// 并行处理边哈希.
ParallelFor( Indexes.Num(),
[&]( int32 EdgeIndex )
{
uint32 VertIndex0 = Indexes[ EdgeIndex ];
uint32 VertIndex1 = Indexes[ Cycle3( EdgeIndex ) ];
const FVector& Position0 = Verts[ VertIndex0 ].Position;
const FVector& Position1 = Verts[ VertIndex1 ].Position;
uint32 Hash0 = HashPosition( Position0 );
uint32 Hash1 = HashPosition( Position1 );
uint32 Hash = Murmur32( { Hash0, Hash1 } );
// 注意此处添加元素使用的是并发版本Add_Concurrent.
EdgeHash.Add_Concurrent( Hash, EdgeIndex );
});
const int32 NumDwords = FMath::DivideAndRoundUp( BoundaryEdges.Num(), NumBitsPerDWORD );
ParallelFor( NumDwords,
[&]( int32 DwordIndex )
{
const int32 NumIndexes = Indexes.Num();
const int32 NumBits = FMath::Min( NumBitsPerDWORD, NumIndexes - DwordIndex * NumBitsPerDWORD );
uint32 Mask = 1;
uint32 Dword = 0;
for( int32 BitIndex = 0; BitIndex < NumBits; BitIndex++, Mask <<= 1 )
{
// 计算边索引.
int32 EdgeIndex = DwordIndex * NumBitsPerDWORD + BitIndex;
uint32 VertIndex0 = Indexes[ EdgeIndex ];
uint32 VertIndex1 = Indexes[ Cycle3( EdgeIndex ) ];
const FVector& Position0 = Verts[ VertIndex0 ].Position;
const FVector& Position1 = Verts[ VertIndex1 ].Position;
uint32 Hash0 = HashPosition( Position0 );
uint32 Hash1 = HashPosition( Position1 );
uint32 Hash = Murmur32( { Hash1, Hash0 } );
// 找到共享两个顶点且方向相反的边.
/*
/\
/ \
o-<<-o
o->>-o
\ /
\/
*/
uint32 FoundEdge = ~0u;
for( uint32 OtherEdgeIndex = EdgeHash.First( Hash ); EdgeHash.IsValid( OtherEdgeIndex ); OtherEdgeIndex = EdgeHash.Next( OtherEdgeIndex ) )
{
uint32 OtherVertIndex0 = Indexes[ OtherEdgeIndex ];
uint32 OtherVertIndex1 = Indexes[ Cycle3( OtherEdgeIndex ) ];
if( Position0 == Verts[ OtherVertIndex1 ].Position &&
Position1 == Verts[ OtherVertIndex0 ].Position )
{
// 找到匹配的边.
// 哈希表不是确定性的顺序。找到稳定的匹配,而不仅仅是第一个。
FoundEdge = FMath::Min( FoundEdge, OtherEdgeIndex );
}
}
SharedEdges[ EdgeIndex ] = FoundEdge;
if( FoundEdge == ~0u )
{
Dword |= Mask;
}
}
if( Dword )
{
BoundaryEdges.GetData()[ DwordIndex ] = Dword;
}
});
// 不连贯的三角形集.
FDisjointSet DisjointSet( NumTriangles );
for( uint32 EdgeIndex = 0, Num = SharedEdges.Num(); EdgeIndex < Num; EdgeIndex++ )
{
uint32 OtherEdgeIndex = SharedEdges[ EdgeIndex ];
if( OtherEdgeIndex != ~0u )
{
// OtherEdgeIndex是匹配EdgeIndex的最小索引.
// ThisEdgeIndex是匹配OtherEdgeIndex的最小索引.
uint32 ThisEdgeIndex = SharedEdges[ OtherEdgeIndex ];
check( ThisEdgeIndex != ~0u );
check( ThisEdgeIndex <= EdgeIndex );
if( EdgeIndex > ThisEdgeIndex )
{
// 上一个元素指向OtherEdgeIndex
SharedEdges[ EdgeIndex ] = ~0u;
}
else if( EdgeIndex > OtherEdgeIndex )
{
// 再次检测.
DisjointSet.UnionSequential( EdgeIndex / 3, OtherEdgeIndex / 3 );
}
}
}
uint32 BoundaryTime = FPlatformTime::Cycles();
UE_LOG( LogStaticMesh, Log, TEXT("Boundary [%.2fs], tris: %i, UVs %i%s"), FPlatformTime::ToMilliseconds( BoundaryTime - Time0 ) / 1000.0f, Indexes.Num() / 3, NumTexCoords, bHasColors ? TEXT(", Color") : TEXT("") );
LOG_CRC( SharedEdges );
// 三角形划分.
FGraphPartitioner Partitioner( NumTriangles );
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::PartitionGraph);
// 获取三角形的中心.
auto GetCenter = [ &Verts, &Indexes ]( uint32 TriIndex )
{
FVector Center;
Center = Verts[ Indexes[ TriIndex * 3 + 0 ] ].Position;
Center += Verts[ Indexes[ TriIndex * 3 + 1 ] ].Position;
Center += Verts[ Indexes[ TriIndex * 3 + 2 ] ].Position;
return Center * (1.0f / 3.0f);
};
// 构建位置连接.
Partitioner.BuildLocalityLinks( DisjointSet, MeshBounds, GetCenter );
auto* RESTRICT Graph = Partitioner.NewGraph( NumTriangles * 3 );
// 处理划分数据.
for( uint32 i = 0; i < NumTriangles; i++ )
{
Graph->AdjacencyOffset[i] = Graph->Adjacency.Num();
uint32 TriIndex = Partitioner.Indexes[i];
for( int k = 0; k < 3; k++ )
{
uint32 EdgeIndex = SharedEdges[ 3 * TriIndex + k ];
// 增加邻边.
if( EdgeIndex != ~0u )
{
Partitioner.AddAdjacency( Graph, EdgeIndex / 3, 4 * 65 );
}
}
// 增加位置连接.
Partitioner.AddLocalityLinks( Graph, TriIndex, 1 );
}
Graph->AdjacencyOffset[ NumTriangles ] = Graph->Adjacency.Num();
// 精确地划分Cluster.
Partitioner.PartitionStrict( Graph, FCluster::ClusterSize - 4, FCluster::ClusterSize, true );
check( Partitioner.Ranges.Num() );
LOG_CRC( Partitioner.Ranges );
}
// 计算最理想的Cluster数量.
const uint32 OptimalNumClusters = FMath::DivideAndRoundUp< int32 >( Indexes.Num(), FCluster::ClusterSize * 3 );
uint32 ClusterTime = FPlatformTime::Cycles();
UE_LOG( LogStaticMesh, Log, TEXT("Clustering [%.2fs]. Ratio: %f"), FPlatformTime::ToMilliseconds( ClusterTime - BoundaryTime ) / 1000.0f, (float)Partitioner.Ranges.Num() / OptimalNumClusters );
const uint32 BaseCluster = Clusters.Num();
Clusters.AddDefaulted( Partitioner.Ranges.Num() );
// 笔者注: 大于32用单线程? 是否弄反了?
const bool bSingleThreaded = Partitioner.Ranges.Num() > 32;
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::BuildClusters);
// 并行构建Cluster.
ParallelFor( Partitioner.Ranges.Num(),
[&]( int32 Index )
{
auto& Range = Partitioner.Ranges[ Index ];
// 创建单个Cluster实例.
Clusters[ BaseCluster + Index ] = FCluster( Verts,
Indexes,
MaterialIndexes,
BoundaryEdges, Range.Begin, Range.End, Partitioner.Indexes, NumTexCoords, bHasColors );
// 负数标明它是个叶子.
Clusters[ BaseCluster + Index ].EdgeLength *= -1.0f;
}, bSingleThreaded);
}
uint32 LeavesTime = FPlatformTime::Cycles();
UE_LOG( LogStaticMesh, Log, TEXT("Leaves [%.2fs]"), FPlatformTime::ToMilliseconds( LeavesTime - ClusterTime ) / 1000.0f );
}
6.4.2.4 FGraphPartitioner
上一小节的代码在处理Cluster时使用了FGraphPartitioner,下面进入它的代码分析:
// Engine\Source\Developer\NaniteBuilder\Private\GraphPartitioner.h
(......)
// 引用了metis第三方开源库.
#include "metis.h"
(......)
// Cluster划分图
class FGraphPartitioner
{
public:
// 图数据.
struct FGraphData
{
int32 Offset; // 索引位移.
int32 Num; // 数量.
TArray< idx_t > Adjacency; // 邻边列表
TArray< idx_t > AdjacencyCost; // 邻边权重列表
TArray< idx_t > AdjacencyOffset; // 邻边位移列表
};
// 范围是[Begin, End]
struct FRange
{
uint32 Begin;
uint32 End;
bool operator<( const FRange& Other) const { return Begin < Other.Begin; }
};
TArray< FRange > Ranges;
TArray< uint32 > Indexes;
public:
FGraphPartitioner( uint32 InNumElements );
// 构建新的子图数据实例.
FGraphData* NewGraph( uint32 NumAdjacency ) const;
// 增加邻边.
void AddAdjacency( FGraphData* Graph, uint32 AdjIndex, idx_t Cost );
// 增加位置连接.
void AddLocalityLinks( FGraphData* Graph, uint32 Index, idx_t Cost );
// 构建位置连接.
template< typename FGetCenter >
void BuildLocalityLinks( FDisjointSet& DisjointSet, const FBounds& Bounds, FGetCenter& GetCenter );
// 划分Cluster.
void Partition( FGraphData* Graph, int32 InMinPartitionSize, int32 InMaxPartitionSize );
// 精确地划分Cluster.
void PartitionStrict( FGraphData* Graph, int32 InMinPartitionSize, int32 InMaxPartitionSize, bool bThreaded );
private:
// 平分子图.
void BisectGraph( FGraphData* Graph, FGraphData* ChildGraphs[2] );
// 递归平分子图.
void RecursiveBisectGraph( FGraphData* Graph );
uint32 NumElements;
int32 MinPartitionSize = 0;
int32 MaxPartitionSize = 0;
// Cluster数量. 用了原子, 以支持多线程读写.
TAtomic< uint32 > NumPartitions;
TArray< idx_t > PartitionIDs;
TArray< int32 > SwappedWith;
TArray< uint32 > SortedTo;
// 位置连接.
TMultiMap< uint32, uint32 > LocalityLinks;
};
(......)
// Engine\Source\Developer\NaniteBuilder\Private\GraphPartitioner.cpp
(......)
// 平分网格.
void FGraphPartitioner::BisectGraph( FGraphData* Graph, FGraphData* ChildGraphs[2] )
{
ChildGraphs[0] = nullptr;
ChildGraphs[1] = nullptr;
// 增加分区回调.
auto AddPartition =
[ this ]( int32 Offset, int32 Num )
{
FRange& Range = Ranges[ NumPartitions++ ];
Range.Begin = Offset;
Range.End = Offset + Num;
};
// 如果Graph的分区数量没有超限, 则直接添加到this中.
if( Graph->Num <= MaxPartitionSize )
{
AddPartition( Graph->Offset, Graph->Num );
return;
}
// 计算预期的分区尺寸.
const int32 TargetPartitionSize = ( MinPartitionSize + MaxPartitionSize ) / 2;
const int32 TargetNumPartitions = FMath::Max( 2, FMath::DivideAndRoundNearest( Graph->Num, TargetPartitionSize ) );
check( Graph->AdjacencyOffset.Num() == Graph->Num + 1 );
idx_t NumConstraints = 1;
idx_t NumParts = 2;
idx_t EdgesCut = 0;
real_t PartitionWeights[] = {
float( TargetNumPartitions / 2 ) / TargetNumPartitions,
1.0f - float( TargetNumPartitions / 2 ) / TargetNumPartitions
};
// 设置Metis库的默认操作参数.
idx_t Options[ METIS_NOPTIONS ];
METIS_SetDefaultOptions( Options );
// 在高层级允许宽松的容差, 严格的平衡在更接近分区大小之前并不重要。
bool bLoose = TargetNumPartitions >= 128 || MaxPartitionSize / MinPartitionSize > 1;
bool bSlow = Graph->Num < 4096;
Options[ METIS_OPTION_UFACTOR ] = bLoose ? 200 : 1;
//Options[ METIS_OPTION_NCUTS ] = Graph->Num < 1024 ? 8 : ( Graph->Num < 4096 ? 4 : 1 );
//Options[ METIS_OPTION_NCUTS ] = bSlow ? 4 : 1;
//Options[ METIS_OPTION_NITER ] = bSlow ? 20 : 10;
//Options[ METIS_OPTION_IPTYPE ] = METIS_IPTYPE_RANDOM;
//Options[ METIS_OPTION_MINCONN ] = 1;
// 调用Metis的递归划分.
int r = METIS_PartGraphRecursive(
&Graph->Num,
&NumConstraints, // number of balancing constraints
Graph->AdjacencyOffset.GetData(),
Graph->Adjacency.GetData(),
NULL, // Vert weights
NULL, // Vert sizes for computing the total communication volume
Graph->AdjacencyCost.GetData(), // Edge weights
&NumParts,
PartitionWeights, // Target partition weight
NULL, // Allowed load imbalance tolerance
Options,
&EdgesCut,
PartitionIDs.GetData() + Graph->Offset
);
// 确认Metis递归划分的结果有效.
if( ensureAlways( r == METIS_OK ) )
{
// 在适当的位置划分数组.
// 双方都保持排序,但顺序是颠倒的.
int32 Front = Graph->Offset;
int32 Back = Graph->Offset + Graph->Num - 1;
while( Front <= Back )
{
while( Front <= Back && PartitionIDs[ Front ] == 0 )
{
SwappedWith[ Front ] = Front;
Front++;
}
while( Front <= Back && PartitionIDs[ Back ] == 1 )
{
SwappedWith[ Back ] = Back;
Back--;
}
if( Front < Back )
{
Swap( Indexes[ Front ], Indexes[ Back ] );
SwappedWith[ Front ] = Back;
SwappedWith[ Back ] = Front;
Front++;
Back--;
}
}
int32 Split = Front;
int32 Num[2];
Num[0] = Split - Graph->Offset;
Num[1] = Graph->Offset + Graph->Num - Split;
check( Num[0] > 1 );
check( Num[1] > 1 );
// 如果两个子节点的分区尺寸未超限, 则直接添加.
if( Num[0] <= MaxPartitionSize && Num[1] <= MaxPartitionSize )
{
AddPartition( Graph->Offset, Num[0] );
AddPartition( Split, Num[1] );
}
else
{
// 创建两个子节点实例.
for( int32 i = 0; i < 2; i++ )
{
ChildGraphs[i] = new FGraphData;
ChildGraphs[i]->Adjacency.Reserve( Graph->Adjacency.Num() >> 1 );
ChildGraphs[i]->AdjacencyCost.Reserve( Graph->Adjacency.Num() >> 1 );
ChildGraphs[i]->AdjacencyOffset.Reserve( Num[i] + 1 );
ChildGraphs[i]->Num = Num[i];
}
ChildGraphs[0]->Offset = Graph->Offset;
ChildGraphs[1]->Offset = Split;
// 遍历所有子分区, 将Graph的邻边加入到ChildGraphs[0]或ChildGraphs[1]
for( int32 i = 0; i < Graph->Num; i++ )
{
// 这里代码有点trick: 若i<=ChildGraphs[0]->Num则获取ChildGraphs[0], 否则获取ChildGraphs[1].
