







Preface
这是我参加今年智慧城市比赛的任务:车辆精确检索,看的论文。
这篇文章是 北京大学 Multimedia Learning Group 组 CVPR 2016 的文章,没有公开源码,数据集也需要签订协议方可获取。
文章地址在这里:Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles。
Abstract
这篇文章所提出的,网络整体架构为:
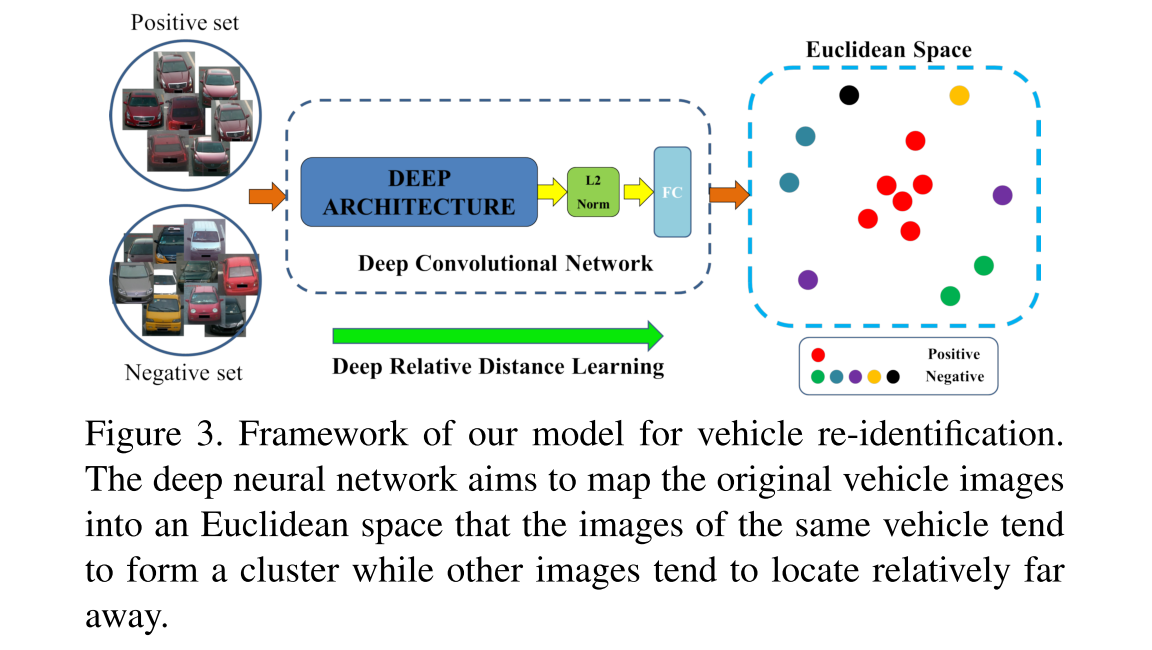
Deep Relative Distance Learning
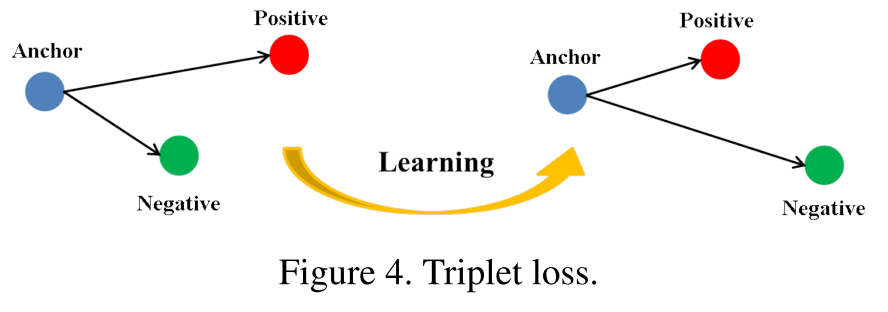
Triplet Loss 是在 2015 年 Pattern Recognition 期刊上的这篇Paper:“Deep feature learning with relative distance comparison for person re-identification”。Triplet Loss 我把它理解为“三元组损失函数”,
Triplet Loss
在标准的 Triplet Loss 中,输入为一批三元组:
{<xa,xp,xn>}
。其中,
xa
和
xp
属于同一标签,而
xa
和
xn
属于不同的标签。
用
f(x)
表示图像
x
的网络的特征表示。当用三元组
或者等同于:
其中, α 是事先预设的参数值,用来衡量标签相同的 xa 、 xp 与标签不相同的 xa 、 xn 之间差距的大小。即“多大的间距”,才能判断这两点的标签是相同的,或者是不相同的。
同时,为了防止损失函数太容易超过 0 ,图像所有的特征都被限制在
上面的话,用图表示为:
所以,定义的损失函数为:
但是,存在一种“极端”的情况,给定
3
个样本点,其中两个属于同一个标签,另一个属于另外的标签。当将这
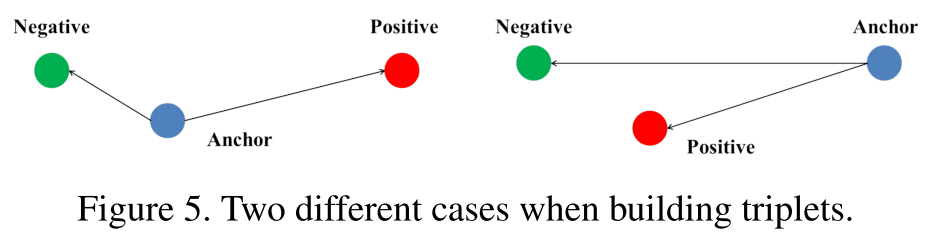
当对于左边的情况,三元组损失函数很容易检测出反常的距离关系。因为左图中, 类内距离( intra−class )明显大于 类间距离( inter−class ),这里, 类内距离( intra−class )指同一个标签的样本之间的“距离”,而 类间距离( inter−class )指不同样本指不同标签样本之间的“距离”。
在图中反应为,蓝色点 “Anchor” 与同标签的红色点 “Positive”,之间的距离大于 Anchor 与 Negative 之间的距离。所以损失函数可以较容易的去学习。
而上一幅图的右边的情况就不同了。
三元损失函数为
0