FGraphData* ChildGraph = ChildGraphs[ i >= ChildGraphs[0]->Num ];
ChildGraph->AdjacencyOffset.Add( ChildGraph->Adjacency.Num() );
int32 OrgIndex = SwappedWith[ Graph->Offset + i ] - Graph->Offset;
for( idx_t AdjIndex = Graph->AdjacencyOffset[ OrgIndex ]; AdjIndex < Graph->AdjacencyOffset[ OrgIndex + 1 ]; AdjIndex++ )
{
idx_t Adj = Graph->Adjacency[ AdjIndex ];
idx_t AdjCost = Graph->AdjacencyCost[ AdjIndex ];
// Remap to child
Adj = SwappedWith[ Graph->Offset + Adj ] - ChildGraph->Offset;
// Edge connects to node in this graph
if( 0 <= Adj && Adj < ChildGraph->Num )
{
ChildGraph->Adjacency.Add( Adj );
ChildGraph->AdjacencyCost.Add( AdjCost );
}
}
}
ChildGraphs[0]->AdjacencyOffset.Add( ChildGraphs[0]->Adjacency.Num() );
ChildGraphs[1]->AdjacencyOffset.Add( ChildGraphs[1]->Adjacency.Num() );
}
}
}
// 精确划分
void FGraphPartitioner::PartitionStrict( FGraphData* Graph, int32 InMinPartitionSize, int32 InMaxPartitionSize, bool bThreaded )
{
MinPartitionSize = InMinPartitionSize;
MaxPartitionSize = InMaxPartitionSize;
PartitionIDs.AddUninitialized( NumElements );
SwappedWith.AddUninitialized( NumElements );
// Adding to atomically so size big enough to not need to grow.
int32 NumPartitionsExpected = FMath::DivideAndRoundUp( Graph->Num, MinPartitionSize );
Ranges.AddUninitialized( NumPartitionsExpected * 2 );
NumPartitions = 0;
// 使用多线程.
if( bThreaded && NumPartitionsExpected > 4 )
{
extern CORE_API int32 GUseNewTaskBackend;
// 使用后台线程.
if (GUseNewTaskBackend)
{
// 局部工作队列
TLocalWorkQueue<FGraphData> LocalWork(Graph);
// 这里的Self指Lambda函数自身.
LocalWork.Run(MakeYCombinator([this, &LocalWork](auto Self, FGraphData* Graph) -> void
{
FGraphData* ChildGraphs[2];
// 平均划分.
BisectGraph( Graph, ChildGraphs );
delete Graph;
if( ChildGraphs[0] && ChildGraphs[1] )
{
// 处理第1个子节点
// 只有在剩余工作足够大的情况下才会添加新的工作线程
if (ChildGraphs[0]->Num > 256)
{
LocalWork.AddTask(ChildGraphs[0]);
LocalWork.AddWorkers(1);
}
else // 否则递归调用.
{
Self(ChildGraphs[0]);
}
// 处理第2个子节点
Self(ChildGraphs[1]);
}
}));
}
// 非后台线程. 使用传统的TaskGraph任务系统.
else
{
const ENamedThreads::Type DesiredThread = IsInGameThread() ? ENamedThreads::AnyThread : ENamedThreads::AnyBackgroundThreadNormalTask;
// 构建任务.
class FBuildTask
{
public:
FBuildTask( FGraphPartitioner* InPartitioner, FGraphData* InGraph, ENamedThreads::Type InDesiredThread)
: Partitioner( InPartitioner )
, Graph( InGraph )
, DesiredThread( InDesiredThread )
{}
void DoTask( ENamedThreads::Type CurrentThread, const FGraphEventRef& MyCompletionEvent )
{
FGraphData* ChildGraphs[2];
Partitioner->BisectGraph( Graph, ChildGraphs );
delete Graph;
if( ChildGraphs[0] && ChildGraphs[1] )
{
if( ChildGraphs[0]->Num > 256 )
{
FGraphEventRef Task = TGraphTask< FBuildTask >::CreateTask().ConstructAndDispatchWhenReady( Partitioner, ChildGraphs[0], DesiredThread);
MyCompletionEvent->DontCompleteUntil( Task );
}
else
{
FBuildTask( Partitioner, ChildGraphs[0], DesiredThread).DoTask( CurrentThread, MyCompletionEvent );
}
FBuildTask( Partitioner, ChildGraphs[1], DesiredThread).DoTask( CurrentThread, MyCompletionEvent );
}
}
static FORCEINLINE TStatId GetStatId()
{
RETURN_QUICK_DECLARE_CYCLE_STAT(FBuildTask, STATGROUP_ThreadPoolAsyncTasks);
}
static FORCEINLINE ESubsequentsMode::Type GetSubsequentsMode() { return ESubsequentsMode::TrackSubsequents; }
FORCEINLINE ENamedThreads::Type GetDesiredThread() const
{
return DesiredThread;
}
private:
FGraphPartitioner* Partitioner;
FGraphData* Graph;
ENamedThreads::Type DesiredThread;
};
FGraphEventRef BuildTask = TGraphTask< FBuildTask >::CreateTask( nullptr ).ConstructAndDispatchWhenReady( this, Graph, DesiredThread);
FTaskGraphInterface::Get().WaitUntilTaskCompletes( BuildTask );
}
}
else
{
RecursiveBisectGraph( Graph );
}
Ranges.SetNum( NumPartitions );
if( bThreaded )
{
// Force a deterministic order
Ranges.Sort();
}
PartitionIDs.Empty();
SwappedWith.Empty();
}
关于Nanite的网格划分,这里补充以下说明:
- 构建Nanite时大量使用了并行化处理,包含但不限于处理边哈希、检测共享边和边界边、构建Cluster、划分网格、生成Imposter等,以缩短Nanite数据的构建时间。
- 划分网格时,根据GUseNewTaskBackend决定是启用新的后台任务并行处理还是传统的TaskGraph,新的后台任务系统是UE5才加入的功能,更加轻便简洁。
- 均分网格时用到了第三方开源库METIS的几个关键接口:METIS_SetDefaultOptions、METIS_PartGraphKway、METIS_PartGraphRecursive。
METIS是一套用于划分图、划分有限元网格和生成稀疏矩阵的填充约序的串行程序,在METIS中实现的算法是基于Karypis实验室开发的多级递归对分、多级k-way和多约束划分方案。它的关键特性有:
- 提供高品质的划分。METIS产生的分区始终优于其他广泛使用的算法产生的分区。METIS产生的分区始终比光谱划分算法(spectral partitioning algorithms)产生的分区好10%到50%。
- 处理速度异常快。大量实践表明,METIS比其他广泛使用的分区算法快一到两个数量级。在当前的工作站和pc机上,具有数百万个顶点的图形可以在几秒钟内划分为256个部分。
- 生成结果具有低填充率。由METIS产生的减少填充的排序明显优于其他广泛使用的算法,包括多最小度(multiple minimum degree)。对于科学计算和线性规划中出现的许多类问题,METIS能够将稀疏矩阵分解的存储和计算要求降低到一个数量级。与多最小度方法不同,METIS生成的消元树适用于并行直接分解。此外,METIS能够非常快地计算这些排序。在当前的工作站和pc上,具有数百万行的矩阵可以在几秒钟内重新排序。
它还有并行化的版本ParMETIS。具体参加官方说明:Family of Graph and Hypergraph Partitioning Software。
-
划分网格时的步骤、细节和逻辑比较复杂,但笔者认为Nanite的划分思路、意图和文稿METIS Three Phases Coarsening Partitioning Uncoarsening、论文Learning Boundary Edges for 3D-Mesh Segmentation比较类似,便依此加以说明网格划分的算法和过程。
在需要将某个模型划分成若干份时,可以使用普林斯顿划分原则(Princeton segmentation benchmark)手动划分,也可以借助某些算法自动划分(下图)。
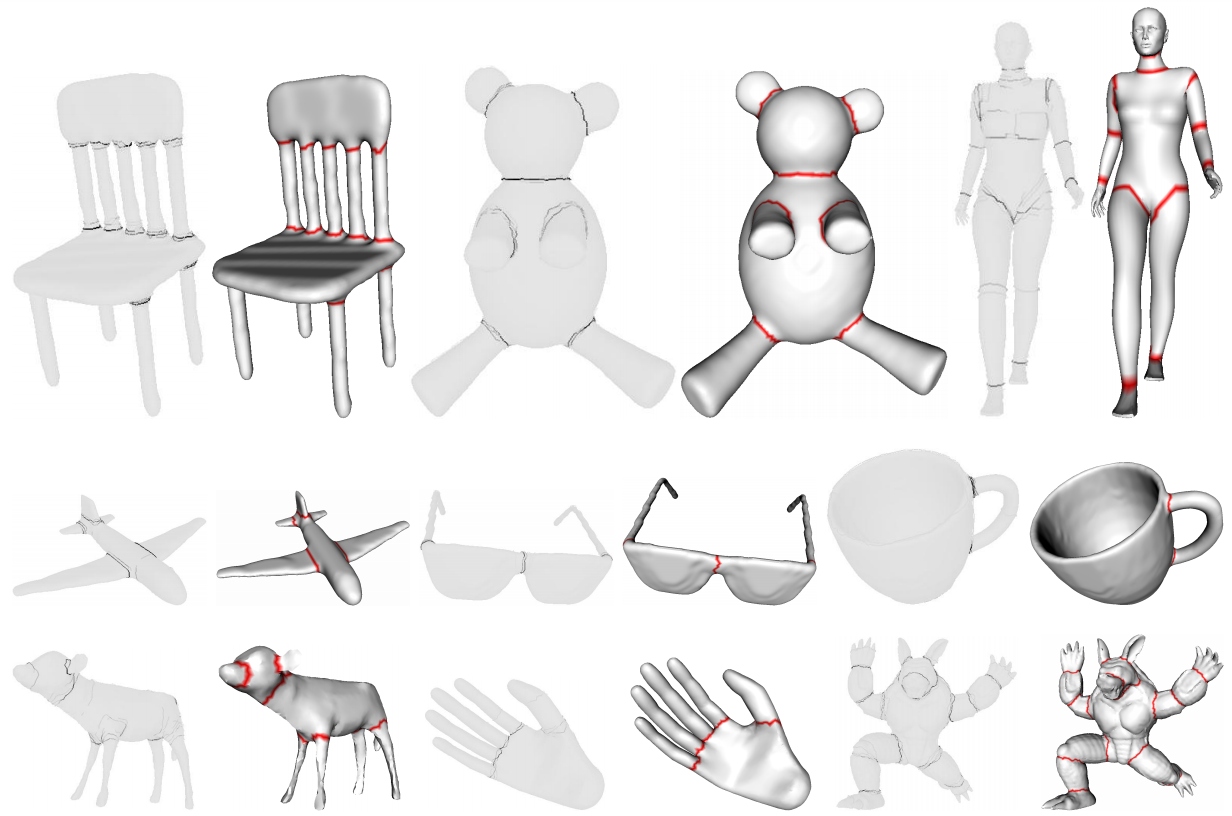
上图存在多组配对图,每组配对图的左边是基于普林斯顿划分原则手动划分的(深色的线表示手动划分的边),配对图的右边是算法自动划分而成(红色是边界)。可见自动划分算法可以和手动划分高度匹配。
自动划分算法既有结合深度学习和视觉的方法,又有像METIS的基于数理的传统算法。而METIS的划分算法有3个阶段:粗化(Coarsening)、划分(Partitioning)、细分(Uncoarsening)。

在Coarsening阶段,最大化匹配:没有共同顶点的边集合,查找复杂度上存在NP完全问题。

Coarsening在匹配最大化边缘时,存在NP完全问题,如a组明显不是最多的非共享顶点边数,b才是。
在Partitioning阶段,需要两个步骤,第一步是随机选取一个根,第二步是宽度优先搜索(breadth first search,BFS)以包含能够获得较少切边的顶点。

在Uncoarsening阶段的关键思路:每个父节点包含了一组子节点,通过从一个分区移动顶点到另一个分区来减少切边。

6.4.2.5 BuildDAG
// Engine\Source\Developer\NaniteBuilder\Private\ClusterDAG.cpp
// 构建Cluster的有向非循环图.
void BuildDAG( TArray< FClusterGroup >& Groups, TArray< FCluster >& Clusters, uint32 ClusterRangeStart, uint32 ClusterRangeNum, uint32 MeshIndex, FBounds& MeshBounds )
{
uint32 LevelOffset = ClusterRangeStart;
TAtomic< uint32 > NumClusters( Clusters.Num() );
uint32 NumExternalEdges = 0;
bool bFirstLevel = true;
while( true )
{
TArrayView< FCluster > LevelClusters( &Clusters[LevelOffset], bFirstLevel ? ClusterRangeNum : (Clusters.Num() - LevelOffset) );
bFirstLevel = false;
for( FCluster& Cluster : LevelClusters )
{
NumExternalEdges += Cluster.NumExternalEdges;
MeshBounds += Cluster.Bounds;
}
if( LevelClusters.Num() < 2 )
break;
// 如果该级别的Cluster少于每个组的最大数量, 直接添加到组列表.
if( LevelClusters.Num() <= MaxGroupSize )
{
TArray< uint32, TInlineAllocator< MaxGroupSize > > Children;
uint32 MaxParents = 0;
for( FCluster& Cluster : LevelClusters )
{
MaxParents += FMath::DivideAndRoundUp< uint32 >( Cluster.Indexes.Num(), FCluster::ClusterSize * 6 );
Children.Add( LevelOffset++ );
}
LevelOffset = Clusters.Num();
Clusters.AddDefaulted( MaxParents );
Groups.AddDefaulted( 1 );
// 使用DAG减顶点减面并添加到对应组.
DAGReduce( Groups, Clusters, NumClusters, Children, Groups.Num() - 1, MeshIndex );
// Correct num to atomic count
Clusters.SetNum( NumClusters, false );
continue;
}
// 该级别的Cluster数量大于MaxGroupSize, 需要用FGraphPartitioner进行划分.
// 外部边缘结构体
struct FExternalEdge
{
uint32 ClusterIndex;
uint32 EdgeIndex;
};
// 外部边缘列表.
TArray< FExternalEdge > ExternalEdges;
FHashTable ExternalEdgeHash;
TAtomic< uint32 > ExternalEdgeOffset(0);
// 有NumExternalEdges的总数,所以可以分配一个不增长的哈希表。
ExternalEdges.AddUninitialized( NumExternalEdges );
ExternalEdgeHash.Clear( 1 << FMath::FloorLog2( NumExternalEdges ), NumExternalEdges );
NumExternalEdges = 0;
// 并行地增加边缘到哈希表.
ParallelFor( LevelClusters.Num(),
[&]( uint32 ClusterIndex )
{
FCluster& Cluster = LevelClusters[ ClusterIndex ];
for( TConstSetBitIterator<> SetBit( Cluster.ExternalEdges ); SetBit; ++SetBit )
{
uint32 EdgeIndex = SetBit.GetIndex();
uint32 VertIndex0 = Cluster.Indexes[ EdgeIndex ];
uint32 VertIndex1 = Cluster.Indexes[ Cycle3( EdgeIndex ) ];
const FVector& Position0 = Cluster.GetPosition( VertIndex0 );
const FVector& Position1 = Cluster.GetPosition( VertIndex1 );
uint32 Hash0 = HashPosition( Position0 );
uint32 Hash1 = HashPosition( Position1 );
uint32 Hash = Murmur32( { Hash0, Hash1 } );
uint32 ExternalEdgeIndex = ExternalEdgeOffset++;
ExternalEdges[ ExternalEdgeIndex ] = { ClusterIndex, EdgeIndex };
ExternalEdgeHash.Add_Concurrent( Hash, ExternalEdgeIndex );
}
});
check( ExternalEdgeOffset == ExternalEdges.Num() );
TAtomic< uint32 > NumAdjacency(0);
// 并行地在其它Cluster查找匹配边缘.
ParallelFor( LevelClusters.Num(),
[&]( uint32 ClusterIndex )
{
FCluster& Cluster = LevelClusters[ ClusterIndex ];
for( TConstSetBitIterator<> SetBit( Cluster.ExternalEdges ); SetBit; ++SetBit )
{
uint32 EdgeIndex = SetBit.GetIndex();
uint32 VertIndex0 = Cluster.Indexes[ EdgeIndex ];
uint32 VertIndex1 = Cluster.Indexes[ Cycle3( EdgeIndex ) ];
const FVector& Position0 = Cluster.GetPosition( VertIndex0 );
const FVector& Position1 = Cluster.GetPosition( VertIndex1 );
uint32 Hash0 = HashPosition( Position0 );
uint32 Hash1 = HashPosition( Position1 );
uint32 Hash = Murmur32( { Hash1, Hash0 } );
for( uint32 ExternalEdgeIndex = ExternalEdgeHash.First( Hash ); ExternalEdgeHash.IsValid( ExternalEdgeIndex ); ExternalEdgeIndex = ExternalEdgeHash.Next( ExternalEdgeIndex ) )
{
FExternalEdge ExternalEdge = ExternalEdges[ ExternalEdgeIndex ];
FCluster& OtherCluster = LevelClusters[ ExternalEdge.ClusterIndex ];
if( OtherCluster.ExternalEdges[ ExternalEdge.EdgeIndex ] )
{
uint32 OtherVertIndex0 = OtherCluster.Indexes[ ExternalEdge.EdgeIndex ];
uint32 OtherVertIndex1 = OtherCluster.Indexes[ Cycle3( ExternalEdge.EdgeIndex ) ];
if( Position0 == OtherCluster.GetPosition( OtherVertIndex1 ) &&
Position1 == OtherCluster.GetPosition( OtherVertIndex0 ) )
{
// 找到匹配边缘, 增加其计数.
Cluster.AdjacentClusters.FindOrAdd( ExternalEdge.ClusterIndex, 0 )++;
// Can't break or a triple edge might be non-deterministically connected.
// Need to find all matching, not just first.
}
}
}
}
NumAdjacency += Cluster.AdjacentClusters.Num();
// 强制邻边的确定性顺序。
Cluster.AdjacentClusters.KeySort(
[ &LevelClusters ]( uint32 A, uint32 B )
{
return LevelClusters[A].GUID < LevelClusters[B].GUID;
} );
});
// 不连续的Cluster的集合.
FDisjointSet DisjointSet( LevelClusters.Num() );
for( uint32 ClusterIndex = 0; ClusterIndex < (uint32)LevelClusters.Num(); ClusterIndex++ )
{
for( auto& Pair : LevelClusters[ ClusterIndex ].AdjacentClusters )
{
uint32 OtherClusterIndex = Pair.Key;
uint32 Count = LevelClusters[ OtherClusterIndex ].AdjacentClusters.FindChecked( ClusterIndex );
check( Count == Pair.Value );
if( ClusterIndex > OtherClusterIndex )
{
DisjointSet.UnionSequential( ClusterIndex, OtherClusterIndex );
}
}
}
// 划分器.
FGraphPartitioner Partitioner( LevelClusters.Num() );
// 排序以强制确定性顺序。
{
TArray< uint32 > SortedIndexes;
SortedIndexes.AddUninitialized( Partitioner.Indexes.Num() );
RadixSort32( SortedIndexes.GetData(), Partitioner.Indexes.GetData(), Partitioner.Indexes.Num(),
[&]( uint32 Index )
{
return LevelClusters[ Index ].GUID;
} );
Swap( Partitioner.Indexes, SortedIndexes );
}
auto GetCenter = [&]( uint32 Index )
{
FBounds& Bounds = LevelClusters[ Index ].Bounds;
return 0.5f * ( Bounds.Min + Bounds.Max );
};
// 构建位置连接.
Partitioner.BuildLocalityLinks( DisjointSet, MeshBounds, GetCenter );
auto* RESTRICT Graph = Partitioner.NewGraph( NumAdjacency );
// 遍历所有层级的Cluster, 再遍历每个层级上的所有Cluster, 增加邻边和位置连接.
for( int32 i = 0; i < LevelClusters.Num(); i++ )
{
Graph->AdjacencyOffset[i] = Graph->Adjacency.Num();
uint32 ClusterIndex = Partitioner.Indexes[i];
for( auto& Pair : LevelClusters[ ClusterIndex ].AdjacentClusters )
{
uint32 OtherClusterIndex = Pair.Key;
uint32 NumSharedEdges = Pair.Value;
const auto& Cluster0 = Clusters[ LevelOffset + ClusterIndex ];
const auto& Cluster1 = Clusters[ LevelOffset + OtherClusterIndex ];
bool bSiblings = Cluster0.GroupIndex != MAX_uint32 && Cluster0.GroupIndex == Cluster1.GroupIndex;
Partitioner.AddAdjacency( Graph, OtherClusterIndex, NumSharedEdges * ( bSiblings ? 1 : 16 ) + 4 );
}
Partitioner.AddLocalityLinks( Graph, ClusterIndex, 1 );
}
Graph->AdjacencyOffset[ Graph->Num ] = Graph->Adjacency.Num();
LOG_CRC( Graph->Adjacency );
LOG_CRC( Graph->AdjacencyCost );
LOG_CRC( Graph->AdjacencyOffset );
// 严格分区.
Partitioner.PartitionStrict( Graph, MinGroupSize, MaxGroupSize, true );
LOG_CRC( Partitioner.Ranges );
// 计算最大父亲数量.
uint32 MaxParents = 0;
for( auto& Range : Partitioner.Ranges )
{
uint32 NumParentIndexes = 0;
for( uint32 i = Range.Begin; i < Range.End; i++ )
{
// Global indexing is needed in Reduce()
Partitioner.Indexes[i] += LevelOffset;
NumParentIndexes += Clusters[ Partitioner.Indexes[i] ].Indexes.Num();
}
MaxParents += FMath::DivideAndRoundUp( NumParentIndexes, FCluster::ClusterSize * 6 );
}
LevelOffset = Clusters.Num();
Clusters.AddDefaulted( MaxParents );
Groups.AddDefaulted( Partitioner.Ranges.Num() );
// 并行地执行DAG减面减模.
ParallelFor( Partitioner.Ranges.Num(),
[&]( int32 PartitionIndex )
{
auto& Range = Partitioner.Ranges[ PartitionIndex ];
TArrayView< uint32 > Children( &Partitioner.Indexes[ Range.Begin ], Range.End - Range.Begin );
uint32 ClusterGroupIndex = PartitionIndex + Groups.Num() - Partitioner.Ranges.Num();
DAGReduce( Groups, Clusters, NumClusters, Children, ClusterGroupIndex, MeshIndex );
});
// Correct num to atomic count
Clusters.SetNum( NumClusters, false );
}
// 最大输出根节点.
uint32 RootIndex = LevelOffset;
FClusterGroup RootClusterGroup;
RootClusterGroup.Children.Add( RootIndex );
RootClusterGroup.Bounds = Clusters[ RootIndex ].SphereBounds;
RootClusterGroup.LODBounds = FSphere( 0 );
RootClusterGroup.MaxParentLODError = 1e10f;
RootClusterGroup.MinLODError = -1.0f;
RootClusterGroup.MipLevel = Clusters[RootIndex].MipLevel + 1;
RootClusterGroup.MeshIndex = MeshIndex;
Clusters[ RootIndex ].GroupIndex = Groups.Num();
Groups.Add( RootClusterGroup );
}
上面数次执行了DAGReduce,简析其实现:
static void DAGReduce( TArray< FClusterGroup >& Groups, TArray< FCluster >& Clusters, TAtomic< uint32 >& NumClusters, TArrayView< uint32 > Children, int32 GroupIndex, uint32 MeshIndex )
{
check( GroupIndex >= 0 );
// 合并Cluster.
TArray< const FCluster*, TInlineAllocator<16> > MergeList;
for( int32 Child : Children )
{
MergeList.Add( &Clusters[ Child ] );
}
// 强制有序。
MergeList.Sort(
[]( const FCluster& A, const FCluster& B )
{
return A.GUID < B.GUID;
} );
FCluster Merged( MergeList );
int32 NumParents = FMath::DivideAndRoundUp< int32 >( Merged.Indexes.Num(), FCluster::ClusterSize * 6 );
int32 ParentStart = 0;
int32 ParentEnd = 0;
float ParentMaxLODError = 0.0f;
// 注意TargetClusterSize的步长-2.
for( int32 TargetClusterSize = FCluster::ClusterSize - 2; TargetClusterSize > FCluster::ClusterSize / 2; TargetClusterSize -= 2 )
{
int32 TargetNumTris = NumParents * TargetClusterSize;
// 简化, 会返回父节点最大LOD误差.
ParentMaxLODError = Merged.Simplify( TargetNumTris );
// 拆分
if( NumParents == 1 )
{
ParentEnd = ( NumClusters += NumParents );
ParentStart = ParentEnd - NumParents;
Clusters[ ParentStart ] = Merged;
Clusters[ ParentStart ].Bound();
break;
}
else
{
FGraphPartitioner Partitioner( Merged.Indexes.Num() / 3 );
Merged.Split( Partitioner );
if( Partitioner.Ranges.Num() <= NumParents )
{
NumParents = Partitioner.Ranges.Num();
ParentEnd = ( NumClusters += NumParents );
ParentStart = ParentEnd - NumParents;
int32 Parent = ParentStart;
for( auto& Range : Partitioner.Ranges )
{
Clusters[ Parent ] = FCluster( Merged, Range.Begin, Range.End, Partitioner.Indexes );
Parent++;
}
break;
}
}
}
TArray< FSphere, TInlineAllocator<32> > Children_LODBounds;
TArray< FSphere, TInlineAllocator<32> > Children_SphereBounds;
// 强制单调地嵌套(monotonic nesting).
float ChildMinLODError = MAX_flt;
for( int32 Child : Children )
{
bool bLeaf = Clusters[ Child ].EdgeLength < 0.0f;
float LODError = Clusters[ Child ].LODError;
Children_LODBounds.Add( Clusters[ Child ].LODBounds );
Children_SphereBounds.Add( Clusters[ Child ].SphereBounds );
ChildMinLODError = FMath::Min( ChildMinLODError, bLeaf ? -1.0f : LODError );
ParentMaxLODError = FMath::Max( ParentMaxLODError, LODError );
Clusters[ Child ].GroupIndex = GroupIndex;
Groups[ GroupIndex ].Children.Add( Child );
check( Groups[ GroupIndex ].Children.Num() <= MAX_CLUSTERS_PER_GROUP_TARGET );
}
FSphere ParentLODBounds( Children_LODBounds.GetData(), Children_LODBounds.Num() );
FSphere ParentBounds( Children_SphereBounds.GetData(), Children_SphereBounds.Num() );
// 强制父节点都有相同的LOD数据, 它们彼此依赖.
for( int32 Parent = ParentStart; Parent < ParentEnd; Parent++ )
{
Clusters[ Parent ].LODBounds = ParentLODBounds;
Clusters[ Parent ].LODError = ParentMaxLODError;
Clusters[ Parent ].GeneratingGroupIndex = GroupIndex;
}
Groups[ GroupIndex ].Bounds = ParentBounds;
Groups[ GroupIndex ].LODBounds = ParentLODBounds;
Groups[ GroupIndex ].MinLODError = ChildMinLODError;
Groups[ GroupIndex ].MaxParentLODError = ParentMaxLODError;
Groups[ GroupIndex ].MipLevel = Merged.MipLevel - 1;
Groups[ GroupIndex ].MeshIndex = MeshIndex;
}
6.4.2.6 BuildCoarseRepresentation
BuildCoarseRepresentation根据输入的Cluster列表和Cluster组列表构建网格的粗糙代表,输出对应的顶点、索引、Section等数据:
static void BuildCoarseRepresentation(
const TArray<FClusterGroup>& Groups,
const TArray<FCluster>& Clusters,
TArray<FStaticMeshBuildVertex>& Verts,
TArray<uint32>& Indexes,
TArray<FStaticMeshSection, TInlineAllocator<1>>& Sections,
uint32& NumTexCoords,
uint32 TargetNumTris
)
{
FCluster CoarseRepresentation = FindDAGCut(Groups, Clusters, TargetNumTris + 4096);
CoarseRepresentation.Simplify(TargetNumTris);
TArray< FStaticMeshSection, TInlineAllocator<1> > OldSections = Sections;
// 需要更新粗糙代表的UV计数以匹配新的数据。
NumTexCoords = CoarseRepresentation.NumTexCoords;
// 重建顶点数据。
Verts.Empty(CoarseRepresentation.NumVerts);
for (uint32 Iter = 0, Num = CoarseRepresentation.NumVerts; Iter < Num; ++Iter)
{
FStaticMeshBuildVertex Vertex = {};
Vertex.Position = CoarseRepresentation.GetPosition(Iter);
Vertex.TangentX = FVector::ZeroVector;
Vertex.TangentY = FVector::ZeroVector;
Vertex.TangentZ = CoarseRepresentation.GetNormal(Iter);
const FVector2D* UVs = CoarseRepresentation.GetUVs(Iter);
for (uint32 UVIndex = 0; UVIndex < NumTexCoords; ++UVIndex)
{
Vertex.UVs[UVIndex] = UVs[UVIndex].ContainsNaN() ? FVector2D::ZeroVector : UVs[UVIndex];
}
if (CoarseRepresentation.bHasColors)
{
Vertex.Color = CoarseRepresentation.GetColor(Iter).ToFColor(false /* sRGB */);
}
Verts.Add(Vertex);
}
TArray<FMaterialTriangle, TInlineAllocator<128>> CoarseMaterialTris;
TArray<FMaterialRange, TInlineAllocator<4>> CoarseMaterialRanges;
// 计算粗糙代表的材质范围.