,因为蓝色点 “Anchor” 与同标签的红色“Positive”之间的距离小于 “Anchor” 点与不同标签的绿色 “Negative” 点之间的距离。因此,这个神经网络在反向传播学习阶段,会忽视这个三元组。
此外,由于三元组损失函数在反向传播中,实际上是要将同标签的越“拉”越近(Anchor 与 Positive),不同标签的越“推”越远(Anchor 与 Negative),所以损失函数对于 Anchor 点的选择是相当敏感的。所以,Anchor 点选择不好的话,在训练阶段会造成极大的干扰,使得网络收敛的很慢。需要很多个正确的三元组样本点去纠正它。
Coupled Clusters Loss
为了使得训练阶段更加稳定,网络收敛的更加快。作者想上面的这种定义损失函数的方式,应该有些欠缺妥当。因此,作者提出了一个新的损失函数,以取代这里的三元组损失函数:Coupled Cluster Loss 。
作者也用深度卷积网络去提取图像的特征,不过原先网络是以“三元组样本点”作为输入数据的,这里由两组图像集取代:一组是正样本集,另一组是负样本集。
一组数据集:
如下图所示:

在计算的时候,先求出正样本“平均中心点”:
相对距离关系反应在下面的公式上:
所以,这个 Coupled Cluster Loss 函数定义为:
其中, xn∗ 是离第一步求得的中心点 cp 最近的 负样本点 。
如果
∥∥f(xpi)−cp∥∥22+α−∥f(xn∗)−cp∥22≤0
,那么正样本的的偏导数,负样本的偏导数都是
0
。
否则的话,正样本的偏导数是:
负样本的偏导数是:
其中,以上的改进中,其核心思想并没有变化。仍是基于那个前提假设,类内距离(intra-class distance) 应该小于 类间距离(inter-class) 。但是作者改进后的版本,不同于之前的版本:
- 距离测度由原先的随机选择 锚点(Anchor),再计算正样本与锚点之间距离,负样本与锚点之间距离,改为:先计算所有正样本的中心点,再计算正样本到中心点的距离。这个改变的前提是基于一个假设:即正样本应该特征相近,形成一个“聚集簇” ,负样本相对较远。
- 改进之后的 Coupled Clusters Loss Function 由多个样本来定义,而不止原先的 3 个。
Mixed Difference Network Structure
辨别一辆特定的车与一个人,是有较大的不同的。因为人与人之间外表几乎不会“重复”(P.S. 双胞胎什么的就别跟我抬杠了……),而一辆车很可能外表上一模一样,比如,它们都是 Audi A4L 2009 款型的车。
但是实际在生活中,还是有可能辨别两辆相同型号的车的,如果车上有一些特殊的标识存在的话,如图:

所以,为了处理这样的例子。对于一张待检索的车辆图像,以及多张待判断的候选车辆图像,它们应该包括两种不同点:
- 它们是否属于同一辆车型?
- 它们是否是同一辆车?