BuildMaterialRanges(
CoarseRepresentation.Indexes,
CoarseRepresentation.MaterialIndexes,
CoarseMaterialTris,
CoarseMaterialRanges);
check(CoarseMaterialRanges.Num() <= OldSections.Num());
// 重建section数据.
Sections.Reset(CoarseMaterialRanges.Num());
for (const FStaticMeshSection& OldSection : OldSections)
{
// 根据计算的材质范围添加新的section.
// 强制材质顺序与OldSections一样.
const FMaterialRange* FoundRange = CoarseMaterialRanges.FindByPredicate([&OldSection](const FMaterialRange& Range) { return Range.MaterialIndex == OldSection.MaterialIndex; });
// 如果它们的源数据没有包含足够的三角形,那么它们实际上可以从粗糙网格中删除.
if (FoundRange)
{
// 从原始网格section复制属性。
FStaticMeshSection Section(OldSection);
// 渲染section时使用的顶点和索引的范围.
Section.FirstIndex = FoundRange->RangeStart * 3;
Section.NumTriangles = FoundRange->RangeLength;
Section.MinVertexIndex = TNumericLimits<uint32>::Max();
Section.MaxVertexIndex = TNumericLimits<uint32>::Min();
for (uint32 TriangleIndex = 0; TriangleIndex < (FoundRange->RangeStart + FoundRange->RangeLength); ++TriangleIndex)
{
const FMaterialTriangle& Triangle = CoarseMaterialTris[TriangleIndex];
// 更新最小顶点索引.
Section.MinVertexIndex = FMath::Min(Section.MinVertexIndex, Triangle.Index0);
Section.MinVertexIndex = FMath::Min(Section.MinVertexIndex, Triangle.Index1);
Section.MinVertexIndex = FMath::Min(Section.MinVertexIndex, Triangle.Index2);
// 更新最大顶点索引.
Section.MaxVertexIndex = FMath::Max(Section.MaxVertexIndex, Triangle.Index0);
Section.MaxVertexIndex = FMath::Max(Section.MaxVertexIndex, Triangle.Index1);
Section.MaxVertexIndex = FMath::Max(Section.MaxVertexIndex, Triangle.Index2);
}
Sections.Add(Section);
}
}
// 重建索引数据.
Indexes.Reset();
for (const FMaterialTriangle& Triangle : CoarseMaterialTris)
{
Indexes.Add(Triangle.Index0);
Indexes.Add(Triangle.Index1);
Indexes.Add(Triangle.Index2);
}
// 计算切线.
CalcTangents(Verts, Indexes);
}
6.4.2.7 NaniteEncode
Encode将Nanite资源根据FMeshNaniteSettings编码到Cluster和Cluster组中:
// Engine\Source\Developer\NaniteBuilder\Private\NaniteEncode.cpp
void Encode(
FResources& Resources,
const FMeshNaniteSettings& Settings,
TArray< FCluster >& Clusters,
TArray< FClusterGroup >& Groups,
const FBounds& MeshBounds,
uint32 NumMeshes,
uint32 NumTexCoords,
bool bHasColors )
{
// 删除退化的三角形.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::RemoveDegenerateTriangles);
RemoveDegenerateTriangles( Clusters );
}
// 构建材质范围.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::BuildMaterialRanges);
BuildMaterialRanges( Clusters );
}
// 约束Cluster.
#if USE_CONSTRAINED_CLUSTERS
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::ConstrainClusters);
ConstrainClusters( Groups, Clusters );
}
(......)
#endif
// 计算量化的位置.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::CalculateQuantizedPositions);
// 需要在cluster被约束和拆分之后触发。
Resources.PositionPrecision = CalculateQuantizedPositionsUniformGrid( Clusters, MeshBounds, Settings );
}
// 输出材质范围统计信息.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::PrintMaterialRangeStats);
PrintMaterialRangeStats( Clusters );
}
TArray<FPage> Pages;
TArray<FClusterGroupPart> GroupParts;
TArray<FEncodingInfo> EncodingInfos;
// 计算编码信息.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::CalculateEncodingInfos);
CalculateEncodingInfos(EncodingInfos, Clusters, bHasColors, NumTexCoords);
}
// 分配Cluster到Page页表.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::AssignClustersToPages);
AssignClustersToPages(Groups, Clusters, EncodingInfos, Pages, GroupParts);
}
// 构建Cluster组的层级节点.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::BuildHierarchyNodes);
BuildHierarchies(Resources, Groups, GroupParts, NumMeshes);
}
// 将Cluster和Cluster组的信息写入Page页表.
{
TRACE_CPUPROFILER_EVENT_SCOPE(Nanite::Build::WritePages);
WritePages(Resources, Pages, Groups, GroupParts, Clusters, EncodingInfos, NumTexCoords);
}
}
上面编码的过程涉及了很多重要接口,下面一一分析它们:
// Engine\Source\Developer\NaniteBuilder\Private\NaniteEncode.cpp
static void RemoveDegenerateTriangles(TArray<FCluster>& Clusters)
{
// 并行地删除Cluster列表的退化三角形.
ParallelFor( Clusters.Num(),
[&]( uint32 ClusterIndex )
{
RemoveDegenerateTriangles( Clusters[ ClusterIndex ] );
} );
}
// 删除单个Cluster的退化三角形.
static void RemoveDegenerateTriangles(FCluster& Cluster)
{
uint32 NumOldTriangles = Cluster.NumTris;
uint32 NumNewTriangles = 0;
for (uint32 OldTriangleIndex = 0; OldTriangleIndex < NumOldTriangles; OldTriangleIndex++)
{
uint32 i0 = Cluster.Indexes[OldTriangleIndex * 3 + 0];
uint32 i1 = Cluster.Indexes[OldTriangleIndex * 3 + 1];
uint32 i2 = Cluster.Indexes[OldTriangleIndex * 3 + 2];
uint32 mi = Cluster.MaterialIndexes[OldTriangleIndex];
// 如果不是退化三角形, 则3个顶点的数据必然彼此不一样.
// 笔者注: 也许这里可以做优化, 比如同一个三角形的任意两个顶点的距离小于某个阈值(0.01f)时也算退化三角形.
if (i0 != i1 && i0 != i2 && i1 != i2)
{
Cluster.Indexes[NumNewTriangles * 3 + 0] = i0;
Cluster.Indexes[NumNewTriangles * 3 + 1] = i1;
Cluster.Indexes[NumNewTriangles * 3 + 2] = i2;
Cluster.MaterialIndexes[NumNewTriangles] = mi;
NumNewTriangles++;
}
}
Cluster.NumTris = NumNewTriangles;
Cluster.Indexes.SetNum(NumNewTriangles * 3);
Cluster.MaterialIndexes.SetNum(NumNewTriangles);
}
// 将Cluster三角形分类到材质范围内, 添加材质范围到Cluster。
static void BuildMaterialRanges( TArray<FCluster>& Clusters )
{
// 并行处理.
ParallelFor( Clusters.Num(),
[&]( uint32 ClusterIndex )
{
BuildMaterialRanges( Clusters[ ClusterIndex ] );
} );
}
static void BuildMaterialRanges(FCluster& Cluster)
{
TArray<FMaterialTriangle, TInlineAllocator<128>> MaterialTris;
// 构建单个Cluster的材质范围.
BuildMaterialRanges(
Cluster.Indexes,
Cluster.MaterialIndexes,
MaterialTris,
Cluster.MaterialRanges);
// 将索引写回到Cluster.
for (uint32 Triangle = 0; Triangle < Cluster.NumTris; ++Triangle)
{
Cluster.Indexes[Triangle * 3 + 0] = MaterialTris[Triangle].Index0;
Cluster.Indexes[Triangle * 3 + 1] = MaterialTris[Triangle].Index1;
Cluster.Indexes[Triangle * 3 + 2] = MaterialTris[Triangle].Index2;
Cluster.MaterialIndexes[Triangle] = MaterialTris[Triangle].MaterialIndex;
}
}
// 约束Cluster.
static void ConstrainClusters( TArray< FClusterGroup >& ClusterGroups, TArray< FCluster >& Clusters )
{
// 计算统计信息.
uint32 TotalOldTriangles = 0;
uint32 TotalOldVertices = 0;
for( const FCluster& Cluster : Clusters )
{
TotalOldTriangles += Cluster.NumTris;
TotalOldVertices += Cluster.NumVerts;
}
// 并行地约束Cluster, 区分是否使用带状索引.
ParallelFor( Clusters.Num(),
[&]( uint32 i )
{
#if USE_STRIP_INDICES // 使用带状索引.
FStripifier Stripifier;
Stripifier.ConstrainAndStripifyCluster(Clusters[i]);
#else // 不使用带状索引.
ConstrainClusterFIFO(Clusters[i]);
#endif
} );
uint32 TotalNewTriangles = 0;
uint32 TotalNewVertices = 0;
// 约束cluster.
const uint32 NumOldClusters = Clusters.Num();
for( uint32 i = 0; i < NumOldClusters; i++ )
{
TotalNewTriangles += Clusters[ i ].NumTris;
TotalNewVertices += Clusters[ i ].NumVerts;
// 如果Cluster太多顶点(多于256个), 则拆分它们.
if( Clusters[ i ].NumVerts > 256 )
{
FCluster ClusterA, ClusterB;
uint32 NumTrianglesA = Clusters[ i ].NumTris / 2;
uint32 NumTrianglesB = Clusters[ i ].NumTris - NumTrianglesA;
BuildClusterFromClusterTriangleRange( Clusters[ i ], ClusterA, 0, NumTrianglesA );
BuildClusterFromClusterTriangleRange( Clusters[ i ], ClusterB, NumTrianglesA, NumTrianglesB );
Clusters[ i ] = ClusterA;
ClusterGroups[ ClusterB.GroupIndex ].Children.Add( Clusters.Num() );
Clusters.Add( ClusterB );
}
}
// 计算统计信息.
uint32 TotalNewTrianglesWithSplits = 0;
uint32 TotalNewVerticesWithSplits = 0;
for( const FCluster& Cluster : Clusters )
{
TotalNewTrianglesWithSplits += Cluster.NumTris;
TotalNewVerticesWithSplits += Cluster.NumVerts;
}
(......)
}
// 计算量化位置的均匀格子.
static int32 CalculateQuantizedPositionsUniformGrid(TArray< FCluster >& Clusters, const FBounds& MeshBounds, const FMeshNaniteSettings& Settings)
{
// 为EA简化全局的量化值.
const int32 MaxPositionQuantizedValue = (1 << MAX_POSITION_QUANTIZATION_BITS) - 1;
int32 PositionPrecision = Settings.PositionPrecision;
if (PositionPrecision == MIN_int32)
{
// 自动: 从叶子层级的边界上猜测需要的精度.
const float MaxSize = MeshBounds.GetExtent().GetMax();
// 启发: 如果网格更密集,需要更高的分辨率.
// 使用cluster大小的几何平均值作为密度的代理.
// 另一种解读: 位精度是cluster所需的平均值.
// 对于大小大致相同的cluster,这给出的结果与旧的量化代码非常相似.
double TotalLogSize = 0.0;
int32 TotalNum = 0;
for (const FCluster& Cluster : Clusters)
{
if (Cluster.MipLevel == 0)
{
float ExtentSize = Cluster.Bounds.GetExtent().Size();
if (ExtentSize > 0.0)
{
TotalLogSize += FMath::Log2(ExtentSize);
TotalNum++;
}
}
}
double AvgLogSize = TotalNum > 0 ? TotalLogSize / TotalNum : 0.0;
PositionPrecision = 7 - FMath::RoundToInt(AvgLogSize);
// 截断精度. 用户现在需要明确选择最低精度设置.
// 这些设置可能会导致问题,并且对节省磁盘大小的贡献很小(在测试项目中约为0.4%), 所以不应该自动选择它们.
// 例如:一个非常低分辨率的道路或建筑框架,在孤立状态下看起来不需要什么精度, 但是在一个场景中仍然需要相当高的精度,因为更小的网格被放置在上面或里面.
const int32 AUTO_MIN_PRECISION = 4; // 最小精度是1/16cm.
PositionPrecision = FMath::Max(PositionPrecision, AUTO_MIN_PRECISION);
}
// 计算量化比例.
float QuantizationScale = FMath::Exp2((float)PositionPrecision);
// 确保所有cluster都是可编码的。一个足够大的cluster可能会达到21bpc的极限。如果发生了,就缩小规模,直到合适为止。
for (const FCluster& Cluster : Clusters)
{
const FBounds& Bounds = Cluster.Bounds;
int32 Iterations = 0;
while (true)
{
float MinX = FMath::RoundToFloat(Bounds.Min.X * QuantizationScale);
float MinY = FMath::RoundToFloat(Bounds.Min.Y * QuantizationScale);
float MinZ = FMath::RoundToFloat(Bounds.Min.Z * QuantizationScale);
float MaxX = FMath::RoundToFloat(Bounds.Max.X * QuantizationScale);
float MaxY = FMath::RoundToFloat(Bounds.Max.Y * QuantizationScale);
float MaxZ = FMath::RoundToFloat(Bounds.Max.Z * QuantizationScale);
if (MinX >= (double)MIN_int32 && MinY >= (double)MIN_int32 && MinZ >= (double)MIN_int32 && // MIN_int32/MAX_int32 is not representable in float
MaxX <= (double)MAX_int32 && MaxY <= (double)MAX_int32 && MaxZ <= (double)MAX_int32 &&
((int32)MaxX - (int32)MinX) <= MaxPositionQuantizedValue && ((int32)MaxY - (int32)MinY) <= MaxPositionQuantizedValue && ((int32)MaxZ - (int32)MinZ) <= MaxPositionQuantizedValue)
{
break;
}
QuantizationScale *= 0.5f;
PositionPrecision--;
check(++Iterations < 100); // Endless loop?
}
}
const float RcpQuantizationScale = 1.0f / QuantizationScale;
// 并行地处理位置量化.
ParallelFor(Clusters.Num(), [&](uint32 ClusterIndex)
{
FCluster& Cluster = Clusters[ClusterIndex];
const uint32 NumClusterVerts = Cluster.NumVerts;
const uint32 ClusterShift = Cluster.QuantizedPosShift;
Cluster.QuantizedPositions.SetNumUninitialized(NumClusterVerts);
// 量化位置.
FIntVector IntClusterMax = { MIN_int32, MIN_int32, MIN_int32 };
FIntVector IntClusterMin = { MAX_int32, MAX_int32, MAX_int32 };
for (uint32 i = 0; i < NumClusterVerts; i++)
{
const FVector Position = Cluster.GetPosition(i);
FIntVector& IntPosition = Cluster.QuantizedPositions[i];
float PosX = FMath::RoundToFloat(Position.X * QuantizationScale);
float PosY = FMath::RoundToFloat(Position.Y * QuantizationScale);
float PosZ = FMath::RoundToFloat(Position.Z * QuantizationScale);
IntPosition = FIntVector((int32)PosX, (int32)PosY, (int32)PosZ);
IntClusterMax.X = FMath::Max(IntClusterMax.X, IntPosition.X);
IntClusterMax.Y = FMath::Max(IntClusterMax.Y, IntPosition.Y);
IntClusterMax.Z = FMath::Max(IntClusterMax.Z, IntPosition.Z);
IntClusterMin.X = FMath::Min(IntClusterMin.X, IntPosition.X);
IntClusterMin.Y = FMath::Min(IntClusterMin.Y, IntPosition.Y);
IntClusterMin.Z = FMath::Min(IntClusterMin.Z, IntPosition.Z);
}
// 存储最小位数.
const uint32 NumBitsX = FMath::CeilLogTwo(IntClusterMax.X - IntClusterMin.X + 1);
const uint32 NumBitsY = FMath::CeilLogTwo(IntClusterMax.Y - IntClusterMin.Y + 1);
const uint32 NumBitsZ = FMath::CeilLogTwo(IntClusterMax.Z - IntClusterMin.Z + 1);
check(NumBitsX <= MAX_POSITION_QUANTIZATION_BITS);
check(NumBitsY <= MAX_POSITION_QUANTIZATION_BITS);
check(NumBitsZ <= MAX_POSITION_QUANTIZATION_BITS);
for (uint32 i = 0; i < NumClusterVerts; i++)
{
FIntVector& IntPosition = Cluster.QuantizedPositions[i];
// 用量化数据更新浮点位置.
Cluster.GetPosition(i) = FVector(IntPosition.X * RcpQuantizationScale, IntPosition.Y * RcpQuantizationScale, IntPosition.Z * RcpQuantizationScale);
IntPosition.X -= IntClusterMin.X;
IntPosition.Y -= IntClusterMin.Y;
IntPosition.Z -= IntClusterMin.Z;
check(IntPosition.X >= 0 && IntPosition.X < (1 << NumBitsX));
check(IntPosition.Y >= 0 && IntPosition.Y < (1 << NumBitsY));
check(IntPosition.Z >= 0 && IntPosition.Z < (1 << NumBitsZ));
}
// 更新包围盒.
Cluster.Bounds.Min = FVector(IntClusterMin.X * RcpQuantizationScale, IntClusterMin.Y * RcpQuantizationScale, IntClusterMin.Z * RcpQuantizationScale);
Cluster.Bounds.Max = FVector(IntClusterMax.X * RcpQuantizationScale, IntClusterMax.Y * RcpQuantizationScale, IntClusterMax.Z * RcpQuantizationScale);
Cluster.MeshBoundsMin = FVector::ZeroVector;
Cluster.MeshBoundsDelta = FVector(RcpQuantizationScale);
Cluster.QuantizedPosBits = FIntVector(NumBitsX, NumBitsY, NumBitsZ);
Cluster.QuantizedPosStart = IntClusterMin;
Cluster.QuantizedPosShift = 0;
} );
return PositionPrecision;
}
// 计算一组Cluster的编码信息.
static void CalculateEncodingInfos(TArray<FEncodingInfo>& EncodingInfos, const TArray<Nanite::FCluster>& Clusters, bool bHasColors, uint32 NumTexCoords)
{
uint32 NumClusters = Clusters.Num();
EncodingInfos.SetNumUninitialized(NumClusters);
for (uint32 i = 0; i < NumClusters; i++)
{
CalculateEncodingInfo(EncodingInfos[i], Clusters[i], bHasColors, NumTexCoords);
}
}
// 计算单个Cluster的编码信息.
static void CalculateEncodingInfo(FEncodingInfo& Info, const Nanite::FCluster& Cluster, bool bHasColors, uint32 NumTexCoords)
{
const uint32 NumClusterVerts = Cluster.NumVerts;
const uint32 NumClusterTris = Cluster.NumTris;
FMemory::Memzero(Info);
// 写三角形索引。索引存储在一个密集的位流中,每个索引使用ceil(log2(NumClusterVerices))位。着色器实现了未对齐的位流读取来支持这一点。
const uint32 BitsPerIndex = NumClusterVerts > 1 ? (FGenericPlatformMath::FloorLog2(NumClusterVerts - 1) + 1) : 0;
const uint32 BitsPerTriangle = BitsPerIndex + 2 * 5; // Base index + two 5-bit offsets
Info.BitsPerIndex = BitsPerIndex;
// 计算页信息.
FPageSections& GpuSizes = Info.GpuSizes;
GpuSizes.Cluster = sizeof(FPackedCluster);
GpuSizes.MaterialTable = CalcMaterialTableSize(Cluster) * sizeof(uint32);
GpuSizes.DecodeInfo = NumTexCoords * sizeof(FUVRange);
GpuSizes.Index = (NumClusterTris * BitsPerTriangle + 31) / 32 * 4;
#if USE_UNCOMPRESSED_VERTEX_DATA // 使用未压缩的顶点数据.
const uint32 AttribBytesPerVertex = (3 * sizeof(float) + sizeof(uint32) + NumTexCoords * 2 * sizeof(float));
Info.BitsPerAttribute = AttribBytesPerVertex * 8;
Info.ColorMin = FIntVector4(0, 0, 0, 0);
Info.ColorBits = FIntVector4(8, 8, 8, 8);
Info.ColorMode = VERTEX_COLOR_MODE_VARIABLE;
Info.UVPrec = 0;
GpuSizes.Position = NumClusterVerts * 3 * sizeof(float);
GpuSizes.Attribute = NumClusterVerts * AttribBytesPerVertex;
#else // 使用压缩的顶点数据.
Info.BitsPerAttribute = 2 * NORMAL_QUANTIZATION_BITS;
check(NumClusterVerts > 0);
const bool bIsLeaf = (Cluster.GeneratingGroupIndex == INVALID_GROUP_INDEX);
// 顶点颜色.
Info.ColorMode = VERTEX_COLOR_MODE_WHITE;
Info.ColorMin = FIntVector4(255, 255, 255, 255);
if (bHasColors)
{
FIntVector4 ColorMin = FIntVector4( 255, 255, 255, 255);
FIntVector4 ColorMax = FIntVector4( 0, 0, 0, 0);
for (uint32 i = 0; i < NumClusterVerts; i++)
{
FColor Color = Cluster.GetColor(i).ToFColor(false);
ColorMin.X = FMath::Min(ColorMin.X, (int32)Color.R);
ColorMin.Y = FMath::Min(ColorMin.Y, (int32)Color.G);
ColorMin.Z = FMath::Min(ColorMin.Z, (int32)Color.B);
ColorMin.W = FMath::Min(ColorMin.W, (int32)Color.A);
ColorMax.X = FMath::Max(ColorMax.X, (int32)Color.R);
ColorMax.Y = FMath::Max(ColorMax.Y, (int32)Color.G);
ColorMax.Z = FMath::Max(ColorMax.Z, (int32)Color.B);
ColorMax.W = FMath::Max(ColorMax.W, (int32)Color.A);
}
const FIntVector4 ColorDelta = ColorMax - ColorMin;
const int32 R_Bits = FMath::CeilLogTwo(ColorDelta.X + 1);
const int32 G_Bits = FMath::CeilLogTwo(ColorDelta.Y + 1);
const int32 B_Bits = FMath::CeilLogTwo(ColorDelta.Z + 1);
const int32 A_Bits = FMath::CeilLogTwo(ColorDelta.W + 1);
uint32 NumColorBits = R_Bits + G_Bits + B_Bits + A_Bits;
Info.BitsPerAttribute += NumColorBits;
Info.ColorMin = ColorMin;
Info.ColorBits = FIntVector4(R_Bits, G_Bits, B_Bits, A_Bits);
if (NumColorBits > 0)
{
Info.ColorMode = VERTEX_COLOR_MODE_VARIABLE;
}
else
{
if (ColorMin.X == 255 && ColorMin.Y == 255 && ColorMin.Z == 255 && ColorMin.W == 255)
Info.ColorMode = VERTEX_COLOR_MODE_WHITE;
else
Info.ColorMode = VERTEX_COLOR_MODE_CONSTANT;
}
}
for( uint32 UVIndex = 0; UVIndex < NumTexCoords; UVIndex++ )
{
FGeometryEncodingUVInfo& UVInfo = Info.UVInfos[UVIndex];
// 分块压缩纹理坐标.
// 纹理坐标相对于Cluster的最小/最大UV坐标存储.
// UV接缝产生非常大的稀疏边界矩形. 为了减轻这一点,最大的差距在U和V的边界矩形被排除在编码空间.
// 解码这个非常简单: UV += (UV >= GapStart) ? GapRange : 0;
// 生成有序的U和V数组.
TArray<float> UValues;
TArray<float> VValues;
UValues.AddUninitialized(NumClusterVerts);
VValues.AddUninitialized(NumClusterVerts);
for (uint32 i = 0; i < NumClusterVerts; i++)
{
const FVector2D& UV = Cluster.GetUVs(i)[ UVIndex ];
UValues[i] = UV.X;
VValues[i] = UV.Y;
}
UValues.Sort();
VValues.Sort();
// 找出有序uv之间的最大差距
FVector2D LargestGapStart = FVector2D(UValues[0], VValues[0]);
FVector2D LargestGapEnd = FVector2D(UValues[0], VValues[0]);
for (uint32 i = 0; i < NumClusterVerts - 1; i++)
{
if (UValues[i + 1] - UValues[i] > LargestGapEnd.X - LargestGapStart.X)
{
LargestGapStart.X = UValues[i];
LargestGapEnd.X = UValues[i + 1];
}
if (VValues[i + 1] - VValues[i] > LargestGapEnd.Y - LargestGapStart.Y)
{
LargestGapStart.Y = VValues[i];
LargestGapEnd.Y = VValues[i + 1];
}
}
const FVector2D UVMin = FVector2D(UValues[0], VValues[0]);
const FVector2D UVMax = FVector2D(UValues[NumClusterVerts - 1], VValues[NumClusterVerts - 1]);
const FVector2D UVDelta = UVMax - UVMin;
const FVector2D UVRcpDelta = FVector2D( UVDelta.X > SMALL_NUMBER ? 1.0f / UVDelta.X : 0.0f,
UVDelta.Y > SMALL_NUMBER ? 1.0f / UVDelta.Y : 0.0f);
const FVector2D NonGapLength = FVector2D::Max(UVDelta - (LargestGapEnd - LargestGapStart), FVector2D(0.0f, 0.0f));
const FVector2D NormalizedGapStart = (LargestGapStart - UVMin) * UVRcpDelta;
const FVector2D NormalizedGapEnd = (LargestGapEnd - UVMin) * UVRcpDelta;
const FVector2D NormalizedNonGapLength = NonGapLength * UVRcpDelta;
#if 1
const float TexCoordUnitPrecision = (1 << 14); // TODO: Implement UI + 'Auto' mode that decides when this is necessary.
int32 TexCoordBitsU = 0;
if (UVDelta.X > 0)
{
// 即使当NonGapLength=0时,UVDelta是非零的,所以至少需要2个值(1bit)来区分高和低。
int32 NumValues = FMath::Max(FMath::CeilToInt(NonGapLength.X * TexCoordUnitPrecision), 2);
// 限制在12位, 从下面的临时hack可知已足够好了.
TexCoordBitsU = FMath::Min((int32)FMath::CeilLogTwo(NumValues), 12);
}
int32 TexCoordBitsV = 0;
if (UVDelta.Y > 0)
{
int32 NumValues = FMath::Max(FMath::CeilToInt(NonGapLength.Y * TexCoordUnitPrecision), 2);
TexCoordBitsV = FMath::Min((int32)FMath::CeilLogTwo(NumValues), 12);
}
#else
// 临时hack以修正编码问题.
const int32 TexCoordBitsU = 12;
const int32 TexCoordBitsV = 12;
#endif
// 处理UV坐标和大小.