因为现在的 Person Re-identification 并没有考虑到上面的两点,作者选择新的网络框架,为了更好地衡量(mesure)上面两者之间的差异。
作者实验中用的基础网络是 但是,单单这一支网络结构不足以提取到 车辆型号信息(vehicle model information) ,更不足以提取到 相同型号不同车之间的差异 ,于是,作者将单线网络扩充成两支网络。下图展示了网络的结构细节:
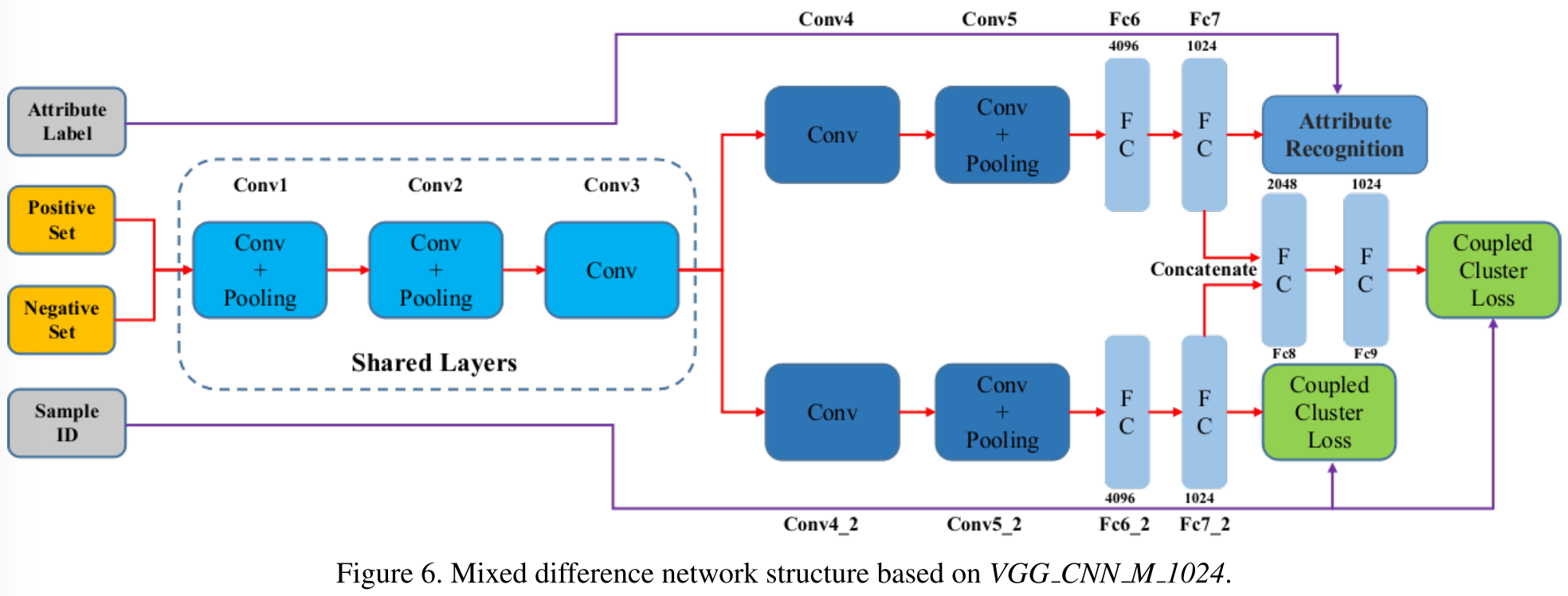
注意到,全连接层 “
fc8
” 是一个 “特征混合层”,将车辆型号信息,以及从 single triplet loss 或者 coupled clusters loss 学习到的 特征表示 进行 混合。这背后的想法也很简单:对于两张车辆图片来说,如果它们的车辆型号不同,那么这两辆车肯定不是同一辆车。如果它们属于同一个型号的车,比如之前例举的都是 Audi A4L 2009,那么就需要做另外的差别测量,以衡量到底是不是同一辆车。这里,
fc8
的维度设置为
2014
维是根据原始标准的
VGG_CNN_M_1024
网络来设置的,是为了消除进行评估实验的时候,特征维度的差异带来的影响。
网络中的
fc7_2
层与标准的
VGG_CNN_M_1024
中特征输出相同,而
fc8
是一个“加强版”的输出,既适合度量相同型号车之间内部的差异,又适合不同型号车之间的差异。
Training the Network
训练数据包括正样本车辆数据集、负样本车辆数据集,以及对应的标签,如 车辆的ID、车辆型号 。
本模型是基于
VGG_CNN_M_1024
在 ImageNet 上训练好的模型上,之后进行 fine-tuned。
实验参数:
- momentum: μ=0.9
- weight decay: λ=2×10−4
- 正样本的图像数、负样本中的图像数都是5张,Batch-size 设置为 15 ,所以在每一次迭代训练时,我们需要输入 15×(5+5)=150 张图像
- 开始设置的学习率 Learning rate: η(0)=0.01 ,之后每 8000 次迭代下降到: η(i)=η(0)0.7i/8000
- 每一个网络分支上的 Loss Weight,如图中,网络上面的分支,Softmax 为: 0.5 ,下面的分支,Coupled Cluster Loss 为: 0.5 ,最后的“聚合”的 Coupled Cluster Loss 为: 1.0















 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