Info.UVPrec |= ((TexCoordBitsV << 4) | TexCoordBitsU) << (UVIndex * 8);
const int32 TexCoordMaxValueU = (1 << TexCoordBitsU) - 1;
const int32 TexCoordMaxValueV = (1 << TexCoordBitsV) - 1;
const int32 NU = (int32)FMath::Clamp(NormalizedNonGapLength.X > SMALL_NUMBER ? (TexCoordMaxValueU - 2) / NormalizedNonGapLength.X : 0.0f, (float)TexCoordMaxValueU, (float)0xFFFF);
const int32 NV = (int32)FMath::Clamp(NormalizedNonGapLength.Y > SMALL_NUMBER ? (TexCoordMaxValueV - 2) / NormalizedNonGapLength.Y : 0.0f, (float)TexCoordMaxValueV, (float)0xFFFF);
int32 GapStartU = TexCoordMaxValueU + 1;
int32 GapStartV = TexCoordMaxValueV + 1;
int32 GapLengthU = 0;
int32 GapLengthV = 0;
if (NU > TexCoordMaxValueU)
{
GapStartU = int32(NormalizedGapStart.X * NU + 0.5f) + 1;
const int32 GapEndU = int32(NormalizedGapEnd.X * NU + 0.5f);
GapLengthU = FMath::Max(GapEndU - GapStartU, 0);
}
if (NV > TexCoordMaxValueV)
{
GapStartV = int32(NormalizedGapStart.Y * NV + 0.5f) + 1;
const int32 GapEndV = int32(NormalizedGapEnd.Y * NV + 0.5f);
GapLengthV = FMath::Max(GapEndV - GapStartV, 0);
}
UVInfo.UVRange.Min = UVMin;
UVInfo.UVRange.Scale = FVector2D(NU > 0 ? UVDelta.X / NU : 0.0f, NV > 0 ? UVDelta.Y / NV : 0.0f);
check(GapStartU >= 0);
check(GapStartV >= 0);
UVInfo.UVRange.GapStart[0] = GapStartU;
UVInfo.UVRange.GapStart[1] = GapStartV;
UVInfo.UVRange.GapLength[0] = GapLengthU;
UVInfo.UVRange.GapLength[1] = GapLengthV;
UVInfo.UVDelta = UVDelta;
UVInfo.UVRcpDelta = UVRcpDelta;
UVInfo.NU = NU;
UVInfo.NV = NV;
Info.BitsPerAttribute += TexCoordBitsU + TexCoordBitsV;
}
const uint32 PositionBitsPerVertex = Cluster.QuantizedPosBits.X + Cluster.QuantizedPosBits.Y + Cluster.QuantizedPosBits.Z;
GpuSizes.Position = (NumClusterVerts * PositionBitsPerVertex + 31) / 32 * 4;
GpuSizes.Attribute = (NumClusterVerts * Info.BitsPerAttribute + 31) / 32 * 4;
#endif
}
/*
构建流式Page
Page布局:
Fixup Chunk (仅加载到CPU内存)
FPackedCluster
MaterialRangeTable
GeometryData
*/
static void AssignClustersToPages(
TArray< FClusterGroup >& ClusterGroups,
TArray< FCluster >& Clusters,
const TArray< FEncodingInfo >& EncodingInfos,
TArray<FPage>& Pages,
TArray<FClusterGroupPart>& Parts
)
{
check(Pages.Num() == 0);
check(Parts.Num() == 0);
const uint32 NumClusterGroups = ClusterGroups.Num();
Pages.AddDefaulted();
SortGroupClusters(ClusterGroups, Clusters);
TArray<uint32> ClusterGroupPermutation = CalculateClusterGroupPermutation(ClusterGroups);
for (uint32 i = 0; i < NumClusterGroups; i++)
{
// 挑选最好的下一个Group.
uint32 GroupIndex = ClusterGroupPermutation[i];
FClusterGroup& Group = ClusterGroups[GroupIndex];
uint32 GroupStartPage = INVALID_PAGE_INDEX;
for (uint32 ClusterIndex : Group.Children)
{
// 挑选最好的下一个Cluster.
FCluster& Cluster = Clusters[ClusterIndex];
const FEncodingInfo& EncodingInfo = EncodingInfos[ClusterIndex];
// 加入Page.
FPage* Page = &Pages.Top();
if (Page->GpuSizes.GetTotal() + EncodingInfo.GpuSizes.GetTotal() > CLUSTER_PAGE_GPU_SIZE || Page->NumClusters + 1 > MAX_CLUSTERS_PER_PAGE)
{
// Page已满, 需要新增一个.
Pages.AddDefaulted();
Page = &Pages.Top();
}
// 检测是否增加新的FClusterGroupPart.
if (Page->PartsNum == 0 || Parts[Page->PartsStartIndex + Page->PartsNum - 1].GroupIndex != GroupIndex)
{
if (Page->PartsNum == 0)
{
Page->PartsStartIndex = Parts.Num();
}
Page->PartsNum++;
FClusterGroupPart& Part = Parts.AddDefaulted_GetRef();
Part.GroupIndex = GroupIndex;
}
// 添加cluster到page.
uint32 PageIndex = Pages.Num() - 1;
uint32 PartIndex = Parts.Num() - 1;
FClusterGroupPart& Part = Parts.Last();
if (Part.Clusters.Num() == 0)
{
Part.PageClusterOffset = Page->NumClusters;
Part.PageIndex = PageIndex;
}
Part.Clusters.Add(ClusterIndex);
check(Part.Clusters.Num() <= MAX_CLUSTERS_PER_GROUP);
Cluster.GroupPartIndex = PartIndex;
if (GroupStartPage == INVALID_PAGE_INDEX)
{
GroupStartPage = PageIndex;
}
Page->GpuSizes += EncodingInfo.GpuSizes;
Page->NumClusters++;
}
Group.PageIndexStart = GroupStartPage;
Group.PageIndexNum = Pages.Num() - GroupStartPage;
check(Group.PageIndexNum >= 1);
check(Group.PageIndexNum <= MAX_GROUP_PARTS_MASK);
}
// 重新计算group part的包围盒.
for (FClusterGroupPart& Part : Parts)
{
check(Part.Clusters.Num() <= MAX_CLUSTERS_PER_GROUP);
check(Part.PageIndex < (uint32)Pages.Num());
FBounds Bounds;
for (uint32 ClusterIndex : Part.Clusters)
{
Bounds += Clusters[ClusterIndex].Bounds;
}
Part.Bounds = Bounds;
}
}
// 构建ClusterGroup层级结构.
static void BuildHierarchies(FResources& Resources, const TArray<FClusterGroup>& Groups, TArray<FClusterGroupPart>& Parts, uint32 NumMeshes)
{
TArray<TArray<uint32>> PartsByMesh;
PartsByMesh.SetNum(NumMeshes);
// 将group part分配给它们所属的网格.
const uint32 NumTotalParts = Parts.Num();
for (uint32 PartIndex = 0; PartIndex < NumTotalParts; PartIndex++)
{
FClusterGroupPart& Part = Parts[PartIndex];
PartsByMesh[Groups[Part.GroupIndex].MeshIndex].Add(PartIndex);
}
for (uint32 MeshIndex = 0; MeshIndex < NumMeshes; MeshIndex++)
{
const TArray<uint32>& PartIndices = PartsByMesh[MeshIndex];
const uint32 NumParts = PartIndices.Num();
int32 MaxMipLevel = 0;
for (uint32 i = 0; i < NumParts; i++)
{
MaxMipLevel = FMath::Max(MaxMipLevel, Groups[Parts[PartIndices[i]].GroupIndex].MipLevel);
}
TArray< FIntermediateNode > Nodes;
Nodes.SetNum(NumParts);
// 为每个网格的LOD层级构建叶子节点.
TArray<TArray<uint32>> NodesByMip;
NodesByMip.SetNum(MaxMipLevel + 1);
for (uint32 i = 0; i < NumParts; i++)
{
const uint32 PartIndex = PartIndices[i];
const FClusterGroupPart& Part = Parts[PartIndex];
const FClusterGroup& Group = Groups[Part.GroupIndex];
const int32 MipLevel = Group.MipLevel;
FIntermediateNode& Node = Nodes[i];
Node.Bound = Part.Bounds;
Node.PartIndex = PartIndex;
Node.MipLevel = Group.MipLevel;
Node.bLeaf = true;
NodesByMip[Group.MipLevel].Add(i);
}
uint32 RootIndex = 0;
if (Nodes.Num() == 1)
{
// 只是一个叶子节点, 需要特殊设置, 因为根节点总是一个内部节点。
FIntermediateNode& Node = Nodes.AddDefaulted_GetRef();
Node.Children.Add(0);
Node.Bound = Nodes[0].Bound;
RootIndex = 1;
}
else
{
// 构建层次结构(Hierarchy):
// Nanite网格包含了许多LOD级的Cluster数据. 不同层级的Cluster大小可以相差很大, 这对建立良好的Hierarchy俨然是个挑战.
// 除了可见性包围盒,该Hierarchy还跟踪子节点的保守LOD误差度量。
// 只要子节点是可见的,并且保守LOD误差不会比我们所寻找的更详细,运行时遍历就会下降。
// 当混合来自不同LOD的Cluster时,我们必须非常小心,因为不太详细的Cluster很容易导致包围盒和误差度量的膨胀。
// 我们已经尝试了许多LOD混合方法,但目前看来,为每个LOD级别构建单独的Hierarchy,然后再构建这些Hierarchy的Hierarchy,可以得到最好的、最可预测的结果。
TArray<uint32> LevelRoots;
for (int32 MipLevel = 0; MipLevel <= MaxMipLevel; MipLevel++)
{
if (NodesByMip[MipLevel].Num() > 0)
{
// 为mip层级构建一个hierarchy, 使用了自顶向下分离法.
uint32 NodeIndex = BuildHierarchyTopDown(Nodes, NodesByMip[MipLevel], true);
if (Nodes[NodeIndex].bLeaf || Nodes[NodeIndex].Children.Num() == MAX_BVH_NODE_FANOUT)
{
// 叶子或填充节点, 直接加入.
LevelRoots.Add(NodeIndex);
}
else
{
// 不完整的节点。丢弃编码,并将子节点添加为根节点.
LevelRoots.Append(Nodes[NodeIndex].Children);
}
}
}
// 构建顶层hierarchy, 是MIP hierarchies的hierarchy.
RootIndex = BuildHierarchyTopDown(Nodes, LevelRoots, false);
}
check(Nodes.Num() > 0);
#if BVH_BUILD_WRITE_GRAPHVIZ
WriteDotGraph(Nodes);
#endif
TArray< FHierarchyNode > HierarchyNodes;
BuildHierarchyRecursive(HierarchyNodes, Nodes, Groups, Parts, RootIndex);
// 转换hierarchy成压缩格式.
const uint32 NumHierarchyNodes = HierarchyNodes.Num();
const uint32 PackedBaseIndex = Resources.HierarchyNodes.Num();
Resources.HierarchyRootOffsets.Add(PackedBaseIndex);
Resources.HierarchyNodes.AddDefaulted(NumHierarchyNodes);
for (uint32 i = 0; i < NumHierarchyNodes; i++)
{
// 压缩Hierarchy节点.
PackHierarchyNode(Resources.HierarchyNodes[PackedBaseIndex + i], HierarchyNodes[i], Groups, Parts);
}
}
}
// 写入页表.
static void WritePages( FResources& Resources,
TArray<FPage>& Pages,
const TArray<FClusterGroup>& Groups,
const TArray<FClusterGroupPart>& Parts,
const TArray<FCluster>& Clusters,
const TArray<FEncodingInfo>& EncodingInfos,
uint32 NumTexCoords)
{
check(Resources.PageStreamingStates.Num() == 0);
const bool bLZCompress = true;
TArray< uint8 > StreamableBulkData;
const uint32 NumPages = Pages.Num();
const uint32 NumClusters = Clusters.Num();
Resources.PageStreamingStates.SetNum(NumPages);
// 处理FixupChunk.
uint32 TotalGPUSize = 0;
TArray<FFixupChunk> FixupChunks;
FixupChunks.SetNum(NumPages);
for (uint32 PageIndex = 0; PageIndex < NumPages; PageIndex++)
{
const FPage& Page = Pages[PageIndex];
FFixupChunk& FixupChunk = FixupChunks[PageIndex];
FixupChunk.Header.NumClusters = Page.NumClusters;
uint32 NumHierarchyFixups = 0;
for (uint32 i = 0; i < Page.PartsNum; i++)
{
const FClusterGroupPart& Part = Parts[Page.PartsStartIndex + i];
NumHierarchyFixups += Groups[Part.GroupIndex].PageIndexNum;
}
FixupChunk.Header.NumHierachyFixups = NumHierarchyFixups; // NumHierarchyFixups must be set before writing cluster fixups
TotalGPUSize += Page.GpuSizes.GetTotal();
}
// 向Page添加额外的修正.
for (const FClusterGroupPart& Part : Parts)
{
check(Part.PageIndex < NumPages);
const FClusterGroup& Group = Groups[Part.GroupIndex];
for (uint32 ClusterPositionInPart = 0; ClusterPositionInPart < (uint32)Part.Clusters.Num(); ClusterPositionInPart++)
{
const FCluster& Cluster = Clusters[Part.Clusters[ClusterPositionInPart]];
if (Cluster.GeneratingGroupIndex != INVALID_GROUP_INDEX)
{
const FClusterGroup& GeneratingGroup = Groups[Cluster.GeneratingGroupIndex];
check(GeneratingGroup.PageIndexNum >= 1);
if (GeneratingGroup.PageIndexStart == Part.PageIndex && GeneratingGroup.PageIndexNum == 1)
continue; // Dependencies already met by current page. Fixup directly instead.
uint32 PageDependencyStart = GeneratingGroup.PageIndexStart;
uint32 PageDependencyNum = GeneratingGroup.PageIndexNum;
RemoveRootPagesFromRange(PageDependencyStart, PageDependencyNum); // Root page should never be a dependency
const FClusterFixup ClusterFixup = FClusterFixup(Part.PageIndex, Part.PageClusterOffset + ClusterPositionInPart, PageDependencyStart, PageDependencyNum);
for (uint32 i = 0; i < GeneratingGroup.PageIndexNum; i++)
{
FFixupChunk& FixupChunk = FixupChunks[GeneratingGroup.PageIndexStart + i];
FixupChunk.GetClusterFixup(FixupChunk.Header.NumClusterFixups++) = ClusterFixup;
}
}
}
}
// 生成page依赖.
for (uint32 PageIndex = 0; PageIndex < NumPages; PageIndex++)
{
const FFixupChunk& FixupChunk = FixupChunks[PageIndex];
FPageStreamingState& PageStreamingState = Resources.PageStreamingStates[PageIndex];
PageStreamingState.DependenciesStart = Resources.PageDependencies.Num();
for (uint32 i = 0; i < FixupChunk.Header.NumClusterFixups; i++)
{
uint32 FixupPageIndex = FixupChunk.GetClusterFixup(i).GetPageIndex();
check(FixupPageIndex < NumPages);
if (IsRootPage(FixupPageIndex) || FixupPageIndex == PageIndex) // Never emit dependencies to ourselves or a root page.
continue;
// 没有在集合内才增加.
// O(n^2), 但实际上依赖数量会比较小.
bool bFound = false;
for (uint32 j = PageStreamingState.DependenciesStart; j < (uint32)Resources.PageDependencies.Num(); j++)
{
if (Resources.PageDependencies[j] == FixupPageIndex)
{
bFound = true;
break;
}
}
if (bFound)
continue;
Resources.PageDependencies.Add(FixupPageIndex);
}
PageStreamingState.DependenciesNum = Resources.PageDependencies.Num() - PageStreamingState.DependenciesStart;
}
// 处理page.
struct FPageResult
{
TArray<uint8> Data;
uint32 UncompressedSize;
};
TArray< FPageResult > PageResults;
PageResults.SetNum(NumPages);
// 并行处理
ParallelFor(NumPages, [&Resources, &Pages, &Groups, &Parts, &Clusters, &EncodingInfos, &FixupChunks, &PageResults, NumTexCoords, bLZCompress](int32 PageIndex)
{
const FPage& Page = Pages[PageIndex];
FFixupChunk& FixupChunk = FixupChunks[PageIndex];
// 增加hierarchy修正.
{
// Parts include the hierarchy fixups for all the other parts of the same group.
uint32 NumHierarchyFixups = 0;
for (uint32 i = 0; i < Page.PartsNum; i++)
{
const FClusterGroupPart& Part = Parts[Page.PartsStartIndex + i];
const FClusterGroup& Group = Groups[Part.GroupIndex];
const uint32 HierarchyRootOffset = Resources.HierarchyRootOffsets[Group.MeshIndex];
uint32 PageDependencyStart = Group.PageIndexStart;
uint32 PageDependencyNum = Group.PageIndexNum;
RemoveRootPagesFromRange(PageDependencyStart, PageDependencyNum);
// Add fixups to all parts of the group
for (uint32 j = 0; j < Group.PageIndexNum; j++)
{
const FPage& Page2 = Pages[Group.PageIndexStart + j];
for (uint32 k = 0; k < Page2.PartsNum; k++)
{
const FClusterGroupPart& Part2 = Parts[Page2.PartsStartIndex + k];
if (Part2.GroupIndex == Part.GroupIndex)
{
const uint32 GlobalHierarchyNodeIndex = HierarchyRootOffset + Part2.HierarchyNodeIndex;
FixupChunk.GetHierarchyFixup(NumHierarchyFixups++) = FHierarchyFixup(Part2.PageIndex, GlobalHierarchyNodeIndex, Part2.HierarchyChildIndex, Part2.PageClusterOffset, PageDependencyStart, PageDependencyNum);
break;
}
}
}
}
check(NumHierarchyFixups == FixupChunk.Header.NumHierachyFixups);
}
// Pack clusters and generate material range data
TArray<uint32> CombinedStripBitmaskData;
TArray<uint32> CombinedVertexRefBitmaskData;
TArray<uint32> CombinedVertexRefData;
TArray<uint8> CombinedIndexData;
TArray<uint8> CombinedPositionData;
TArray<uint8> CombinedAttributeData;
TArray<uint32> MaterialRangeData;
TArray<uint16> CodedVerticesPerCluster;
TArray<uint32> NumVertexBytesPerCluster;
TArray<FPackedCluster> PackedClusters;
PackedClusters.SetNumUninitialized(Page.NumClusters);
CodedVerticesPerCluster.SetNumUninitialized(Page.NumClusters);
NumVertexBytesPerCluster.SetNumUninitialized(Page.NumClusters);
const uint32 NumPackedClusterDwords = Page.NumClusters * sizeof(FPackedCluster) / sizeof(uint32);
FPageSections GpuSectionOffsets = Page.GpuSizes.GetOffsets();
TMap<FVariableVertex, uint32> UniqueVertices;
for (uint32 i = 0; i < Page.PartsNum; i++)
{
const FClusterGroupPart& Part = Parts[Page.PartsStartIndex + i];
for (uint32 j = 0; j < (uint32)Part.Clusters.Num(); j++)
{
const uint32 ClusterIndex = Part.Clusters[j];
const FCluster& Cluster = Clusters[ClusterIndex];
const FEncodingInfo& EncodingInfo = EncodingInfos[ClusterIndex];
const uint32 LocalClusterIndex = Part.PageClusterOffset + j;
FPackedCluster& PackedCluster = PackedClusters[LocalClusterIndex];
PackCluster(PackedCluster, Cluster, EncodingInfos[ClusterIndex], NumTexCoords);
PackedCluster.PackedMaterialInfo = PackMaterialInfo(Cluster, MaterialRangeData, NumPackedClusterDwords);
check((GpuSectionOffsets.Index & 3) == 0);
check((GpuSectionOffsets.Position & 3) == 0);
check((GpuSectionOffsets.Attribute & 3) == 0);
PackedCluster.SetIndexOffset(GpuSectionOffsets.Index);
PackedCluster.SetPositionOffset(GpuSectionOffsets.Position);
PackedCluster.SetAttributeOffset(GpuSectionOffsets.Attribute);
PackedCluster.SetDecodeInfoOffset(GpuSectionOffsets.DecodeInfo);
GpuSectionOffsets += EncodingInfo.GpuSizes;
const uint32 PrevVertexBytes = CombinedPositionData.Num();
uint32 NumCodedVertices = 0;
EncodeGeometryData( LocalClusterIndex, Cluster, EncodingInfo, NumTexCoords,
CombinedStripBitmaskData, CombinedIndexData,
CombinedVertexRefBitmaskData, CombinedVertexRefData, CombinedPositionData, CombinedAttributeData,
UniqueVertices, NumCodedVertices);
NumVertexBytesPerCluster[LocalClusterIndex] = CombinedPositionData.Num() - PrevVertexBytes;
CodedVerticesPerCluster[LocalClusterIndex] = NumCodedVertices;
}
}
check(GpuSectionOffsets.Cluster == Page.GpuSizes.GetMaterialTableOffset());
check(Align(GpuSectionOffsets.MaterialTable, 16) == Page.GpuSizes.GetDecodeInfoOffset());
check(GpuSectionOffsets.DecodeInfo == Page.GpuSizes.GetIndexOffset());
check(GpuSectionOffsets.Index == Page.GpuSizes.GetPositionOffset());
check(GpuSectionOffsets.Position == Page.GpuSizes.GetAttributeOffset());
check(GpuSectionOffsets.Attribute == Page.GpuSizes.GetTotal());
// Dword对齐索引数据.
CombinedIndexData.SetNumZeroed((CombinedIndexData.Num() + 3) & -4);
// 直接在packkedclusters上执行页面内部修复.
for (uint32 LocalPartIndex = 0; LocalPartIndex < Page.PartsNum; LocalPartIndex++)
{
const FClusterGroupPart& Part = Parts[Page.PartsStartIndex + LocalPartIndex];
const FClusterGroup& Group = Groups[Part.GroupIndex];
uint32 GeneratingGroupIndex = MAX_uint32;
for (uint32 ClusterPositionInPart = 0; ClusterPositionInPart < (uint32)Part.Clusters.Num(); ClusterPositionInPart++)
{
const FCluster& Cluster = Clusters[Part.Clusters[ClusterPositionInPart]];
if (Cluster.GeneratingGroupIndex != INVALID_GROUP_INDEX)
{
const FClusterGroup& GeneratingGroup = Groups[Cluster.GeneratingGroupIndex];
uint32 PageDependencyStart = Group.PageIndexStart;
uint32 PageDependencyNum = Group.PageIndexNum;
RemoveRootPagesFromRange(PageDependencyStart, PageDependencyNum);
if (GeneratingGroup.PageIndexStart == PageIndex && GeneratingGroup.PageIndexNum == 1)
{
// 当前Page已经满足的依赖, 直接修正.
PackedClusters[Part.PageClusterOffset + ClusterPositionInPart].Flags &= ~NANITE_CLUSTER_FLAG_LEAF; // Mark parent as no longer leaf
}
}
}
}
// 开始page
FPageResult& PageResult = PageResults[PageIndex];
PageResult.Data.SetNum(CLUSTER_PAGE_DISK_SIZE);
FBlockPointer PagePointer(PageResult.Data.GetData(), PageResult.Data.Num());
// 磁盘头信息.
FPageDiskHeader* PageDiskHeader = PagePointer.Advance<FPageDiskHeader>(1);
// 16字节对齐材质范围数据,使其易于在GPU转码期间复制.
MaterialRangeData.SetNum(Align(MaterialRangeData.Num(), 4));
static_assert(sizeof(FUVRange) % 16 == 0, "sizeof(FUVRange) must be a multiple of 16");
static_assert(sizeof(FPackedCluster) % 16 == 0, "sizeof(FPackedCluster) must be a multiple of 16");
PageDiskHeader->NumClusters = Page.NumClusters;
PageDiskHeader->GpuSize = Page.GpuSizes.GetTotal();
PageDiskHeader->NumRawFloat4s = Page.NumClusters * (sizeof(FPackedCluster) + NumTexCoords * sizeof(FUVRange)) / 16 + MaterialRangeData.Num() / 4;
PageDiskHeader->NumTexCoords = NumTexCoords;
// Cluster头信息.
FClusterDiskHeader* ClusterDiskHeaders = PagePointer.Advance<FClusterDiskHeader>(Page.NumClusters);
// 用SOA(Structure-of-Arrays)内存布局写入cluster.
{
const uint32 NumClusterFloat4Propeties = sizeof(FPackedCluster) / 16;
for (uint32 float4Index = 0; float4Index < NumClusterFloat4Propeties; float4Index++)
{
for (const FPackedCluster& PackedCluster : PackedClusters)
{
uint8* Dst = PagePointer.Advance<uint8>(16);
FMemory::Memcpy(Dst, (uint8*)&PackedCluster + float4Index * 16, 16);
}
}
}
// 材质表.
uint32 MaterialTableSize = MaterialRangeData.Num() * MaterialRangeData.GetTypeSize();
uint8* MaterialTable = PagePointer.Advance<uint8>(MaterialTableSize);
FMemory::Memcpy(MaterialTable, MaterialRangeData.GetData(), MaterialTableSize);
check(MaterialTableSize == Page.GpuSizes.GetMaterialTableSize());
// 解码信息.
PageDiskHeader->DecodeInfoOffset = PagePointer.Offset();
for (uint32 i = 0; i < Page.PartsNum; i++)
{
const FClusterGroupPart& Part = Parts[Page.PartsStartIndex + i];
for (uint32 j = 0; j < (uint32)Part.Clusters.Num(); j++)
{
const uint32 ClusterIndex = Part.Clusters[j];
FUVRange* DecodeInfo = PagePointer.Advance<FUVRange>(NumTexCoords);
for (uint32 k = 0; k < NumTexCoords; k++)
{
DecodeInfo[k] = EncodingInfos[ClusterIndex].UVInfos[k].UVRange;
}
}
}
// 索引数据.
{
uint8* IndexData = PagePointer.GetPtr<uint8>();
#if USE_STRIP_INDICES
for (uint32 i = 0; i < Page.PartsNum; i++)
{
const FClusterGroupPart& Part = Parts[Page.PartsStartIndex + i];
for (uint32 j = 0; j < (uint32)Part.Clusters.Num(); j++)
{
const uint32 LocalClusterIndex = Part.PageClusterOffset + j;
const uint32 ClusterIndex = Part.Clusters[j];
const FCluster& Cluster = Clusters[ClusterIndex];
ClusterDiskHeaders[LocalClusterIndex].IndexDataOffset = PagePointer.Offset();
ClusterDiskHeaders[LocalClusterIndex].NumPrevNewVerticesBeforeDwords = Cluster.StripDesc.NumPrevNewVerticesBeforeDwords;
ClusterDiskHeaders[LocalClusterIndex].NumPrevRefVerticesBeforeDwords = Cluster.StripDesc.NumPrevRefVerticesBeforeDwords;
PagePointer.Advance<uint8>(Cluster.StripIndexData.Num());
}
}
uint32 IndexDataSize = CombinedIndexData.Num() * CombinedIndexData.GetTypeSize();
FMemory::Memcpy(IndexData, CombinedIndexData.GetData(), IndexDataSize);
PagePointer.Align(sizeof(uint32));
PageDiskHeader->StripBitmaskOffset = PagePointer.Offset();
uint32 StripBitmaskDataSize = CombinedStripBitmaskData.Num() * CombinedStripBitmaskData.GetTypeSize();
uint8* StripBitmaskData = PagePointer.Advance<uint8>(StripBitmaskDataSize);
FMemory::Memcpy(StripBitmaskData, CombinedStripBitmaskData.GetData(), StripBitmaskDataSize);
#else
for (uint32 i = 0; i < Page.NumClusters; i++)
{
ClusterDiskHeaders[i].IndexDataOffset = PagePointer.Offset();
PagePointer.Advance<uint8>(PackedClusters[i].GetNumTris() * 3);
}
PagePointer.Align(sizeof(uint32));
uint32 IndexDataSize = CombinedIndexData.Num() * CombinedIndexData.GetTypeSize();
FMemory::Memcpy(IndexData, CombinedIndexData.GetData(), IndexDataSize);
#endif
}
// 写入顶点引用的位掩码.
{
PageDiskHeader->VertexRefBitmaskOffset = PagePointer.Offset();
const uint32 VertexRefBitmaskSize = Page.NumClusters * (MAX_CLUSTER_VERTICES / 8);
uint8* VertexRefBitmask = PagePointer.Advance<uint8>(VertexRefBitmaskSize);
FMemory::Memcpy(VertexRefBitmask, CombinedVertexRefBitmaskData.GetData(), VertexRefBitmaskSize);
check(CombinedVertexRefBitmaskData.Num() * CombinedVertexRefBitmaskData.GetTypeSize() == VertexRefBitmaskSize);
}
// 写入顶点引用.
{
uint8* VertexRefs = PagePointer.GetPtr<uint8>();
for (uint32 i = 0; i < Page.NumClusters; i++)
{
ClusterDiskHeaders[i].VertexRefDataOffset = PagePointer.Offset();
uint32 NumVertexRefs = PackedClusters[i].GetNumVerts() - CodedVerticesPerCluster[i];
PagePointer.Advance<uint32>(NumVertexRefs);
}
FMemory::Memcpy(VertexRefs, CombinedVertexRefData.GetData(), CombinedVertexRefData.Num() * CombinedVertexRefData.GetTypeSize());
}
// 写入位置.
{
uint8* PositionData = PagePointer.GetPtr<uint8>();
for (uint32 i = 0; i < Page.NumClusters; i++)
{
ClusterDiskHeaders[i].PositionDataOffset = PagePointer.Offset();
PagePointer.Advance<uint8>(NumVertexBytesPerCluster[i]);
}
check( (PagePointer.GetPtr<uint8>() - PositionData) == CombinedPositionData.Num() * CombinedPositionData.GetTypeSize());
FMemory::Memcpy(PositionData, CombinedPositionData.GetData(), CombinedPositionData.Num() * CombinedPositionData.GetTypeSize());
}
// 写入属性.
{
uint8* AttribData = PagePointer.GetPtr<uint8>();
for (uint32 i = 0; i < Page.NumClusters; i++)
{
const uint32 BytesPerAttribute = (PackedClusters[i].GetBitsPerAttribute() + 7) / 8;
ClusterDiskHeaders[i].AttributeDataOffset = PagePointer.Offset();
PagePointer.Advance<uint8>(Align(CodedVerticesPerCluster[i] * BytesPerAttribute, 4));
}
check((uint32)(PagePointer.GetPtr<uint8>() - AttribData) == CombinedAttributeData.Num() * CombinedAttributeData.GetTypeSize());
FMemory::Memcpy(AttribData, CombinedAttributeData.GetData(), CombinedAttributeData.Num()* CombinedAttributeData.GetTypeSize());
}
// 使用Lempel-Ziv(LZ)无损压缩内存, LZ的一个变种是Lempel-Ziv-Welch(LZW).
// 更多详见: http://athena.ecs.csus.edu/~wang/DLZW.pdf.
if (bLZCompress)
{
TArray<uint8> DataCopy(PageResult.Data.GetData(), PagePointer.Offset());
PageResult.UncompressedSize = DataCopy.Num();
int32 CompressedSize = PageResult.Data.Num();
verify(FCompression::CompressMemory(NAME_LZ4, PageResult.Data.GetData(), CompressedSize, DataCopy.GetData(), DataCopy.Num()));
PageResult.Data.SetNum(CompressedSize, false);
}
else // 不使用压缩.
{
PageResult.Data.SetNum(PagePointer.Offset(), false);
PageResult.UncompressedSize = PageResult.Data.Num();
}
});
// 写入Page.
uint32 TotalUncompressedSize = 0;
uint32 TotalCompressedSize = 0;
uint32 TotalFixupSize = 0;
for (uint32 PageIndex = 0; PageIndex < NumPages; PageIndex++)
{
const FPage& Page = Pages[PageIndex];
FFixupChunk& FixupChunk = FixupChunks[PageIndex];
TArray<uint8>& BulkData = IsRootPage(PageIndex) ? Resources.RootClusterPage : StreamableBulkData;
FPageStreamingState& PageStreamingState = Resources.PageStreamingStates[PageIndex];
PageStreamingState.BulkOffset = BulkData.Num();
// 写入修正块.
uint32 FixupChunkSize = FixupChunk.GetSize();
check(FixupChunk.Header.NumHierachyFixups < MAX_CLUSTERS_PER_PAGE);
check(FixupChunk.Header.NumClusterFixups < MAX_CLUSTERS_PER_PAGE);
BulkData.Append((uint8*)&FixupChunk, FixupChunkSize);
TotalFixupSize += FixupChunkSize;
// 拷贝页到BulkData.
TArray<uint8>& PageData = PageResults[PageIndex].Data;
BulkData.Append(PageData.GetData(), PageData.Num());
TotalUncompressedSize += PageResults[PageIndex].UncompressedSize;
TotalCompressedSize += PageData.Num();
PageStreamingState.BulkSize = BulkData.Num() - PageStreamingState.BulkOffset;
PageStreamingState.PageUncompressedSize = PageResults[PageIndex].UncompressedSize;
}
uint32 TotalDiskSize = Resources.RootClusterPage.Num() + StreamableBulkData.Num();
UE_LOG(LogStaticMesh, Log, TEXT("WritePages:"), NumPages);
UE_LOG(LogStaticMesh, Log, TEXT(" %d pages written."), NumPages);
UE_LOG(LogStaticMesh, Log, TEXT(" GPU size: %d bytes. %.3f bytes per page. %.3f%% utilization."), TotalGPUSize, TotalGPUSize / float(NumPages), TotalGPUSize / (float(NumPages) * CLUSTER_PAGE_GPU_SIZE) * 100.0f);
UE_LOG(LogStaticMesh, Log, TEXT(" Uncompressed page data: %d bytes. Compressed page data: %d bytes. Fixup data: %d bytes."), TotalUncompressedSize, TotalCompressedSize, TotalFixupSize);
UE_LOG(LogStaticMesh, Log, TEXT(" Total disk size: %d bytes. %.3f bytes per page."), TotalDiskSize, TotalDiskSize/ float(NumPages));
// 存储PageData.
Resources.StreamableClusterPages.Lock(LOCK_READ_WRITE);
uint8* Ptr = (uint8*)Resources.StreamableClusterPages.Realloc(StreamableBulkData.Num());
FMemory::Memcpy(Ptr, StreamableBulkData.GetData(), StreamableBulkData.Num());
Resources.StreamableClusterPages.Unlock();
Resources.StreamableClusterPages.SetBulkDataFlags(BULKDATA_Force_NOT_InlinePayload);
Resources.bLZCompressed = bLZCompress;
}
6.4.2.8 FImposterAtlas::Rasterize
// Engine\Source\Developer\NaniteBuilder\Private\ImposterAtlas.cpp
// 将指定Cluster的光栅化到Imposter.
void FImposterAtlas::Rasterize( const FIntPoint& TilePos, const FCluster& Cluster, uint32 ClusterIndex )
{
constexpr uint32 ViewSize = TileSize;// * SuperSample;
FIntRect Scissor( 0, 0, ViewSize, ViewSize );
// 获取局部到Imposter的变换矩阵.
FMatrix LocalToImposter = GetLocalToImposter( TilePos );
TArray< FVector, TInlineAllocator<128> > Positions;
Positions.SetNum( Cluster.NumVerts, false );
// 提取Cluster顶点位置, 并转换到Imposter空间.
for( uint32 VertIndex = 0; VertIndex < Cluster.NumVerts; VertIndex++ )
{
FVector Position = Cluster.GetPosition( VertIndex );
Position = LocalToImposter.TransformPosition( Position );
Positions[ VertIndex ].X = ( Position.X * 0.5f + 0.5f ) * ViewSize;
Positions[ VertIndex ].Y = ( Position.Y * 0.5f + 0.5f ) * ViewSize;
Positions[ VertIndex ].Z = ( Position.Z * 0.5f + 0.5f ) * 254.0f + 1.0f; // zero is reserved as masked
}
// 遍历所有三角形, 光栅化它们到Imposter.
for( uint32 TriIndex = 0; TriIndex < Cluster.NumTris; TriIndex++ )
{
FVector Verts[3];
Verts[0] = Positions[ Cluster.Indexes[ TriIndex * 3 + 0 ] ];
Verts[1] = Positions[ Cluster.Indexes[ TriIndex * 3 + 1 ] ];
Verts[2] = Positions[ Cluster.Indexes[ TriIndex * 3 + 2 ] ];
// 光栅化三角形.
RasterizeTri( Verts, Scissor, 0,
// 保存光栅化后的结果.
[&]( int32 x, int32 y, float z )
{
uint32 Depth = FMath::RoundToInt( FMath::Clamp( z, 1.0f, 255.0f ) );
uint16 PixelValue = ( Depth << 8 ) | ( ClusterIndex << 7 ) | TriIndex;
//uint32 PixelIndex = x + y * ViewSize;
uint32 PixelIndex = x + ( y + ( TilePos.X + TilePos.Y * AtlasSize ) * TileSize ) * TileSize;
Pixels[ PixelIndex ] = FMath::Max( Pixels[ PixelIndex ], PixelValue );
} );
}
}
// Engine\Source\Developer\NaniteBuilder\Private\Rasterizer.h
// 软光栅指定的三角形, 写入数据时调用FWritePixel回调函数.
template< typename FWritePixel >
void RasterizeTri( const FVector Verts[3], const FIntRect& ScissorRect, uint32 SubpixelDilate, FWritePixel WritePixel )
{
constexpr uint32 SubpixelBits = 8;
constexpr uint32 SubpixelSamples = 1 << SubpixelBits;
FVector v01 = Verts[1] - Verts[0];
FVector v02 = Verts[2] - Verts[0];
float DetXY = v01.X * v02.Y - v01.Y * v02.X;
if( DetXY >= 0.0f )
{
// 背面剔除.
// 如果未剔除,需要交换顶点,为其余代码纠正winding.
return;
}
FVector2D GradZ;
GradZ.X = ( v01.Z * v02.Y - v01.Y * v02.Z ) / DetXY;
GradZ.Y = ( v01.X * v02.Z - v01.Z * v02.X ) / DetXY;
// 24.8 fixed point
FIntPoint Vert0 = ToIntPoint( Verts[0] * SubpixelSamples );
FIntPoint Vert1 = ToIntPoint( Verts[1] * SubpixelSamples );
FIntPoint Vert2 = ToIntPoint( Verts[2] * SubpixelSamples );
// 矩形包围盒.
FIntRect RectSubpixel( Vert0, Vert0 );
RectSubpixel.Include( Vert1 );
RectSubpixel.Include( Vert2 );
RectSubpixel.InflateRect( SubpixelDilate );
// 四舍五入到最近像素.
FIntRect RectPixel = ( ( RectSubpixel + (SubpixelSamples / 2) - 1 ) ) / SubpixelSamples;
// 裁剪到视口.
RectPixel.Clip( ScissorRect );
// 若没有像素覆盖, 裁剪之.
if( RectPixel.IsEmpty() )
return;
// 12.8 fixed point
FIntPoint Edge01 = Vert0 - Vert1;
FIntPoint Edge12 = Vert1 - Vert2;
FIntPoint Edge20 = Vert2 - Vert0;
// 用半像素偏移调整MinPixel.
// 12.8 fixed point
// 最大的三角形尺寸 = 2047x2047 像素.
const FIntPoint BaseSubpixel = RectPixel.Min * SubpixelSamples + (SubpixelSamples / 2);
Vert0 -= BaseSubpixel;
Vert1 -= BaseSubpixel;
Vert2 -= BaseSubpixel;
auto EdgeC = [=]( const FIntPoint& Edge, const FIntPoint& Vert )
{
int64 ex = Edge.X;
int64 ey = Edge.Y;
int64 vx = Vert.X;
int64 vy = Vert.Y;
// Half-edge constants
// 24.16 fixed point
int64 C = ey * vx - ex * vy;
// 校正填充公约(fill convention)
// Top left rule for CCW
C -= ( Edge.Y < 0 || ( Edge.Y == 0 && Edge.X > 0 ) ) ? 0 : 1;
// 扩大边.
C += ( FMath::Abs( Edge.X ) + FMath::Abs( Edge.Y ) ) * SubpixelDilate;
// 像素增量步进.
// 低位总是相同的,因此在测试符号时无关紧要。
// 24.8 fixed point
return int32( C >> SubpixelBits );
};
int32 C0 = EdgeC( Edge01, Vert0 );
int32 C1 = EdgeC( Edge12, Vert1 );
int32 C2 = EdgeC( Edge20, Vert2 );
float Z0 = Verts[0].Z - ( GradZ.X * Vert0.X + GradZ.Y * Vert0.Y ) / SubpixelSamples;
int32 CY0 = C0;
int32 CY1 = C1;
int32 CY2 = C2;
float ZY = Z0;
// 遍历矩形内的所有像素, 填充在三角形内的像素.
for( int32 y = RectPixel.Min.Y; y < RectPixel.Max.Y; y++ )
{
int32 CX0 = CY0;
int32 CX1 = CY1;
int32 CX2 = CY2;
float ZX = ZY;
for( int32 x = RectPixel.Min.X; x < RectPixel.Max.X; x++ )
{
// 如果当前3个边的X分量都是正数, 说明在三角形内, 调用WritePixel写入数据.
if( ( CX0 | CX1 | CX2 ) >= 0 )
{
WritePixel( x, y, ZX );
}
CX0 -= Edge01.Y;
CX1 -= Edge12.Y;
CX2 -= Edge20.Y;
ZX += GradZ.X;
}
CY0 += Edge01.X;
CY1 += Edge12.X;
CY2 += Edge20.X;
ZY += GradZ.Y;
}
}
6.4.2.9 Nanite数据构建总结
本小节总结一下Nanite数据构建的过程。最初的入口是BuildNaniteFromHiResSourceModel:
- 从UStaticMesh的HiResSourceModel获取Nanite的高精度模型。
- 计算切线、光照图UV等。
- 构建临时的RenderData数据, 以便传递到后续的Nanite构建阶段.。
- 构建逐Section索引、顶点和索引缓冲。
- BuildCombinedSectionIndices:连结逐section的索引缓冲。
- ComputeBoundsFromVertexList:在Nanite构建之前从高分辨率网格计算包围盒。
- 从SectionInfoMap中解析出Section材质索引。
- NaniteBuilderModule.Build:执行Nanite构建模块。
下面是NaniteBuilderModule.Build的主要过程概述:
- 构建三角形索引和材质索引的关联数组。
- BuildNaniteData:构建Nanite数据。
- 处理顶点色。
- 遍历所有Section,给每个Section构建Cluster。
- ClusterTriangles:将Section拆分成一个或多个Cluster。
- 初始化共享边、边界边、边哈希等数据。
- 并行地处理边哈希。
- 并行地查找共享边和边界边。
- 处理不连贯的三角形集。
- 使用FGraphPartitioner划分网格。
- FGraphPartitioner内部使用了METIS第三方开源库,METIS能够高效地提供高品质的网格划分,同时具有低填充率的特点,能够保证网格划分的效果和效率。METIS的划分算法有3个阶段:粗化(Coarsening)、划分(Partitioning)、细分(Uncoarsening)。
- 并行地构建Cluster。
- ClusterTriangles:将Section拆分成一个或多个Cluster。
- 检测是否需要用粗糙代表(coarse representation)代替原始的静态网格数据。
- 使用粗糙代表须满足:Nanite设置的PercentTriangles小于1且原网格的三角形数量大于2000。
- 为所有Section调用BuildDAG构建有向非循环图加速减面减模。
- 如果使用粗糙代表,则调用BuildCoarseRepresentation构建粗糙代表的数据,然后使用粗糙网格范围修正网格section信息,同时遵守原始序号和保留材质。
- Encode:编码Nanite网格。
- RemoveDegenerateTriangles:删除所有Cluster的退化三角形。
- BuildMaterialRanges:构建所有Cluster的材质范围。
- ConstrainClusters:约束Cluster到ClusterGroup。
- CalculateQuantizedPositionsUniformGrid:计算量化的位置。
- CalculateEncodingInfos:计算编码信息。
- AssignClustersToPages:分配Cluster到Page。
- BuildHierarchies:构建ClusterGroup的层级节点。
- WritePages:将Cluster和ClusterGroup的信息写入Page。
- 如果有需要(只有一个Section时),则生成FImposterAtlas。
- 并行地为所有Cluster生成Imposter,将每个Cluster的所有三角形光栅化到FImposterAtlas。
在Nanite的构建过程使用了大量的优化技巧,主要包含但不限于:
- 大量使用了ParallelFor,以便利用多线程并行地处理逻辑,缩减构建时间。
- 利用MITES能够获得优良的网格划分。
- 使用Cluster、ClusterGroup、ClusterGroupPart等不同层级的概念有机组合网格相关的数据。
- 使用DAG、Hierarchy、Mip Level、Coarse Representation等加速和优化网格构建和划分。
- 提前生成GPU渲染时需要的Page、ImposterAtlas等信息。
- 使用了大量的高度的数据压缩,如LZ Compression、定点数(fixed point)、位操作等。
另外再说一下,Nanite并没有使用之前传闻的几何图像(Geometry Image)技术,但核心思想或技术还是比较类似的。
据说UE5的Coder中就有和国际数学大师丘成桐弟子、几何图像先驱——顾险峰教授一起发表过论文的作者。
关于Geometry Image技术,可以参考顾教授的论文Geometry images以及他的公众号:老顾谈几何。















 3748
3748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









